Python爬虫连载1-urllib.request和chardet包使用方式
一、参考资料
1.《Python网络数据采集》图灵工业出版社
2.《精通Python爬虫框架Scrapy》人民邮电出版社
3.[Scrapy官方教程](http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html)
4.[Python3网络爬虫](http://blog.csdn.net/c406495762/article/details/72858983
二、前提知识
url、http协议、web前端:html\CSS\JS、ajax、re、Xpath、xml
三、基础知识
1.爬虫简介
爬虫定义:网络爬虫(又被称为网页蜘蛛、网络机器人、在FOAF社区中,更经常的称为网页追逐者)是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。两外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者如蠕虫。
2.两大特征
(1)能按作者要求下载数据或者内容
(2)能自动在网络上流窜
3.三大步骤
(1)下载网页;
(2)提取正确的信息
(3)根据一定规则自动跳到另外的网页上执行上两步内容
4.爬虫分类
(1)通用爬虫
(2)专用爬虫
5.Python网络包简介
Python2:urllib\urllib2\urllib3\httplib\httplib2\requests
Python3.x:urllib\urllib3\httplib2\requests
其中python2中urllib和urllib2配合使用,或者requests
Python3就是使用urllib.requests
6.urllib
包含模块
urllib.requests:打开和读取urls
urllib.error:包含urllib.requests产生的常见的错误,使用try捕捉
urllib.parse:包含即时url的方法
urllib.robotparse:解析roobs.txt文件
from urllib import request
"""
使用urllib,request请求一个网页内容,并把内容打印出来
"""
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=984602018"
#打开相应的url并把相应页面作为返回
rsp = request.urlopen(url)
#返回结果读取出来
html = rsp.read()
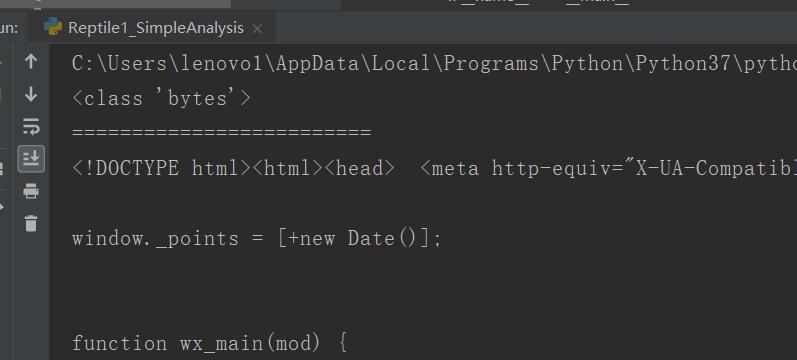
print(type(html))##bytes类型
html = html.decode()
print(html)
7.网页编码解析方式chardet包的使用
from urllib import request
import chardet
"""
使用urllib,request请求一个网页内容,并把内容打印出来
"""
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=984602018"
#打开相应的url并把相应页面作为返回
rsp = request.urlopen(url)
#返回结果读取出来
html = rsp.read()
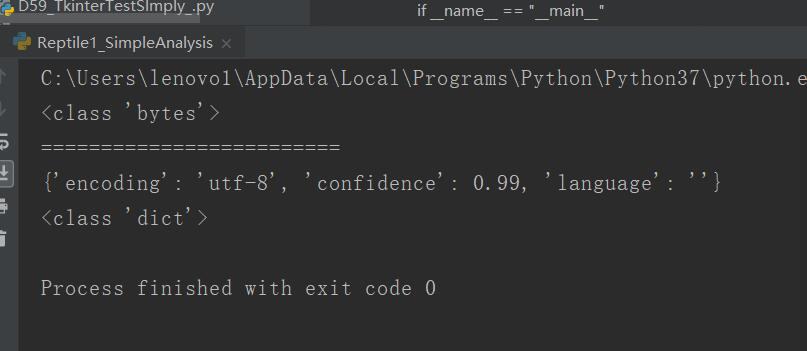
print(type(html))##bytes类型
print("=========================")
cs = chardet.detect(html)#利用chardet来检测这个网页使用的是什么编码方式
print(cs)
print(type(cs))
#使用get方法是为了避免如果取不到值报错,程序就崩溃了
html = html.decode(cs.get("encoding","utf-8"))#取cs字典中encoding属性,如果取不到,那么就使用utf-8
四、源码
Reptile1_SimpleAnalysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile1_SimpleAnalysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050(心悦君兮君不知-睿)
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料

Python爬虫连载1-urllib.request和chardet包使用方式的更多相关文章
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- 【学习笔记】第二章 python安全编程基础---python爬虫基础(urllib)
一.爬虫基础 1.爬虫概念 网络爬虫(又称为网页蜘蛛),是一种按照一定的规则,自动地抓取万维网信息的程序或脚本.用爬虫最大的好出是批量且自动化得获取和处理信息.对于宏观或微观的情况都可以多一个侧面去了 ...
- Python爬虫基础之Urllib
一.随时随地爬取一个网页下来 怎么爬取网页?对网站开发了解的都知道,浏览器访问Url向服务器发送请求,服务器响应浏览器请求并返回一堆HTML信息,其中包括html标签,css样式,js脚本等.Chro ...
- PYTHON 爬虫笔记二:Urllib库基本使用
知识点一:urllib的详解及基本使用方法 一.基本介绍 urllib是python的一个获取url(Uniform Resource Locators,统一资源定址器)了,我们可以利用它来抓取远程的 ...
- Python爬虫实践~BeautifulSoup+urllib+Flask实现静态网页的爬取
爬取的网站类型: 论坛类网站类型 涉及主要的第三方模块: BeautifulSoup:解析.遍历页面 urllib:处理URL请求 Flask:简易的WEB框架 介绍: 本次主要使用urllib获取网 ...
- Python爬虫连载2-reponse\parse简介
一.reponse解析 urlopen的返回对象 (1)geturl:返回网页地址 (2)info:请求反馈对象的meta信息 (3)getcode:返回的http code from urllib ...
- python爬虫起步...开发环境搭建,最简单的方式
研究一门编程语言,一般第一步就是配置安装部署相关的编程环境.我认为啊,在学习的初期,大家不是十分了解相关的环境,或者是jar包,python模块等的相关内容,就不需要花费大量的时间去研究如何去安装它. ...
- Python爬虫连载3-Post解析、Request类
一.访问网络的两种方法 1.get:利用参数给服务器传递信息:参数为dict,然后parse解码 2.post:一般向服务器传递参数使用:post是把信息自动加密处理:如果想要使用post信息,需要使 ...
随机推荐
- 010、MySQL日期时间戳转化为文本日期时间
#时间戳转化文本时间 SELECT from_unixtime( unix_timestamp( curdate( ) ) ); #时间戳转化文本时间格式化 SELECT from_unixtime( ...
- flutter安装中的一些方法
1.配置flutter环境变量 进入终端 vim ~/.bash_profile export ANDROID_HOME=~Library/Android/sdk export PATH=$PATH: ...
- Golang函数-函数的基本概念
Golang函数-函数的基本概念 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.函数的概述 1>.函数定义语法格式 Go语言函数定义格式如下: func 函数名( 函数参 ...
- UVA - 10891 Game of Sum (区间dp)
题意:AB两人分别拿一列n个数字,只能从左端或右端拿,不能同时从两端拿,可拿一个或多个,问在两人尽可能多拿的情况下,A最多比B多拿多少. 分析: 1.枚举先手拿的分界线,要么从左端拿,要么从右端拿,比 ...
- netty权威指南学习笔记六——编解码技术之MessagePack
编解码技术主要应用在网络传输中,将对象比如BOJO进行编解码以利于网络中进行传输.平常我们也会将编解码说成是序列化/反序列化 定义:当进行远程跨进程服务调用时,需要把被传输的java对象编码为字节数组 ...
- MFC中修改光标形状
修改光标形状,如果是修改系统内光标形状,那就很简单了,直接是用::SetCursor(::LoadCursor(NULL,MAKEINTRESOURCE(IDC_CURSOR1)))就可以修改成功了, ...
- hashCode equals hashSet
基于hash的map也是这种机制. HashSet import java.util.HashSet; import java.util.Set; import java.util.TreeSet; ...
- Spark 2.x Troubleshooting Guide
IBM在spark summit上分享的内容,包括编译spark源码,运行spark时候常见问题(缺包.OOM.GC问题.hdfs数据分布不均匀等),spark任务堆/thread dump 目录 编 ...
- 前端第一篇---前端基础之HTML内容
前端基础之HTML内容 阅读目录(Content) 一.HTML初识 1.web服务本质 2.HTML是什么 3.HTML不是什么 二.HTML文档结构 三.HTML标签格式 四.HTML注释 五.H ...
- springboot启动项目报错:ERROR:o.s.b.d.LoggingFailureAnalysisReporter解决办法
原因是引入了spring security的依赖,将spring security对应的依赖删除即可. 具体可参照: https://blog.csdn.net/qq_37887131/article ...