Spark 广播变量 和 累加器
1. 广播变量
理解图
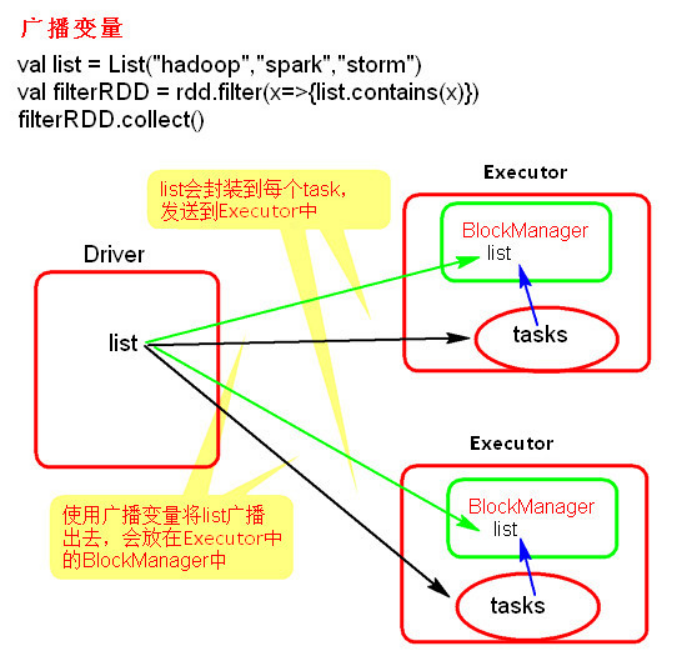
使用示例
# word.txt
hello scala
hello python
hello java
hello go
hello julia
hello C++
hello lucenepackage com.ronnie.scala.core.Test import org.apache.spark.broadcast.Broadcast
import org.apache.spark.{SparkConf, SparkContext} object BroadCastTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("broadcast")
val sc = new SparkContext(conf)
val list: Seq[String] = List("hello scala")
val broadCast: Broadcast[Seq[String]] = sc.broadcast(list)
val lineRDD = sc.textFile("./resources/word.txt") lineRDD.filter(x => {
val list = broadCast.value
list.contains(x)
}).foreach(println)
}
}
源码
package org.apache.spark.broadcast import java.io.Serializable import scala.reflect.ClassTag import org.apache.spark.SparkException
import org.apache.spark.internal.Logging
import org.apache.spark.util.Utils /**
* A broadcast variable. Broadcast variables allow the programmer to keep a read-only * variable cached on each machine rather than shipping a copy of it with tasks.
* 一个广播变量。 这些广播变量允许程序员在每台机器上维持一个只读的缓存的变量, 而不是将该变量和它一起拷贝。
* They can be used, for example, to give every node a copy of a large input dataset * in an efficient manner.
* 这些广播变量可用于把一个巨大的传入数据集的副本以一种有效地方式发送给每个节点
*
* Spark also attempts to distribute broadcast variables using efficient broadcast
* algorithms to reduce communication cost.
* Spark 尝试以高效的广播算法 来 分发 广播变量 且 减少通讯开销
*
* Broadcast variables are created from a variable `v` by calling
* [[org.apache.spark.SparkContext#broadcast]].
* 广播变量由 一个变量'v' 通过调用 SparkContext中的broadcast参数 产生
*
* The broadcast variable is a wrapper around `v`, and its value can be accessed by
* calling the `value` method. The interpreter session below shows this:
* 该广播变量是一个基于 变量 'v' 的 包装, 并且它的值可以通过 调用 value
* 方法来获取。解释程序会话表现如下(scala命令行)
*
* {{{
* scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
* broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
*
* scala> broadcastVar.value
* res0: Array[Int] = Array(1, 2, 3)
* }}}
*
* After the broadcast variable is created, it should be used instead of the value
* `v` in any functions run on the cluster so that `v` is not shipped to the nodes
* more than once.
* 在广播变量被创建之后, 它应当被使用而不是 将 变量 'v' 以任何方式运行在集群上, 所以 变量
* 'v' 并没有被装载到节点上多次
*
* In addition, the object `v` should not be modified after it is broadcast in order * to ensure that all nodes get the same value of the broadcast variable (e.g. if the * variable is shipped to a new node later).
* 此外, 在 对象 'v'已经被广播之后, 它不应当再被修改 以 确保 所有的节点都能获得相同的广播变量值
*
* @param id A unique identifier for the broadcast variable.
* @tparam T Type of the data contained in the broadcast variable.
*/
abstract class Broadcast[T: ClassTag](val id: Long) extends Serializable with Logging { /**
* Flag signifying whether the broadcast variable is valid
* 标记了 该广播变量是否有效的标签
* (that is, not already destroyed) or not.
*/
@volatile private var _isValid = true // 破坏的位置
private var _destroySite = "" /** Get the broadcasted value. 获取被广播的值*/
def value: T = {
assertValid()
getValue()
} /**
* Asynchronously delete cached copies of this broadcast on the executors.
* 异步删除 在 executor进程上 缓存的 广播
* If the broadcast is used after this is called, it will need to be re-sent to
* each executor.
* 如果该广播在这次被调用之前已经被使用过了, 它需要被重新发送到每个 executor进程
*/
// 去持久化
def unpersist() {
unpersist(blocking = false)
} /**
* Delete cached copies of this broadcast on the executors.
* 在 executor进程上删除缓存的 当前 广播
* If the broadcast is used after this is called, it will need to be re-sent to
* each executor.
* 如果该广播在这次被调用之前已经被使用过了, 它需要被重新发送到每个 executor进程
* @param blocking Whether to block until unpersisting has completed
* blocking 代表了是否阻塞到在去持久化完成 的标签
*/
def unpersist(blocking: Boolean) {
assertValid()
doUnpersist(blocking)
} /**
* Destroy all data and metadata related to this broadcast variable. Use this with * caution;
* 破坏所有的与该广播变量相关的数据与元数据 使用这个指令要小心(rm -rf/* 2.0?)
* once a broadcast variable has been destroyed, it cannot be used again.
* 一个单一个广播变量被破坏了, 它就不能再被使用了
* This method blocks until destroy has completed
* 该方法会阻塞到 破坏 执行完成
*/
def destroy() {
destroy(blocking = true)
} /**
* Destroy all data and metadata related to this broadcast variable. Use this with * caution;
* 破坏所有的与该广播变量相关的数据与元数据 使用这个指令要小心
* once a broadcast variable has been destroyed, it cannot be used again.
* 一个单一个广播变量被破坏了, 它就不能再被使用了
* @param blocking Whether to block until destroy has completed
* blocking: 是否阻塞到 破坏 执行完成的标签
*/
private[spark] def destroy(blocking: Boolean) {
assertValid()
_isValid = false
_destroySite = Utils.getCallSite().shortForm
logInfo("Destroying %s (from %s)".format(toString, _destroySite))
doDestroy(blocking)
} /**
* Whether this Broadcast is actually usable. This should be false once persisted
* state is removed from the driver.
* 判断此广播是否需实际上可以被使用, 一旦持久状态从这个driver中被移除, 就应该为false
*/
private[spark] def isValid: Boolean = {
_isValid
} /**
* Actually get the broadcasted value. Concrete implementations of Broadcast class * must define their own way to get the value.
* 真实的获取 被广播的值。 要落实广播类的应用必须要定义他们自己的方式来获取值
*/
protected def getValue(): T /**
* Actually unpersist the broadcasted value on the executors.
* 真实的将executor进程上的被广播的值去持久化
* Concrete implementations of Broadcast class must define their own logic to
* unpersist their own data.
* 要落实广播类的应用必须要定义他们自己的逻辑来将他们自己的数据去持久化
*/
protected def doUnpersist(blocking: Boolean) /**
* Actually destroy all data and metadata related to this broadcast variable.
* 真实的破坏所有 与 这个广播变量相关的 数据 和 元数据
* Implementation of Broadcast class must define their own logic to destroy their
* ownstate.
* 要落实广播类的应用必须要定义他们自己的逻辑来破坏他们自己的状态
*/
protected def doDestroy(blocking: Boolean) /** Check if this broadcast is valid. If not valid, exception is thrown.
* 检查这个广播是否是有效的。 如果无效, 就抛出异常
*/
protected def assertValid() {
if (!_isValid) {
throw new SparkException(
"Attempted to use %s after it was destroyed (%s) ".format(toString, _destroySite))
}
} override def toString: String = "Broadcast(" + id + ")"
}
注意事项
广播变量只能在 Driver 端定义, 不能在 Executor 端定义
在 Driver 端可以修改广播变量的值, 在 Executor 端无法修改广播变量的值
2. 累加器
理解图
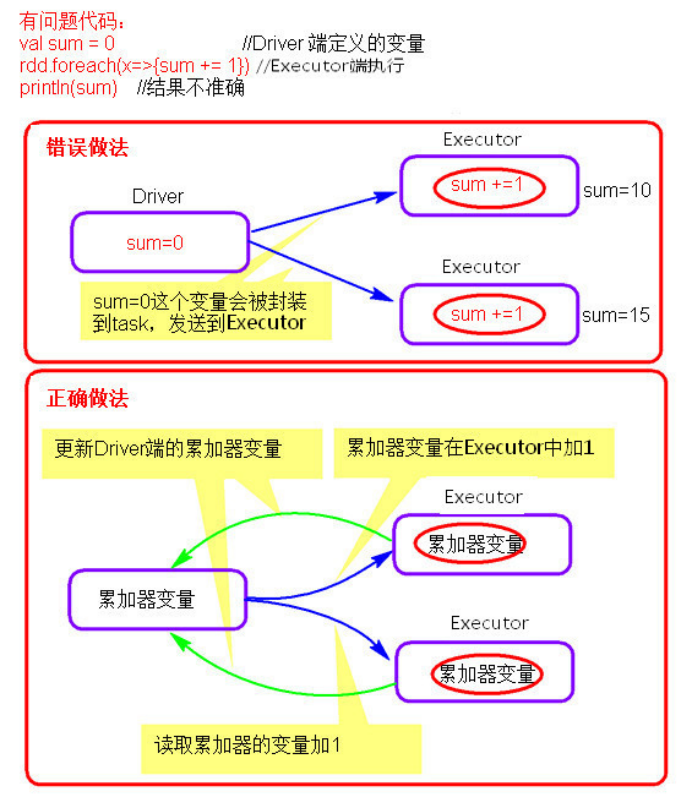
使用示例
源码
/**
* An [[AccumulatorV2 accumulator]] for computing sum, count, and average of 64-bit
* integers.
* 一个 基于 AccumulatorV2 类的 用于计算和, 计数 和 获取 64 bit int 平均数的累加器
*
* @since 2.0.0
*/
class LongAccumulator extends AccumulatorV2[jl.Long, jl.Long] {
// 总和
private var _sum = 0L
// 计数
private var _count = 0L /**
* Returns false if this accumulator has had any values added to it or the sum is
* non-zero.
* 如果有任何值被添加到这个累加器中, 或者 sum 为非0, 就返回 false
* @since 2.0.0
*/
override def isZero: Boolean = _sum == 0L && _count == 0 // 创建了新对象, 深拷贝
override def copy(): LongAccumulator = {
val newAcc = new LongAccumulator
newAcc._count = this._count
newAcc._sum = this._sum
newAcc
} // 重设(都初始化为0)
override def reset(): Unit = {
_sum = 0L
_count = 0L
} /**
* Adds v to the accumulator, i.e. increment sum by v and count by 1.
* 添加 v 到 累加器, sum = sum + v, count = count + 1
* @since 2.0.0
*/
override def add(v: jl.Long): Unit = {
_sum += v
_count += 1
} /**
* Adds v to the accumulator, i.e. increment sum by v and count by 1.
* @since 2.0.0
*/
def add(v: Long): Unit = {
_sum += v
_count += 1
} /**
* Returns the number of elements added to the accumulator.
* 返回 添加到累加器的元素的数量
* @since 2.0.0
*/
def count: Long = _count /**
* Returns the sum of elements added to the accumulator.
* 返回 添加到累加器元素的和
* @since 2.0.0
*/
def sum: Long = _sum /**
* Returns the average of elements added to the accumulator.
* 返回添加到累加器中的元素的平均值
* @since 2.0.0
*/
def avg: Double = _sum.toDouble / _count // 合并累加器
override def merge(other: AccumulatorV2[jl.Long, jl.Long]): Unit = other match {
// 如果类型相同, 就合并 sum 和 count
case o: LongAccumulator =>
_sum += o.sum
_count += o.count
// 如果不同, 就抛出异常
case _ =>
throw new UnsupportedOperationException(
s"Cannot merge ${this.getClass.getName} with ${other.getClass.getName}")
} private[spark] def setValue(newValue: Long): Unit = _sum = newValue override def value: jl.Long = _sum
}
注意事项
累加器在 Driver 端定义赋初始值
累加器只能在 Driver 端读取, 在 Executor端更新
Spark 广播变量 和 累加器的更多相关文章
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- 【Spark-core学习之七】 Spark广播变量、累加器
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Spark广播变量和累加器
一.广播变量图解 二.代码 val conf = new SparkConf() conf.setMaster("local").setAppName("brocast& ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark--DataFrames,RDD,DataSets 一.弹性数据集(RDD) 创建RDD 1.1RDD的宽依赖和窄依赖 二.DataFrames 三.DataSets 四.什么时候使用Dat ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- 广播变量、累加器、collect
广播变量.累加器.collect spark集群由两类集群构成:一个驱动程序,多个执行程序. 1.广播变量 broadcast 广播变量为只读变量,它由运行sparkContext的驱动程序创建后发送 ...
- spark 广播变量
Spark广播变量 使用广播变量来优化,广播变量的原理是: 在每一个Executor中保存一份全局变量,task在执行的时候需要使用和这一份变量就可以,极大的减少了Executor的内存开销. Exe ...
随机推荐
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- day14-Python运维开发基础(内置函数、pickle序列化模块、math数学模块)
1. 内置函数 # ### 内置函数 # abs 绝对值函数 res = abs(-10) print(res) # round 四舍五入 (n.5 n为偶数则舍去 n.5 n为奇数,则进一!) 奇进 ...
- 在线配置raid
Exit Code: 0x00 rpm -ivh MegaCli-8.07.14-1.noarch.rpm ls /opt/MegaRAID/MegaCli//opt/MegaRAID/MegaCli ...
- java中将图片上传到配置好的ftp服务器上
测试用例: @Test public void testFtp() throws Exception { //1.连接ftp服务器 FTPClient ftpClient = new FTPClien ...
- Day3-O-Median POJ3579
Given N numbers, X1, X2, ... , XN, let us calculate the difference of every pair of numbers: ∣Xi - X ...
- Python数据分析在互联网寒冬下,数据分析师还吃香吗?
伴随着移动互联网的飞速发展,越来越多用户被互联网连接在一起,用户所积累下来的数据越来越多,市场对数据方面人才的需求也越来越大,由此也带火了如数据分析.数据挖掘.算法等职业,而作为其中入门门槛相对较低. ...
- IOS TableView 用法
1.在视图上创建TableView( 拖控件),为ViewController创建UITableView属性(链接至TableView)和NSArray属性(存储数据) ViewController. ...
- spark on yarn container分配极端倾斜
环境:CDH5.13.3 spark2.3 在提交任务之后,发现executor运行少量几台nodemanager,而其他nodemanager没有executor分配. 测试环境通过spark-s ...
- 南邮CG-CTF Web记录
MYSQL(利用精度,传参为小数) robots.txt中的代码: <?php if($_GET[id]) { mysql_connect(SAE_MYSQL_HOST_M . ':' . SA ...
- arm linux 移植 PHP
背景: PHP 是世界上最好的语言. host平台 :Ubuntu 16.04 arm平台 : 3531d arm-gcc :4.9.4 php :7.1.30 zlib :1.2.11 libxml ...