python 爬取36kr 7x24h快讯
url为https://36kr.com/newsflashes,抓包后发现第一次的新闻内容就是包含在<script>var props={}></script>标签中,具体的是在props中的key为newsflashList|newsflash的列表中紧着我又让页面多加载了一些,发现此时请求地址有了些变化,此时返回的内容是json字符串了
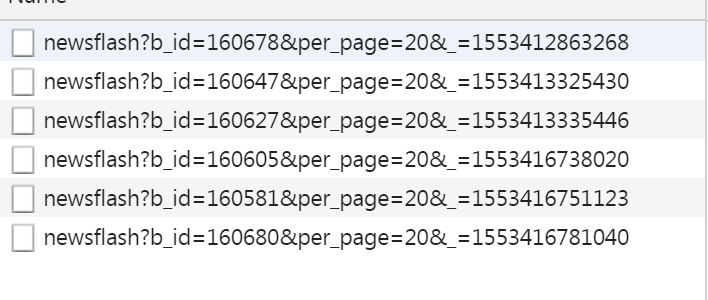
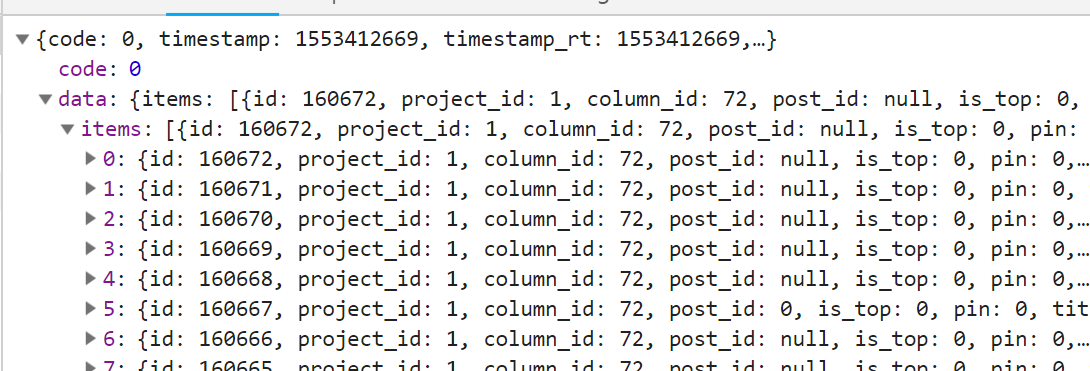
仔细研究下请求中的bid其实和返回的items中的最后一个id是相同的,这意味着我们可以第一次请求https://36kr.com/newsflashes,解析其中的props标签,然后获得最后一个id,接下来构造新的url时就可以采用形如https://36kr.com/api/newsflash?b_id=160678&per_page=20&_=1553412863268格式的地址了,测试发现只需要https://36kr.com/api/newsflash?b_id=160678&per_page=20就可以了,这个地址其实是多了层"api",测试时发现构造这种https://36kr.com/newsflashes?b_id=160680&per_page=20这个地址没有那层"api",所以返回的也是html,解析props标签同样可以获得数据
好了,综上我们有了两种思路,第一种是请求https://36kr.com/newsflashes,正则解析props.然后获得id,构造返回值为json字符串的url,第二种也是请求https://36kr.com/newsflashes,解析props.然后获得id,
构造返回html内容的url,之后也是使用正则解析props标签,但实际测试时这种效率有点低,因为大规模的使用了正则匹配,
所以我使用了第一种方式,此外使用第一种方式我们可以指定per_page,虽然过大容易被封IP
# -*- coding: utf-8 -*-
# @author: Tele
# @Time : 2019/3/24 0024 下午 12:56
import re
import json
import requests
import os
from pprint import pprint class NewsFlashesSplider:
def __init__(self):
# "https://36kr.com/newsflashes?b_id={}&per_page=20"
self.url = "https://36kr.com/newsflashes"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
self.file_dir = "./newsflashes.txt" def parse_url(self):
response = requests.get(self.url, headers=self.headers)
ret = json.loads(response.content.decode())["data"]["items"] print(ret) size = len(ret)
last_id = int(ret[size - 1]["id"])
with open(self.file_dir, "a", encoding="utf-8") as file:
file.write(json.dumps(ret, ensure_ascii=False))
file.write("\r\n")
return size, last_id def run(self):
if os.path.exists(self.file_dir):
os.remove(self.file_dir)
print("文件已清空") # 第一次请求获得当前最新的新闻
response = requests.get(self.url, headers=self.headers)
result = re.compile("<script>var props=(.*),locationnal=").findall(response.content.decode())
ret = json.loads(result[0])["newsflashList|newsflash"] # 新闻个数,最后一个id
tuple_result = len(ret), int(ret[len(ret) - 1]["id"]) while True:
self.url = "https://36kr.com/api/newsflash?b_id={}&per_page=20".format(tuple_result[1])
tuple_result = self.parse_url()
if tuple_result[0] < 20:
break def main():
splider = NewsFlashesSplider()
splider.run() if __name__ == '__main__':
main()
python 爬取36kr 7x24h快讯的更多相关文章
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
随机推荐
- Docker---(2)为什么要用Docker
原文:Docker---(2)为什么要用Docker 版权声明:欢迎转载,请标明出处,如有问题,欢迎指正!谢谢!微信:w1186355422 https://blog.csdn.net/weixin_ ...
- BZOJ——3343: 教主的魔法 || 洛谷—— P2801 教主的魔法
http://www.lydsy.com/JudgeOnline/problem.php?id=3343 || https://www.luogu.org/problem/show?pid=280 ...
- nginx源代码分析--事件模块 & 琐碎
通过HUP信息使得NGINX实现又一次读取配置文件,使用USR2信号使得NGINX实现平滑升级. 在nginx中有模块这么一说,对外全部的模块都是ngx_module_t类型,这个结构体作为全部模块的 ...
- Python 实用第三方库
1. youtube 视频下载 使用:you-get pip install you-get you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
- EularProject 41:最长的n位Pandigital素数问题
Pandigital prime Problem 41 We shall say that an n-digit number is pandigital if it makes use of all ...
- 算法 Tricks(三)—— 数组(序列)任意区间最小(大)值
序列(数组)的区间通过左右端点确定,这样首先设置一个最值变量用来记录最值,从左端点一步步移动到右端点,自然移动的过程中也可以计算整个区间的和,也即一次线性遍历下来,可同时获得多个有用信息. // 区间 ...
- 第三方插件将数据转成json
1.需要使用第三方jar commons-beanutils-1.7.0.jar /commons-collections-3.1.jar/commons-lang-2.5jar /commons-l ...
- vue指令应用--实现输入框常见过滤功能
前端开发最常碰到的就是输入框,经常要做各种验证,本公司惯用的需求是直接屏蔽特定字符的输入,如禁止非数字输入,特殊符号输入,空格输入等,这些功能反复使用,做成指令的形式,直接调用,非常方便,上代码: 目 ...
- [Nuxt] Use Vuex Actions to Delete Data from APIs in Nuxt and Vue.js
You'll begin to notice as you build out your actions in Vuex, many of them will look quite similar. ...
- cocos2d-x 3.0 android mk文件 之 自己主动遍历*.cpp文件
还记得上一篇android mk 文件的写法吗?传送门, 我们须要手动去加入 cpp文件.假设cpp一多,那不是要累死? LOCAL_PATH := $(call my-dir) include $( ...