mongodb之集群模式
前言
数据量大了或者并发量上来了,单机肯定是抗不住的,这个时候要开始考虑使用集群了。mongodb目前为止支持三种集群模式:主从集群,副本集集群,分片集群。
主从集群
特性
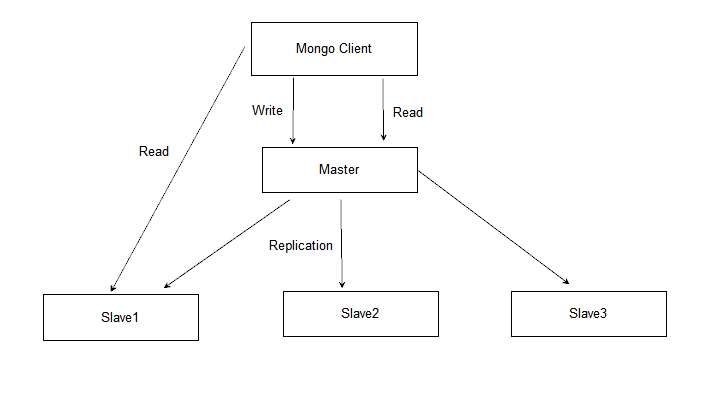
1. 一主多从
2. 主负责读写
3. 从负责读
4. 从通过异步同步主op日志同步主数据
5. 主挂无法自动恢复
架构图
实践
规划
一主两从
ip端口配置
主节点:127.0.0.1:27021
从节点1:127.0.0.1:27022
从节点2:127.0.0.1:27023
启动主节点
su -s /bin/bash -c "/usr/bin/mongod --master -f /etc/mongodb/27021.conf" mongod
启动从节点
su -s /bin/bash -c "/usr/bin/mongod --slave --source 127.0.0.1:27021 -f /etc/mongodb/27022.conf" mongod
su -s /bin/bash -c "/usr/bin/mongod --slave --source 127.0.0.1:27021 -f /etc/mongodb/27023.conf" mongod
设置从节点可用
use admin
rs.slaveOk()
查看是否主节点
use admin
rs.isMaster()
查看主节点复制状态信息
use admin
rs.printReplicationInfo()
查看从节点复制状态信息
use admin
rs.printSlaveReplicationInfo()
replica set集群
特性
1. n个不同类型节点组成
2. 每个节点数据相同
3. 建议至少有一个primary和两个secondary节点
4. 集群中只能有一个primary节点
5. 写请求都通过primary节点
6. 支持自动故障恢复
7. primary节点不可用时,通过投票选举从secondary节点列表中选出primary节点,因此最好节点数量是奇数
8. secondary节点从primary节点通过oplog异步方式同步数据
节点类型
primary
主节点,负责集群数据维护,所有数据更新操作都通过主节点
secondary
从节点,从主节点复制数据,提供读请求响应
arbiter
选举节点,不保存数据,只参与primary投票选举
架构图

节点属性说明
priority: 0 表示不是候选人,可以投票
hidden:true 对用户端不可见,不可见的节点priority必须设置为0
votes: 1 投票权限 0表示不能投票
实践
规划
搭建3个节点的集群,一个primary,两个secondary
ip和端口配置
host1: 127.0.0.1:27018
host2: 127.0.0.1:27019
host3: 127.0.0.1:27020
集群名: replSetTest0
启动3个事例
单个实例的配置
#系统日志配置
systemLog:
destination: file
path: /var/log/mongodb/mongod_27018.log
logAppend: true
#quiet模式运行,建议设置为false,方便排查错误
quiet: false #进程管理
processManagement:
#进程后台运行
fork: true
#进程pid文件
pidFilePath: /var/log/mongodb/mongod_27018.pid #网络配置
net:
#监听端口
port: 27018
#监听网卡 多个使用英文逗号隔开
bindIp: 127.0.0.1
#最大并发连接数 默认65535
maxIncomingConnections: 65535
#验证客户端传过来的数据,文档嵌套多时,对性能会有些影响
wireObjectCheck: true
#是否启用ipv6,默认不启用
ipv6: false
unixDomainSocket:
#是否启用socket监听 默认true
enabled: true
#socket保存目录,默认/tmp
pathPrefix: /var/log/mongodb
#socket文件权限,默认0700
filePermissions: 0700
http:
#是否启用http服务,默认false,安全考虑线上环境要关闭
enabled: false
#是否启用http jsonp,默认false,即使http.enabled为false,只要此项为true,一样可以访问,安全考虑线上环境要关闭
JSONPEnabled: false
#是否启用rest api接口,默认false,安全考虑线上环境要关闭
RESTInterfaceEnabled: false
compression:
#是否启用数据压缩
compressors: snappy #安全配置
security:
#type:string
#密钥路径,副本集和分片集群节点间授权时使用的密钥
keyFile: /var/log/mongodb/.replSetTest0Key #type:string
#集群授权模式,默认keyFile,值列表:keyFile,sendKeyFile,sendX509,x509
clusterAuthMode: keyFile #type:string
#是否开启数据库访问RBAC权限控制,默认:disabled,仅对mongod命令有效
authorization: enabled #type:boolean
#是否开启服端js执行,默认true,如果未开启$where,group,mapreduce都不能使用
javascriptEnabled: true #存储配置
storage:
#type:string
#数据库数据存储目录,默认/data/db
dbPath: /data/mongodb/27018 #type:boolean
#启动时是否尝试重建索引,默认true
indexBuildRetry: true #journal日志
journal:
#type:boolean
#Enable or disable the durability journal to ensure data files remain valid and recoverable.
enabled: true #type:int
#日志同步间隔,Values can range from 1 to 500 milliseconds.
commitIntervalMs: 100 #type:boolean
#是否开启一数据库一目录,默认是false
directoryPerDB: false #type:int
#数据落地时间间隔,默认为60秒,不能设置为0,一般使用默认值即可
syncPeriodSecs: 60 #type:string
##存储引擎,默认wiredTiger,可选值 mmapv1,wiredTiger,inMemory
engine: wiredTiger wiredTiger:
engineConfig:
#type:float
#单个实例可用的数据缓存内存大小,version >= 3.4默认:50% of RAM minus 1 GB, or 256 MB.
cacheSizeGB: 0.25 #type:string
#WiredTiger journal数据压缩格式,默认snappy,可用的压缩类型: none, snappy, zlib
journalCompressor: snappy #type:boolean
#索引文件分目录存储,默认false,version >= 3.0后版本可用
directoryForIndexes: false
collectionConfig:
#type:string
#块数据压缩格式,默认snappy,可用的压缩类型:none, snappy, zlib
blockCompressor: snappy
indexConfig:
#type:boolean
#是否开启索引prefix compression,默认true
prefixCompression: true #是否开启索引prefix compression,默认true #operationProfiling操作性能分析
operationProfiling:
#type:int
#慢查询时间单位毫秒,默认100,如果开启了profile,日志会保存到system.profile集合中
slowOpThresholdMs: 100 #type:string
#性能分析模式,开启会影响性能,谨慎操作。默认off.
#可选值1:off: Off. No profiling.
#可选值2: slowOp:On. Only includes slow operations.
#可选值3: all:On. Includes all operations.
mode: slowOp #replication复制配置
replication:
#type:int
#数字类型(单位M) replication op log 大小,64位系统默认为可用磁盘的5%
oplogSizeMB: 512 #type:string
#所属replica set集群名称
replSetName: replSetTest0 #setParameter配置
setParameter:
enableLocalhostAuthBypass: false
启动
su -s /bin/bash -c "/usr/bin/mongod -f /etc/mongodb/27018.conf" mongod
su -s /bin/bash -c "/usr/bin/mongod -f /etc/mongodb/27019.conf" mongod
su -s /bin/bash -c "/usr/bin/mongod -f /etc/mongodb/27020.conf" mongod
mongod -f /etc/mongodb/27018.conf --shutdown
集群初始化
mongo --port 27018
rs.initiate(
{
_id: "replSetTest0",
version: 1,
members: [
{ _id: 0, host : "127.0.0.1:27018" },
{ _id: 1, host : "127.0.0.1:27019" },
{ _id: 2, host : "127.0.0.1:27020" }
]
}
)
设置从节点可用
mongo --port 27018(填写实际的从节点地址)
rs.slaveOk()
查看集群状态
mongo --port 27018
rs.status()
查看是否primary节点
mongo --port 27018
rs.isMaster()
查看集群配置
mongo --port 27018
rs.conf()
添加节点
mongo 主节点地址
rs.add({} | host地址)
删除节点
mongo 主节点地址
删除前,建议先停止这个节点的服务
rs.remove(hostname)
更改集群配置
mongo 主节点地址
rs.reconfig({},{})
分片集群
选定一个或多个key,按照选定的key进行数据分割,分割后的数据分别保存在不同的mongodb副本集中,这个是分片的基本思路。
分片思路可以水平扩展机器,根据业务需要扩展任意多的机器。读写压力分散到集群不同的机器中。
架构图
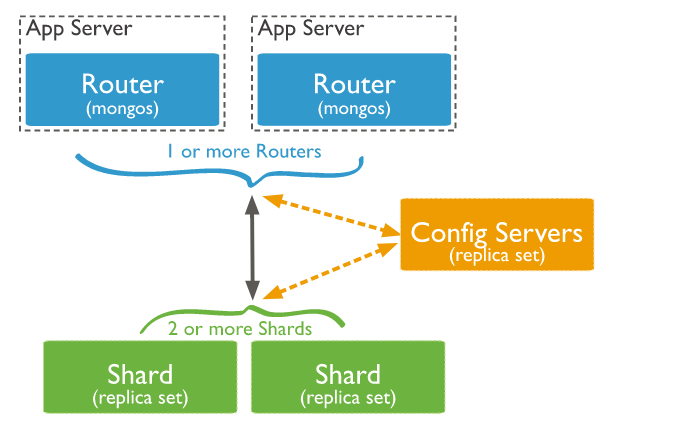
组件
配置server
副本集集群,分片信息,用户授权信息,配置信息等都保存在这里
分片server
单个独立的mongod实例或者副本集集群,存放真实的数据
路由server
处理客户端连接请求,路由到存放数据的分片server,合并分片server的数据,返回给客户端
分片策略
支持类型
哈希分片
对分片key使用某种哈希算法,根据哈希值确定数据插入哪个分片server中
特点
数据离散性好,能均匀分布在不同的分片server中
不适合根据范围查询的情况
范围分片
对分片key的值通过范围确定存储的分片server
特点
数据离散性可能不好,可能会造成热点数据在某个分片server中
适合范围查询的情况
限制
分片key确定后不能更改
分片key必须设置索引,如果不是,设置分片key时,mongod会自动创建
原则
1. 选择值多样性的key,尽可能分散,避免数据文档集中到某些分片server中
2. 考虑以后是否会数据分组,数据分组时分组key需要是分片key或者分片组合key的前缀
3. 选择合适的分片类型,不同的分片类型适用的场景不一样
4. 当必须选择值重复频率高的key时,可以考虑选择组合key
实践
规划
考虑到只是实践使用,配置server副本集只用一台,分片server副本集也只用一台
1台配置server: 127.0.0.1:27024(副本集集群,集群名:shardClusterCfgServerReplSet0)
1台路由server: 127.0.0.1:27025
2台分片server:127.0.0.1:27026(副本集集群,集群名:shardClusterShardServerReplSet0),127.0.0.1:27027(副本集集群,集群名:shardClusterShardServerReplSet1)
启动配置server
sharding:
clusterRole: configsvr
replication:
replSetName: shardClusterCfgServerReplSet0 su -s /bin/bash -c "/usr/bin/mongod -f /etc/mongodb/27024.conf" mongod rs.initiate(
{
_id: "shardClusterCfgServerReplSet0",
configsvr: true,
members: [
{ _id : 0, host : "127.0.0.1:27024" }
]
}
)
启动分片server
sharding:
clusterRole: shardsvr
replication:
replSetName: shardClusterShardServerReplSet0 su -s /bin/bash -c "/usr/bin/mongod -f /etc/mongodb/27026.conf" mongod
su -s /bin/bash -c "/usr/bin/mongod -f /etc/mongodb/27027.conf" mongod rs.initiate(
{
_id: "shardClusterShardServerReplSet1",
members: [
{ _id : 0, host : "127.0.0.1:27027" }
]
}
)
启动路由server
su -s /bin/bash -c "/usr/bin/mongos -f /etc/mongodb/27025.conf" mongod
增加或者移除分片最好停服操作,减少数据不一致的可能性
使用配置server用户登录mongos进行操作
#系统日志配置
systemLog:
destination: file
path: /var/log/mongodb/mongod_27025.log
logAppend: true
#quiet模式运行,建议设置为false,方便排查错误
quiet: false #进程管理
processManagement:
#进程后台运行
fork: true
#进程pid文件
pidFilePath: /var/log/mongodb/mongod_27025.pid #网络配置
net:
#监听端口
port: 27025
#监听网卡 多个使用英文逗号隔开
bindIp: 127.0.0.1
#最大并发连接数 默认65535
maxIncomingConnections: 65535
#验证客户端传过来的数据,文档嵌套多时,对性能会有些影响
wireObjectCheck: true
#是否启用ipv6,默认不启用
ipv6: false
unixDomainSocket:
#是否启用socket监听 默认true
enabled: true
#socket保存目录,默认/tmp
pathPrefix: /var/log/mongodb
#socket文件权限,默认0700
filePermissions: 0700
http:
#是否启用http服务,默认false,安全考虑线上环境要关闭
enabled: false
compression:
#是否启用数据压缩
compressors: snappy #安全配置
security:
#type:string
#密钥路径,副本集和分片集群节点间授权时使用的密钥
keyFile: /var/log/mongodb/.replSetTest0Key #type:string
#集群授权模式,默认keyFile,值列表:keyFile,sendKeyFile,sendX509,x509
clusterAuthMode: keyFile #setParameter配置
setParameter:
enableLocalhostAuthBypass: false #分片配置
sharding:
#type:string
#配置server,多个使用英文逗号分开
configDB: shardClusterCfgServerReplSet0/127.0.0.1:27024
添加分片server
添加分片操作会触发数据迁移,迁移过程中对数据库性能会有些影响
sh.addShard("shardClusterShardServerReplSet0/127.0.0.1:27026")
sh.addShard("shardClusterShardServerReplSet1/127.0.0.1:27027")
开启数据库分片
sh.enableSharding("test")
设置集合分片key
sh.shardCollection("test.people",{_id:1})
移除分片server
移除分片server前需要先迁移分区数据到其它分片,为了保证整个集群性能,迁移过程中会占用比较小的资源,网络带宽和数据量大小会影响迁移时间,
可能需要几分钟到几天不等
移除步骤
step1 确定迁移进程开启
sh.getBalancerState()
返回true表示开启
step2 确定需要删除分片的名字
db.adminCommand( { listShards : 1 } )
_id字段值为分片名称
step3 迁移分片数据到其它分片
db.adminCommand({removeShard:"shardClusterShardServerReplSet1"})
{
"msg" : "draining started successfully",
"state" : "started",
"shard" : "shardClusterShardServerReplSet1",
"note" : "you need to drop or movePrimary these databases",
"dbsToMove" : [
"test"
],
"ok" : 1
}
step4 查看迁移状态
db.adminCommand({removeShard:"shardClusterShardServerReplSet1"})
{
"msg" : "draining ongoing",
"state" : "ongoing",
"remaining" : {
"chunks" : NumberLong(0),
"dbs" : NumberLong(1)
},
"note" : "you need to drop or movePrimary these databases",
"dbsToMove" : [
"test"
],
"ok" : 1
}
step5 迁移未分片的数据
分片数据迁移完成后执行
返回的状态列表字段remaining.chunks为0时表示迁移完成
如果没有未分片的数据库,不需要执行这个步骤
返回的状态列表有一个字段dbsToMove,这个字段的内容为需要迁移的未分片的数据库,不为空时需要执行迁移操作
use admin
db.runCommand({movePrimary:"test", to:"shardClusterShardServerReplSet0"})
db.runCommand({flushRouterConfig:1})
step6 数据迁移完成确认
前面步骤都执行完成后执行
db.adminCommand({removeShard:"shardClusterShardServerReplSet1"})
{
"msg" : "removeshard completed successfully",
"state" : "completed",
"shard" : "shardClusterShardServerReplSet1",
"ok" : 1
}
集群相关操作
连接mongos
mongo --host mongos_host --port mongos_port
查看状态
sh.status()
显示开启分区的数据库
use config
db.databases.find({partitioned:true})
显示分片server列表
db.adminCommand( { listShards : 1 } )
查看数据迁移进程状态
sh.getBalancerState()
备注
1. 第一次初始化时禁用权限判断,添加好用户之后再开启
2. 增删改只能在主节点操作
3. 集群使用的密码不能超过1K且只能是base64编码字符集
4. keyFile文件权限不能开放给所在组成员和其他组成员
5. 生成随机密码:openssl rand -base64 741
参考资料
【1】Replication
https://docs.mongodb.com/manual/replication/
【2】Read Preference
https://docs.mongodb.com/manual/core/read-preference/
【3】Replica Set Members
https://docs.mongodb.com/manual/core/replica-set-members/
【4】Replica Set Elections
https://docs.mongodb.com/manual/core/replica-set-elections/
【5】Replica Set Data Synchronization
https://docs.mongodb.com/manual/core/replica-set-sync/
【6】Replica Set Oplog
https://docs.mongodb.com/manual/core/replica-set-oplog/
【7】Replica Set Deployment Architectures
https://docs.mongodb.com/manual/core/replica-set-architectures/
【8】Mongo Shell - Replication Methods
https://docs.mongodb.com/manual/reference/method/js-replication/
【9】Deploy a Replica Set
https://docs.mongodb.com/manual/tutorial/deploy-replica-set/
【10】Replica Set Configuration
https://docs.mongodb.com/manual/reference/replica-configuration/
【11】Rollbacks During Replica Set Failover
https://docs.mongodb.com/manual/core/replica-set-rollbacks/
【12】Change the Size of the Oplog
https://docs.mongodb.com/manual/tutorial/change-oplog-size/
【13】Resync a Member of a Replica Set
https://docs.mongodb.com/manual/tutorial/resync-replica-set-member/
【14】Replication Reference
https://docs.mongodb.com/manual/reference/replication/
【15】Write Concern
https://docs.mongodb.com/manual/reference/write-concern/
【16】Read Isolation, Consistency, and Recency
https://docs.mongodb.com/manual/core/read-isolation-consistency-recency/
【17】Master Slave Replication
https://docs.mongodb.com/manual/core/master-slave/
【18】分片集群
https://docs.mongodb.com/manual/sharding/
【19】分片-区域
https://docs.mongodb.com/manual/core/zone-sharding/
【20】分片-参考
https://docs.mongodb.com/manual/reference/sharding/
【21】分片-管理
https://docs.mongodb.com/manual/administration/sharded-cluster-administration/
【22】分片-均衡
https://docs.mongodb.com/manual/core/sharding-balancer-administration/
【23】分片-组件
https://docs.mongodb.com/manual/core/sharded-cluster-components/
mongodb之集群模式的更多相关文章
- MongoDB的集群模式--Sharding(分片)
分片是数据跨多台机器存储,MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署. 具有大型数据集或高吞吐量应用程序的数据库系统可能会挑战单个服务器的容量.例如,高查询率会耗尽服务器的CP ...
- MongoDB的集群模式--Replica Set
一.Replica Set 集群分为两种架构: 奇数个节点构成Replica Set,所有节点拥有数据集.最小架构: 1个Primary节点,2个Secondary节点 偶数个节点 + 一个仲裁节点 ...
- elasticsearch与mongodb分布式集群环境下数据同步
1.ElasticSearch是什么 ElasticSearch 是一个基于Lucene构建的开源.分布式,RESTful搜索引擎.它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索 ...
- zookeeer 集群和伪集群模式
环境变量设置: # .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi # U ...
- mongodb分片集群
第一章 1.mongodb 分片集群解释和目的 一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合.复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础. 第二章 1. ...
- mongodb分布式集群搭建手记
一.架构简介 目标单机搭建mongodb分布式集群(副本集 + 分片集群),演示mongodb分布式集群的安装部署.简单操作. 说明在同一个vm启动由两个分片组成的分布式集群,每个分片都是一个PSS( ...
- 网易云MongoDB分片集群(Sharding)服务已上线
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. MongoDB sharding cluster(分片集群)是MongoDB提供的数据在线水平扩展方案,包括 ...
- CentOS7+Docker+MangoDB下部署简单的MongoDB分片集群
简单的在Docker上快速部署MongoDB分片集群 前言 文中使用的环境如下 OS:CentOS Linux release 7.5.1804 (Core) Docker:Docker versio ...
- MongoDB(7):集群部署实践,包含复制集,分片
注: 刚开始学习MongoDB,写的有点麻烦了,网上教程都是很少的代码就完成了集群的部署, 纯属个人实践,错误之处望指正!有好的建议和资料请联系我QQ:1176479642 集群架构: 2mongos ...
随机推荐
- Python机器学习算法 — K-Means聚类
K-Means简介 步,直到每个簇的中心基本不再变化: 6)将结果输出. K-Means的说明 如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示: (a)刚开始时是原始数据,杂乱无章 ...
- [Swift通天遁地]五、高级扩展-(8)ImageView(图像视图)的各种扩展方法
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★➤微信公众号:山青咏芝(shanqingyongzhi)➤博客园地址:山青咏芝(https://www.cnblogs. ...
- 安科 OJ 1054 排队买票 (递归,排列组合)
时间限制:1 s 空间限制:128 M 题目描述 有M个小孩到公园玩,门票是1元.其中N个小孩带的钱为1元,K个小孩带的钱为2元.售票员没有零钱,问这些小孩共有多少种排队方法,使得售票员总能找得开零钱 ...
- Java转大数据开发全套视频资料
大数据在近两年可算是特别火,有很多人都想去学大数据,有java转大数据的,零基础学习大数据的.但是大数据真的好学吗. 我们先来了解一下什么是大数据. 大数据是指无法在一定时间内用常规软件工具对其内容进 ...
- 推荐给Web前端开发人员的一些书籍(从基础到架构阶段)
有很多人问我说作为一个前端开发人员都需要看一些什么书籍,尤其是刚入门的新手,今天我整理了一下推荐给大家,大佬绕过. HTML+CSS+JavaScript 网页设计 从入门到精通 作为一个前端新手,强 ...
- fastjson读取json配置文件
fastjson读取json配置文件: ClassLoader loader=FileUtil.class.getClassLoader(); InputStream stream=loader.ge ...
- Unity Android交互过坑指南
Unity Android交互过坑指南 介于网上看过很多unity和Android交互的教程,都或多或少的漏掉了一些部分,导致编译过程中出现各种问题,特此整理一份教程,仅供参考 介绍 本次实现的是在游 ...
- VMWare 安装Ubuntu 16.04
1.新建虚拟机 (1)点击文件-->新建虚拟机 (2)选择 自定义(高级)--> 下一步 (3)选择Workstation 12.0 --> 下一步 (4)选择 稍后安装操作系统 - ...
- linux shell & bash
shell & bash shell指允许用户通过文本操作计算机的程序. interactive shell:从是否通过标准输入输出与用户进行交互的角度分为交互式shell(interacti ...
- C# WinForm窗体应用(第四天)
一.点击登录按钮,将两个窗体进行连接,并进行用户名和密码验证. /// <summary> /// 登录设置 /// </summary> /// <param name ...