Python的主成分分析PCA算法
这篇文章很不错:https://blog.csdn.net/u013082989/article/details/53792010
为什么数据处理之前要进行归一化???(这个一直不明白)
这个也很不错:https://blog.csdn.net/u013082989/article/details/53792010#commentsedit
下面是复现一个例子:
# -*- coding: utf-8 -*-
#来源:https://blog.csdn.net/u013082989/article/details/53792010
#来源:https://blog.csdn.net/hustqb/article/details/78394058 (这里有个例子)关于降维之后的坐标系问题,???结合里面的例子
#用库函数实现的过程:
#导入需要的包:
import numpy as np
from matplotlib import pyplot as plt
from scipy import io as spio
from sklearn.decomposition import pca
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
#归一化数据,并作图
def scaler(X):
"""
注:这里的归一化是按照列进行的。也就是把每个特征都标准化,就是去除了单位的影响。
"""
scaler=StandardScaler()
scaler.fit(X)
x_train=scaler.transform(X)
return x_train
#使用pca模型拟合数据并降维n_components对应要降的维度
def jiangwei_pca(x_train,K): #传入的是X的矩阵和主成分的个数K
model=pca.PCA(n_components=K).fit(x_train)
Z=model.transform(x_train) #transform就会执行降维操作
#数据恢复,model.components_会得到降维使用的U矩阵
Ureduce=model.components_
x_rec=np.dot(Z,Ureduce) #数据恢复
return Z,x_rec #这里Z是将为之后的数据,x_rec是恢复之后的数据。
if __name__ == '__main__':
X=np.array([[1,1],[1,3],[2,3],[4,4],[2,4]])
x_train=scaler(X)
print('x_train:',x_train)
Z,x_rec=jiangwei_pca(x_train,2)
print("Z:",Z)
print("x_rec:",x_rec) #如果有时候,这里不能够重新恢复x_train,一个原因可能是主成分太少。
print("x_train:",x_train)
## 这里的主成分为什么不是原来的两个。
## 还有一个问题是,如何用图像表现出来。
## 还有一个问题就是如何得到系数,这个系数是每个特征在主成分中的贡献,要做这个就需要看矩阵,弄明白原理:
或许和这个程序有关:pca.explained_variance_ratio_
摘自:https://blog.csdn.net/qq_36523839/article/details/82558636
这里提一点:pca的方法explained_variance_ratio_计算了每个特征方差贡献率,所有总和为1,explained_variance_为方差值,通过合理使用这两个参数可以画出方差贡献率图或者方差值图,便于观察PCA降维最佳值。
在提醒一点:pca中的参数选项可以对数据做SVD与归一化处理很方便,但是需要先考虑是否需要这样做。
关于pca的一个推导例子:

、、
根据最后的图形显示来看,一共有五个样本点。而从下面的矩阵看,似乎不是这样???
有点纠结。
从对矩阵X的求均值过程可以知道,是对行求均值的。然后每行减掉均值。
(这样的话,也就是说:每一行是一个特征???,就不太明白了。)
应该写成这样比较清楚:(每一列是一个特性)
[
[1,1]
[1,3]
[2,3]
[4,4]
[2,4]
]
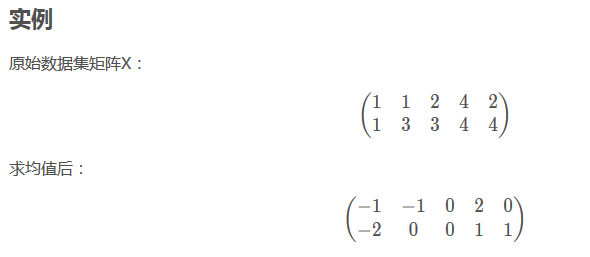
、、
从下面看出这里除的是5,也就是说5是m,也就是行数。???
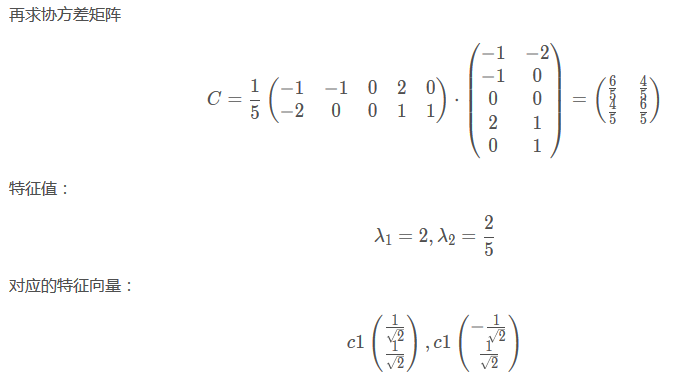
、、
最后降维到一个特征::
下面图片中P的部分,是两个数,也就是两个特征的系数。代表着特征的系数。。。
关键是用的别人的库,但是怎么弄???

、、
上面
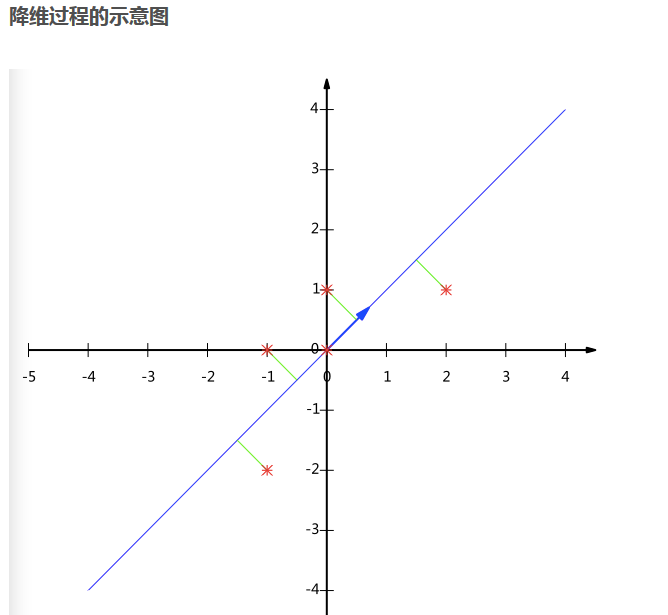
#、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
下面我们来分析另一个例子:这个例子是官方给出的:
程序如下:
# -*- coding: utf-8 -*-
"""
测试
这里是Python的pca主成分分析的一个测试程序
"""
import numpy as np
from sklearn.decomposition import PCA
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
pca = PCA(n_components='mle') #这里是让机器决定主成分的个数,我们也可以自行设置。
pca = PCA(n_components=2) #这里设置主成分为,这里不能设置成3,因为这里的特征本身只有两个。
pca.fit(X)
print("这里是X:")
print(X)
Z=pca.transform(X) #transform就会执行降维操作
print('这里是Z:')
print(Z)
# Z = np.dot(X, self.components_.T)
# PCA(copy=True, n_components=2, whiten=False)
print(pca.explained_variance_ratio_)
然后运行程序输出的结果:
这里是X:
[[-1 -1]
[-2 -1]
[-3 -2]
[ 1 1]
[ 2 1]
[ 3 2]]
可能是系数的东西: 这里有可能是没个主成分中包含各个特征的权重系数。
你有没有感觉到这个矩阵有一定的特性,有点对角线对称的样子。
[[-0.83849224 0.54491354]
[-0.54491354 -0.83849224]]
这里是Z: 这里的Z实际上主成分的意思。主成分也就是综合特征
[[ 1.38340578 0.2935787 ]
[ 2.22189802 -0.25133484]
[ 3.6053038 0.04224385]
[-1.38340578 -0.2935787 ]
[-2.22189802 0.25133484]
[-3.6053038 -0.04224385]]
[0.99244289 0.00755711]
要捋清一个问题,我们想要得到的是什么?
我们想要得到的是每个主成分前面包含特征的系数。
主成分1=权重11*特征1+权重12*特征2+权重13*特征3···
主成分2=权重21*特征1+权重22*特征2+权重23*特征3···
[[-0.83849224 0.54491354]
[-0.54491354 -0.83849224]]
主成分1=(-0.83849224) *特征1+(-0.54491354)*特征2···
主成分2=(0.54491354) *特征1+(-0.83849224)*特征2···
就是上面这种系数,
我还是有一点疑问?为什么?这个系数矩阵是对称的,这样有点不是很科学??
Python的主成分分析PCA算法的更多相关文章
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- 主成分分析 PCA算法原理
对同一个体进行多项观察时,必定涉及多个随机变量X1,X2,…,Xp,它们都是的相关性, 一时难以综合.这时就需要借助主成分分析 (principal component analysis)来概括诸多信 ...
- 三种方法实现PCA算法(Python)
主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域.它的主要作用是对高维数据进行降维.PCA把原先的n个特征用数目 ...
- Python使用三种方法实现PCA算法[转]
主成分分析(PCA) vs 多元判别式分析(MDA) PCA和MDA都是线性变换的方法,二者关系密切.在PCA中,我们寻找数据集中最大化方差的成分,在MDA中,我们对类间最大散布的方向更感兴趣. 一句 ...
- python实现PCA算法原理
PCA主成分分析法的数据主成分分析过程及python原理实现 1.对于主成分分析法,在求得第一主成分之后,如果需要求取下一个主成分,则需要将原来数据把第一主成分去掉以后再求取新的数据X’的第一主成分, ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- 主成分分析 —PCA
一.定义 主成分分析(principal components analysis)是一种无监督的降维算法,一般在应用其他算法前使用,广泛应用于数据预处理中.其在保证损失少量信息的前提下,把多个指标转化 ...
- 如何用Python实现常见机器学习算法-1
最近在GitHub上学习了有关python实现常见机器学习算法 目录 一.线性回归 1.代价函数 2.梯度下降算法 3.均值归一化 4.最终运行结果 5.使用scikit-learn库中的线性模型实现 ...
随机推荐
- excel操作小技巧
excel拼接sql语句时,时间格式问题 问题:若直接插入时间的单元格 :="insert into t_entity_car (create_time,name,age) value (' ...
- Smart Pointer Guidelines
For Developers > Smart Pointer Guidelines What are smart pointers? Smart pointers are a specif ...
- Idea下mybatis的错误—Module not specified
IDEA下使用maven的mybatis常见错误 错误类型一:导入项目引起的错误Module not specified 错误提示:idea Error Module not specified. 错 ...
- pip版本及升级 pip安装指定模板
昨天在微信聊天,一妹子9点的时候告诉我她要看书了,让明天聊,瞬间自己心中那颗学习的种子燃烧起来,思来想去还是继续学习自己之前未学好的python吧,因为之前有了点点的python基础,所以本次打算从p ...
- 【C/C++】链表的理解与使用
转载自:http://blog.csdn.NET/xubin341719/article/details/7091583/ 最近不是太忙,整理些东西,工作也许用得到. 1,为什么要用到链表 数组作为存 ...
- CentOS下安装.net core环境并部署WebAPI
1.安装CentOS 7 2.安装.net Core 2环境,参考官方文档:(建议采用SDK (tar.gz)安装) https://www.microsoft.com/net/download/li ...
- 保留原先小程序名称 更改微信小程序主体
首先给小程序开发者普及一些官方消息: 1.目前官方是不允许修改已经认证的小程序主体信息!(公众号可以修改) 2.小程序与公众号的名称是全平台唯一,即如果小程序叫‘ABC’其他小程序和公众号就不能存在‘ ...
- php 内置的 html 格式化/美化tidy函数 -- 让你的HTML更美观
php 内置的 html 格式化/美化tidy函数 https://github.com/htacg/tidy-html5 # HTML 格式化 function beautify_html($htm ...
- 3.索引与string进行映射实现高效查找
#include <iostream> #include <typeindex>//类型索引 #include <unordered_map>//红黑树 #incl ...
- 突破极限 解决大硬盘上安装Unix新思路
一.问题提出 硬盘越做越大,然我喜欢让我忧.10年前就遇到过在586电脑BIOS不认识超过8.4G容量硬盘的问题,以及Windows Nt操作系统不认大硬盘(容量超过8.4G)的问题,对于Linux ...