memcached缓存分布式部署方案
一、分布式方案介绍
比较流行的两种方案:
1.取余分布:
计算key的哈希值,与服务器数量取余,得到目标服务器。优点:实现简单,当某台服务器不可用时,故障转移方便;缺点:当增减服务器时, Key与服务器取余变动量较大,缓存重组代价极大。
代码实现可参考开源组件Memcached.ClientLibrary下的SockIOPool,源码地址:
https://sourceforge.net/p/memcacheddotnet/code/HEAD/tree/trunk/clientlib/src/clientlib/SockIOPool.cs
2.一致性哈希环分布:
其原理参考
https://www.cnblogs.com/lpfuture/p/5796398.html
http://www.zsythink.net/archives/1182
这两位老哥写的很清楚和直白,很容易理解。
一致性哈希环分布需要物理节点和虚拟节点,且虚拟节点对应到物理节点的服务器上。
二、代码实现
由于Memcached.ClientLibrary的作者已出取余分布的实现,这里不再叙述,以下代码和测试均是一致性哈希分布的。
1.数据结构:
服务器列表:List<string> servers;//IP:PORT
服务器虚拟节点数:List<int> weights;//与servers一一对应,灵活设置每server的不同虚拟节点数
节点存储结构:SortedDictionary<long, String> buckets;
Key:long类型,存储节点的hash%2^32;
Value:String类型,存储节点,即IP:PORT;
2.代码
计算哈希值算法,参考Memcached.ClientLibrary下的SockIOPool:
https://sourceforge.net/p/memcacheddotnet/code/HEAD/tree/trunk/clientlib/src/clientlib/SockIOPool.cs
private int CalculateHashValue(String key)
{
int hv;
switch (_hashingAlgorithm)
{
case EnumHashingAlgorithm.Native:
hv = key.GetHashCode();
break;
case EnumHashingAlgorithm.OldCompatibleHash:
hv = HashingAlgorithmTool.OriginalHashingAlgorithm(key);
break;
case EnumHashingAlgorithm.NewCompatibleHash:
hv = HashingAlgorithmTool.NewHashingAlgorithm(key);
break;
default:
// use the native hash as a default
hv = key.GetHashCode();
_hashingAlgorithm = EnumHashingAlgorithm.Native;
break;
}
return hv;
}
经过测试,OldCompatibleHash方式计算的哈希值比较散列。
//哈希取余值,为什么是2的32次方:IPV4的总量是2的32次方个,可以保证环上的IP不重复
long HashValue = (long)Math.Pow(, );
将Key生成一致性哈希环中的哈希值
private long GenerateConsistentHashValue(String key)
{
long serverHV = CalculateHashValue(key);
long mod = serverHV % HashValue;
if (mod < )
{
mod = mod + HashValue;
}
return mod;
}
将Servers生成节点(物理+虚拟):
private void GenerateServersToBuckets()
{
for (int i = ; i < _servers.Count; i++)
{
// 创建物理节点
String server = _servers[i];
long mod = GenerateConsistentHashValue(server);
buckets.Add(mod, server);
//创建虚拟节点
List<String> virtualHostServers = GenerateVirtualServer(server, this.Weights[i]);
foreach (String v in virtualHostServers)
{
mod = GenerateConsistentHashValue(v);
buckets.Add(mod, server);
}
}
}
根据物理节点生成虚拟节点
private static List<String> GenerateVirtualServer(String server, int count)
{
if (count > )
{
throw new ArgumentException("每服务器虚拟节点数不能超过254");
}
List<String> virtualServers = new List<string>(); #region 1.按修改IP值+随机GUID生成虚拟节点
String[] ipaddr = server.Split(':');
String ip = ipaddr[];
string port = ipaddr[];
int header = Convert.ToInt32(ip.Split('.')[]);
String invariantIPPart = ip.Substring(ip.IndexOf('.'));
int succ = ;
for (int i = ; i <= ; i++)
{
if (i != header)
{
String virtualServer = i.ToString() + invariantIPPart + ":" + port + i;// Guid.NewGuid().ToString("N").ToUpper();
virtualServers.Add(virtualServer);
succ++;
}
if (succ == count)
{
break;
}
}
#endregion #region 2.物理节点自增序号||随机GUID
//for (int i = 0; i < count; i++)
//{
// //virtualServers.Add(server + i.ToString());
// virtualServers.Add(server + i.ToString()+Guid.NewGuid().ToString());
//}
#endregion #region 32.其它生成算法
//TODO
#endregion return virtualServers;
}
三、节点分布测试
四台服务器:{ "192.168.1.100:11211", "192.168.1.101:11211", "192.168.1.102:11211", "192.168.1.103:11211" }
哈希算法不同,则节点分布规则不同
1.物理节点分布
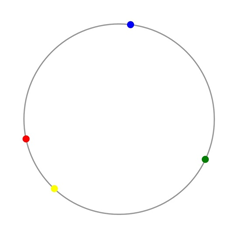
2.每物理节点10虚拟节点

节点分布测试结果:
节点数共有(物理4+虚拟4*10):44
在第一个节点和第二个节点间:
服务器A的虚拟节点数:1 占比:10%
服务器B的虚拟节点数:1 占比:10%
服务器C的虚拟节点数:0 占比:0%
服务器D的虚拟节点数:2 占比:20%
在第二个节点和第三个节点间:
服务器A的虚拟节点数:0 占比:0%
服务器B的虚拟节点数:0 占比:0%
服务器C的虚拟节点数:2 占比:20%
服务器D的虚拟节点数:2 占比:20%
在第三个节点和第四个节点间:
服务器A的虚拟节点数:4 占比:40%
服务器B的虚拟节点数:5 占比:50%
服务器C的虚拟节点数:4 占比:40%
服务器D的虚拟节点数:4 占比:40%
在第四个节点和第一个节点间:
服务器A的虚拟节点数:5 占比:50%
服务器B的虚拟节点数:4 占比:40%
服务器C的虚拟节点数:4 占比:40%
服务器D的虚拟节点数:2 占比:20%
3.每物理节点30虚拟节点

节点分布测试结果:
节点数共有(物理4+虚拟4*30):124
在第一个节点和第二个节点间:
服务器A的虚拟节点数:7 占比:23%
服务器B的虚拟节点数:7 占比:23%
服务器C的虚拟节点数:6 占比:20%
服务器D的虚拟节点数:7 占比:23%
在第二个节点和第三个节点间:
服务器A的虚拟节点数:3 占比:10%
服务器B的虚拟节点数:1 占比:3%
服务器C的虚拟节点数:4 占比:13%
服务器D的虚拟节点数:4 占比:13%
在第三个节点和第四个节点间:
服务器A的虚拟节点数:11 占比:36%
服务器B的虚拟节点数:11 占比:36%
服务器C的虚拟节点数:10 占比:33%
服务器D的虚拟节点数:10 占比:33%
在第四个节点和第一个节点间:
服务器A的虚拟节点数:9 占比:30%
服务器B的虚拟节点数:11 占比:36%
服务器C的虚拟节点数:10 占比:33%
服务器D的虚拟节点数:9 占比:30%
4. 每物理节点50虚拟节点:.
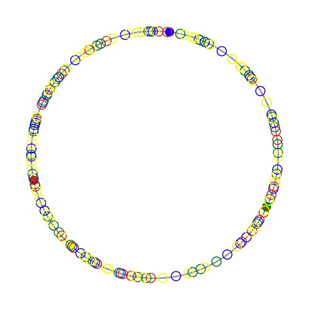
节点分布测试结果:
节点数共有(物理4+虚拟4*50):204
在第一个节点和第二个节点间:
服务器A的虚拟节点数:14 占比:28%
服务器B的虚拟节点数:13 占比:26%
服务器C的虚拟节点数:12 占比:24%
服务器D的虚拟节点数:13 占比:26%
在第二个节点和第三个节点间:
服务器A的虚拟节点数:4 占比:8%
服务器B的虚拟节点数:3 占比:6%
服务器C的虚拟节点数:5 占比:10%
服务器D的虚拟节点数:7 占比:14%
在第三个节点和第四个节点间:
服务器A的虚拟节点数:17 占比:34%
服务器B的虚拟节点数:18 占比:36%
服务器C的虚拟节点数:16 占比:32%
服务器D的虚拟节点数:16 占比:32%
在第四个节点和第一个节点间:
服务器A的虚拟节点数:15 占比:30%
服务器B的虚拟节点数:16 占比:32%
服务器C的虚拟节点数:17 占比:34%
服务器D的虚拟节点数:14 占比:28%
5. 每物理节点80虚拟节点

节点分布测试结果:
节点数共有(物理4+虚拟4*80):324
在第一个节点和第二个节点间:
服务器A的虚拟节点数:22 占比:27%
服务器B的虚拟节点数:23 占比:28%
服务器C的虚拟节点数:21 占比:26%
服务器D的虚拟节点数:22 占比:27%
在第二个节点和第三个节点间:
服务器A的虚拟节点数:7 占比:8%
服务器B的虚拟节点数:5 占比:6%
服务器C的虚拟节点数:9 占比:11%
服务器D的虚拟节点数:10 占比:12%
在第三个节点和第四个节点间:
服务器A的虚拟节点数:27 占比:33%
服务器B的虚拟节点数:27 占比:33%
服务器C的虚拟节点数:25 占比:31%
服务器D的虚拟节点数:24 占比:30%
在第四个节点和第一个节点间:
服务器A的虚拟节点数:24 占比:30%
服务器B的虚拟节点数:25 占比:31%
服务器C的虚拟节点数:25 占比:31%
服务器D的虚拟节点数:24 占比:30%
6. 每物理节点100虚拟节点

节点分布测试结果:
节点数共有(物理4+虚拟4*100):404
在第一个节点和第二个节点间:
服务器A的虚拟节点数:29 占比:29%
服务器B的虚拟节点数:30 占比:30%
服务器C的虚拟节点数:28 占比:28%
服务器D的虚拟节点数:28 占比:28%
在第二个节点和第三个节点间:
服务器A的虚拟节点数:8 占比:8%
服务器B的虚拟节点数:8 占比:8%
服务器C的虚拟节点数:11 占比:11%
服务器D的虚拟节点数:12 占比:12%
在第三个节点和第四个节点间:
服务器A的虚拟节点数:33 占比:33%
服务器B的虚拟节点数:32 占比:32%
服务器C的虚拟节点数:30 占比:30%
服务器D的虚拟节点数:30 占比:30%
在第四个节点和第一个节点间:
服务器A的虚拟节点数:30 占比:30%
服务器B的虚拟节点数:30 占比:30%
服务器C的虚拟节点数:31 占比:31%
服务器D的虚拟节点数:30 占比:30%
说明:由于统计计算时按int取值,服务器虚拟节点比率总和可能有1的误差。
总结:以上可以看出当总节点在300以上时,各物理节点之间的虚拟节点所占比率变化较小,说明分布比较均匀。
四、存取数据查找服务器
原理:根据数据的Key与HashValue取余值hv,查找buckets中Key>=hv的第一个服务器,即是Key的目标服务器,当返回的服务器不可用时,还可以进行故障转移
1.从节点环中查找服务器
private String FindServer(String key, ref long startIndex)
{
long mod = startIndex;
if (mod < )
{
mod = GenerateConsistentHashValue(key);
}
foreach (KeyValuePair<long, String> kvp in buckets)
{
startIndex = kvp.Key;
//找到第一个大于或等于key的服务器
if (kvp.Key >= mod)
{
//若找到的服务器不可用,则继续查找下一服务器
if (_hostDead.ContainsKey(kvp.Value))
{
continue;
}
return kvp.Value;
}
}
//如果大于mod的服务器均不可用或没有找到,则从头开始找可用服务器
foreach (KeyValuePair<long, String> kvp in buckets)
{
startIndex = kvp.Key;
if (kvp.Key >= mod)
{
break;
}
if (_hostDead.ContainsKey(kvp.Value))
{
continue;
}
return kvp.Value;
}
//不存在可用服务器
return string.Empty;
}
2.获取服务器及连接
public ISockIO GetSock(string key)
{
if (buckets.Count == )
{
return null;
} if (buckets.Count == )
{
return GetConnection(buckets[]);
} long startIndex = -;//开始查找位置,-1表示从hash(key)% HashValue位置开始查找
int tries = ;//重试次数,不超过总服务器数
while (tries++ <= this.servers.Count)
{
String server = FindServer(key, ref startIndex);
//找不到可用的服务器
if (String.IsNullOrEmpty(server))
{
return null;
}
ISockIO sock = GetConnection(server);
if (sock != null)
{
WriteLog.Write("key:" + key + ",server:" + server);
return sock;
}
//是否需要故障转移,若需要,则会继续查找可用的服务器
if (!_failover)
{
return null;
}
}
return null;
}
memcached缓存分布式部署方案的更多相关文章
- Memcached常规应用与分布式部署方案
1.Memcached常规应用 $mc = new Memcache(); $mc->conncet('127.0.0.1', 11211); $sql = sprintf("SELE ...
- Window Redis分布式部署方案 java
Redis分布式部署方案 Window 1. 基本介绍 首先redis官方是没有提供window下的版本, 是window配合发布的.因现阶段项目需求,所以研究部署的是window版本的,其实都 ...
- Linux-Memcache分布式部署方案(magent代理解决单点故障)
Memcached的特点 Memcached作为高速运行的分布式缓存服务器具有以下特点. 1. 协议简单:memcached的服务器客户端通信并不使用复杂的MXL等格式, 而是使用简单的基于文本的协议 ...
- Memcache分布式部署方案
基础环境 其实基于PHP扩展的Memcache客户端实际上早已经实现,而且非常稳定.先解释一些名词,Memcache是danga.com的一个开源项目,可以类比于MySQL这样的服务,而PHP扩展的M ...
- zookeeper分布式部署方案
版本:http://apache.fayea.com/zookeeper/zookeeper-3.4.8/环境:debian 7/8说明:最低配置3台步骤:1.下载zookeeper-3.4.8并解压 ...
- 一文读懂 Redis 分布式部署方案
为什么要分布式 Redis是一款开源的基于内存的K-V型数据库,因为内存访问速度快,一般被用来做系统的缓存. Redis作为单机部署能够支持业务简单,数据量不大的系统需求,但在实际应用中,一旦系统规模 ...
- 矢量切片应用中geoserver与geowebcache分布式部署方案
在进行GIS项目开发中,常使用Geoserver作为开源的地图服务器,Geoserver是一个JavaEE项目,常通过Tomcat进行部署.而GeoWebCache是一个采用Java实现用于缓存WMS ...
- Redis集群的分布式部署
3.2.2:Redis Cluster: Redis 分布式部署方案: 1) 客户端分区:由客户端程序决定 key 写分配和写入的 redis node,但是需要客户端自己处理写入 分配.高可用管 ...
- 项目分布式部署那些事(2):基于OCS(Memcached)的Session共享方案
在不久之前发布了一篇"项目分布式部署那些事(1):ONS消息队列.基于Redis的Session共享,开源共享",因为一些问题我们使用了阿里云的OCS,下面就来简单的介绍和分享下相 ...
随机推荐
- leetcode: Maximum Depth of Binary Tree
Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the long ...
- 关于命令行签名时.SF和.RSA文件的命名问题
准备工作: 签名文件名称为android.keystore 签名的别名为123456789.keystore 1.使用签名命令后例如以下图 发现.SF和.RSA文件自己主动命名为12345678.SF ...
- js---10作用域链
<html> <head> <title>scope basic</title> </head> <body> <scri ...
- 60.浅谈nodejs中的Crypto模块
转自:https://www.cnblogs.com/c-and-unity/articles/4552059.html node.js的crypto在0.8版本并没有改版多少,这个模块的主要功能是加 ...
- ActionListener三种实现
/** * Simple1.java - 处理事件的第一种方法 * 在这个例子中,利用一个ActionListener来监听事件源产生的事件 * 用一些if语句来决定是哪个事件源 */ import ...
- 【hdu 6038】Function
[Link]:http://codeforces.com/contest/834/problem/C [Description] 给你两个排列a和b; a排列的长度为n,b排列的长度为m; a∈[0. ...
- VC多线程临界区
在使用多线程时,一般非常少有多个线程全然独立的工作.往往是多个线程同一时候操作一个全局变量来获取程序的执行结果.多个线程同一时候訪问同一个全局变量,假设都是读取操作,则不会出现故障. 假设是写操作,则 ...
- POJ--2516--Minimum Cost【最小费用最大流】
链接:http://poj.org/problem?id=2516 题意:有k种货物,n个客户对每种货物有一定需求量,有m个仓库.每一个仓库里有一定数量的k种货物.然后k个n*m的矩阵,告诉从各个仓库 ...
- java——简单理解线程
一·[概念] 一般来说,我们把正在计算机中运行的程序叫做"进程"(process),而不将其称为"程序"(program). 所谓"线程& ...
- BASH 文本模版的简单实现 micro_template_compile
详细代码 ############################### # # Funciton: micro_template_compile # # Parameter: # [1] => ...