(数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平方误差,当样本数据中出现了不合理的极端值,会导致最终聚类结果产生一定的误差,而本篇将要介绍的K-medoids(中心点)聚类法在削弱异常值的影响上就有着其过人之处。
与K-means算法类似,区别在于中心点的选取,K-means中选取的中心点为当前类中所有点的重心,而K-medoids法选取的中心点为当前cluster中存在的一点,准则函数是当前cluster中所有其他点到该中心点的距离之和最小,这就在一定程度上削弱了异常值的影响,但缺点是计算较为复杂,耗费的计算机时间比K-means多。
具体的算法流程如下:
1.在总体n个样本点中任意选取k个点作为medoids
2.按照与medoids最近的原则,将剩余的n-k个点分配到当前最佳的medoids代表的类中
3.对于第i个类中除对应medoids点外的所有其他点,按顺序计算当其为新的medoids时,准则函数的值,遍历所有可能,选取准则函数最小时对应的点作为新的medoids
4.重复2-3的过程,直到所有的medoids点不再发生变化或已达到设定的最大迭代次数
5.产出最终确定的k个类
而在R中有内置的pam()函数来进行K-medoids聚类,下面我们对人为添加脏数据的样本数据集分别利用K-medoids和K-means进行聚类,以各自的代价函数变化情况作为评判结果质量的标准:
rm(list=ls())
library(Rtsne)
library(cluster)
library(RColorBrewer)
data1 <- matrix(rnorm(10000,mean=0,sd=0.7),ncol=10,nrow=1000)
data2 <- matrix(rnorm(10000,mean=8,sd=0.7),ncol=10,nrow=1000)
data3 <- matrix(rnorm(10000,mean=16,sd=0.7),ncol=10,nrow=1000)
data4 <- matrix(rnorm(200,mean=100,sd=0.5),ncol=10,nrow=20)
data <- rbind(data1,data2,data3,data4) #数据降维
tsne <- Rtsne(data,check_duplicates = FALSE)
cols <- sample(brewer.pal(n=7,name='Set1'),7) #自定义代价函数计算函数
Mycost <- function(data,medoids){
l <- length(data[,1])
d <- matrix(0,nrow=l,ncol=length(medoids[,1]))
for(i in 1:l){
for(j in 1:length(medoids[,1])){
dist <- 0
for(k in 1:length(medoids[1,])){
dist <- dist + (data[i,k]-medoids[j,k])^2
}
d[i,j] <- dist
}
}
return(sum(apply(d,1,min)))
} par(mfrow=c(2,3))
#进行K-medoids聚类
cost <- c()
for(i in 2:7){
cl <- pam(data,k=i)
plot(tsne$Y,col=cols[cl$clustering])
title(paste(paste('K-medoids Cluster of',as.character(i)),'Clusters'))
cost[i-1] <- Mycost(data,cl$medoids)
} par(mfrow=c(1,1))
plot(2:7,cost,type='o',xlab='k',ylab='Cost')
title('Cost Change of K-medoids') #进行K-means聚类
cost <- c()
par(mfrow=c(2,3))
for(i in 2:7){
cl <- kmeans(data,centers=i)
plot(tsne$Y,col=cols[cl$cluster])
title(paste(paste('K-means Cluster of',as.character(i)),'Clusters'))
cost[i-1] <- Mycost(data,cl$centers)
}
par(mfrow=c(1,1))
plot(2:7,cost,type='o',xlab='k',ylab='Cost')
title('Cost Change of K-means')
K-medoids的聚类结果(基于不同的k值):
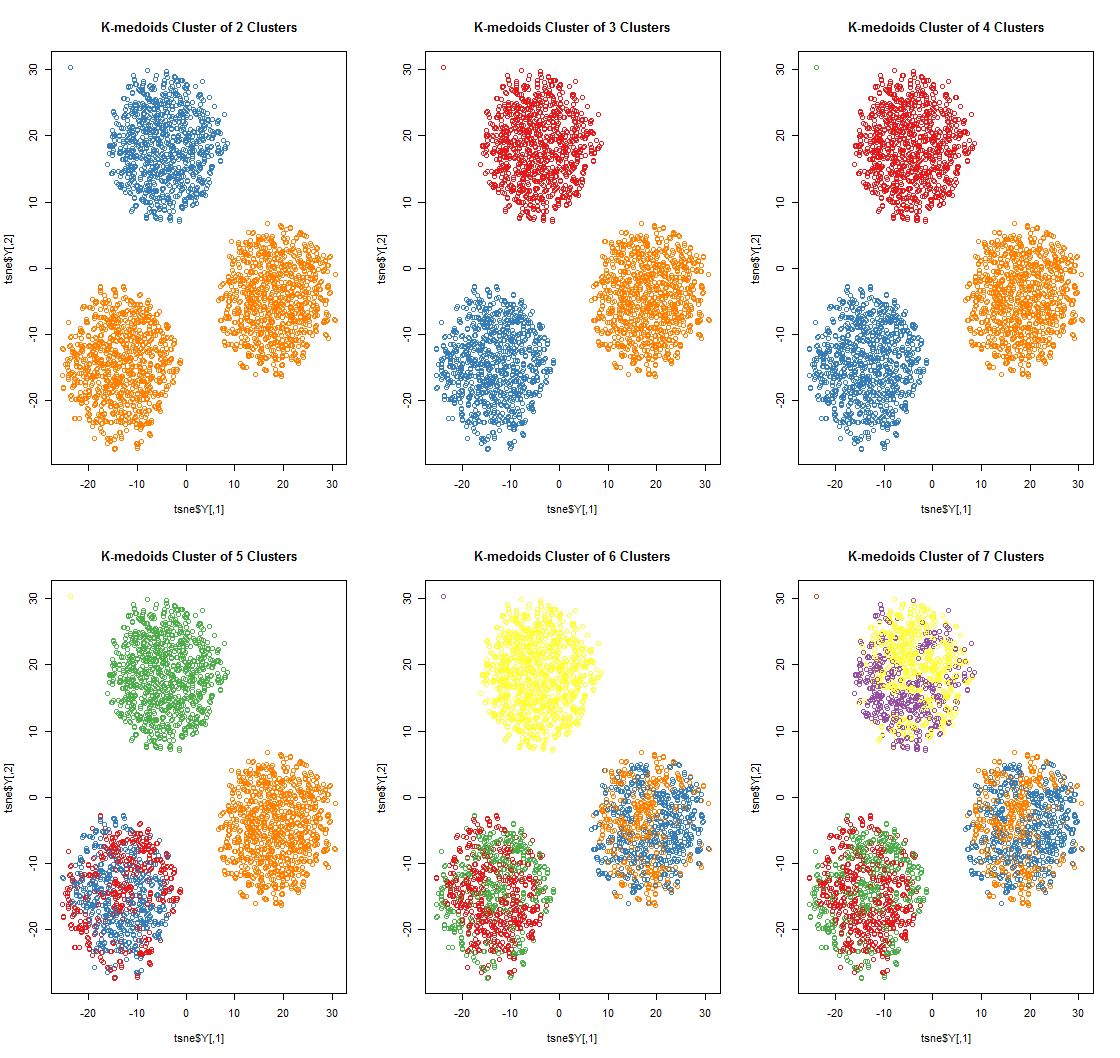
K-medoids过程的代价函数变化情况:

K-means的聚类结果(基于不同的k值):

K-means的代价函数变化情况:
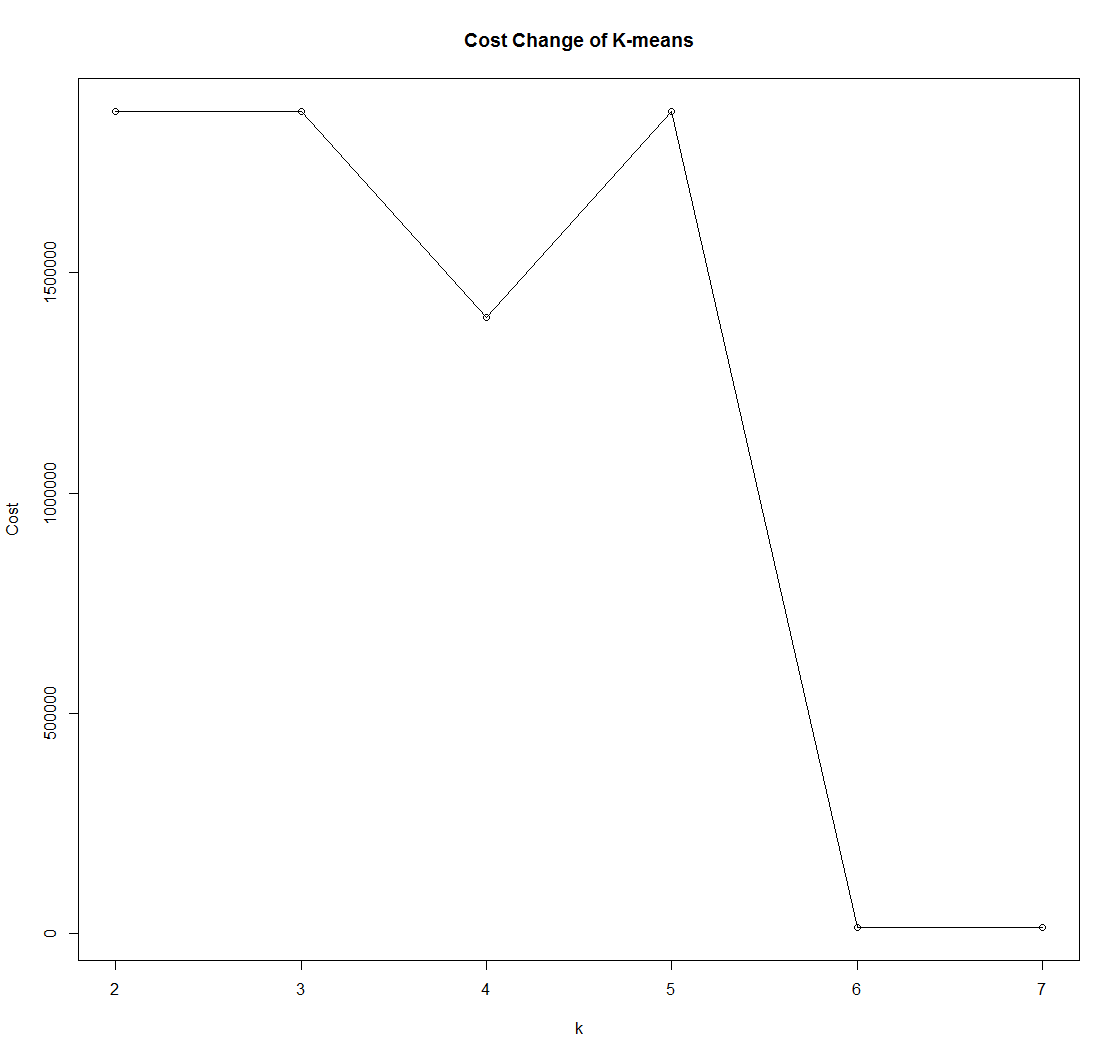
可以看出,K-medoids在应付含有脏数据的数据集时有着更为稳定的性能表现。
Python
在Python中关于K-medoids的第三方算法实在是够冷门,经过笔者一番查找,终于在一个久无人维护的第三方模块pyclust中找到了对应的方法KMedoids(),若要对制定的数据进行聚类,使用格式如下:
KMedoids(n_clusters=n).fit_predict(data),其中data即为将要预测的样本集,下面以具体示例进行展示:
from pyclust import KMedoids
import numpy as np
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt '''构造示例数据集(加入少量脏数据)'''
data1 = np.random.normal(0,0.9,(1000,10))
data2 = np.random.normal(1,0.9,(1000,10))
data3 = np.random.normal(2,0.9,(1000,10))
data4 = np.random.normal(3,0.9,(1000,10))
data5 = np.random.normal(50,0.9,(50,10)) data = np.concatenate((data1,data2,data3,data4,data5)) '''准备可视化需要的降维数据'''
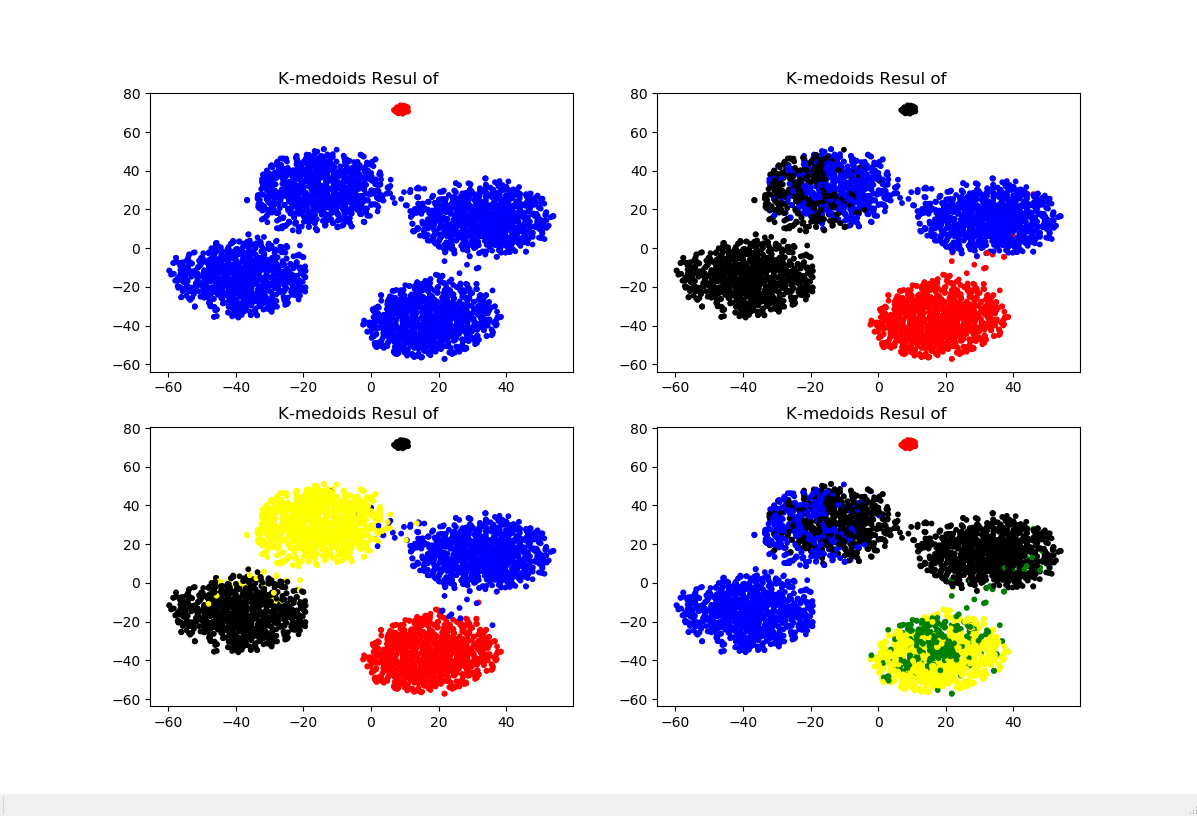
data_TSNE = TSNE(learning_rate=100).fit_transform(data) '''对不同的k进行试探性K-medoids聚类并可视化'''
plt.figure(figsize=(12,8))
for i in range(2,6):
k = KMedoids(n_clusters=i,distance='euclidean',max_iter=1000).fit_predict(data)
colors = ([['red','blue','black','yellow','green'][i] for i in k])
plt.subplot(219+i)
plt.scatter(data_TSNE[:,0],data_TSNE[:,1],c=colors,s=10)
plt.title('K-medoids Resul of '.format(str(i)))
以上就是关于K-medoids算法的基本知识,如有错误之处望指出。
(数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现的更多相关文章
- (数据科学学习手札16)K-modes聚类法的简介&Python与R的实现
我们之前经常提起的K-means算法虽然比较经典,但其有不少的局限,为了改变K-means对异常值的敏感情况,我们介绍了K-medoids算法,而为了解决K-means只能处理数值型数据的情况,本篇便 ...
- (数据科学学习手札17)线性判别分析的原理简介&Python与R实现
之前数篇博客我们比较了几种具有代表性的聚类算法,但现实工作中,最多的问题是分类与定性预测,即通过基于已标注类型的数据的各显著特征值,通过大量样本训练出的模型,来对新出现的样本进行分类,这也是机器学习中 ...
- (数据科学学习手札09)系统聚类算法Python与R的比较
上一篇笔者以自己编写代码的方式实现了重心法下的系统聚类(又称层次聚类)算法,通过与Scipy和R中各自自带的系统聚类方法进行比较,显然这些权威的快捷方法更为高效,那么本篇就系统地介绍一下Python与 ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- (数据科学学习手札12)K-means聚类实战(基于R)
上一篇我们详细介绍了普通的K-means聚类法在Python和R中各自的实现方法,本篇便以实际工作中遇到的数据集为例进行实战说明. 数据说明: 本次实战样本数据集来自浪潮集团提供的美团的商家信息,因涉 ...
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- (数据科学学习手札08)系统聚类法的Python源码实现(与Python,R自带方法进行比较)
聚类分析是数据挖掘方法中应用非常广泛的一项,而聚类分析根据其大体方法的不同又分为系统聚类和快速聚类,其中系统聚类的优点是可以很直观的得到聚类数不同时具体类中包括了哪些样本,而Python和R中都有直接 ...
- (数据科学学习手札29)KNN分类的原理详解&Python与R实现
一.简介 KNN(k-nearst neighbors,KNN)作为机器学习算法中的一种非常基本的算法,也正是因为其原理简单,被广泛应用于电影/音乐推荐等方面,即有些时候我们很难去建立确切的模型来描述 ...
随机推荐
- Python迭代器生成器,私有变量及列表字典集合推导式(二)
1 python自省机制 这个是python一大特性,自省就是面向对象的语言所写的程序在运行时,能知道对象的类型,换句话说就是在运行时能获取对象的类型,比如通过 type(),dir(),getatt ...
- Linux--DHCP搭建
服务功能:为局域网中的主机自动分配IP地址.子网掩码.广播地址.默认网关地址.DNS服务器地址 1.安装DHCP服务器软件 [root@localhost Packages]# rpm -ivh dh ...
- 2.GlusterFS 安装配置
2.1 GlusterFS 安装前的准备 服务器规划:(vmware 实验) 操作系统 IP 主机名 数据盘(2 块) CentOS 6.8 x86_64 10.1.0.151 mystorage1 ...
- NO.005-2018.02.10《南歌子词二首 / 新添声杨柳枝词》唐代:温庭筠
南歌子词二首 / 新添声杨柳枝词_古诗文网 南歌子词二首 / 新添声杨柳枝词 唐代:温庭筠(yún) 一尺深红胜曲尘,天生旧物不如新.(胜曲尘 一作:蒙曲尘)一袭深红色的长裙日子久了便蒙上了淡黄色,自 ...
- JQUERY实现点击INPUT使光标移动到最后或指定位置
下面本文章给大家简单介绍一下JQUERY实现点击INPUT使光标移动到最后或指定位置例子,希望对各位有帮助,你要知道面对一个 处女座的 需求者, focus()是远远不够的,比如说“我点进去的时候光标 ...
- Android(java)学习笔记18:单例模式
单例模式代码示例: 1. 单例模式之饿汉式: package cn.itcast_03; public class Student { // 构造私有 private Student() { } // ...
- Android开发学习之TabView选项卡具体解释 -- 基于Android4.4
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/he90227/article/details/24474197 直接上代码 -- 基于Android ...
- Codeforces Round #432 (Div. 2)
A. Arpa and a research in Mexican wave Arpa is researching the Mexican wave. There are n spectators ...
- delete在js里为引用删除
delete 运算符从对象中删除一个属性,或从数组中删除一个元素. delete expressionexpression 参数是一个有效的 JScript 表达式,通常是一个属性名或数组元素. 说明 ...
- AIM Tech Round 5 (rated, Div. 1 + Div. 2) C. Rectangles 【矩阵交集】
题目传传传送门:http://codeforces.com/contest/1028/problem/C C. Rectangles time limit per test 2 seconds mem ...