2.如何使用python连接hdfs
总所周知,python是一门很强大的语言,主要在于它有着丰富的第三方模块,当然连接hdfs的模块也不例外。
在python中有一个模块也叫hdfs,可以使用它连接hadoop的hdfs。直接pip install hdfs即可。我们使用python的hdfs可以达到和hadoop shell一样的效果
import hdfs
# 1.如何连接hadoop上的hdfs
'''
参数:
def __init__(self, url, root=None, proxy=None, timeout=None, session=None):
url:这里的url就是我们在浏览器查看hdfs时的连接,也就是ip:端口
root:指定hdfs的根目录
proxy:指定用户的登录身份
timeout:设定的超时时间
session:requests模块里面的session类的实例,用来发出请求
'''
client = hdfs.Client("http://ubuntu:50070")
# 2.查看路径的具体信息
'''
参数:
def status(self, hdfs_path, strict=True):
hdfs_path:路径,这里我们指定/,也就是根目录
strict:严格模式,默认为True,表示路径不存在就会抛出异常,为False路径不存在则返回None
'''
client.status(hdfs_path="/")
# 3.查看指定目录里的文件或目录
'''
参数:
def list(self, hdfs_path, status=False):
hdfs_path:路径
status:默认为False,如果为True,则不仅显示有哪些文件或目录,还显示具体的信息
'''
client.list("/")
# 4.创建目录
'''
参数:
def makedirs(self, hdfs_path, permission=None):
hdfs_path:创建的目录,值得一提的是,这个是可以递归创建的
permission:设置权限,比如777,可读可写可执行
'''
client.makedirs("/古明地觉/hello.txt")
# 5.重命名
'''
参数:
def rename(self, hdfs_src_path, hdfs_dst_path):
hdfs_src_path:源文件
hdfs_dst_path:新文件
'''
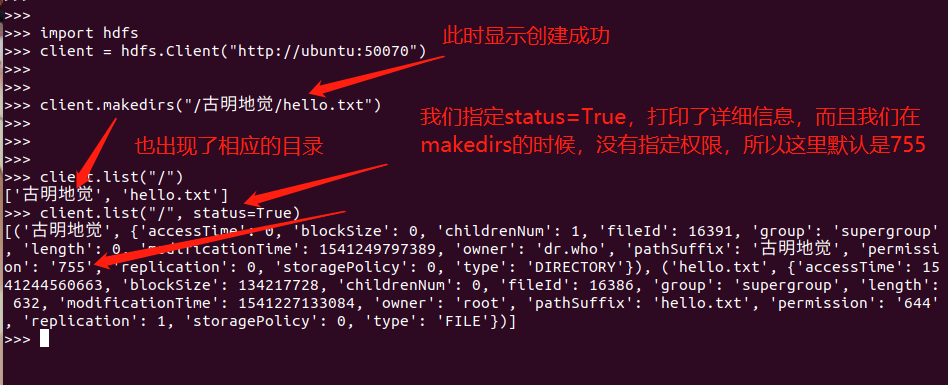
client.rename("/古明地觉/hello.txt", "/古明地觉/hello_satori.txt")
# 6.删除
'''
参数:
def delete(self, hdfs_path, recursive=False):
hdfs_path:路径
recursive:表示是否递归,默认为False
'''
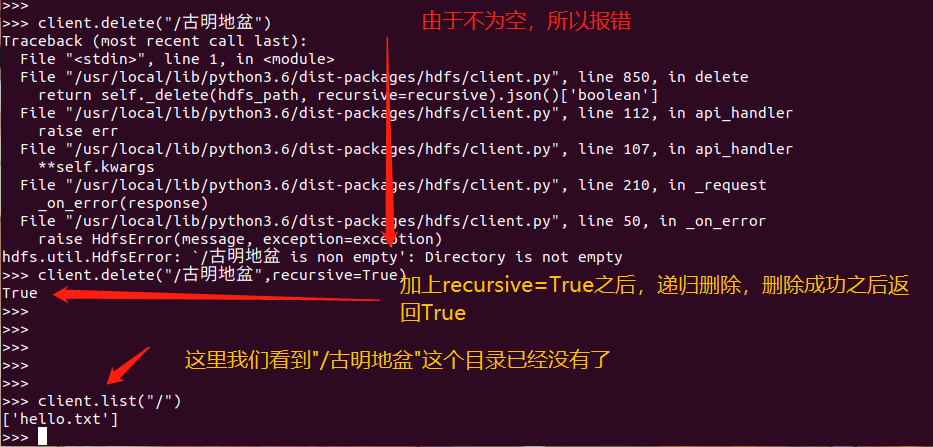
client.delete("/古明地觉/hello_satori.txt", recursive=True)
# 7.上传文件
'''
参数:
def upload(self, hdfs_path, local_path, overwrite=False, n_threads=1,
temp_dir=None, chunk_size=2 ** 16, progress=None, cleanup=True, **kwargs):
hdfs_path:hdfs路径
local_path:本地文件路径,仔细一看这和hdfs dfs -put 本地 hdfs,刚好是相反的。表示从本地上传文件到hdfs
overwrite:就是遇见同名的,是否覆盖
n_threads:启动的线程数
temp_dir:当overwrite=true时,远程文件一旦存在,则会在上传完之后进行交换
chunk_size:文件上传的大小区间
progress:回调函数来跟踪进度,为每一chunk_size字节。它将传递两个参数,文件上传的路径和传输的字节数。一旦完成,-1将作为第二个参数
cleanup:如果在上传任何文件时发生错误,则删除该文件
'''
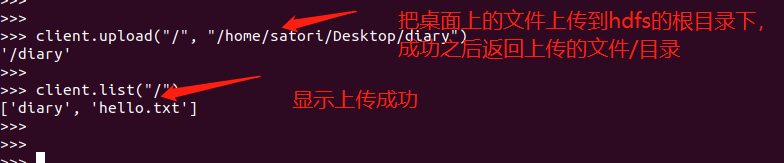
client.upload("/", "/home/satori/Desktop/diary")
# 8.下载文件
'''
参数:
def download(self, hdfs_path, local_path, overwrite=False, n_threads=1,
temp_dir=None, **kwargs):
hdfs_path:hdfs文件路径
local_path:本地文件路径,表示从hdfs下载文件到本地
'''
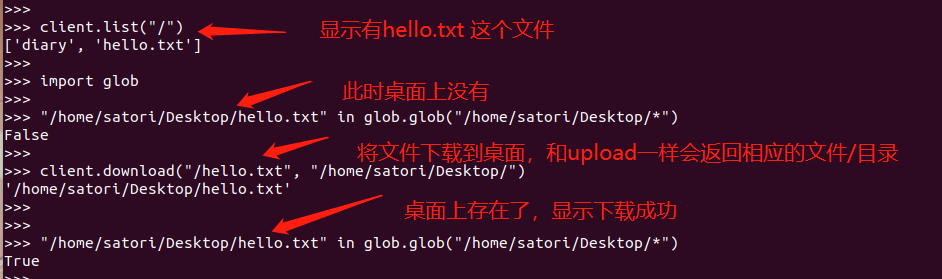
client.download("/hello.txt", "/home/satori/Desktop/hello.txt")
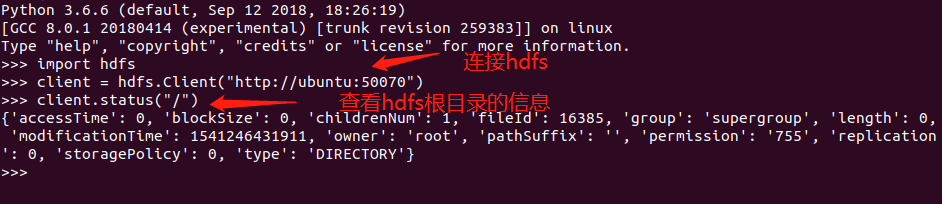

但当我们想创建文件的时候,却出现了如下错误
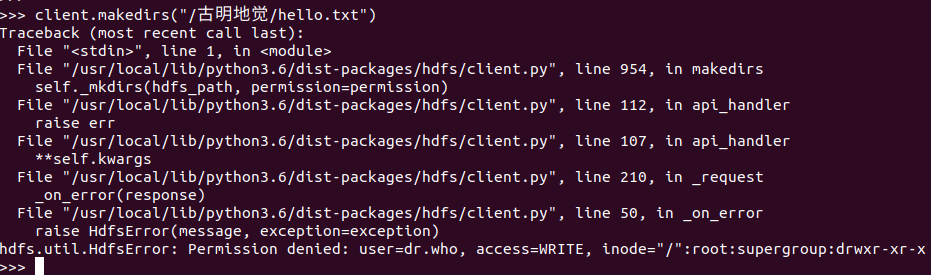
不要怕,这个只需要修改一下配置文件core-site.xml即可。

然后重启hadoop集群

HDFS文件读写流程





HDFS的优点
数据冗余,硬件容错
解决了数据存储的丢失问题,一个节点挂掉了,还可从其他的节点读取数据。尽管这个一定程度增加了数据存储的浪费,但是更加安全
处理流式的数据访问
这个流式并不是流式处理,而是一次写入,多次读取的操作
适合存储大文件
可以存储大文件,即使数据量很大,也可以通过扩展机器来解决
可以部署在廉价的机器上
可以使用廉价的机器进行部署,相比于使用小型机和刀片机,可以大幅度的降低价格
HDFS的缺点
低延迟的数据访问
数据可能会比较大,要在秒级别对想要的数据进行检索是不现实的
不适合小文件的存储
不管文件是127M还是1M,都是有对应的元数据存放在对应的namenode上面。如果小文件很多,意味着元数据所占用的内存信息也会很大,对namenode的压力也越大
2.如何使用python连接hdfs的更多相关文章
- python读取hdfs并返回dataframe教程
不多说,直接上代码 from hdfs import Client import pandas as pd HDFSHOST = "http://xxx:50070" FILENA ...
- 使用Python访问HDFS
最近接触到大数据,对于Skpark和Hadoop的料及都停留在第一次听到这个名词时去搜一把看看大概介绍免得跟不上时代的层次. 在实际读了点别人的代码,又自己写了一些之后,虽然谈不上理解加深,至少对于大 ...
- 【初学python】使用python连接mysql数据查询结果并显示
因为测试工作经常需要与后台数据库进行数据比较和统计,所以采用python编写连接数据库脚本方便测试,提高工作效率,脚本如下(python连接mysql需要引入第三方库MySQLdb,百度下载安装) # ...
- python连接mysql的驱动
对于py2.7的朋友,直接可以用MySQLdb去连接,但是MySQLdb不支持python3.x.这是需要注意的~ 那应该用什么python连接mysql的驱动呢,在stackoverflow上有人解 ...
- paip. 解决php 以及 python 连接access无效的参数量。参数不足,期待是 1”的错误
paip. 解决php 以及 python 连接access无效的参数量.参数不足,期待是 1"的错误 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源 ...
- python 连接sql server
linux 下pymssql模块的安装 所需压缩包:pymssql-2.1.0.tar.bz2freetds-patched.tar.gz 安装: tar -xvf pymssql-2.1.0.tar ...
- paip.python连接mysql最佳实践o4
paip.python连接mysql最佳实践o4 python连接mysql 还使用了不少时间...,相比php困难多了..麻烦的.. 而php,就容易的多兰.. python标准库没mysql库,只 ...
- python连接字符串的方式
发现Python连接字符串又是用的不顺手,影响速度 1.数字对字符进行拼接 s="" #定义这个字符串,方便做连接 print type(s) for i in range(10 ...
- python连接zookeeper的日志问题
用python连接zookeeper时,在终端里,一直会有zookeeper的日志冒出来,这样会很烦. -- ::,:(: Exceeded deadline by 11ms 解决方法是在连接后设置一 ...
随机推荐
- C++STL——list
一.相关定义 list 链表,分配的内存不连续 可以高效地进行插入/删除元素 不可随机访问,访问速度慢 特征 只能通过迭代器来访问list中的元素 在头和尾都可以插入元素 二.list [前提条件] ...
- antDesign DatePicker 禁用日期
const disabledDate = (current) => { return current < moment().subtract(29, 'days') || current ...
- LaTex标准article文件框架解析
新建一个LaTex-Article文件 生成的文件框架代码 % ---------------------------------------------------------------- % A ...
- Bjarne Stroustrup语录2
一.致读者 1. 在编程序时,你是在为你针对某个问题的解决方案中的思想建立起一种具体表示.让程序的结构尽可能地直接反映这些思想: ★.如果你能把“它”看成一个独立的概念,就把它做成一个类. ...
- html框架集 target
- C#怎么调用方法
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace Exep ...
- JS调用C#中的变量
今天早上做项目,需要使用JS来得到数据库里面表的行数.经过查找资料,知道可以使用在C#中定义一个全局变量.在JS中调用即可,自己总结一下:供日后参考; public string Str() { st ...
- LeetCode -- Best Time to Buy and Sell Stock系列
Question: Best Time to Buy and Sell Stock Say you have an array for which the ith element is the pri ...
- Angular白名单&&Angular拦截器 全局通用
//angular 白名单全局通用 app.config([ '$compileProvider', function ($compileProvider) { $compileProvider.aH ...
- 闲话JavaScript与Cookies
使用 Cookies 我们已经知道,在 document 对象中有一个 cookie 属性.但是 Cookie 又是什么?"某些 Web 站点在您的硬盘上用很小的文本文件存储了一些信息,这些 ...