机器学习基础之knn的简单例子
knn算法是人工智能的基本算法,类似于语言中的"hello world!",python中的机器学习核心模块:Scikit-Learn
Scikit-learn(sklearn)模块,为Python语言实现机器学习的核心模块,其包含了大量的算法模型函数API,
可以让我们很轻松地创建、训练、评估 算法模型。同时该模块也是Python在人工智能(机器学习)领域的基础应用模块。
核心依赖模块:
NumPy:pip install –U numpy
Scipy:pip install –U scipy
Pandas:pip install –U pandas
Matplotlib:pip install –U matplotlib
Scikit-Learn模块:
Scikit-Learn:pip install –U scikit-learn
机器学习分为五个步骤:
1.算法选型 看选择监督学习还是无监督学习
2.样本数据划分 需要样本数据对模型进行训练
3.魔性训练 使用fit()方法 算法模型对象.fit( X_train_features, X_train_labels )
4.模型评估 metrics 使用sklearn中的 meterics 类可以实现对训练后的模型进行量化指标评估
5.模型预测 predict Predict实现了对测试数据验证以及用于对新数据的预测
KNN算法的简单应用,文档树:
其中numbers.csv数据如下:
number,classes
1,A
2,A
3,A
4,B
5,B
6,B
7,C
8,C
9,C
num_knn.py源码:
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
import os
import pandas as pd
import imp
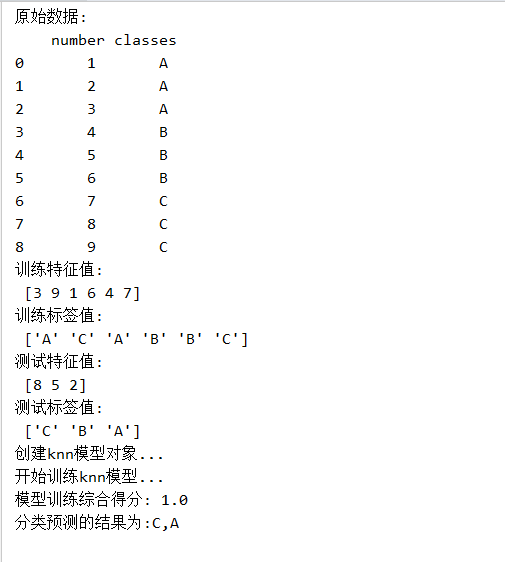
from sklearn.model_selection import train_test_split data=pd.read_csv(os.getcwd()+'\data'+os.sep+'numbers.csv')
print('原始数据:\n',data) X_train,X_test,y_train,y_test=train_test_split(data['number'],data['classes'],test_size=0.25,random_state=40)
print('训练特征值:\n',X_train.values)
print('训练标签值:\n',y_train.values)
print('测试特征值:\n',X_test.values)
print('测试标签值:\n',y_test.values)
#print(y_train)
#print(y_test) plt.scatter(y_train,X_train) print('创建knn模型对象...')
knn=KNeighborsClassifier(n_neighbors=3) print('开始训练knn模型...')
knn.fit(X_train.values.reshape(len(X_train),1),y_train)
#print(X_train.values)
#print(X_train.values.reshape(len(X_train),1)) #变成列向量 # 评估函数
# 算法对象.score(测试特征值数据, 测试标签值数据)
score=knn.score(X_test.values.reshape(len(X_test),1),y_test)
print('模型训练综合得分:',score) # 步骤6:模型预测
# predict()函数实现
# predict(新数据(二维数组类型)): 分类结果
result = knn.predict([[12],[1.5]])
print('分类预测的结果为:{0},{1}'.format(result[0],result[1])) # 绘制测试数据点
plt.scatter(result[0], 12, color='r')
plt.scatter(result[1], 1.5, color='g')
plt.grid(linestyle='--')
plt.show()
运行结果如下图:
KNN第二个例子:
movies.csv:
filename,war_count,love_count,movietype
movieA,3,104,爱情片
movieB,2,100,爱情片
movieC,1,81,爱情片
movieD,101,10,战争片
movieF,99,5,战争片
movieF,98,2,战争片
movie_knn.py:
import pandas as pd
import os
import imp
#导入分解词
from sklearn.model_selection import train_test_split
#导入knn算法模型
from sklearn.neighbors import KNeighborsClassifier
# 导入分类器性能监测报告模块
from sklearn.metrics import classification_report def loaddata(filepath): #加载数据
data=pd.read_csv(filepath)
print('样本数据集:\n',data)
#print('样本数据集:\n{0}'.format(data)) # 步骤2:数据抽取
# 获取war_count、love_count、movietype列数据
data = data[['war_count', 'love_count', 'movietype']]
print('原始样本数据集(数据抽取):\n{0}'.format(data)) # 返回数据
return data def splitdata(data):
print('--数据划分--')
X_train,X_test,y_train,y_test=train_test_split(data[['war_count','love_count']],data['movietype'],\
test_size=0.25,random_state=30)
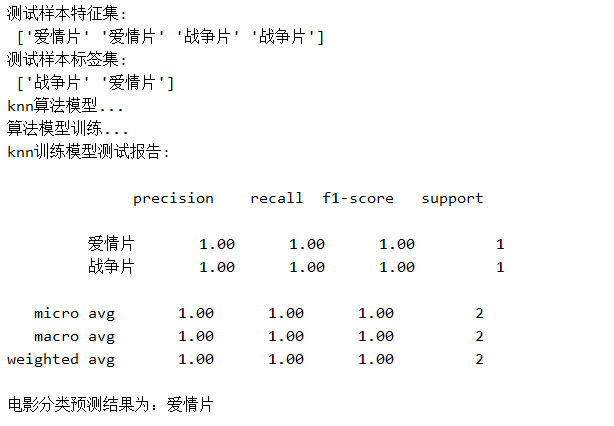
print('训练样本特征集:\n', X_train.values)
print('训练样本标签集:\n', X_test.values)
print('测试样本特征集:\n', y_train.values)
print('测试样本标签集:\n', y_test.values) # 返回数据
return X_train, X_test, y_train, y_test def ModelTraing(X_train,X_test,y_train,y_yest):
#先创建knn算法模型
print('knn算法模型...')
knn=KNeighborsClassifier(n_neighbors=3) #训练算法模型
print('算法模型训练...')
knn.fit(X_train,y_train) #训练模型评估
result=knn.predict(X_test)
print('knn训练模型测试报告:\n')
print(classification_report(y_test,result,target_names=data['movietype'].unique())) return knn if __name__=='__main__':
# 设置数据文件的地址
filePath = os.getcwd() + '\data' + os.sep + 'movies.csv'
print(filePath)
# 加载数据文件
data = loaddata(filePath)
# 数据划分
X_train, X_test, y_train, y_test = splitdata(data)
# 模型训练
knn = ModelTraing(X_train, X_test, y_train, y_test)
# 模型应用
movietype = knn.predict([[20, 94]])
print('电影分类预测结果为:{0}'.format(movietype[0]))
代码运行结果:
附上GitHub地址 tyutltf/knn_basic: knn的简单例子 https://github.com/tyutltf/knn_basic
机器学习基础之knn的简单例子的更多相关文章
- 通过Redux源码学习基础概念一:简单例子入门
最近公司有个项目使用react+redux来做前端部分的实现,正好有机会学习一下redux,也和小伙伴们分享一下学习的经验. 首先声明一下,这篇文章讲的是Redux的基本概念和实现,不包括react- ...
- Python机器学习基础教程-第1章-鸢尾花的例子KNN
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之K近邻
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之决策树集成
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之决策树
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之线性模型
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- 机器学习(1) - TensorflowSharp 简单使用与KNN识别MNIST流程
机器学习是时下非常流行的话题,而Tensorflow是机器学习中最有名的工具包.TensorflowSharp是Tensorflow的C#语言表述.本文会对TensorflowSharp的使用进行一个 ...
- Python3实现机器学习经典算法(二)KNN实现简单OCR
一.前言 1.ocr概述 OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然 ...
- 数据分析之Matplotlib和机器学习基础
一.Matplotlib基础知识 Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形. 通过 Matplotlib,开发者可以仅需 ...
随机推荐
- solidity语言7
单位和全局变量 Ether Units: wei, finney, szabo, ether Time Units: 1 == 1 seconds 1 minutes == 60 seconds 1 ...
- C# 中关于radiobutton控件的使用
在一个Form窗口中定义了3个radiobutton,radioButton1.radioButton2和radioButton3,以及button1和button2(这里可以是其他控件) 为了实现单 ...
- Tomcat无法正常启动start.bat 一闪而过、只显示USING 故障排除
在云主机上配置tomcat的时候遇到的问题. 1. 开始的时候我将自己用的tomcat6绿色版打包放到了主机上,当我打开bin下面的时候startup.bat时,控制台一闪而过,查看log文件没有任何 ...
- 文件读取方法(FileHelpers) z
using System; using System.Collections.Generic; using System.Linq; using System.Text; using FileHelp ...
- JavaScript 三种工厂模式
标签(空格分隔): JavaScript 简单工厂模式是工厂函数返回实例化对象或者对象,工厂函数作为一个方法. 工厂方法模式是工厂函数不作改变,将子类放在工厂原型中:工厂函数返回对应的实例化对象:re ...
- Python 列表排序方法reverse、sort、sorted操作方法
python语言中的列表排序方法有三个:reverse反转/倒序排序.sort正序排序.sorted可以获取排序后的列表.在更高级列表排序中,后两中方法还可以加入条件参数进行排序. reverse() ...
- VS LNK2019 解决办法之一
LNK2019: unresolved external symbol _main referenced in function __main 有人说这是因为静态动态引用引起的,但是!这些都没有解决我 ...
- hdu 6243,6247
题意:n只狗,n个笼子,每个笼子只能有一只,求不在自己笼子的狗的数量的期望. 分析:概率是相等的,可以直接用方案数代替,k 不在自己的笼子的方案数是 n!- (n-1)!,这样的k有n个,总的方案数n ...
- jdbc连接各种数据库字符串
oracle driverClass:oracle.jdbc.driver.OracleDriver url:jdbc:oracle:thin:@127.0.0.1:1521:dbname mysql ...
- 10474 - Where is the Marble?(模拟)
传送门: UVa10474 - Where is the Marble? Raju and Meena love to play with Marbles. They have got a lot o ...