oracle 基础知识(十四)----索引扫描
(1)索引唯一扫描(index unique scan)
通过唯一索引查找一个数值经常返回单个ROWID。如果该唯一索引有多个列组成(即组合索引),则至少要有组合索引的引导列参与到该查询中,如创建一个索引:create index idx_test on emp(ename, deptno, loc)。则select ename from emp where ename = ‘JACK’ and deptno = ‘DEV’语句可以使用该索引。如果该语句只返回一行,则存取方法称为索引唯一扫描。而select ename from emp where deptno = ‘DEV’语句则不会使用该索引,因为where子句种没有引导列。如果存在UNIQUE 或PRIMARY KEY 约束(它保证了语句只存取单行)的话,Oracle经常实现唯一性扫描。
为了方便查看设置执行计划为只显示执行计划
SQL> set autot traceonly exp;
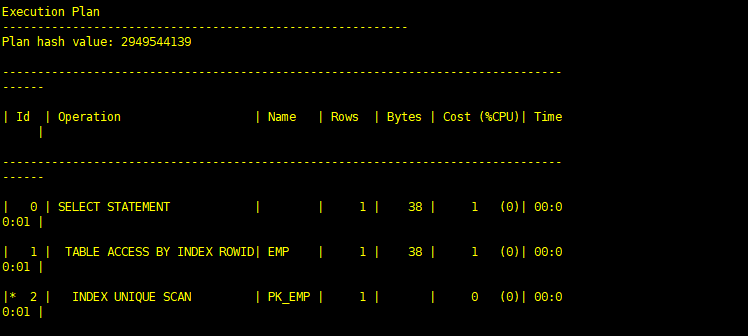
SQL> select * from scott.emp t where t.empno=10; Execution Plan
----------------------------------------------------------
Plan hash value: 2949544139 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
| -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 | -------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 2 - access("T"."EMPNO"=10) SQL>
(2)索引范围扫描(index range scan)
使用一个索引存取多行数据,同上面一样,如果索引是组合索引,而且select ename from emp where ename = ‘JACK’ and deptno = ‘DEV’ 语句返回多行数据,虽然该语句还是使用该组合索引进行查询,可此时的存取方法称为索引范围扫描。
在唯一索引上使用索引范围扫描的典型情况下是在谓词(where限制条件)中使用了范围操作符(如>、<、<>、>=、<=、between)
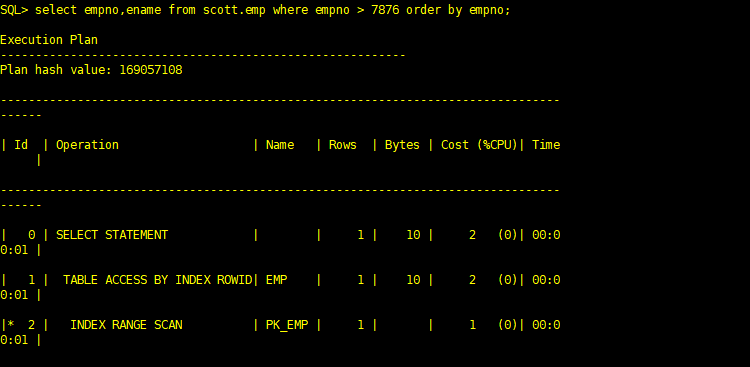
SQL> select empno,ename from scott.emp where empno > 6666 order by empno; Execution Plan
----------------------------------------------------------
Plan hash value: 169057108 --------------------------------------------------------------------------------
------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
| --------------------------------------------------------------------------------
------ | 0 | SELECT STATEMENT | | 14 | 140 | 2 (0)| 00:0
0:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 14 | 140 | 2 (0)| 00:0
0:01 | |* 2 | INDEX RANGE SCAN | PK_EMP | 14 | | 1 (0)| 00:0
0:01 | --------------------------------------------------------------------------------
------ Predicate Information (identified by operation id):
--------------------------------------------------- 2 - access("EMPNO">6666)
在非唯一索引上,谓词可能返回多行数据,所以在非唯一索引上都使用索引范围扫描。
使用index rang scan的3种情况:
(a) 在唯一索引列上使用了range操作符(> < <> >= <= between)。
(b) 在组合索引上,只使用部分列进行查询,导致查询出多行。
(c) 对非唯一索引列上进行的任何查询。
(3)索引全扫描(index full scan)
与全表扫描对应,也有相应的全Oracle索引扫描。在某些情况下,可能进行全Oracle索引扫描而不是范围扫描,需要注意的是全Oracle索引扫描只在CBO模式下才有效。 CBO根据统计数值得知进行全Oracle索引扫描比进行全表扫描更有效时,才进行全Oracle索引扫描,而且此时查询出的数据都必须从索引中可以直接得到。
SQL> create index big_emp on scott.emp(empno,ename); ---创建索引 Index created. SQL> select empno, ename from scott.emp order by empno,ename; 执行计划查看你 Execution Plan
----------------------------------------------------------
Plan hash value: 322359667 ----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 140 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | BIG_EMP | 14 | 140 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------

(4)索引快速扫描(index fast full scan)
扫描索引中的所有的数据块,与 index full scan很类似,但是一个显著的区别就是它不对查询出的数据进行排序,即数据不是以排序顺序被返回。在这种存取方法中,可以使用多块读功能,也可以使用并行读入,以便获得最大吞吐量与缩短执行时间。
测试表创建: ---资源来自>>
create table t as select * from dba_objects where 1=2; insert into t select * from dba_objects where object_id is not null; 创建一个索引
create index i_t_object_id on t(object_id); select object_id from t; set autot trace exp; -- 设置格式 查询:select object_id from t;
Execution Plan
----------------------------------------------------------
Plan hash value: 1601196873 --------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 89550 | 1136K| 336 (1)| 00:00:05 |
| 1 | TABLE ACCESS FULL| T | 89550 | 1136K| 336 (1)| 00:00:05 |
-------------------------------------------------------------------------- Note
-----
- dynamic sampling used for this statement (level=2) 这个好像走的是全表呀...由于我们需要查询的列为object_id,因此理论上只需要读取索引就应该可以返回所有数据,而此时为什么是全表扫描呢?这是因为NULL值与索引的特性所决定的。即null值不会被存储到B树索引。因此应该为表 t 的列 object_id 添加 not null 约束。 alter table t modify(object_id not null); 添加约束 再次查看 SQL> select object_id from t; Execution Plan
----------------------------------------------------------
Plan hash value: 2036340805 --------------------------------------------------------------------------------
------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
| --------------------------------------------------------------------------------
------ | 0 | SELECT STATEMENT | | 89550 | 1136K| 53 (0)| 00:0
0:01 | | 1 | INDEX FAST FULL SCAN| I_T_OBJECT_ID | 89550 | 1136K| 53 (0)| 00:0
0:01 | --------------------------------------------------------------------------------
------ Note
-----
- dynamic sampling used for this statement (level=2) INDEX FAST FULL SCAN
类似于full table scan,使用该方式当在高速缓存中没有找到所需的索引块时,则根据db_file_multiblock_read_count的值进行多块读操
作。对于索引的分支结构只是简单的获取,然后扫描所有的叶结点。其结果是导致索引结构没有访问,获取的数据没有根据索引键的顺序排序。
INDEX FAST FULL SCAN使用multiblock_read,故产生db file scattered reads 事件

Execution Plan
----------------------------------------------------------
Plan hash value: 431110666
--------------------------------------------------------------------------------
--
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
|
--------------------------------------------------------------------------------
--
| 0 | SELECT STATEMENT | | 89550 | 1136K| 194 (1)| 00:00:03
|
| 1 | INDEX FULL SCAN | I_T_OBJECT_ID | 89550 | 1136K| 194 (1)| 00:00:03
|
--------------------------------------------------------------------------------
--
Note
-----
- dynamic sampling used for this statement (level=2)
与INDEX FAST FULL SCAN所不同的是,INDEX FULL SCAN会完全按照索引存储的顺序依次访问整个索引树。当访问到叶结点之后,按照双向
链表方式读取相连节点的值。换言之,对于索引上所有的数据是按照有序的方式来读取的。如果索引块没有在高速缓存中被找到时,则需要从数
据文件中单块进行读取。对于需要读取大量数据的全索引扫描而言,这将使其变得低效。INDEX FULL SCAN使用single read,故产生
db file sequential reads事件。新版的Oracle支持db file parallel reads方式。
(5)索引跳跃扫描(INDEX SKIP SCAN)
INDEX SKIP SCAN,发生在多个列建立的复合索引上,如果SQL中谓词条件只包含索引中的部分列,并且这些列不是建立索引时的第一列时,就可能发生INDEX SKIP SCAN。这里SKIP的意思是因为查询条件没有第一列或前面几列,被忽略了。
例子来自于>>>
SQL> create table employee(gender varchar2(1),employee_id number);
Table created.
SQL> alter table employee modify(employee_id not null);
Table altered.
SQL> create index idx_employee on employee(gender,employee_id);
Index created.
SQL> begin
for i in 5001..10000 loop
insert into employee values ('M',i);
end loop;
commit;
end;
SQL> /
PL/SQL procedure successfully completed.
SQL> begin
for i in 1..5000 loop
insert into employee values ('F',i);
end loop;
commit;
end;
SQL> /
PL/SQL procedure successfully completed.
SQL> analyze table EMPLOYEE compute statistics for table for all columns for all indexes;
Table analyzed.
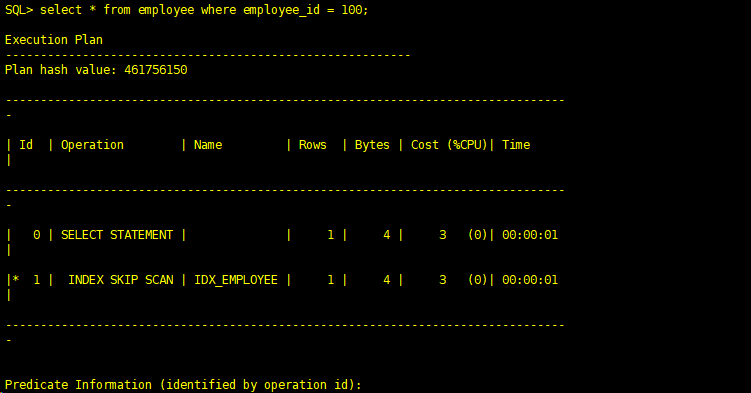
SQL> select * from employee where employee_id = 100;
Execution Plan
----------------------------------------------------------
Plan hash value: 461756150
--------------------------------------------------------------------------------
-
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
|
--------------------------------------------------------------------------------
-
| 0 | SELECT STATEMENT | | 1 | 4 | 3 (0)| 00:00:01
|
|* 1 | INDEX SKIP SCAN | IDX_EMPLOYEE | 1 | 4 | 3 (0)| 00:00:01
|
--------------------------------------------------------------------------------
-
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("EMPLOYEE_ID"=100)
filter("EMPLOYEE_ID"=100)
SQL>
oracle 基础知识(十四)----索引扫描的更多相关文章
- oracle 基础知识(十二)----索引
一, 索引介绍 索引与表一样,也属于段(segment)的一种.里面存放了用户的数据,跟表一样需要占用磁盘空间.索引是一种允许直接访问数据表中某一数据行的树型结构,为了提高查询效率而引入,是一个独立于 ...
- oracle 基础知识(十五)----高水位线
一,oracle的逻辑存储管理 ORACLE的逻辑存储管理,分4个粒度:表空间,段,区和块. ## 块 粒度最小的存储单位,现在标准的块大小是8K,ORACLE每一次I/O操作也是按块来操作的,也就是 ...
- Android学习之基础知识十四 — Android特色开发之基于位置的服务
一.基于位置的服务简介 LBS:基于位置的服务.随着移动互联网的兴起,这个技术在最近的几年里十分火爆.其实它本身并不是什么时髦的技术,主要的工作原理就是利用无线电通讯网络或GPS等定位方式来确定出移动 ...
- oracle 基础知识(十)----exp/imp--->>>>>expdp/impdp
一,简介 存活下来的远古级别的导入导出软件exp/imp ,软件多数使用于oracle 9i 之前 到了10g以后基本全面被数据库泵(Data Pump)取代,即expdp/impdp.本文会分别介 ...
- oracle 基础知识(四)常用函数
SQL中的单记录函数 .ASCII 返回与指定的字符对应的十进制数; SQL') zero,ascii(' ') space from dual; A A ZERO SPACE --------- - ...
- 正则表达式、Calendar类、SimpleDateFormat类、Date类、BigDecimal类、BigInteger类、System类、Random类、Math类(Java基础知识十四)
1.正则表达式的概述和简单使用 * A:正则表达式(一个字符串,是规则) * 是指一个用来描述或者匹配一系列符合某个语法规则的字符串的单个字符串.其实就是一种规则.有自己特殊的应用. * B: ...
- Oracle基础 (十四)其他函数
转换函数: TO_DATE:转换为日期 --将字符串转换为日期 SELECT TO_DATE('2014-12-31', 'yyyy-mm-dd') FROM DUAL; SELECT TO_DATE ...
- ASP.NET Core 2.2 基础知识(十四) WebAPI Action返回类型(未完待续)
要啥自行车,直接看手表 //返回基元类型 public string Get() { return "hello world"; } //返回复杂类型 public Person ...
- Oracle基础知识汇总一
Oracle基础知识 以下内容为本人的学习笔记,如需要转载,请声明原文链接 https://www.cnblogs.com/lyh1024/p/16720759.html oracle工具: SQ ...
随机推荐
- python核心编程第4章课后题答案(第二版75页)
4-1Python objects All Python objects have three attributes:type,ID,and value. All are readonly with ...
- [Lua快速了解一下]Lua的语法
-注释 -- 两个减号是行注释 -块注释 --[[ 这是块注释 这是块注释 --]] -变量 Lua的数字只有double型,64bits, Lua的字符串string支持双引号或者单引号 以下例子会 ...
- 前端框架 json 返回值
layui: string strJson = "{\"code\": \"0\",\"msg\": \"\" ...
- 客户端 post ,get 访问服务器
private void sendReuestExpansion() { HttpRequest<T> req = this; HttpWebRequest request; try { ...
- 从头开始学eShopOnContainers——设置WebSPA单页应用程序
一.简介 Web SPA单页应用程序需要一些额外的步骤才能使其工作,因为它需要在生成Docker镜像之前构建JavaScript框架依赖项和JS代码. 二.安装基础环境 1.安装NPM 为了能够使用n ...
- NSKeyedArchiver数据归档
前言 在 OC 语言中,归档是一个过程,即用某种格式来保存一个或多个对象,以便以后还原这些对象. 通常,这个过程包括将(多个)对象写入文件中,以便以后读取该对象.可以使用归档的方法进行对象的深复制. ...
- 第八篇 Python异常
程序在运行时,如果Python解释器遇到一个错误,会停止程序的执行,并且提示一些错误信息,这就是异常,程序通知执行并且提示错误信息,这个动作,我们通常称之为:抛出异常. 1.简单的捕获异常的语法 在程 ...
- JAVA学习必须掌握的框架,不看后悔
Web应用,最常见的研发语言是Java和PHP. 后端服务,最常见的研发语言是Java和C/C++. 大数据,最常见的研发语言是Java和Python. 可以说,Java是现阶段中国互联网公司中,覆盖 ...
- spring 学习(一):使用 intellijIDEA 创建 maven 工程进行 Spring ioc 测试
spring学习(一):使用 intellijIDEA 创建 maven 工程进行 Spring ioc 测试 ioc 概念 控制反转(Inversion of Control,缩写为IOC),是面向 ...
- 题解 P1339 【[USACO09OCT]热浪Heat Wave】
题目链接 这道题纯属是一个裸的SPFA: 建议先把模板AC之后再做. 只需要做一些手脚,就是在加边的时候加一个双向边就好. 然后再第一次加点的时候 看不懂模板的出门左转度娘. 推荐下面一片讲解: 友链 ...