知识增强深度学习及其应用:综述《Knowledge-augmented Deep Learning and Its Applications: A Survey》(下)
论文:Knowledge-augmented Deep Learning and Its Applications: A Survey
GitHub:
arXiv上的论文。
(接着来)
4 用经验知识进行深度学习
除了科学知识,经验知识被广泛认为是神经符号模型的主要知识来源。经验知识是指日常生活中众所周知的事实,描述一个对象的语义财产或多个对象之间的语义关系。它通常是直观的,通过长期观察或成熟的研究得出。与科学知识不同,经验知识虽然广泛可用,但具有描述性和不精确性。包含语义信息的经验知识可以作为深度学习中预测任务(例如,回归或分类任务)的强大先验知识,特别是在小数据情况下,仅训练数据不足以捕捉变量之间的关系[65]。
A 经验知识识别
根据应用领域的不同,经验知识可能表现为两种类型:实体属性和实体关系。实体关系揭示了实体之间的语义关系。它们可以从命名实体之间的关系的日常事实中推断出来,也可以从成熟的研究或理论(例如解剖学)中推导出来。例如人体解剖学在计算机视觉中被广泛用于人体和面部行为分析[14],[110],[111]。对于面部行为分析,面部解剖知识可以提供关于面部肌肉之间的关系的信息,以产生自然的面部表情。类似地,身体解剖学可以提供关于身体关节之间的关系的信息,以产生稳定和物理上合理的身体姿势和运动。语义关系可以直接给出,也可以从现有关系中间接推断。例如,从海伦·米伦出演《墨心》和海伦·米伦获得最佳女主角奖的事实来看,我们可以推断《墨心”获得了提名。然而,推断的事实容易出错。实体财产捕获关于实体财产的知识。它们可以指描述人类感知的世界中概念层次关系的本体论信息[112]。例如,雨是由水构成的,海是海洋的同义词。语言知识是经验知识的主要来源,在[113],[114]中进行了分析。大型语言模型被认为是抽象文本推理任务的归纳偏见[115]。文本解释等语言知识已被探索用于语言模型细化[116]。
(现在21:22,真的醉了,经历了四次会议截稿,撤稿了两次,终于投上之后(我亲爱的导师,我的大老板收到了撤稿邮件后终于忍不住给我打电话问我为什么撤稿,会议级别都不一样,随便投随便撤影响不好,我说是小老板让我撤的,撤了才能投新的,老板说,我和他说一下,不能这样),看我小老板发我的一篇文献综述,还:建议精读。我看了十几页了,逐渐暴躁,复制粘贴翻译的我都手疼,只有前两页和我的专业有关,剩下的十几页全是物理和医学的东西,excuse me?他是不是只看了第一页就发给我让我看啊。现在拳头都紧了[撇嘴]。)
B 经验知识的表示
经验知识的表示因领域而异。一般来说,经验知识的表示包括概率依赖、逻辑规则和知识图。这些表示捕获了经验知识所揭示的实体的关系和财产。我们在图7中说明了经验知识的分类及其表示。
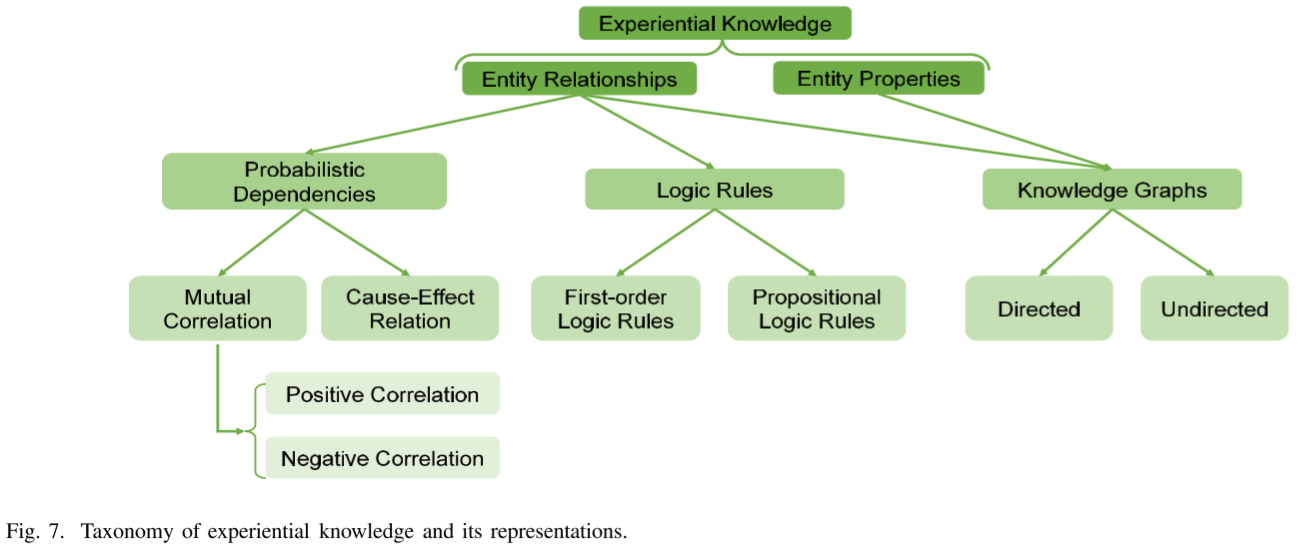
1) 概率依赖性:由于固有的不确定性,对象之间的语义关系通过概率依赖性被广泛表示。对象的状态是以概率方式建模的,通过概率依赖关系获取对象之间的关系。关系可以进一步分为正相关和负相关。让我们以面部动作单元(AU)为例。根据FACS[117],AU代表面部肌肉,一个面部肌肉可以控制一个或多个AU。如果相应的肌肉被激活,二进制AU可以打开。AU1(内眉毛提升)和AU2(外眉毛提升)通常一起发生,因为它们由相同的额肌控制。AU15(唇角按压器)和AU24(唇角加压器)是正相关的另一个例子,这是因为它们下面的控制肌肉(即,分别为口肌和口轮匝肌)总是一起运动。如果两个变量X和Y与X={0,1}正相关(例如,X=“AU1”,Y=“AU2”)并且Y={0,1},则我们有
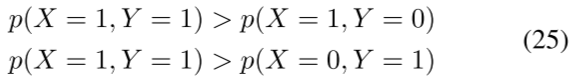
考虑到负相关,AU12(唇角拉力器)和AU15(唇角压力器)不能一起出现,因为它们对应的肌肉(即,分别为大颧骨和口部压力器,)不可能同时被激活。负相关可以用类似的方式表示。如果两个变量X和Y与X={0,1}和Y={0,1}负相关(例如,X=“AU12”和Y=“AU15”),那么我们有
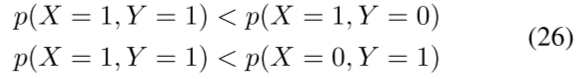
2) 一阶逻辑与命题逻辑:逻辑可分为一阶逻辑和命题逻辑。一阶逻辑(FOL)[118]使用逻辑规则从现有的经验知识中推断出新的经验知识;它已被用作推导不同类型知识的推理方法,例如文本解释[116]。FOL公式如下:
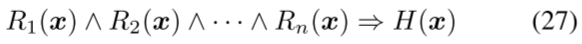
其中R1(x)、R2(x)和··Rn(x)表示逻辑原子。每个原子通过谓词捕获已知的对象属性或关系。原子通过连接(例如,连接)运算符组合,形成逻辑规则的条件部分。H(x)是逻辑规则的隐含结果或结论。它代表了从逻辑规则中获得的新的经验知识。规则的条件部分和结论部分通过蕴涵算子连接。例如,我们有

Smokes(x)是一个原子,Smokes是谓词,x是逻辑变量。它获取变量x所代表的人是否吸烟的实体属性知识。咳嗽(x)是隐含的结果或派生的知识,它捕获了患者咳嗽或不咳嗽的知识。该规则指出,如果条件部分Smokes(x)为真,则咳嗽(x)也为真。
3) 知识图:知识图是经验知识的另一种符号表示,主要用于捕捉对象之间的语义关系,从而语义知识以三种格式表示:(主语、谓语、宾语)。这种三元组的数量通常很大。在知识图中,这些三元组被组织为包含节点和边的图。节点表示主体或对象,例如动物或场所,以及命名实体,例如名为Mary Kelley的人。边表示谓词,连接成对的节点,并描述它们之间的关系。此外,边还可以用表示属性的节点表示实体的财产。以三元组(猫、属性、爪)为例,节点是猫和爪,关系是属性。这个三元组陈述了一个事实:“猫的属性是爪子”。边缘可以是有方向的或无方向的,例如动物之间的食物链关系或人与人之间的社会关系。知识图可以对大量常识、规则和领域知识进行编码,以捕获实体的语义关系和财产。因此,知识图是获取经验知识的重要基础资源。例如,可以在图像分类的知识图中组织对象语义的经验知识[119]。Mistrosoft概念图[120]是知识图的另一个示例,其中Mistrosoft概念图[122]中的顶点可以表示食物(如水果)、哺乳动物(如狗和猫)或设施(如公共汽车和加油站)。边缘表示基于日常事实的概念之间的关系,例如猫是哺乳动物,其中反映了猫和哺乳动物之间的关系。

如果xk<a和xp,k>a,根据先验知识,我们应该有\ yj–\ yp,j<0。如果满足约束,则L(x,xp,⑪yj,⑪yp,j)=0。否则,L(x,xp,⑪yj,⑪yp,j)>0。
2) 架构级集成:描述变量之间关系的领域知识可以通过架构设计集成到深度模型中。我们讨论了分别表示为概率依赖、逻辑规则和知识图的经验知识的架构级集成方法。
a) 结合概率依赖性的架构设计:架构级集成的一条代表性线集中于表示为概率依赖性(probability dependencies)的经验知识,由此根据知识构建的概率模型充当先验模型,并嵌入神经网络的一层。因此,变量之间的语义关系可以以概率的方式并入神经网络。通常,概率模型连接到神经网络的最后一层。通常使用条件随机场(CRF),它将神经网络的隐藏特征作为输入,并输出满足CRF中编码的知识的最终预测(例如,AU[66])。在[67]中,将完全连接的CRF连接到CNN的最后一层,以联合执行面部标志检测。通过利用完全连接的CNN-CRF,获得面部标志位置的概率预测,捕捉标志点之间的结构相关性。对于场景图生成[68],首先通过基于能量的概率模型捕获实体之间的结构化关系和关系。基于能量的概率模型将典型场景图生成模型的输出作为输入,并通过最小化能量对其进行细化。还可以利用通过概率模型捕获的先验知识来定义图卷积网络的邻接矩阵[69]。对于面部动作单元(AU)密度估计任务,使用贝叶斯网络来捕获AU之间的固有相关性。然后提出了一种概率图卷积,其邻接矩阵由贝叶斯网络的结构定义。此外,还可以引入概率模型作为神经网络的可学习中间层。提出了一种因果VAE[74],借此将因果层引入变分自动编码器(VAE)的潜在空间。因果层本质上描述了结构因果模型(SCM)。通过因果层,独立的外生因素被转化为因果内生因素,用于因果表征学习。
b) 结合逻辑规则的架构设计:通过神经网络架构进行集成是一种传统的神经符号方法,将符号逻辑规则集成到深度模型中。通过引入逻辑变量或参数,逻辑规则被集成到神经网络结构中。这种方法可以追溯到20世纪90年代,当时引入了基于知识的人工神经网络(KBANN)[121]和连接主义归纳学习和逻辑编程(CILP)[122]方法。最近,提出了逻辑神经网络(LNN)[123],其中每个神经元表示逻辑公式中的元素,该元素可以是概念(例如,cat)或逻辑连接(例如,AND、or)。然而,这些工作侧重于利用神经网络进行可微和可扩展的逻辑推理。
(21:50洗澡去了,告辞.)
(现在是2月24日 16:52)
很少有人提出通过逻辑规则定制其架构来改进深度模型。为了利用逻辑规则提高深度模型性能,将逻辑规则编码到马尔可夫逻辑网络(MLN)中,并将构建的MLN作为先验模型嵌入到神经网络中,作为改进知识图完成任务的输出层[75]。特别地,首先确定了四种类型的逻辑规则来捕获知识图中的知识:(1)合成规则:如果对于任意三个变量Y1、Y2、Y3,我们有Ri(Y1,Y2)∧Rj(Y2,Y2),则谓词Rk由两个谓词Ri和Rj组成⇒ Rk(Y1,Y3);(2) 逆规则:如果对于任意两个变量Y1和Y2,我们有Ri(Y1,Y2),则谓词Ri是Rj的逆⇒ Rj(Y2,Y1);(3) 对称规则:如果对于任意两个变量Y1和Y2,我们有R(Y1,Y2),则谓词R是对称的⇒ R(Y2,Y1);(4) 子集规则:谓词Rj是Ri的子集,如果对于任意两个变量Y1和Y2,我们有Rj(Y1,Y2)⇒ Ri(Y2,Y1)表示。给定一组已识别的逻辑规则l∈l,马尔可夫逻辑网络(MLN)将三元组的目标变量y的联合分布定义为
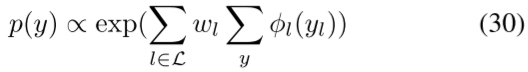
其中φl是势函数,并根据观察到的三元组进行计算。这样的MLN然后被连接到深度模型的最后一层,由此在给定观察到的三元组的情况下。通过引入MLN,预测缺失三元组的任务被重新表述为根据编码的逻辑规则推断不可见配置的后验分布。
c) 结合知识图的架构设计:知识图也可以作为一层集成到神经网络的架构中。Liang等人[78]提出了一种具有符号推理的图卷积。知识图中的先验知识通过提出的符号图推理(SGR)层具体集成到神经网络中,如图8所示。为了使所提出的SGR与卷积层协作,首先将来自当前卷积层的局部隐藏特征转移到SGR中相应符号节点的特征。SGR中符号节点之间的连接性是基于来自知识图的先验知识来定义的。在先验知识的指导下,SGR随后执行图形推理并更新特性。最后,将更新的特征映射到下一卷积层中的局部特征上。为了在跨视觉域和文本域中以无监督的方式生成医疗报告,提出了一种知识驱动的编码器-解码器模型来利用知识图[79]。知识图被编码到编码器内的知识驱动注意力模块中。以图像和医疗报告为输入,编码器首先通过标准深度模型分别获得图像嵌入和报告嵌入。然后引入了注意机制,其中嵌入是查询,并使用知识图来定义查找矩阵。来自注意力模块的学习表示通过利用知识图来连接视觉和文本域。在训练期间,通过最小化文本域中生成的和观察到的医学报告之间的重建误差来学习所提出的模型。在测试期间,知识驱动的编码器模型可以通过利用适用于视觉和文本领域的知识图中的经验知识,从医学图像生成医学报告。
CRF已被用来捕获知识图中的经验知识,并被集成为神经网络的一层。Luo等人[80]提出了一种上下文感知零炮识别(CA-ZSL)方法。从知识图中提取先验对象间关系,并使用条件随机域(CRF)进行编码。对于包含N个对象的图像,图像区域和每个对象的类分配分别表示为Bi和ci,其中i=1,2。。。,N。然后将CRF模型定义为
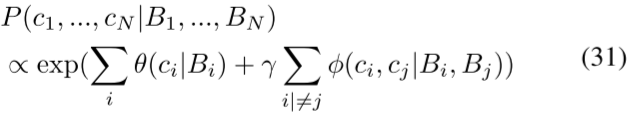
其中,一元势θ(ci|Bi)是在给定每个对象的相应提取特征的情况下估计的。使用提取的特征和知识图来估计成对势φ(ci,cj|Bi,Bj)。从知识图中提取的语义关系被编码在成对势函数中,其中γ是可调超参数。通过最大化对数似然来训练神经网络。在测试过程中,通过学习的CRF模型中的最大后验(MAP)推断,以上下文感知的方式推断不可见对象的标签。
3) 训练水平整合:经验知识被视为指导深度模型训练的先验偏见。基于知识获得约束,并将其作为正则化项集成到深度模型[77],[112],[124],[125]中。正则化可以从概率依赖、逻辑规则或知识图中导出,我们将在下面的段落中进一步讨论。
a) 具有概率依赖性的正则化:从语义关系的知识中导出的概率依赖性通常通过正则化集成到深度模型中。Srinivas-Kancheti等人[70]在训练期间考虑了用于正则化神经网络的因果域先验,由此,神经网络中学习到的因果效应通过正则化来匹配因果关系的先验知识。考虑具有d个输入和C个输出的神经网络f,对于第j个输入,δGj是包含先验因果知识(以梯度表示)的C×d矩阵。为了使f与先验知识一致,定义了正则化
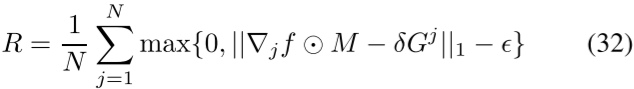
其中M是表示先验知识可用性的C×d二元矩阵,N是训练样本的总数jf是f w.r.t.第j个输入的C×d雅可比。ǫ表示可接受的误差容限,⊙是元素乘积。类似地,Rieger等人[71]提出通过解释损失来惩罚与先前知识不一致的模型解释。对于AU检测任务,AU之间的概率关系源自面部解剖知识。这些概率关系中的每一个都被表述为约束。在[72]中,相应地定义了测量这些约束中的每一个的满足程度的损失函数,并将其用于学习AU检测器。不同的是,Cui等人[73]提出学习贝叶斯网络(BN),以紧凑地捕获AU关系上的大量约束。然后使用BN构建期望的交叉熵损失,以训练用于AU检测的深度神经网络。
b) 用逻辑规则正则化:逻辑知识被编码为模型正则化的约束。通过正则化,如果深度模型的输出违反了从逻辑规则导出的约束,则该模型将受到惩罚。Xu等人[76]提出将命题逻辑的自动推理技术与现有的深度学习模型相结合。通过提出的语义损失,命题逻辑被编码在损失函数中。命题逻辑中的句子α是在变量X={X1,…,Xn}上定义的。该句子是对神经网络输出施加的语义约束。假设p是概率向量,其中每个元素pi表示变量Xi的预测概率,并对应于神经网络的单个输出。语义损失Ls(α,p)度量α的违反。给定p为

x|=α表示状态x满足句子α。状态满足句子的概率越大,语义损失越小。所提出的语义损失将神经网络正则化与逻辑推理联系起来。它适用于不同的应用,例如分类和偏好排名。
对于关系预测任务,提出了具有语义正则化的逻辑嵌入网络(LENSR)[77],其中将命题逻辑集成到关系检测模型中。对于给定图像,首先使用标准视觉关系检测模型来估计关系谓词的概率分布。然后基于给定输入图像预定义的命题逻辑公式,提出关系谓词的另一概率分布。最后,定义了一个语义正则化,通过最小化这两个概率分布的差异来对齐它们。
c) 知识图正则化:知识图是经验知识的图形表示,也被用于模型正则化。Fang等人[81]提出从知识图中提取语义一致性约束,然后将其用作正则化项。特别是,一对对象O和受试者S之间的一致性分数是通过随机行走和重启来计算的
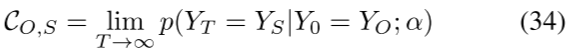
其中C∈R|O|×|S||O|和|S|表示目标对象和目标对象的总数。T是总移动步骤,α是重新启动概率,这意味着在每个移动步骤中,α从起始节点重新启动而不是移动到节点的邻居之一的概率。所计算的矩阵C被用作语义一致性的约束,并用于对对象检测任务的神经网络进行正则化。类似地,Gu等人[82]提出从KG中提取外部知识,并应用图像重建来改进场景图生成,尤其是当数据集有偏差或注释有噪声或缺失时。从ConceptNet检索对象关系作为外部领域知识,并通过对象到图像生成分支应用于细化对象特征。对象到图像生成分支基于对象特征和关于对象的先验关系知识来重建图像。语义上有意义的对象特征可以通过最小化重构误差来学习。
4) 决策层集成:通过自上而下和自下而上的联合预测策略,可以直接组合来自深度模型和先验知识的预测。通过整合两组预测,最终预测可以更加准确和稳健。
对于开放领域基于知识的视觉问题回答,Marino等人[83]结合了隐式和符号知识。内隐知识是指从数据(例如,原始文本)中学习到的知识。符号知识是指编码在现有知识图中的基于图的知识(例如,DBpedia[126]和ConceptNet[127])。提出的KRISP模型包含两个子模块:内隐知识推理和外显知识推理。然后,通过使用后期融合策略,将两个知识源组合以生成最终输出。通过后期融合策略,来自数据和符号知识的预测被直接组合,而不依赖于深度模型的训练。
通过遵循贝叶斯规则,可以以概率的方式组合两组预测。为了获得基于概率的预测,采用捕获先验知识的PGM模型作为先验模型,并通过概率推断获得其预测。对于AU识别任务,Li等人[64]考虑了自上而下和自下而上的集成,其中从通用知识中学习的贝叶斯网络充当自上而下的模型,数据驱动模型充当自下而上的模型。然后使用贝叶斯规则将来自两个模型的预测进行组合,以产生最终预测。基于概率的知识预测也可以基于知识直接定义。对于知识图完成任务,Cui等人[84]基于类型信息导出了关系的先验分布。然后,通过贝叶斯规则将先验分布与来自现有基于嵌入的模型的自下而上的预测相结合,以进行最终预测。
5 讨论和未来方向
在这项调查中,我们回顾了传统和流行的知识增强深度学习技术,包括知识识别、知识表示和集成。我们将知识分为两类:科学知识和经验知识。在每个类别中,我们都引入了知识识别、表示和深度学习的集成。正如我们所讨论的,已经做了很多工作来利用相关的先验知识改进深度学习,以生成数据高效、可推广和可解释的深度学习模型。为了帮助读者更好地理解KADL并将其应用于他们的工作,我们基于现有工作的总结提供了一个规定性的树(表I)。图9所示的规定性树是一个配方,它包括将特定类型的先验知识纳入深度模型的不同途径。每一条路径都包含一种特定的知识类型、一种知识表示格式和一种知识集成方法,并附有相关工作的参考。

尽管作出了这些努力,但现有的方法仍有几个缺点。在下面的段落中,我们将讨论现有技术,并强调未来的发展方向。
a) 不同类型的知识:现有的知识增强深度模型探索不同类型的领域知识,包括科学知识和经验知识。然而,大多数探索的知识都是物理学中的科学知识,并象征性地代表了经验知识。将成熟的算法知识注入深度模型已经开始吸引研究人员的注意力,从而通过算法监督而不是基础事实注释来训练深度模型[100]。此外,现有的方法通常限于一种特定类型的知识。对于某一应用任务,科学知识和经验知识可以从多个来源存在。因此,不同类型的知识可以联合起来,以提高深度模型性能。
b) 有效的知识集成:现有的集成方法利用合成数据、模型架构设计、正则化函数或预测细化。其中,大多数集成方法是在培训期间执行的。因此,现有的集成技术在很大程度上依赖于特定的训练程序,通过该程序,通过联合考虑两个信息源来训练深度模型,而无需明确区分数据和知识。这个问题可以通过决策级融合来解决。使用先验模型捕获领域知识的决策级知识集成方案相对较少受到关注。将知识与先验模型相结合以将来自知识的自上而下的预测和来自数据的自下而上的估计从几个方面来看可能是有益的。首先,先验模型的构建独立于深度模型,从而通过可观察数据初始化深度模型。由于先验模型和深度模型是独立于集成过程构建的,所以自上而下和自下而上的集成过程可以灵活地应用于任何深度模型和先验模型。其次,通过遵循贝叶斯规则以原则的方式进行知识集成。基于知识的基于数据的预测的细化变得易于处理和解释。
c) 混合集成方法:现有方法倾向于将科学知识和经验知识分开集成。此外,他们倾向于采用一种特定的方法来执行知识集成。对于某些应用领域,两种类型的知识可能同时存在。因此,应将它们联合起来,以进一步提高深度模型的性能。此外,用户始终需要选择一种集成方法。没有适用于所有类型知识的通用集成方案,如何以最佳方式自动将知识与数据集成仍然是一个悬而未决的问题。因此,考虑到不同集成方法的互补性,同时采用不同的集成方法以利用其各自的优势可能是有益的。
d) 知识与不确定性的整合:现有的研究以概率的方式探索了经验知识的编码,例如使用概率图形模型捕捉不确定性关系。但总的来说,现有的知识集成方法是确定性方法,忽略了潜在的知识不确定性及其对深度模型学习和推理的影响。不确定性不仅存在于经验知识中,也存在于科学知识中。例如,在物理学中,不确定性来自随机物理参数或未知物理参数或不完全观测。沿着这条线的现有工作旨在衡量管理物理系统的PDE解决方案的质量,因此受到特定领域假设的影响。概率工具,如概率图形模型(PGM),在捕捉经验知识的不确定性方面非常强大。然而,很少有研究探讨PGM在科学规律中建模不确定性[128],[129]中的应用。对于深度学习社区来说,如何有效和系统地为现实应用任务的科学知识中的不确定性建模仍然是一个悬而未决的问题。
(现在是17:10,终于看完了,总结:感觉被骗了,没什么适合现在的情况用的技术,小老板还建议精读,反正是看完了,还好没仔细看,被骗了,fine :)
知识增强深度学习及其应用:综述《Knowledge-augmented Deep Learning and Its Applications: A Survey》(下)的更多相关文章
- 深度学习与计算机视觉(11)_基于deep learning的快速图像检索系统
深度学习与计算机视觉(11)_基于deep learning的快速图像检索系统 作者:寒小阳 时间:2016年3月. 出处:http://blog.csdn.net/han_xiaoyang/arti ...
- TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)【转】
本文转载自:https://blog.csdn.net/xummgg/article/details/69214366 前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络,并把 ...
- TensorFlow和深度学习新手教程(TensorFlow and deep learning without a PhD)
前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络.并把其PPT的參考学习资料给了我们, 这是codelabs上的教程:<TensorFlow and deep lear ...
- 深度学习模型训练技巧 Tips for Deep Learning
一.深度学习建模与调试流程 先看训练集上的结果怎么样(有些机器学习模型没必要这么做,比如决策树.KNN.Adaboost 啥的,理论上在训练集上一定能做到完全正确,没啥好检查的) Deep Learn ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- 【RS】Deep Learning based Recommender System: A Survey and New Perspectives - 基于深度学习的推荐系统:调查与新视角
[论文标题]Deep Learning based Recommender System: A Survey and New Perspectives ( ACM Computing Surveys ...
- NLP related basic knowledge with deep learning methods
NLP related basic knowledge with deep learning methods 2017-06-22 First things first >>> ...
- Papers | 图像/视频增强 + 深度学习
目录 I. ARCNN 1. Motivation 2. Contribution 3. Artifacts Reduction Convolutional Neural Networks (ARCN ...
- 深度学习目标检测综述推荐之 Xiaogang Wang ISBA 2015
一.INTRODUCTION部分 (1)先根据时间轴讲了历史 (2)常见的基础模型 (3)讲了深度学习的优势 那就是feature learning,而不用人工划分的feature engineeri ...
- 深度学习基础(五)ResNet_Deep Residual Learning for Image Recognition
ResNet可以说是在过去几年中计算机视觉和深度学习领域最具开创性的工作.在其面世以后,目标检测.图像分割等任务中著名的网络模型纷纷借鉴其思想,进一步提升了各自的性能,比如yolo,Inception ...
随机推荐
- 洛谷P1057
#include<iostream> #include<utility> using namespace std; typedef long long ll; #define ...
- 部分解决 | ocrmypdf对中文pdf进行ocr识别后存在多余空格
1.问题 ocrmypdf安装采用的是在windows安装方法具体看 https://media.readthedocs.org/pdf/ocrmypdf/latest/ocrmypdf.pdf 由于 ...
- .NET科普:.NET简史、.NET Standard以及C#和.NET Framework之间的关系
最近在不少自媒体上看到有关.NET与C#的资讯与评价,感觉大家对.NET与C#还是不太了解,尤其是对2016年6月发布的跨平台.NET Core 1.0,更是知之甚少.在考虑一番之后,还是决定写点东西 ...
- openEuler 安装 DocekrCE
就个人而言,openEuler 算是不错的国产化操作系统."一脉传承"自redhat让实际的使用体验非常丝滑.软件源都是国内的,开箱即用,漏洞的补丁发的也挺及时.美中不足的是貌似 ...
- 如何对jar包修改并重新发布在本机
本人苦于jieba不能如何识别伊利丹·怒风,召唤者坎西恩这种名字,对jieba-analysis进行了解包和打包 步骤1:找到对应jar 步骤2:在cmd中输入jar -xvf xxx.jar解压包, ...
- windows环境xampp搭建php电商项目/搭建禅道
windows环境xampp搭建php论坛/电商项目 一,首先下载xampp https://www.apachefriends.org/zh_cn/index.html 下载之后解压到E盘或者F盘的 ...
- 为什么美国人聊天,结尾的时候他们会说“peace”
相关: https://www.youtube.com/watch?v=w2O--Ly0aQg 作为世界上当前唯一的军事霸权国家,美国居然通过立法的形式来支持种族清洗,这样的国家用虚假的"自 ...
- 使用pybind11为Python编写一个简单的C语言扩展模块
相关: 为Python编写一个简单的C语言扩展模块 在Pybind11 出现之前为Python编写扩展模块的方法有多种,但是并没有哪种方法被认为一定比其他的好,因此也就变得在为Python编写扩展模块 ...
- 【单调栈+倍增】[P7167 [eJOI2020 Day1] Fountain
[单调栈+倍增][P7167 [eJOI2020 Day1] Fountain 思路 用单调栈处理每个圆盘溢出后流到的第一个位置,然后倍增优化. 代码 #include <bits/stdc++ ...
- [CSP-S 2023] 消消乐 & CF1223F 题解
LG9753 CF1223F 我们称一个字符串是可消除的,当且仅当可以对这个字符串进行若干次操作,使之成为一个空字符串.其中每次操作可以从字符串中删除两个相邻的相同字符,操作后剩余字符串会拼接在一起. ...