TensorRT C# API 项目介绍:基于C#与TensorRT部署深度学习模型
TensorRT C# API 项目介绍:基于C#与TensorRT部署深度学习模型
1. 项目介绍
NVIDIA TensorRT 是一款用于高性能深度学习推理的 SDK,包括深度学习推理优化器和运行时,可为推理应用程序提供低延迟和高吞吐量。基于 NVIDIA TensorRT 的应用程序在推理过程中的执行速度比纯 CPU 平台快 36 倍,使您能够优化在所有主要框架上训练的神经网络模型,以高精度校准低精度,并部署到超大规模数据中心、嵌入式平台或汽车产品平台。
TensorRT 基于 NVIDIA CUDA 并行编程模型构建,使您能够在 NVIDIA GPU 上使用量化、层和张量融合、内核调整等技术来优化推理。TensorRT 提供 INT8 使用量化感知训练和训练后量化和浮点 16 (FP16) 优化,用于部署深度学习推理应用程序,例如视频流、推荐、欺诈检测和自然语言处理。低精度推理可显著降低延迟,这是许多实时服务以及自主和嵌入式应用所必需的。TensorRT 与 PyTorch 和 TensorFlow 集成,因此只需一行代码即可实现 6 倍的推理速度。TensorRT 提供了一个 ONNX 解析器,因此您可以轻松地将 ONNX 模型从常用框架导入 TensorRT。它还与 ONNX 运行时集成,提供了一种以 ONNX 格式实现高性能推理的简单方法。
基于这些优势,TensorRT目前在深度模型部署应用越来越广泛。但是TensorRT目前只提供了C++与Python接口,对于跨语言使用十分不便。目前C#语言已经成为当前编程语言排行榜上前五的语言,也被广泛应用工业软件开发中。为了能够实现在C#中调用TensorRT部署深度学习模型,我们在之前的开发中开发了TensorRT C# API。虽然实现了该接口,但由于数据传输存在问题,当时开发的版本在应用时存在较大的问题。
基于此,我们开发了TensorRT C# API 2.0版本,该版本在开发时充分考虑了上一版本应用时出现的问题,并进行了改进。同时在本版本中,我们对接口进行了优化,使用起来更加简单,并同时提供了相关的应用案例,方便开发者进行使用。
- TensorRT C# API 项目源码:
https://github.com/guojin-yan/TensorRT-CSharp-API.git
- TensorRT C# API 项目应用源码:
https://github.com/guojin-yan/TensorRT-CSharp-API-Samples.git
2. 接口介绍
下面简单介绍一下该项目封装的接口:
class Nvinfer
模型推理类: 该类主要是封装了转换后的接口,用户可以直接调用该类进行初始化推理引擎。
**public static void OnnxToEngine(string modelPath, int memorySize) **
- 模型转换接口:可以调用封装的TensorRT中的ONNX 解释器,对ONNX模型进行转换,并根据本机设备信息,编译本地模型,将模型转换为TensorRT 支持的engine格式。
- string modelPath: 本地ONNX模型地址,只支持ONNX格式,且ONNX模型必须为确定的输入输出,暂不支持动态输入。
- int memorySize: 模型转换时分配的内存大小
**public Nvinfer(string modelPath) **
- Nvinfer 初始化接口: 初始化Nvinfer类,主要初始化封装的推理引擎,该推理引擎中封装了比较重要的一些类和指针。
- string modelPath: engine模型路径。
**public Dims GetBindingDimensions(int index)/GetBindingDimensions(string nodeName) **
- 获取节点维度接口: 通过端口编号或者端口名称,获取绑定的端口的形状信息.
- int index: 绑定端口的编号
- string nodeName: 绑定端口的名称
- return Dims: 接口返回一个Dims结构体,该结构体包含了节点的维度大小以及每个维度的具体大小。
public void LoadInferenceData(string nodeName, float[] data)/LoadInferenceData(int nodeIndex, float[] data)
- 加载待推理数据接口: 通过端口编号或者端口名称,将处理好的带推理数据加载到推理通道上。
- string nodeName: 待加载推理数据端口的名称。
- **int nodeIndex: **待加载推理数据端口的编号。
- float[] data: 处理好的待推理数据,由于目前使用的推理数据多为float类型,因此此处目前只做了该类型接口。
public void infer()
- 模型推理接口: 调用推理接口,对加载到推理通道的数据进行推理。
public float[] GetInferenceResult(string nodeName)/GetInferenceResult(int nodeIndex)
- 获取推理结果: 通过端口编号或者端口名称,读取推理好的结果数据。
- string nodeName: 推理结果数据端口的名称。
- **int nodeIndex: **推理结果数据端口的编号。
- return float[]: 返回值为指定节点的推理结果数据。
3. 安装流程
下面演示一下安装方式,下文所有演示都是基于以下环境进行配置的:
操作系统:Windows 11
编译平台:Visual Studio 2022
显卡型号:RTX 2060
CUDA型号:12.2
Cudnn:8.9.3
TensorRT:8.6.1.6
对于CUDA以及Cudnn的安装此处不再作过多演示,大家可以自行安装。
3.1 TensorRT安装
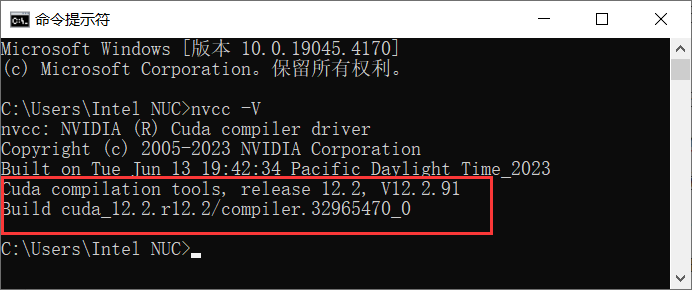
首先确定安装的CUDA版本,在命令提示符中输入nvcc -V指令,便可以获取安装的CUDA版本。
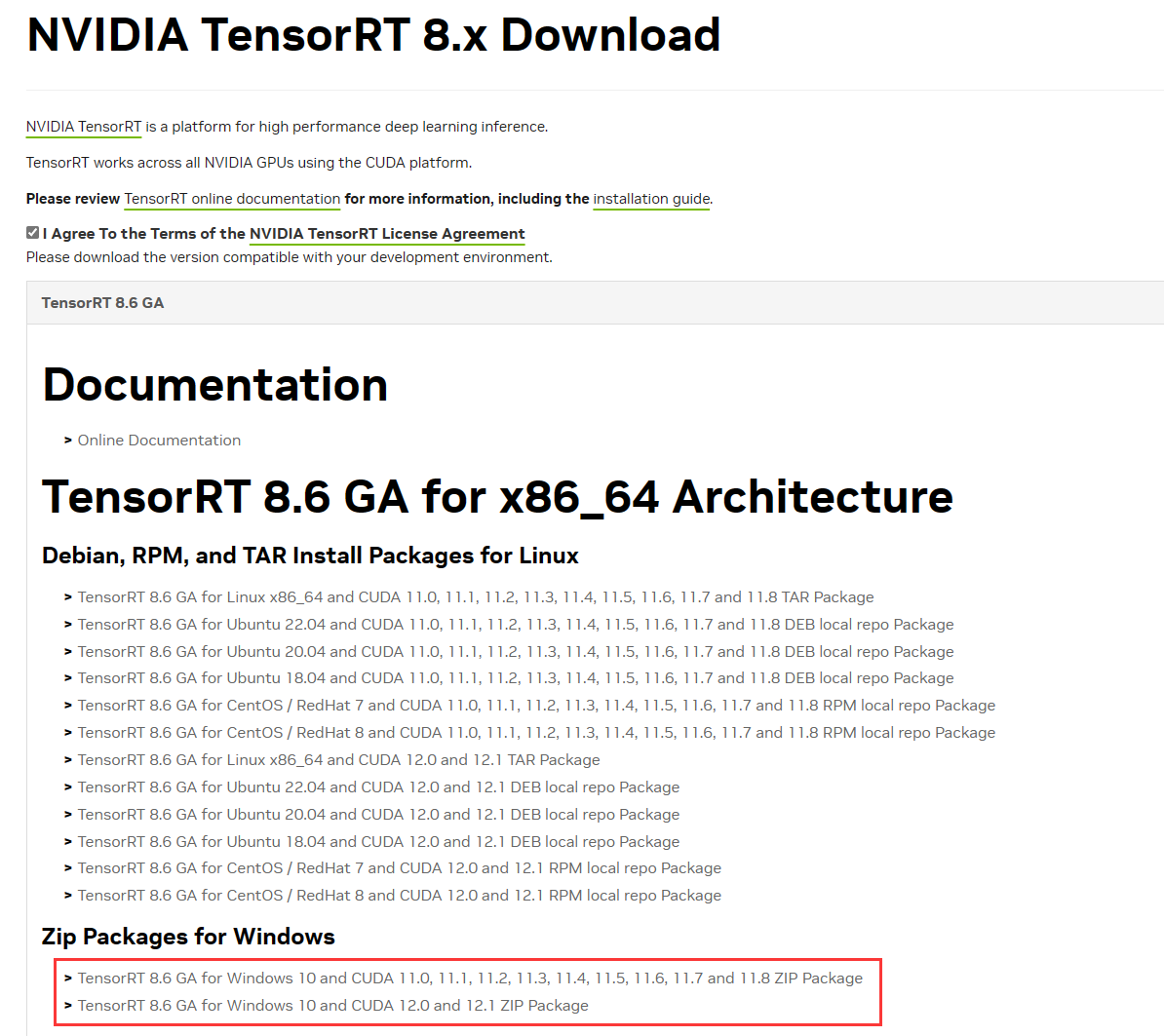
接下来访问TensorRT Download | NVIDIA Developer下载安装包,此处安装8.x系列,安装最新的版本8.6,如下图所示,通过下载Zip文件进行安装,大家可以根据自己的CUDN版本进行下载。
由于下载的是编译好的文件,因此在下载完成后,大家可以将其解压到常用的安装目录,然后将路径添加到环境变量即可,下面路径为本机安装的TensorRT路径,将其添加到本机的Path环境变量中。
D:\Program Files\TensorRT\TensorRT-8.6.1.6\lib
3.2 下载项目源码
由于CUDA以及TensorRT程序集文件较大,无法打包成NuGet Package,因此需要用户自己进行编译。
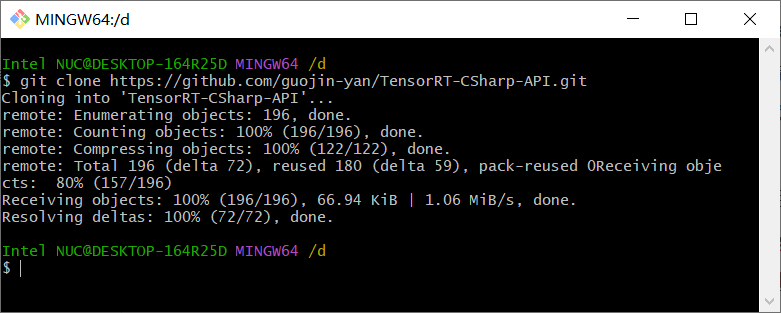
首先第一步下载项目源码,使用Git命令将源码下载到本地,如下图所示
git clone https://github.com/guojin-yan/TensorRT-CSharp-API.git
然后使用Visual Studio 2022打开解决方案文件,如下图所示:
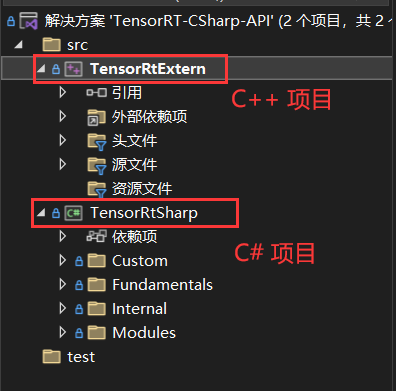
该解决方案中包含两个项目,一个是C++项目,该项目是封装的TensorRT接口,将接口封装到动态链接库中;另一个是C#项目,该项目是读取动态链接库中的C++接口,然后重新封装该接口。
3.3 配置C++项目
接下来配置C++项目,主要分为以下几步:
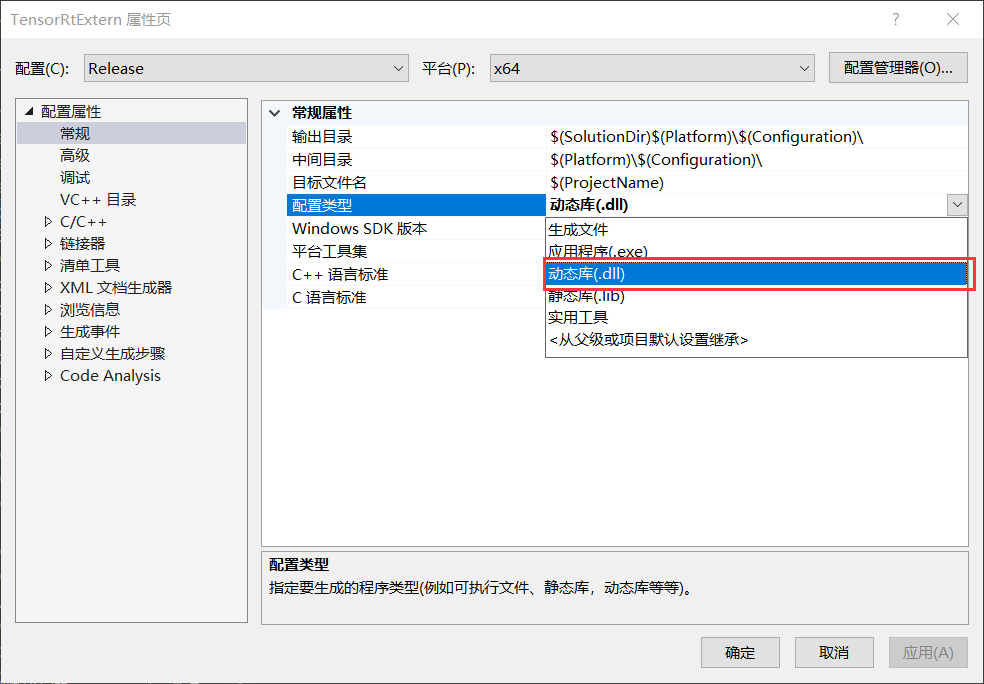
第一步:设置项目输出类型
C++项目主要用于生成动态链接库文件,因此将配置类型改为动态库(.dll)。
第二部:设置包含目录
当前C++项目主要使用两个依赖库,主要是CUDA(CUDNN)以及TensorRT,因此此处主要配置这两个依赖项,用户根据自己的安装情况进行配置即可。
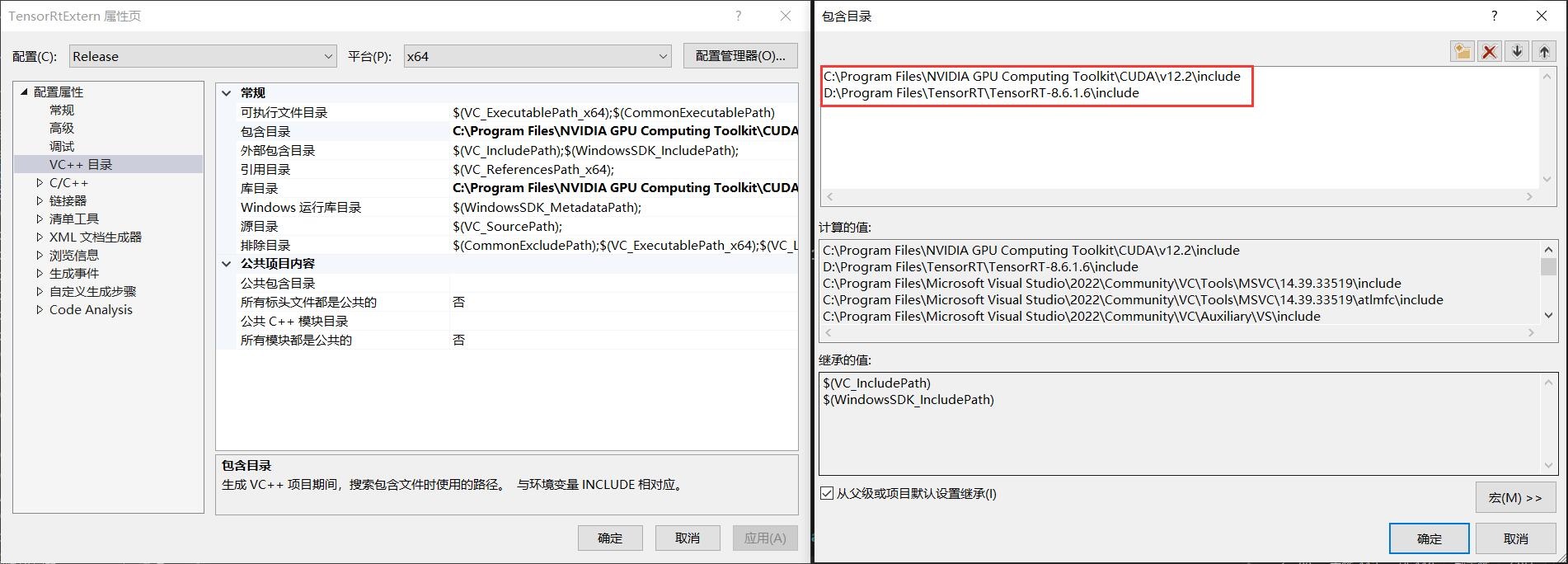
以下是本设备CUDA(CUDNN)以及TensorRT的包含目录位置,用户在使用时这需要根据自己本机安装情况进行设置即可。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2\include
D:\Program Files\TensorRT\TensorRT-8.6.1.6\include
第三步:设置库目录
下面设置安装的CUDA(CUDNN)以及TensorRT的库目录情况,如下图所示。
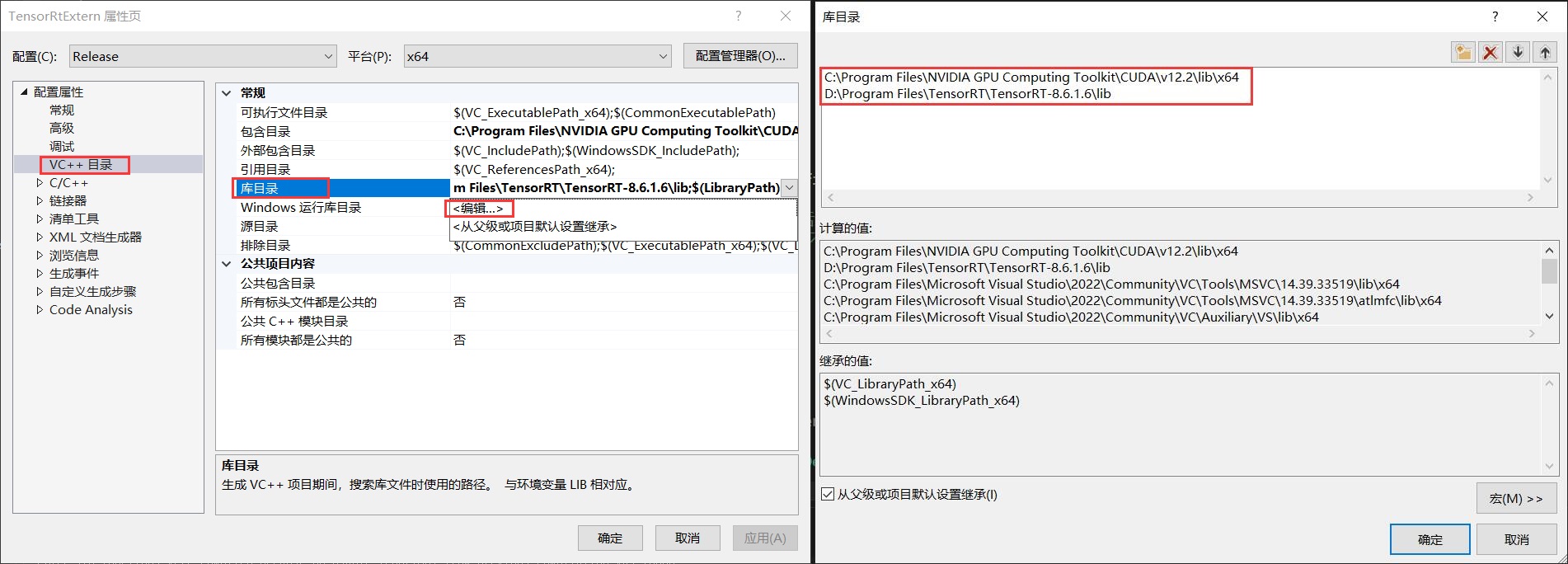
以下是本设备CUDA(CUDNN)以及TensorRT的库目录位置,用户在使用时这需要根据自己本机安装情况进行设置即可。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2\lib\x64
D:\Program Files\TensorRT\TensorRT-8.6.1.6\lib
第四步:设置附加依赖项
下面设置附加依赖项,附加依赖项文件在上一步设置的库目录路径中,此处主要添加.lib文件。
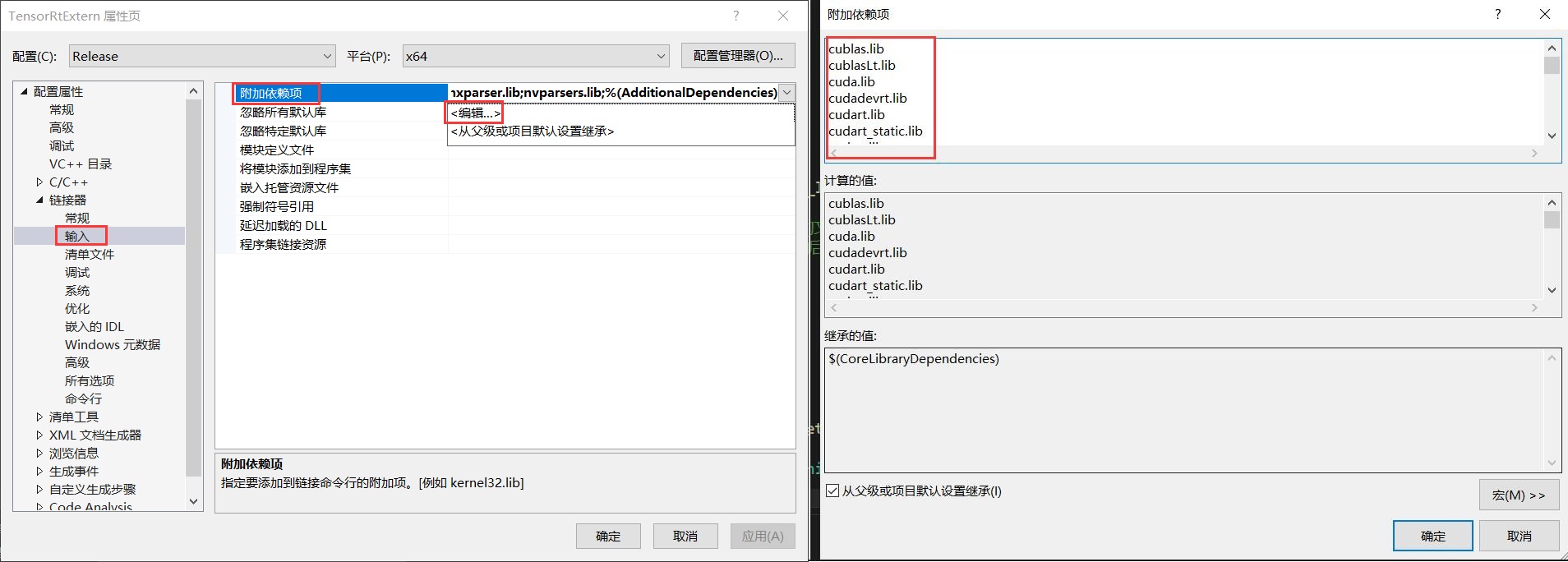
以下是CUDA(CUDNN)以及TensorRT的附加依赖项目录,但不同版本可能会不一致,因此用户在使用时需要根据自己的安装情况进行设置。
cublas.lib
cublasLt.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cudnn.lib
cudnn64_8.lib
cudnn_adv_infer.lib
cudnn_adv_infer64_8.lib
cudnn_adv_train.lib
cudnn_adv_train64_8.lib
cudnn_cnn_infer.lib
cudnn_cnn_infer64_8.lib
cudnn_cnn_train.lib
cudnn_cnn_train64_8.lib
cudnn_ops_infer.lib
cudnn_ops_infer64_8.lib
cudnn_ops_train.lib
cudnn_ops_train64_8.lib
cufft.lib
cufftw.lib
cufilt.lib
curand.lib
cusolver.lib
cusolverMg.lib
cusparse.lib
nppc.lib
nppial.lib
nppicc.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvJitLink.lib
nvJitLink_static.lib
nvjpeg.lib
nvml.lib
nvptxcompiler_static.lib
nvrtc-builtins_static.lib
nvrtc.lib
nvrtc_static.lib
OpenCL.lib
nvinfer.lib
nvinfer_dispatch.lib
nvinfer_lean.lib
nvinfer_plugin.lib
nvinfer_vc_plugin.lib
nvonnxparser.lib
nvparsers.lib
第五步:设置预处理器
由于项目中应用了一些不安全方法,所以需要在宏定义中添加以下定义,如下图所示:
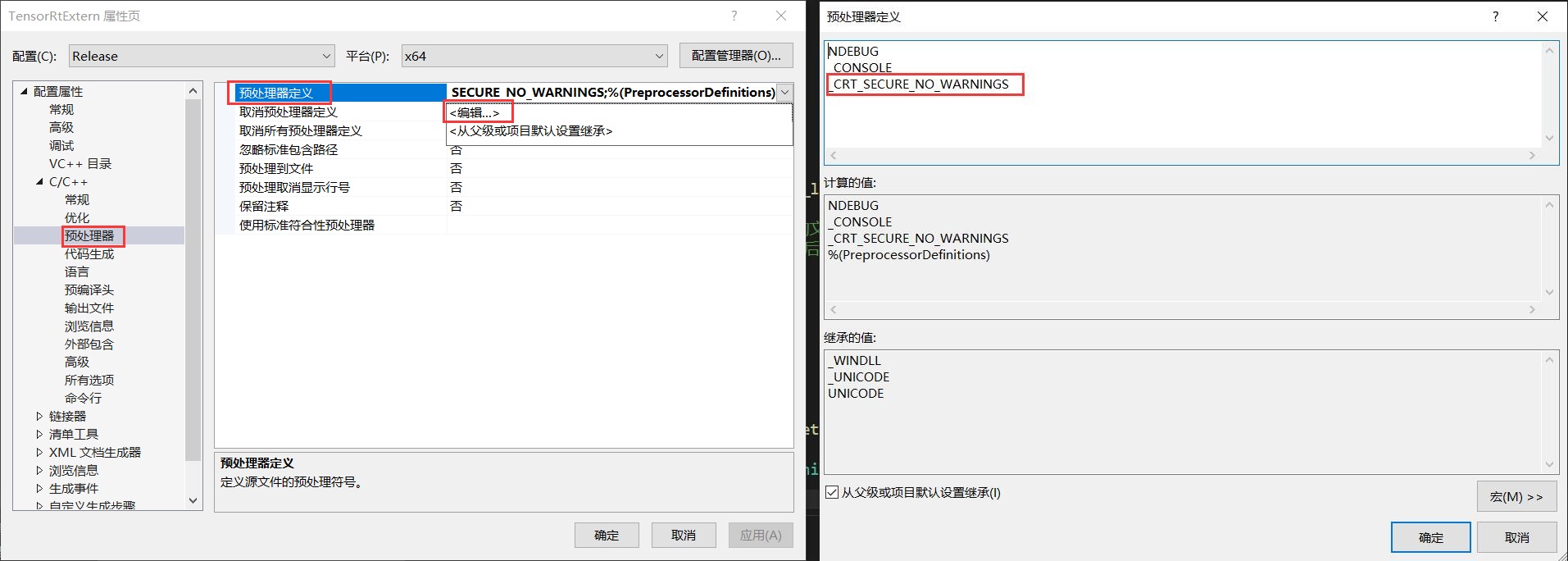
_CRT_SECURE_NO_WARNINGS
第六步:编译项目源码
接下来生成C++项目,此处选择生成,不要选择运行,如下图所示:
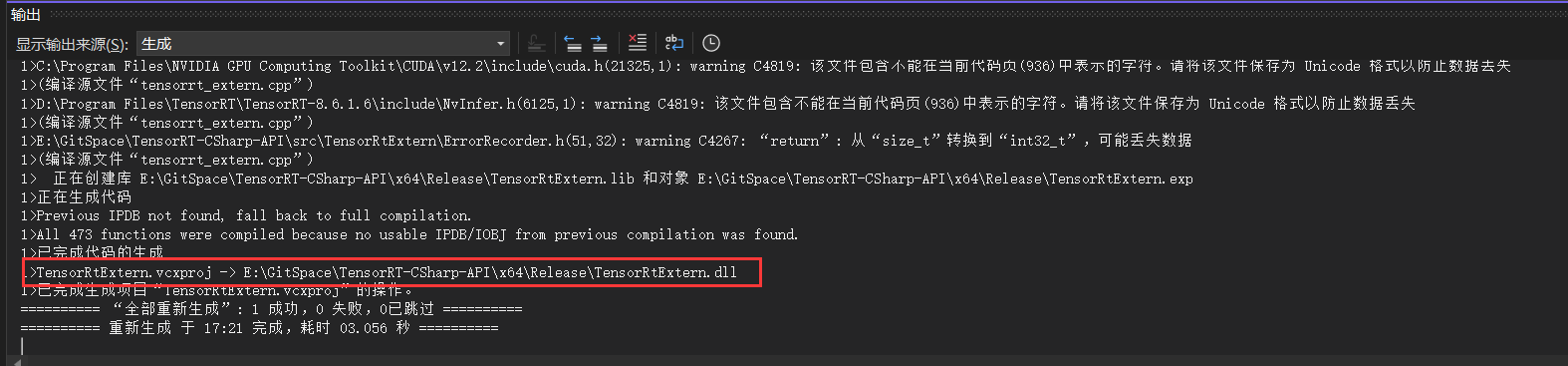
最终可以看出生成的动态链接库文件名称以及文件路径,这个路径在下一步中十分重要。
3.4 编译C#项目
接下来编译C#项目,C#项目只需要修改一下位置即可,修改NativeMethods.cs文件中的dll文件路径,该路径及上一步中C++项目生成的动态链接库文件,如下图所示:
E:\GitSpace\TensorRT-CSharp-API\x64\Release\TensorRtExtern.dll
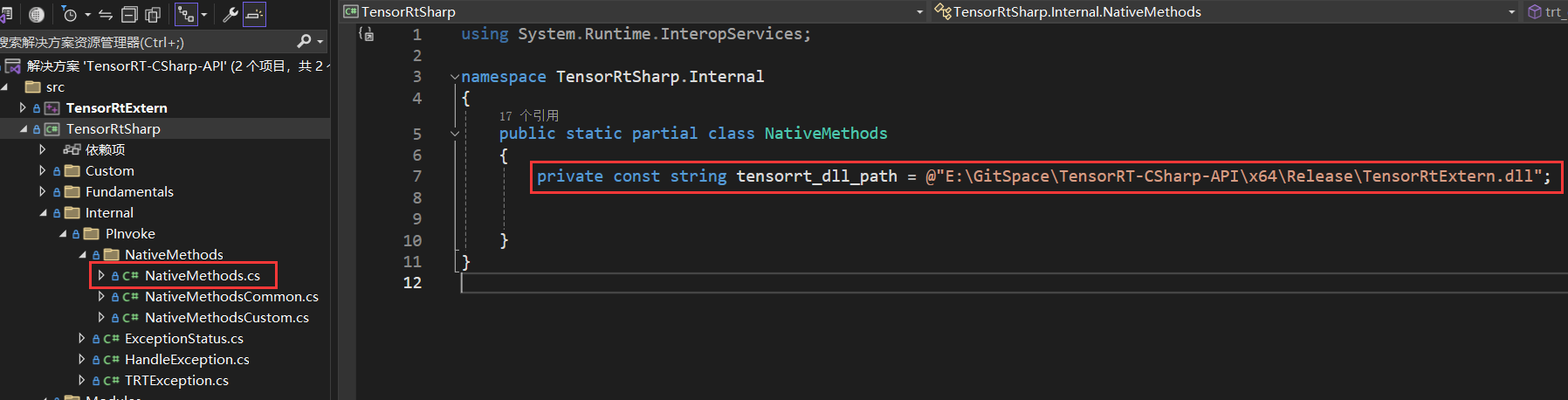
接下来就可以运行C#项目,生成类库文件,如下图所示:
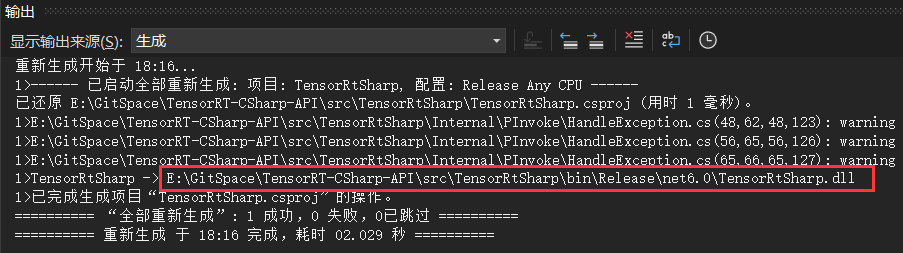
4. 接口调用
4.1 创建并配置C#项目
首先创建一个简单的C#项目,然后添加项目配置。
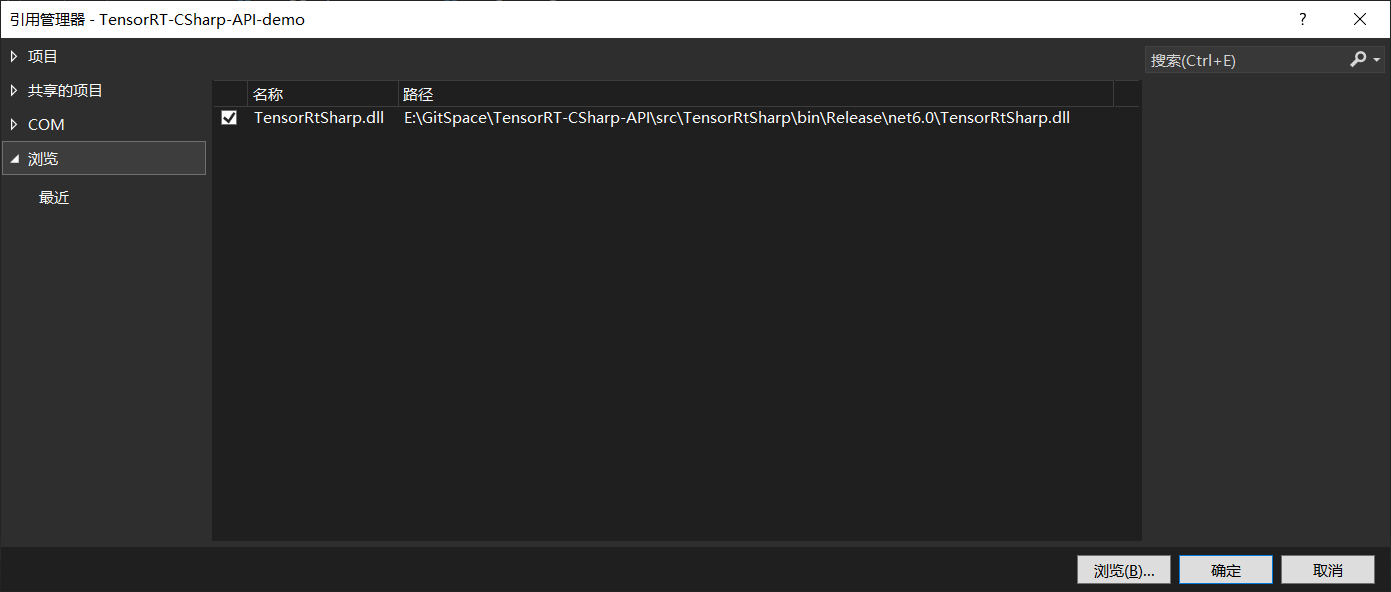
首先是添加TensorRT C# API 项目引用,如下图所示,添加上文中C#项目生成的dll文件即可。
接下来添加OpenCvSharp,此处通过NuGet Package安装即可,此处主要安装以下两个程序包即可:
 |
|
配置好项目后,项目的配置文件如下所示:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net6.0</TargetFramework>
<RootNamespace>TensorRT_CSharp_API_demo</RootNamespace>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="OpenCvSharp4.Extensions" Version="4.9.0.20240103" />
<PackageReference Include="OpenCvSharp4.Windows" Version="4.9.0.20240103" />
</ItemGroup>
<ItemGroup>
<Reference Include="TensorRtSharp">
<HintPath>E:\GitSpace\TensorRT-CSharp-API\src\TensorRtSharp\bin\Release\net6.0\TensorRtSharp.dll</HintPath>
</Reference>
</ItemGroup>
</Project>
4.2 添加推理代码
此处演示一个简单的图像分类项目,以Yolov8-cls项目为例:
static void Main(string[] args)
{
Nvinfer predictor = new Nvinfer("E:\\Model\\yolov8\\yolov8s-cls_2.engine");
Dims InputDims = predictor.GetBindingDimensions("images");
int BatchNum = InputDims.d[0];
Mat image1 = Cv2.ImRead("E:\\ModelData\\image\\demo_4.jpg");
Mat image2 = Cv2.ImRead("E:\\ModelData\\image\\demo_5.jpg");
List<Mat> images = new List<Mat>() { image1, image2 };
for (int begImgNo = 0; begImgNo < images.Count; begImgNo += BatchNum)
{
DateTime start = DateTime.Now;
int endImgNo = Math.Min(images.Count, begImgNo + BatchNum);
int batchNum = endImgNo - begImgNo;
List<Mat> normImgBatch = new List<Mat>();
int imageLen = 3 * 224 * 224;
float[] inputData = new float[2 * imageLen];
for (int ino = begImgNo; ino < endImgNo; ino++)
{
Mat input_mat = CvDnn.BlobFromImage(images[ino], 1.0 / 255.0, new OpenCvSharp.Size(224, 224), 0, true, false);
float[] data = new float[imageLen];
Marshal.Copy(input_mat.Ptr(0), data, 0, imageLen);
Array.Copy(data, 0, inputData, ino * imageLen, imageLen);
}
predictor.LoadInferenceData("images", inputData);
DateTime end = DateTime.Now;
Console.WriteLine("[ INFO ] Input image data processing time: " + (end - start).TotalMilliseconds + " ms.");
predictor.infer();
start = DateTime.Now;
predictor.infer();
end = DateTime.Now;
Console.WriteLine("[ INFO ] Model inference time: " + (end - start).TotalMilliseconds + " ms.");
start = DateTime.Now;
float[] outputData = predictor.GetInferenceResult("output0");
for (int i = 0; i < batchNum; ++i)
{
Console.WriteLine(string.Format("\n[ INFO ] Classification Top {0} result : \n", 10));
Console.WriteLine("[ INFO ] classid probability");
Console.WriteLine("[ INFO ] ------- -----------");
float[] data = new float[1000];
Array.Copy(outputData, i * 1000, data, 0, 1000);
List<int> sortResult = Argsort(new List<float>(data));
for (int j = 0; j < 10; ++j)
{
string msg = "";
msg += ("index: " + sortResult[j] + "\t");
msg += ("score: " + data[sortResult[j]] + "\t");
Console.WriteLine("[ INFO ] " + msg);
}
}
end = DateTime.Now;
Console.WriteLine("[ INFO ] Inference result processing time: " + (end - start).TotalMilliseconds + " ms.");
}
}
public static List<int> Argsort(List<float> array)
{
int arrayLen = array.Count;
List<float[]> newArray = new List<float[]> { };
for (int i = 0; i < arrayLen; i++)
{
newArray.Add(new float[] { array[i], i });
}
newArray.Sort((a, b) => b[0].CompareTo(a[0]));
List<int> arrayIndex = new List<int>();
foreach (float[] item in newArray)
{
arrayIndex.Add((int)item[1]);
}
return arrayIndex;
}
4.3 项目演示
配置好项目并编写好代码后,运行该项目,项目输出如下所示:
[03/31/2024-22:27:44] [I] [TRT] Loaded engine size: 15 MiB
[03/31/2024-22:27:44] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +12, now: CPU 0, GPU 12 (MiB)
[03/31/2024-22:27:44] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +4, now: CPU 0, GPU 16 (MiB)
[03/31/2024-22:27:44] [W] [TRT] CUDA lazy loading is not enabled. Enabling it can significantly reduce device memory usage and speed up TensorRT initialization. See "Lazy Loading" section of CUDA documentation https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#lazy-loading
[ INFO ] Input image data processing time: 6.6193 ms.
[ INFO ] Model inference time: 1.1434 ms.
[ INFO ] Classification Top 10 result :
[ INFO ] classid probability
[ INFO ] ------- -----------
[ INFO ] index: 386 score: 0.87328124
[ INFO ] index: 385 score: 0.082506955
[ INFO ] index: 101 score: 0.04416279
[ INFO ] index: 51 score: 3.5818E-05
[ INFO ] index: 48 score: 4.2115275E-06
[ INFO ] index: 354 score: 3.5188648E-06
[ INFO ] index: 474 score: 5.789438E-07
[ INFO ] index: 490 score: 5.655325E-07
[ INFO ] index: 343 score: 5.1091644E-07
[ INFO ] index: 340 score: 4.837259E-07
[ INFO ] Classification Top 10 result :
[ INFO ] classid probability
[ INFO ] ------- -----------
[ INFO ] index: 293 score: 0.89423335
[ INFO ] index: 276 score: 0.052870292
[ INFO ] index: 288 score: 0.021361532
[ INFO ] index: 290 score: 0.009259541
[ INFO ] index: 275 score: 0.0066174944
[ INFO ] index: 355 score: 0.0025512716
[ INFO ] index: 287 score: 0.0024535337
[ INFO ] index: 210 score: 0.00083151844
[ INFO ] index: 184 score: 0.0006893527
[ INFO ] index: 272 score: 0.00054959994
通过上面输出可以看出,模型推理仅需1.1434ms,大大提升了模型的推理速度。
5. 总结
在本项目中,我们开发了TensorRT C# API 2.0版本,重新封装了推理接口。并结合分类模型部署流程向大家展示了TensorRT C# API 的使用方式,方便大家快速上手使用。
为了方便各位开发者使用,此处开发了配套的演示项目,主要是基于Yolov8开发的目标检测、目标分割、人体关键点识别、图像分类以及旋转目标识别,由于时间原因,还未开发配套的技术文档,此处先行提供给大家项目源码,大家可以根据自己需求使用:
- Yolov8 Det 目标检测项目源码:
https://github.com/guojin-yan/TensorRT-CSharp-API-Samples/blob/master/model_samples/yolov8_custom/Yolov8Det.cs
- Yolov8 Seg 目标分割项目源码:
https://github.com/guojin-yan/TensorRT-CSharp-API-Samples/blob/master/model_samples/yolov8_custom/Yolov8Seg.cs
- Yolov8 Pose 人体关键点识别项目源码:
https://github.com/guojin-yan/TensorRT-CSharp-API-Samples/blob/master/model_samples/yolov8_custom/Yolov8Pose.cs
- Yolov8 Cls 图像分类项目源码:
https://github.com/guojin-yan/TensorRT-CSharp-API-Samples/blob/master/model_samples/yolov8_custom/Yolov8Cls.cs
- Yolov8 Obb 旋转目标识别项目源码:
https://github.com/guojin-yan/TensorRT-CSharp-API-Samples/blob/master/model_samples/yolov8_custom/Yolov8Obb.cs
同时对本项目开发的案例进行了时间测试,以下时间只是程序运行一次的时间,测试环境为:
CPU:i7-165G7
CUDA型号:12.2
Cudnn:8.9.3
TensorRT:8.6.1.6
| Model | Batch | 数据预处理 | 模型推理 | 结果后处理 |
|---|---|---|---|---|
| Yolov8s-Det | 2 | 25 ms | 7 ms | 20 ms |
| Yolov8s-Obb | 2 | 49 ms | 15 ms | 32 ms |
| Yolov8s-Seg | 2 | 23 ms | 8 ms | 128 ms |
| Yolov8s-Pose | 2 | 27 ms | 7 ms | 20 ms |
| Yolov8s-Cls | 2 | 16 ms | 1 ms | 3 ms |
最后如果各位开发者在使用中有任何问题,欢迎大家与我联系。

TensorRT C# API 项目介绍:基于C#与TensorRT部署深度学习模型的更多相关文章
- 28款GitHub最流行的开源机器学习项目,推荐GitHub上10 个开源深度学习框架
20 个顶尖的 Python 机器学习开源项目 机器学习 2015-06-08 22:44:30 发布 您的评价: 0.0 收藏 1收藏 我们在Github上的贡献者和提交者之中检查了用Python语 ...
- JEECG-Boot 项目介绍——基于代码生成器的快速开发平台(Springboot前后端分离)
Jeecg-Boot 是一款基于代码生成器的智能开发平台!采用前后端分离架构:SpringBoot,Mybatis,Shiro,JWT,Vue&Ant Design.强大的代码生成器让前端和后 ...
- Keras:基于Theano和TensorFlow的深度学习库
catalogue . 引言 . 一些基本概念 . Sequential模型 . 泛型模型 . 常用层 . 卷积层 . 池化层 . 递归层Recurrent . 嵌入层 Embedding 1. 引言 ...
- 基于Windows,Python,Theano的深度学习框架Keras的配置
1.安装Anaconda 面向科学计算的Python IDE--Anaconda 2.打开Anaconda Prompt 3.安装gcc环境 (1)conda update conda (2)cond ...
- 基于SpringBoot的WEB API项目的安全设计
SpringBoot的开箱即用功能,大大降低了上手一个WEB应用的门槛,友好的REST接口支持,在SpringCloud微服务体系中可编程性大大提高,本篇基于一个面向企业调用方用户的WEB API项目 ...
- 一、VUE项目BaseCms系列文章:项目介绍与环境配置
一.项目效果图预览: 二.项目介绍 基于 elementui 写一个自己的管理后台.这个系列文章的目的就是记录自己搭建整个管理后台的过程,希望能帮助到那些入门 vue + elementui 开发的小 ...
- [AI开发]将深度学习技术应用到实际项目
本文介绍如何将基于深度学习的目标检测算法应用到具体的项目开发中,体现深度学习技术在实际生产中的价值,算是AI算法的一个落地实现.本文算法部分可以参见前面几篇博客: [AI开发]Python+Tenso ...
- 大数据下基于Tensorflow框架的深度学习示例教程
近几年,信息时代的快速发展产生了海量数据,诞生了无数前沿的大数据技术与应用.在当今大数据时代的产业界,商业决策日益基于数据的分析作出.当数据膨胀到一定规模时,基于机器学习对海量复杂数据的分析更能产生较 ...
- Github上Stars最多的53个深度学习项目,TensorFlow遥遥领先
原文:https://github.com/aymericdamien/TopDeepLearning 项目名称 Stars 项目介绍 TensorFlow 29622 使用数据流图计算可扩展机器学习 ...
- 基于TensorFlow Serving的深度学习在线预估
一.前言 随着深度学习在图像.语言.广告点击率预估等各个领域不断发展,很多团队开始探索深度学习技术在业务层面的实践与应用.而在广告CTR预估方面,新模型也是层出不穷: Wide and Deep[1] ...
随机推荐
- C++ 多线程的错误和如何避免(11)
不要在对时间敏感的上下文中使用 .get() 先看下面的代码, #include "stdafx.h" #include <future> #include <i ...
- win32 - 将线程重定向到另一个函数(附带Suspend的解释)
Suspend: 挂起指定的线程 备注:不要永远挂起线程, 因为在Win32中,进程堆是线程安全的对象,并且由于在不访问堆的情况下很难在Win32中完成很多工作,因此在Win32中挂起线程极有可能使进 ...
- 【会员题】253. 会议室 II
会议室II 给定一个会议时间安排的数组,每个会议时间都会包括开始和结束的时间s1,e1,s2,e2]..](si<ei) ,为避免会议冲突,同时要考虑充分 利用会议室资源,请你计算至少需要多少间 ...
- SUB-LVDS 与LVDS 互联
SUB-LVDS 与 LVDS介绍 电气规范 今天有同学问SUB-LVDS输出是否能接到LVDS输入上,以前没用过SUB-LVDS,一起学习一下. Sub-LVDS is a differential ...
- Mysql 删除binlog日志方法
方法1 RESET MASTER; 解释: 该方法可以删除列于索引文件中的所有二进制日志,把二进制日志索引文件重新设置为空,并创建一个以.000001为后缀新的二进制日志文件. 该语法一般只用在主从环 ...
- webpack图片压缩
减少代码体积 | 尚硅谷 Web 前端之 Webpack5 教程 (yk2012.github.io) npm install image-mininizer webpack plugin image ...
- 【应用服务 App Service】 App Service Rewrite 实例 -- 限制站点的访问
问题描述 在Azure App Service中,当需要限制某些特殊的情况对其进行访问时候,可以通过IP限制,逻辑代码判断,或者Rewrite规则.通过IP限制则需要知道客户端访问的IP,而通过逻辑代 ...
- nmcli命令详解(创建热点,连接wifi,管理连接等)
目录 简述 语法 比较有用的选项(OPTION) 对象 general对象(常规信息) 用途 语法 networking对象(整个网络) 用途 语法 命令示例 radio对象(无线开关) 用途 语法 ...
- [爬坑] termux ssh 设置总是 permission denied
问题 设置ssh之后,客户端登录会提示 permission denied 的问题,经过排查最终确定是 shell设置错误的问题,解决方法如下 http://new.aidlearning.net/d ...
- 专访容智信息柴亚团:最低调的公司如何炼成最易用的RPA?
专访容智信息柴亚团:最低调的公司如何炼成最易用的RPA? 专访容智信息柴亚团:终极愿景是助力天下企业成为数字化孪生组织 文/王吉伟 6月,容智信息(容智)正式发布了全新的移动端RPA产品iBot Mo ...