Python爬虫实战系列4:天眼查公司工商信息采集
Python爬虫实战系列1:博客园cnblogs热门新闻采集
Python爬虫实战系列2:虎嗅网24小时热门新闻采集
Python爬虫实战系列3:今日BBNews编程新闻采集
Python爬虫实战系列4:天眼查公司工商信息采集
一、分析页面
打开天眼查网址 https://www.tianyancha.com/ ,随便搜索一个公司【比亚迪】
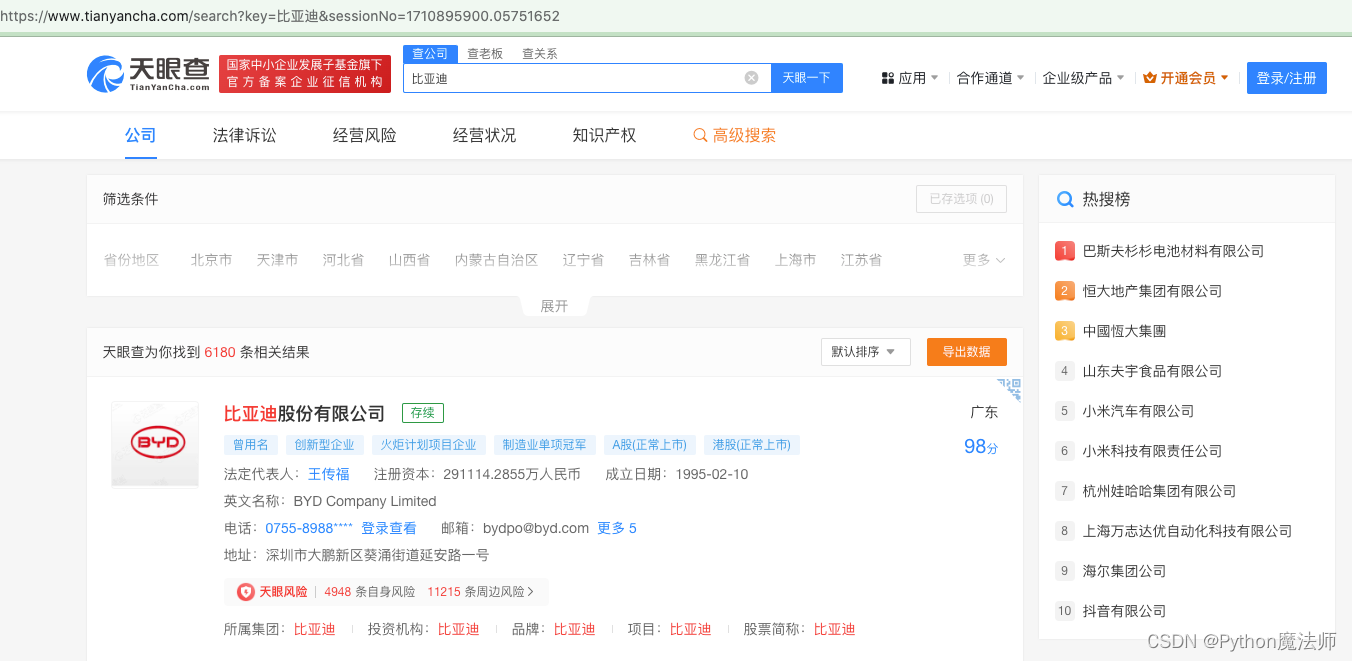
查看地址栏URL变化,由https://www.tianyancha.com变成https://www.tianyancha.com/search?key=比亚迪&sessionNo=1710895900.05751652
然后分析cookie情况,当不登陆,直接访问首页https://www.tianyancha.com时,网站会自动生成一堆cookie
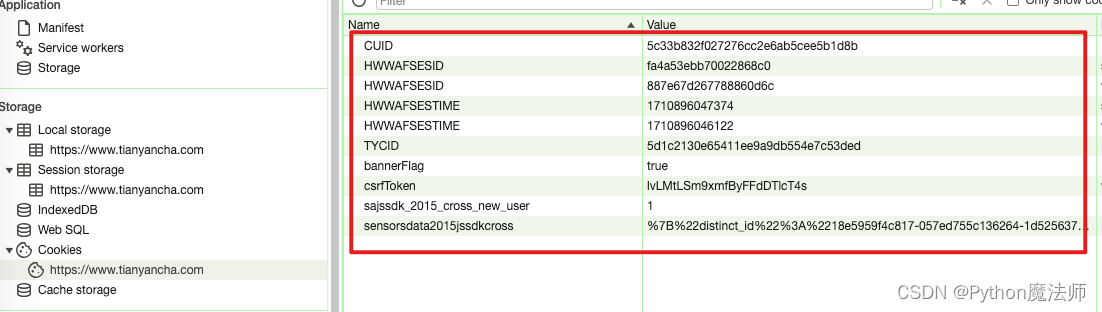
接下来查看公司详情页面,每个公司详情页都会有天眼查自己的公司id拼接出来的URL
例如:https://www.tianyancha.com/company/11807506
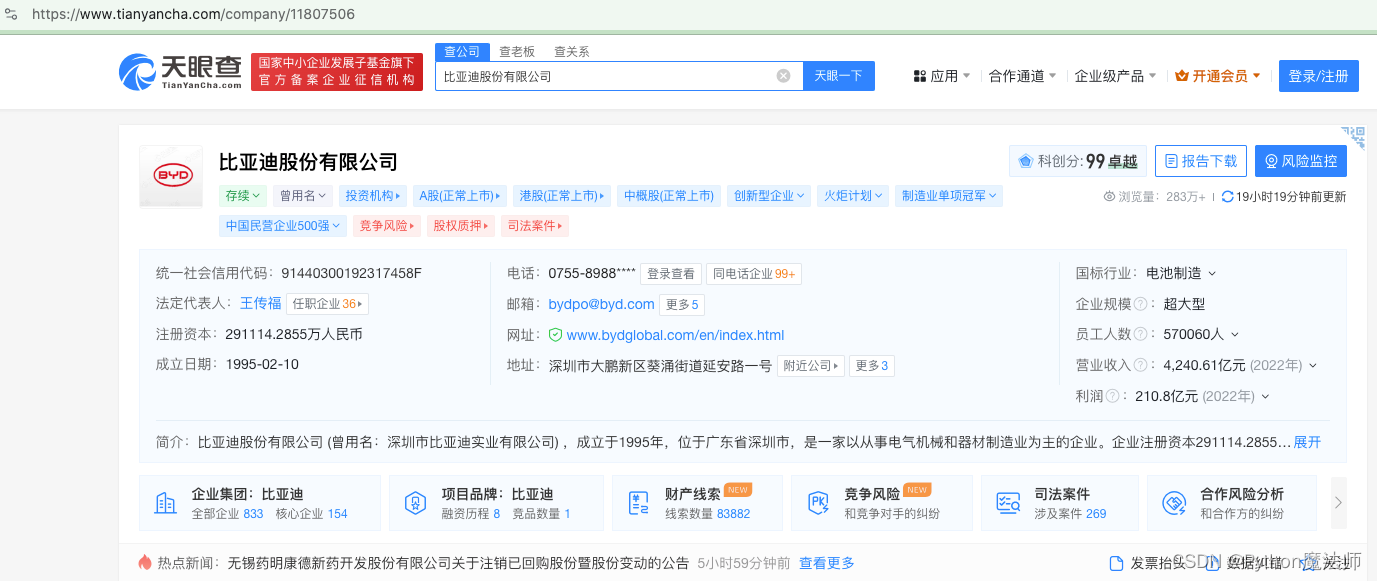
这个详情页面就是我们真正需要数据的页面
1.1、分析请求
开始分析请求,F12打开开发者模式,点击Network,然后刷新页面
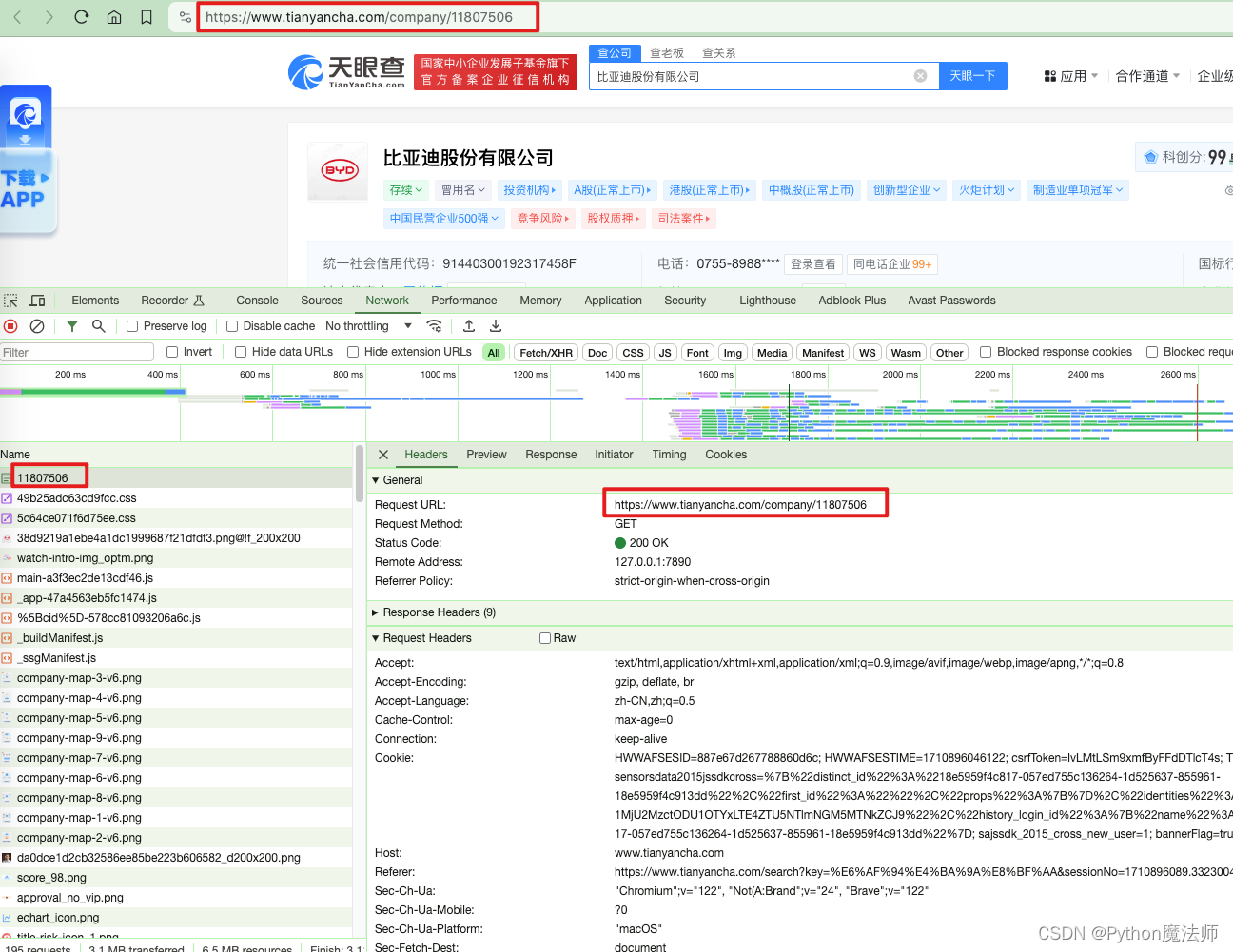
由于公司详情页都是新标签页打开的,所以请求地址也就是当前页面地址https://www.tianyancha.com/company/11807506并且该请求Response的是HTML源码,我们只需要分析该HTML代码解析处理数据即可。
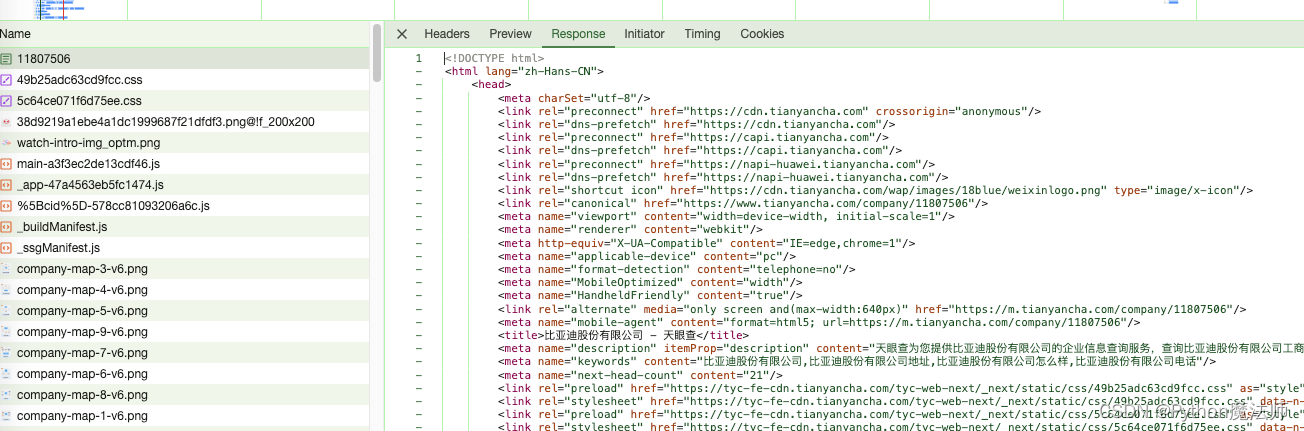
右键请求=》copy curl=》
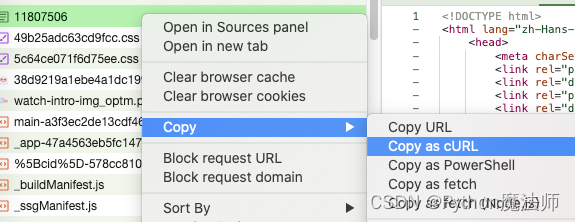
curl代码如下
curl 'https://www.tianyancha.com/company/11807506' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8' \
-H 'Accept-Language: zh-CN,zh;q=0.5' \
-H 'Cache-Control: max-age=0' \
-H 'Connection: keep-alive' \
-H 'Cookie: HWWAFSESID=887e67d267788860d6c; HWWAFSESTIME=1710896046122; csrfToken=lvLMtLSm9xmfByFFdDTlcT4s; TYCID=5d1c2130e65411ee9a9db554e7c53ded; CUID=5c33b832f027276cc2e6ab5cee5b1d8b; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218e5959f4c817-057ed755c136264-1d525637-855961-18e5959f4c913dd%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMThlNTk1OWY0YzgxNy0wNTdlZDc1NWMxMzYyNjQtMWQ1MjU2MzctODU1OTYxLTE4ZTU5NTlmNGM5MTNkZCJ9%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%2218e5959f4c817-057ed755c136264-1d525637-855961-18e5959f4c913dd%22%7D; sajssdk_2015_cross_new_user=1; bannerFlag=true; searchSessionId=1710896089.33230042' \
-H 'Referer: https://www.tianyancha.com/search?key=%E6%AF%94%E4%BA%9A%E8%BF%AA&sessionNo=1710896089.33230042' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Sec-Fetch-User: ?1' \
-H 'Sec-GPC: 1' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36' \
-H 'sec-ch-ua: "Chromium";v="122", "Not(A:Brand";v="24", "Brave";v="122"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"'
然后逐个测试哪些是请求必要参数
大部分情况下,一个请求必要参数是如下这些
- User-Agent:标识发送请求的客户端
- Content-Type:内容类型
- cookie或者Authorization
所以可以删除不必要参数进行测试,经过测试,其他不重要参数可以删除,但是删除cookie不可行,说明接口需要cookie信息
但是这个cookie怎么来的呢?
还记得上面说过,我们观察得到当我们访问首页时会自动注入一些cookie吗?
我们截止目前也没有登录,所以直接对比首页cookie和详情页cookie是否有区别即可。
分析结论:
- 详情页面请求需要cookie信息,但是该cookie可以从首页获取到
- 详情页面有反爬策略,同ip多次访问会提示需要登录,但是一个ip第一次请求时无需登录也可以请求到结果
二、代码实现
分析完请求后,我们开始代码实现,由于需要先从访问一次首页后拿到cookie才能再请求详情页
所以我们采用Python的requests的session功能,利用该session发起get和post请求,这样每次session发起请求时都会携带cookie,那我们只需要在获取session前先请求一次首页即可。
def new_session():
"""
获取session
:return:
"""
session = requests.session()
while True:
try:
session.get(url='https://www.tianyancha.com', headers=headers, timeout=(2, 2), proxies=proxies)
return session
except Exception as e:
Print.print("异常,重试...", e)
update_proxies()
注意这里我演示使用了代理proxies,当出现异常无法访问时需要更新一下代理update_proxies()
拿到session后就可以请求详情页面了
def get_co_detail(url):
"""
公司详情
:param url:
:return:
"""
session = new_session()
response = session.get(url=url, headers=headers, timeout=(2, 2), proxies=proxies)
restext = response.content.decode('utf-8', errors='ignore')
tree = etree.HTML(restext)
title = str(tree.xpath('//title/text()'))
# 公司名称
coName = tree.xpath("//h1[@class='index_company-name__LqKlo']/text()")
注意详情页面这里是先获取session,然后get请求时同样增加代理
本次学习演示只获取页面中的公司名称信息,如需请求信息可自行分析页面源码然后xpath获取
总结
- 分析请求时多注意cookie信息,分析cookie是后端生成还是前端js生成
- 如遇需要携带cookie请求时,可以采用
requests.session()创建一个session来请求
本文章代码只做学习交流使用,作者不负责任何由此引起的任何法律责任。
由于信息安全问题,这里不放源码。
各位看官,如对你有帮助欢迎点赞,收藏,转发,关注公众号【Python魔法师】获取更多Python魔法~

Python爬虫实战系列4:天眼查公司工商信息采集的更多相关文章
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二手急速响应捡垃圾平台_3(附源码持续更新)
说明 文章首发于HURUWO的博客小站,本平台做同步备份发布. 如有浏览或访问异常图片加载失败或者相关疑问可前往原博客下评论浏览. 原文链接 PYTHON爬虫实战_垃圾佬闲鱼爬虫转转爬虫数据整合自用二 ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python爬虫学习系列教程
最近想学一下Python爬虫与检索相关的知识,在网上看到这个教程,觉得挺不错的,分享给大家. 来源:http://cuiqingcai.com/1052.html 一.Python入门 1. Pyth ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- Python爬虫实战七之计算大学本学期绩点
大家好,本次为大家带来的项目是计算大学本学期绩点.首先说明的是,博主来自山东大学,有属于个人的学生成绩管理系统,需要学号密码才可以登录,不过可能广大读者没有这个学号密码,不能实际进行操作,所以最主要的 ...
随机推荐
- Kafka-启动时报错: ERROR Fatal error during KafkaServer startup. Prepare to shutdown
一.问题描述 在启动kafka时报错: ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server. ...
- Windows上同时使用有线网络及无线网络连接配置
由于公司搬到了新的办公地点,公司内部只有内网,当需要连接互联网查询资料时只能切换网络,非常麻烦.所以为了能够同时连接连接公司内网,又能够访问互联网,这里介绍如何同时连接无线和有线. 有线网络:10.3 ...
- MySQL 将执行结果保存到文件
1. 使用mysql的tee命令记录对mysql的操作过程 (1)第一种情况是在连接数据库的时候使用tee >mysql -u root -p --tee=C:/log.txt ...
- CentOS7环境源码安装python3.9
操作系统 : CentOS7.6.1810_x64 Python 版本 : 3.9.12 1.获取源代码 python官方网址: https://www.python.org/ 源码下载地址: 或者直 ...
- NC24263 USACO 2018 Feb G]Directory Traversal
题目链接 题目 题目描述 奶牛Bessie令人惊讶地精通计算机.她在牛棚的电脑里用一组文件夹储存了她所有珍贵的文件,比如: bessie/ folder1/ file1 folder2/ file2 ...
- 【Unity3D】Unity与Android交互
1 前言 本文主要介绍 Unity 打包发布 Android apk 流程.基于 AndroidJavaObject(或 AndroidJavaClass)实现 Unity 调用 Java 代码. ...
- springboot中前端ajax如何给controller提交数组参数?
说明 我有个需求,前端批量添加一堆商品明细.也就是说会有一个商品ID,然后一堆商品明细,多行. 如此一来,针对后端接口肯定是要以数组或列表方式接收这个商品明细数组了. 前端代码 关键地方在于以form ...
- .Net 6 WebAPI 使用JWT进行 授权认证配置
.Net 6 WebAPI 使用JWT进行 授权认证 1.安装组件(Nuget) Microsoft.AspNetCore.Authentication.JwtBearer 2.Program.cs ...
- 微服务程序运行步骤及nameko入门案例
首先一个微服务应用程序需要有服务的生产者和服务的消费者,另外还需要一个注册中心来管理和调度服务 1.服务提供方,即生产者启动服务,并将服务提交到注册中心注册服务 2.服务需求方,即消费者连接到注册中心 ...
- C#程序全局异常处理—WPF和Web API两种模式
C#程序的全局异常处理,网上搜下资料都是一大堆,我这里最近也是独立做一个B/S结构的小项目, 后面又增加了需求用WPF实现相同的功能,这里将我所使用的全局异常处理方式做一个简短的总结分享. Web A ...