C++常见面试题整理
- 1. CPP编译链接过程
- 2. new和malloc区别,delete和free区别
- 3. 指针和引用
- 4. 左值引用和右值引用
- 5. const
- 6. 函数重载
- 7. 函数调用栈帧开辟过程
- 8. inline 内联函数
- 9. static关键字
- 10. 定义指向类的成员的指针
- 11. this指针
- 12. 常成员方法
- 13. 函数模板与类模板
- 14. 容器空间配置器
- 15. 运算符重载
- 16. 实现一个string类
- 17. 容器迭代器实现原理
- 18. 迭代器失效问题
1. CPP编译链接过程
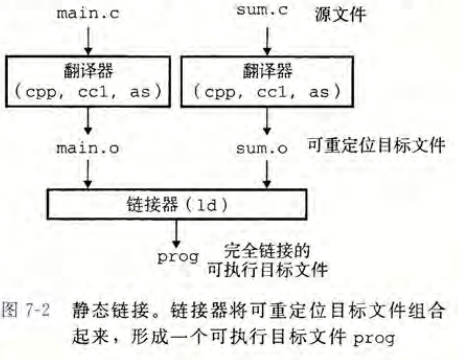
预处理
处理以#开头的命令,纯文本替换,类型不安全
#pragma lib和#pragma link除外,#pragma lib用于指定要链接的库,
#pragma link用于指定程序入口(默认入口是main函数,但可以通过该命令修改)
都是在链接阶段进行处理
编译
词法分析,语法分析,代码优化,编译生成相应平台的汇编代码
汇编
将汇编代码转成特定平台的机器码,生成二进制可重定位的目标文件(*.obj),
链接
为了构造可执行文件,链接器必须完成两个主要任务:
- 符号解析(symbol resolution) 目标文件定义和引用符号,每个符号对应于一个函数、一个全局变量或一个静态变量。符号解析的目的是将每个符号引用正好和一个符号定义关联起来。
- 重定位(relocation) 编译器和汇编器生成从地址 0 开始的代码和数据节。链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
可以参考书籍《深入理解计算机系统》第7章 链接的相关内容
相关的命令:
g++ 编译的相关命令,可以使用-E、-S、-c分别对源代码进行预处理,编译,汇编,分别生成对应的文件
| 命令 | 描述 |
|---|---|
g++ -E source_filename.cpp -o output_filename.i |
生成预处理后的 CPP 源文件(.i 文件) |
g++ -S source_filename.cpp -o output_filename.s |
生成汇编代码文件(.s 文件) |
g++ -c source_filename.cpp -o output_filename.o |
生成目标文件(.o 文件) |
objdump 可用于查看目标文件或可执行文件的一些信息
| 命令 | 描述 |
|---|---|
objdump -d 可执行文件 |
反汇编可执行文件,显示其汇编代码 |
objdump -t 可执行文件 |
显示可执行文件的符号表 |
objdump -r 可执行文件 |
显示可执行文件的重定位表 |
objdump -s 可执行文件 |
显示可执行文件的完整节(section)内容 |
objdump -h 可执行文件 |
显示可执行文件的节头表信息 |
objdump -x 可执行文件 |
显示可执行文件的全部信息 |
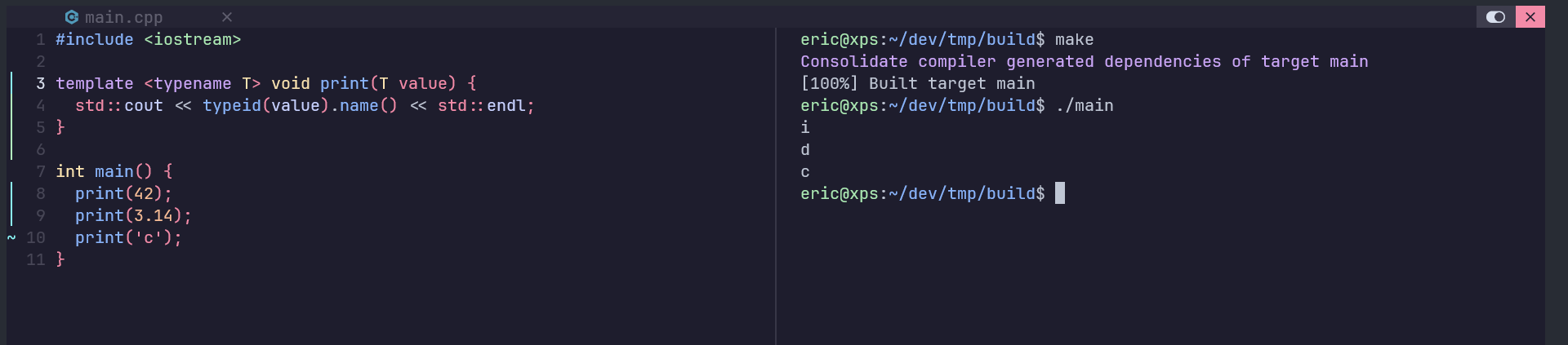
以下给出一段示例代码,我们通过objdump查看通过编译器生成的目标文件的符号信息
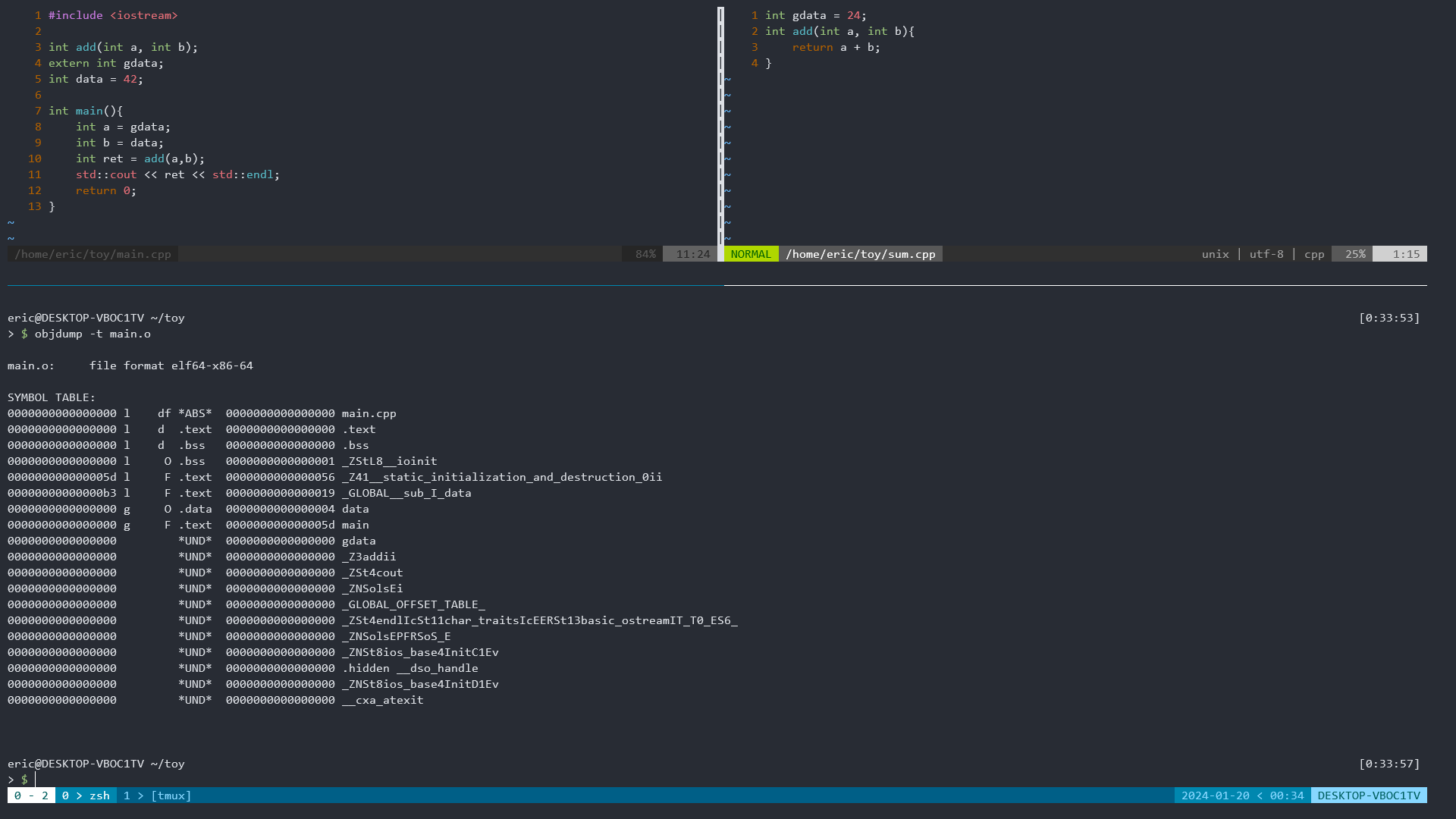
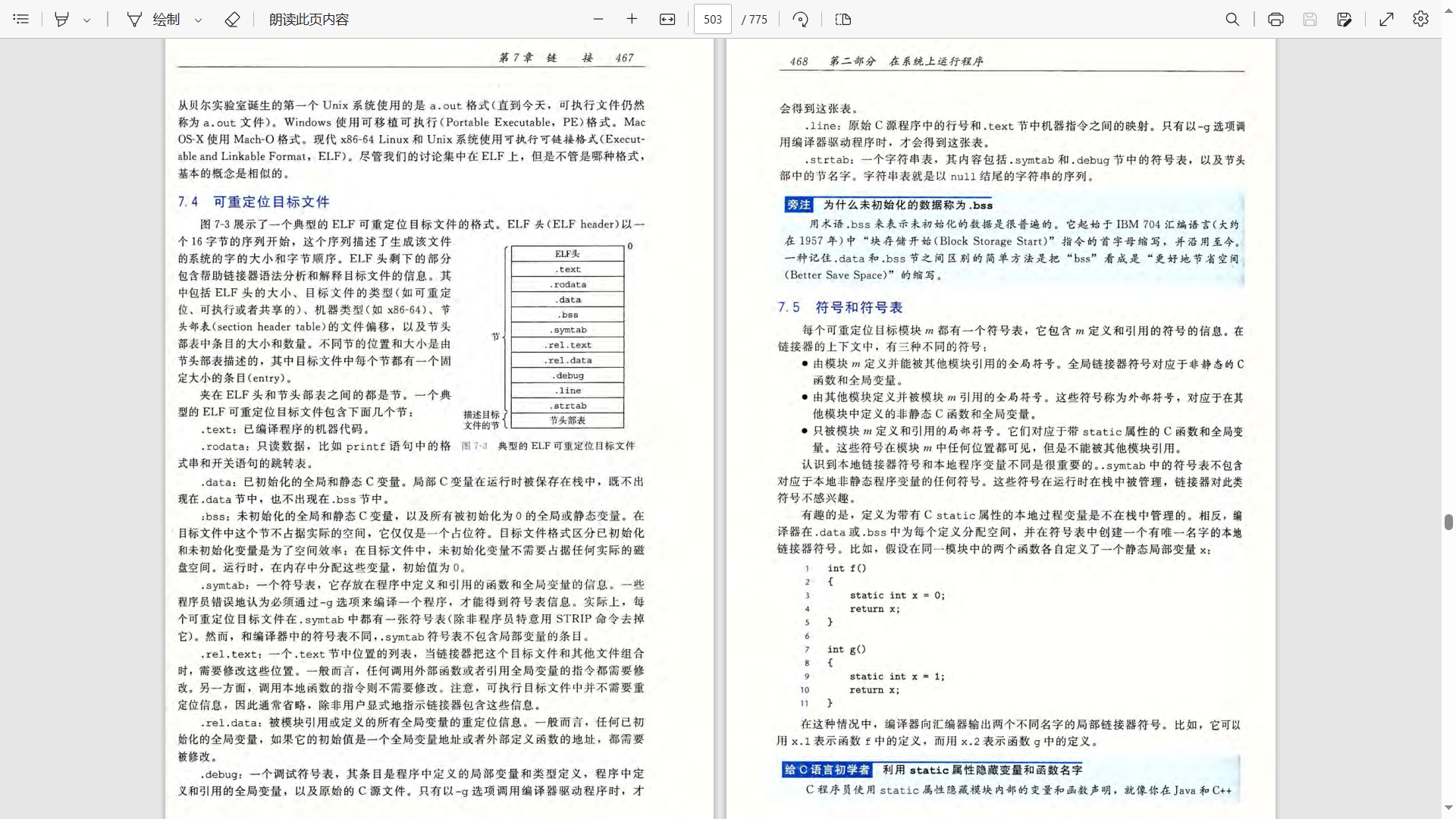
其中,每个段的具体含义可以参考以下内容,截取自书籍《深入理解计算机系统》第7章 链接
我们还可以查看这个elf文件的文件头信息,通过以下命令
objdump -h <executable>
2. new和malloc区别,delete和free区别
new 和 malloc
| 特性 | new(C++) |
malloc(C语言) |
|---|---|---|
| 内存分配 | 为特定类型的对象分配内存 | 分配指定大小的内存块 需计算内存大小 |
| 对象构造 | 调用对象的构造函数进行初始化 | 不调用构造函数 |
| 对象销毁 | 使用delete时调用对象的析构函数 |
不调用析构函数 |
| 返回类型 | 返回指向分配对象的指针 | 返回void指针(void*),需要类型强转 |
| 错误处理 | 在分配失败时抛出异常 | 在分配失败时返回空指针 |
| 内存释放 | 使用delete释放通过new分配的内存 |
使用free()释放通过malloc分配的内存 |
| 数组分配 | 支持使用new[]进行数组分配 |
支持使用malloc和calloc进行数组分配 |
delete 和 free
| 特性 | delete (C++) |
free (C) |
|---|---|---|
| 内存释放 | 释放通过 new 分配的内存 |
释放通过 malloc 或 calloc 分配的内存 |
| 对象销毁 | 调用对象的析构函数 | 不调用对象的析构函数 |
| 数组释放 | 使用 delete[] 释放通过 new[] 分配的数组内存 |
使用free释放 |
| 空指针处理 | 可以安全地删除空指针 | 可以安全地释放空指针 |
Note:
new和delete都是运算符,支持运算符重载
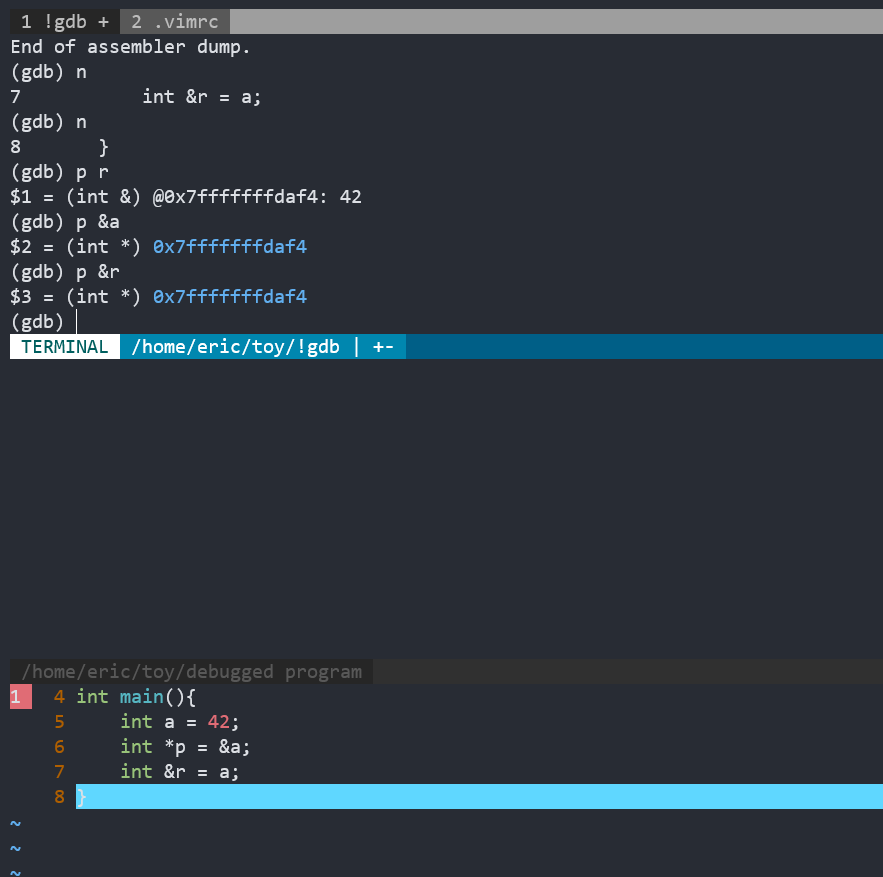
3. 指针和引用
引用是更安全的指针
int a = 42;
// 指针可以初始化为nullptr
int *p = nullptr;
p = &a;
// 引用必须初始化,且无法重新绑定
int &r = a;
底层汇编代码一样
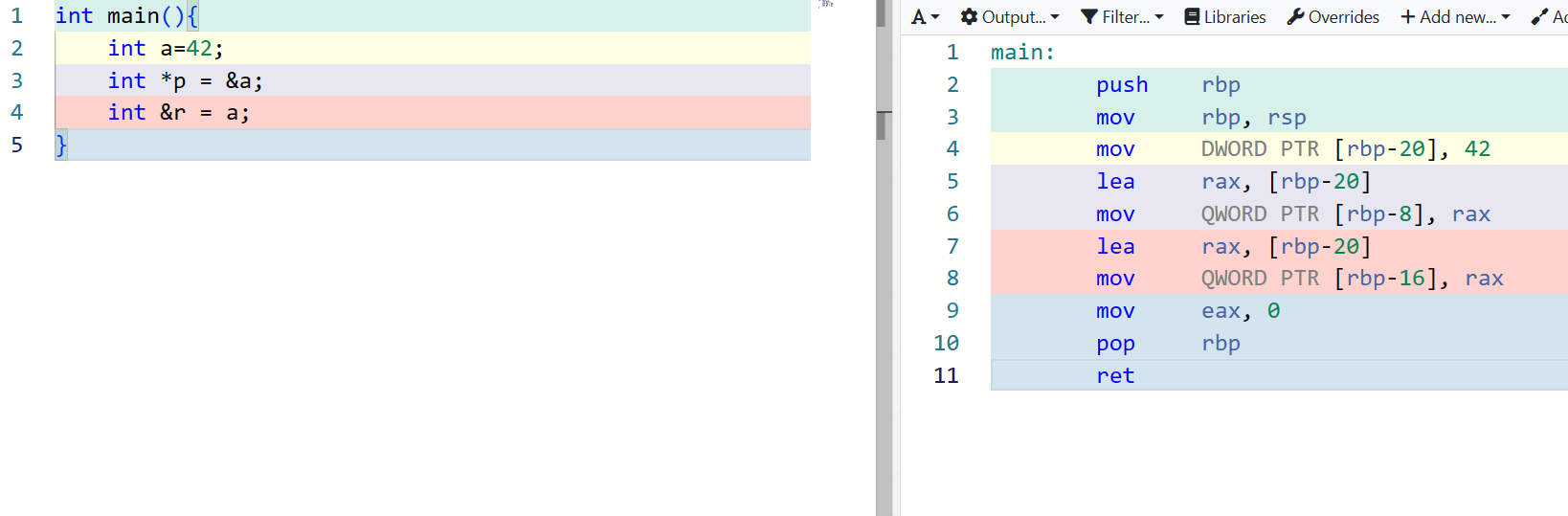
引用不占用内存空间,不是对象,只是别名而已,必须初始化,且无法重新绑定,重新对引用赋值,其实是对引用所绑定的对象赋值而非重新绑定
总结如下:
| 区别 | 引用 | 指针 |
|---|---|---|
| 语法 | 使用&声明,用对象初始化 |
使用*声明,用对象地址初始化 |
| 可空性 | 必须初始化,不可为null | 可以用null值(nullptr)初始化 |
| 对象间接访问 | 透明,可以直接使用对象语法 | 需要使用*进行显式解引用 |
| 指针运算 | 不支持,引用不是真正的内存地址 | 支持加减等运算,用于在内存中导航 |
| 重新赋值 | 初始化后无法重新指向其他对象 | 可以随时重新指向不同的对象 |
| 函数参数 | 用于通过引用传递参数 | 既可以用于通过引用传递参数,也可以作为空指针或可为空类型的参数 |
4. 左值引用和右值引用
int main(){
int a = 10; // a是左值,有名字,有内存,值可以修改
int &b = a; // b是左值引用
// int &c = 20; // 20是右值,没内存,没名字
const int &c = 20;
// C++11提供了右值引用
int &&d = 20; // d是右值引用
d = 30;
int &e = d; // d是右值引用,右值引用本身是一个左值
}
Note: 重点理解,一个右值引用变量本身是一个左值,可以被修改,可以被引用
TODO
SEE ALSO
- 移动语义
- [] 完美转发
- [] 引用折叠
5. const
const 修饰的变量不能再作为左值,初始化完成后,值不能被修改
const和非const类型之间(无论哪一层的const)在不破坏类型安全的前提下,是可以进行自动类型转换的,所以才能相互赋值(或初始化)。
比如int*和const int*,把const int*赋值给int*是错误的,因为这可能导致int*指向一个const int,从而破坏类型安全。
但反过来把int*赋值给const int*则是安全的。
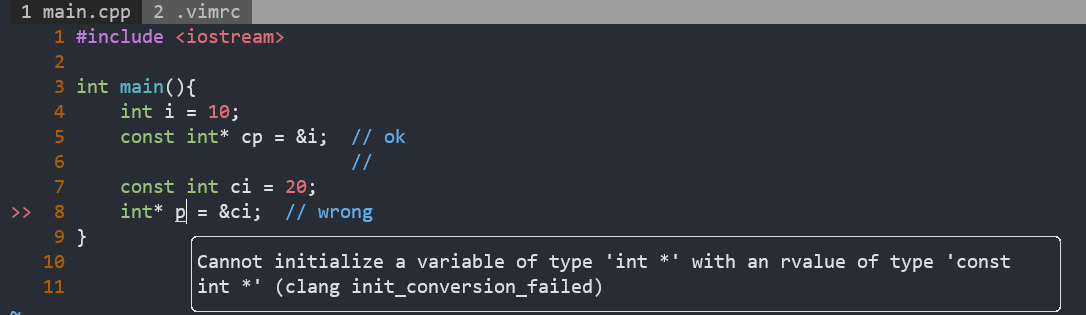
虽然,把int*赋值给const int*是正确的,但是把int**赋值给const int**却是错误的。乍一看这两种转换非常相似,都是加一个底层const,但实际上前者确实是安全的,后者却会引入致命的漏洞。
int* p = nullptr;
const int** cpp = &p; // 假如这行代码是正确的...
const int ci = 0;
*cpp = &ci; // ???
关注最后这个赋值,cpp是const int**,所以等号左边*cpp的类型是const int*,ci是const int,所以等号右边&ci的类型是const int*,类型完全匹配,看起来毫无问题。然而实际上,*cpp返回的这个引用是绑定在p上的,也就是说这个赋值的语义是把p指向了ci,而实际上p是个int*而非const int*。
也就是说,把int**赋值给const int**,这个多出的const可以把一个原本错误的赋值伪装得人畜无害。所以这种转换是错误的。到这里已经很容易理解为什么int**赋值给const int* const*是正确的——在上面这个例子中,假如cpp的类型改成const int* const*,那么*cpp返回的就是一个常量,根本不能赋值,自然就没有这个问题了。所以int**到const int* const*的转换是安全的,因此被允许。
Note: 多级指针T可以隐式转换到有更多const限定符的类型,但是如果某一层加上了const,那么右边每层都必须有const
内容节选自C++ 底层const二级指针为何能被非const指针初始化? - 张三的回答 - 知乎
而在分析引用时,我们总是可以把引用转化为指针来分析
int i = 10;
int &r = i;
// 我们总可以把上面的代码转化为
int *r = &i;
在处理更复杂的引用时,也总是可以这样进行转化来分析。
#define, const, constexpr, consteval 比较
| 关键字 | 描述 |
|---|---|
#define |
#define 是C++中的预处理指令。它用于定义宏,宏是表示一系列记号的符号名称。宏在编译阶段之前由预处理器处理。它们可用于文本替换、定义常量或创建类似函数的宏。 |
const |
const 是一个关键字,用于将变量声明为常量。当变量声明为const时,其值变为只读,在初始化后无法修改。它在运行时解析,不提供编译时评估(即不保证编译时只读,仅保证运行时只读)。 |
constexpr |
constexpr 是C++11引入的关键字。它用于声明一个值或表达式可以在编译时评估。它允许在编译期间进行计算,从而可能提高性能。constexpr 变量和函数使得编译时评估成为可能。 |
consteval |
consteval 是C++20引入的关键字。它用于指定函数必须在编译时评估。它限制了函数只能在常量表达式上下文中调用。consteval 函数保证在编译时完全评估,从而实现了优化和编译时错误检查。 |
6. 函数重载
函数重载:一组函数,在同一个作用域下,函数名相同,参数列表的个数或者类型不同
Note:
- 注意必须处于同一个作用域下
- 静态(编译时期)多态包括函数重载和模板
- 仅仅返回值类型不同不叫函数重载
- 还需要注意const和volatile是如何影响形参类型的(进而影响函数重载)
C++为什么支持函数重载(C语言不支持)
C代码产生函数符号时,符号仅由函数名决定
C++代码产生函数符号时,符号由函数名和参数列表决定
C++代码和C代码之间如何互相调用
C++代码中调用C代码
add.c文件
int add(int a, int b){
return a + b;
}
main.cpp文件
int add(int a, int b);
int main(){
add(1, 2);
}
上述代码会出现链接错误,main.cpp文件中使用到了add函数,这个函数的声明一般是c库的作者对外提供一份头文件,而c库的使用者将通过#include来使用这个c库,那么这个函数的声明在编译时,将通过c++语法规则生成对应的函数符号,这个函数符号生成规则与c编译器是不同的(这也是c不支持函数重载的原因,因为c的函数符号仅由函数名生成),所以在链接时,是无法找到这个函数的。
正确的处理办法如下
#ifdef __cplusplus
extern "C"
{
#endif
int add(int a, int b);
#ifdef __cplusplus
}
#endif
__cplusplus是c++编译器内置的宏,其值一般是C++标准的年份,用于区分不同的C++标准。C编译器中没有这个宏,且C编译器不认识extern "C"这个语法。
上述代码在C++编译器看来就是
extern "C"
{
int add(int a, int b);
}
那么C++编译器就会按照C标准生成函数符号,从而成功链接
C代码中调用C++代码 (比较少见)
add.cpp文件
#ifdef __cplusplus
extern "C"
{
#endif
int add(int a, int b){
return a + b;
}
#ifdef __cplusplus
}
#endif
C++编译器会将上面的代码按照C标准生成函数符号,提供给C程序使用
main.c文件
int add(int a, int b);
int main(){
add(1, 2);
}
7. 函数调用栈帧开辟过程
一些前置知识:
- 程序计数器 (Program Counter,PC)保持跟踪下一条要执行的指令的地址。在每个指令执行完成后,程序计数器自动递增,将控制转移到下一条指令
- rbp存放当前栈帧的基地址
- rsp存放当前栈帧的栈顶地址,且始终指向栈顶
- 栈帧是由高地址向低地址方向开辟的,当函数被调用时,新的栈帧会被分配在栈的顶部,栈指针向低地址移动以留出空间。栈帧包含了函数的局部变量、参数、返回地址和其他临时数据(堆是由低地址向高地址方向增长的)。
- 32位模式下,指针占4字节,64位模式下,占8字节
- CALL指令会将当前指令的下一条指令的地址(即CALL指令后面的指令)压入栈中。这是为了在子程序执行完毕后能够返回到CALL指令后面的指令。
- 子程序执行完毕后,通过RET(返回)指令返回到CALL指令后面的指令。CALL指令之后的指令地址被弹出栈,恢复为当前指令的下一条指令地址。
- eax(累加器寄存器)是一个32位的通用寄存器,用于存储算术和逻辑运算的结果,以及函数返回值
- edx(数据寄存器)也是一个32位的通用寄存器,用于存储除法和乘法运算的结果
- esi(源索引寄存器)是用于数据传输和字符串操作的32位通用寄存器。它通常用作源数据或源地址的索引
- edi(目的索引寄存器)是另一个32位的通用寄存器,也用于数据传输和字符串操作。它通常用作目标数据或目标地址的索引
Note:
- rbp是64位模式下的基址指针寄存器,ebp是32位模式下的基址指针寄存器
- rsp是64位模式下的栈指针寄存器,esp是32位模式下的栈指针寄存器
这里对以下代码中的函数调用的栈帧进行详细分析:
int add(int a, int b)
{
int result = a + b;
return result;
}
int main()
{
int answer;
answer = add(40, 2);
}
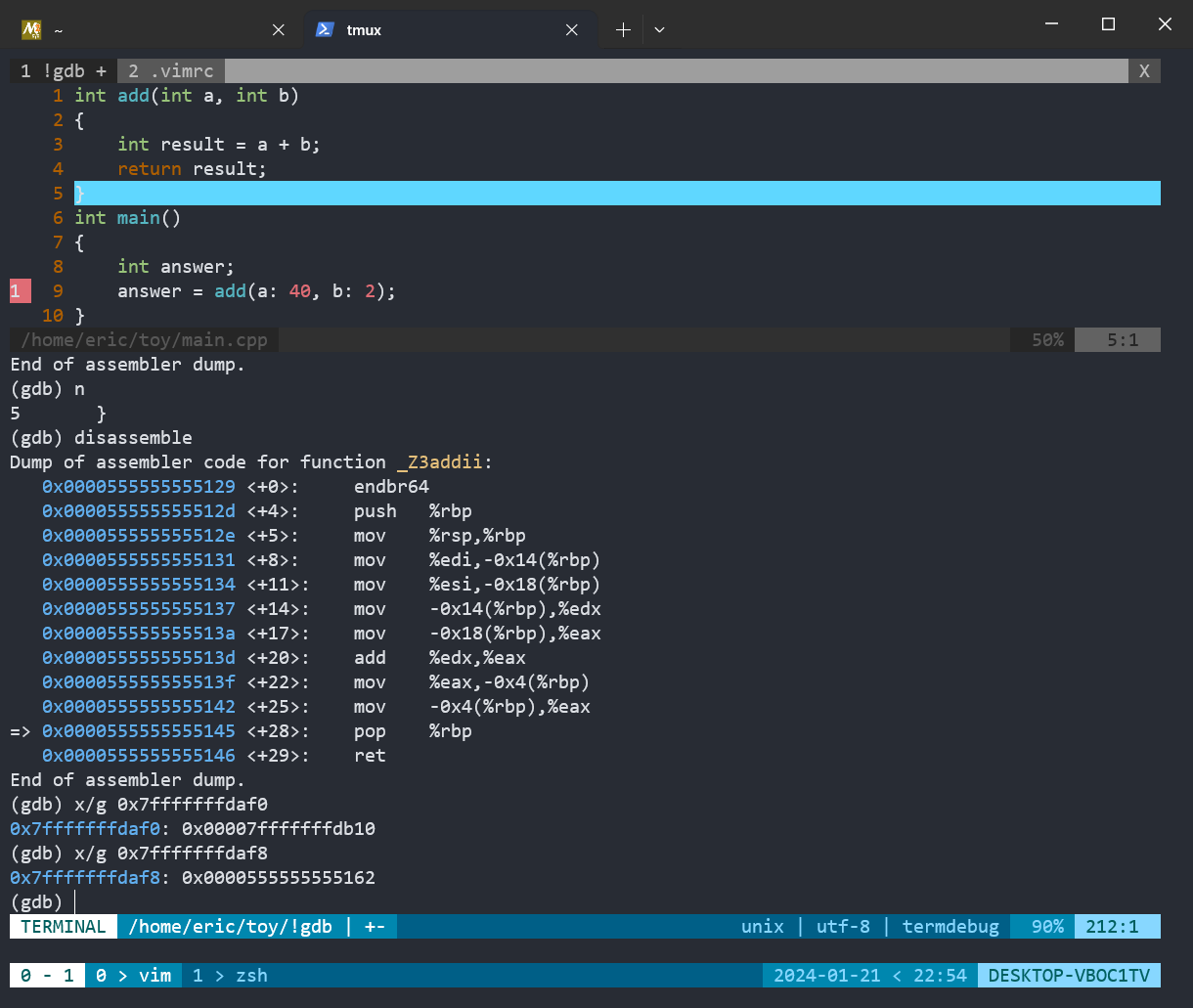
通过vim的termdebug模式,我们可以方便的查看这段程序的反汇编指令和查看内存,这将帮助我们理解栈帧开辟的具体过程。这里先给出四张截图,
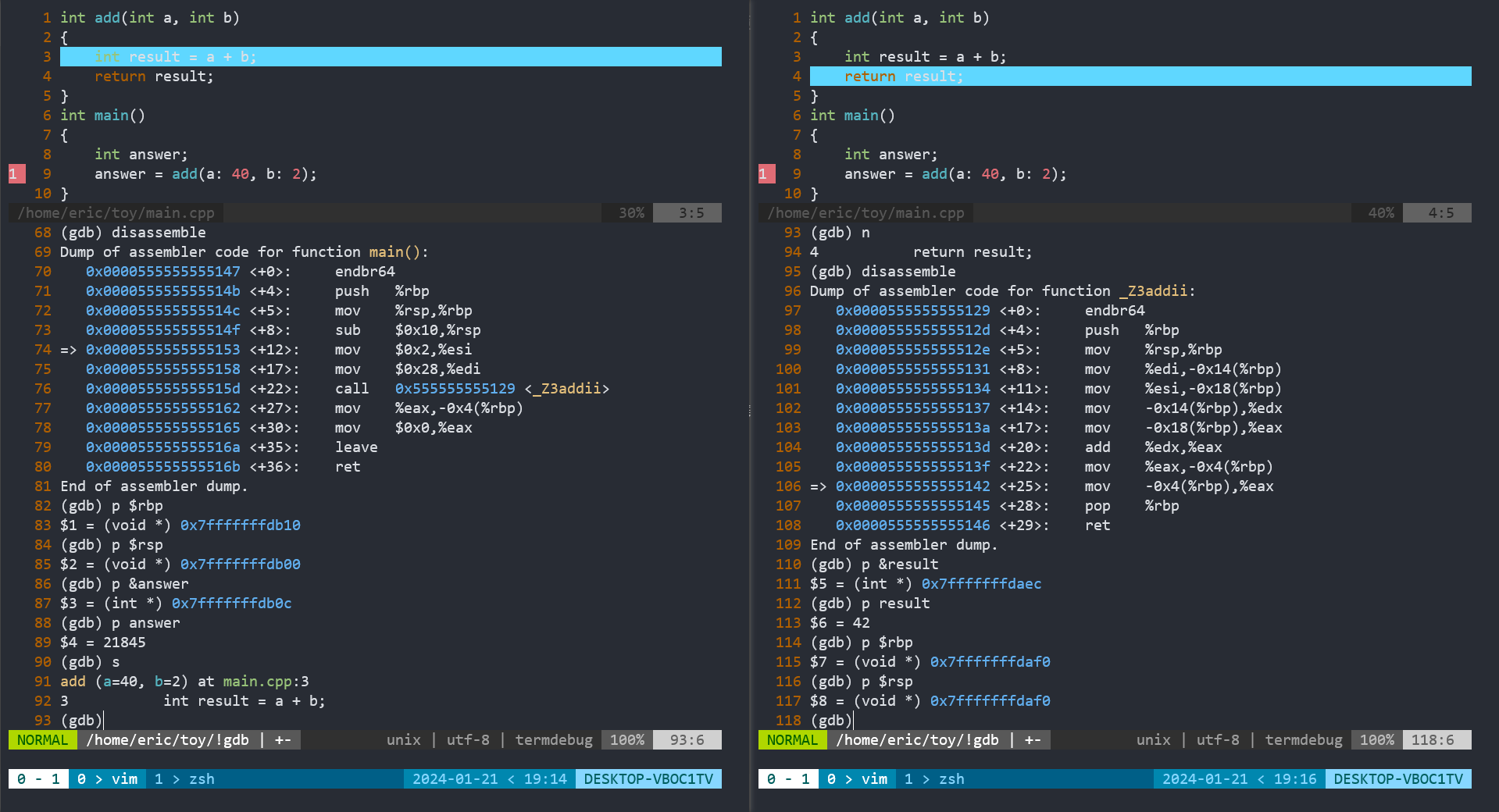
图一图二是通过gdb对程序进行调试,并使用命令查看变量和寄存器以及反汇编指令
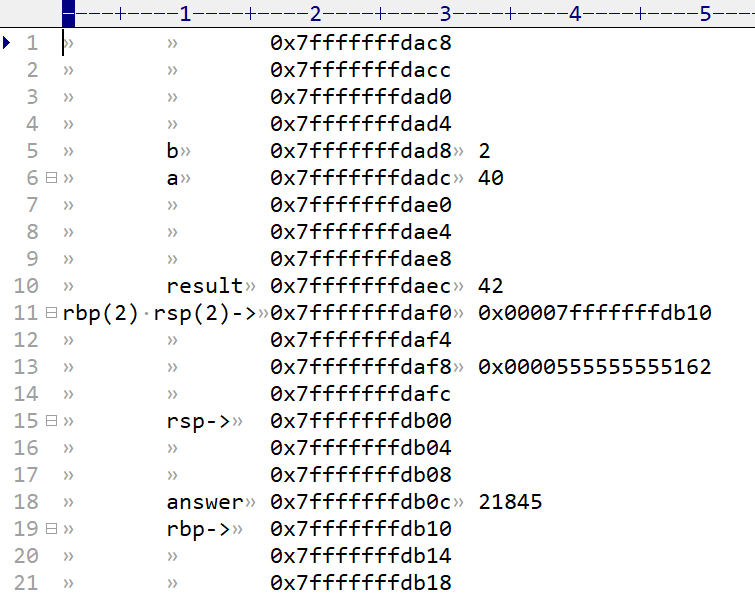
图三是这段程序的栈帧,最左边有记录着变量和 rbp,rsp的位置,中间是内存地址,下面是高地址,上面是低地址,即栈帧是从下往上开辟的,最右边是对应的内存中存储的值。
Note: rbp,rsp表示main函数栈帧,rbp(2),rsp(2)表示add函数的栈帧
我们先分析main函数的汇编代码,
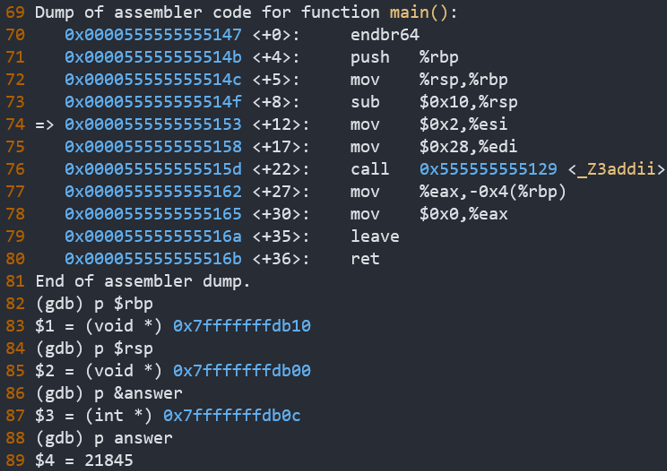
为了节约篇幅,这里截取部分指令地址,
147 <+0>: endbr64
14b <+4>: push %rbp //rbp入栈,main函数执行完后,回退到之前的栈帧
14c <+5>: mov %rsp,%rbp //把rsp赋值给rbp
14f <+8>: sub $0x10,%rsp //rsp向低地址移动16字节,即main函数的栈帧,就是16bytes
153 <+12>: mov $0x2,%esi //把立即数2赋值给esi寄存器
158 <+17>: mov $0x28,%edi //把立即数40赋值给edi寄存器
15d <+22>: call 0x555555555129 <_Z3addii> //调用add函数
162 <+27>: mov %eax,-0x4(%rbp) //把eax寄存器中存放的值赋值给rbp-4(也就是answer)
165 <+30>: mov $0x0,%eax //把0赋给eax寄存器
16a <+35>: leave
16b <+36>: ret
main函数中的栈帧在0x7fffffffdb10 到 0x7fffffffdb00之间,如下所示
rsp-> 0x7fffffffdb00
0x7fffffffdb04
0x7fffffffdb08
answer 0x7fffffffdb0c 21845
rbp-> 0x7fffffffdb10
0x7fffffffdb14
汇编代码执行到0x000055555555515d <+22>: call 0x555555555129 <_Z3addii>时,会把call指令的下一条指令地址压栈,即把指令地址0x0000555555555162压栈,然后将控制转移到指定的目标地址,即子程序的入口点。控制转移后,程序开始执行子程序中的代码。
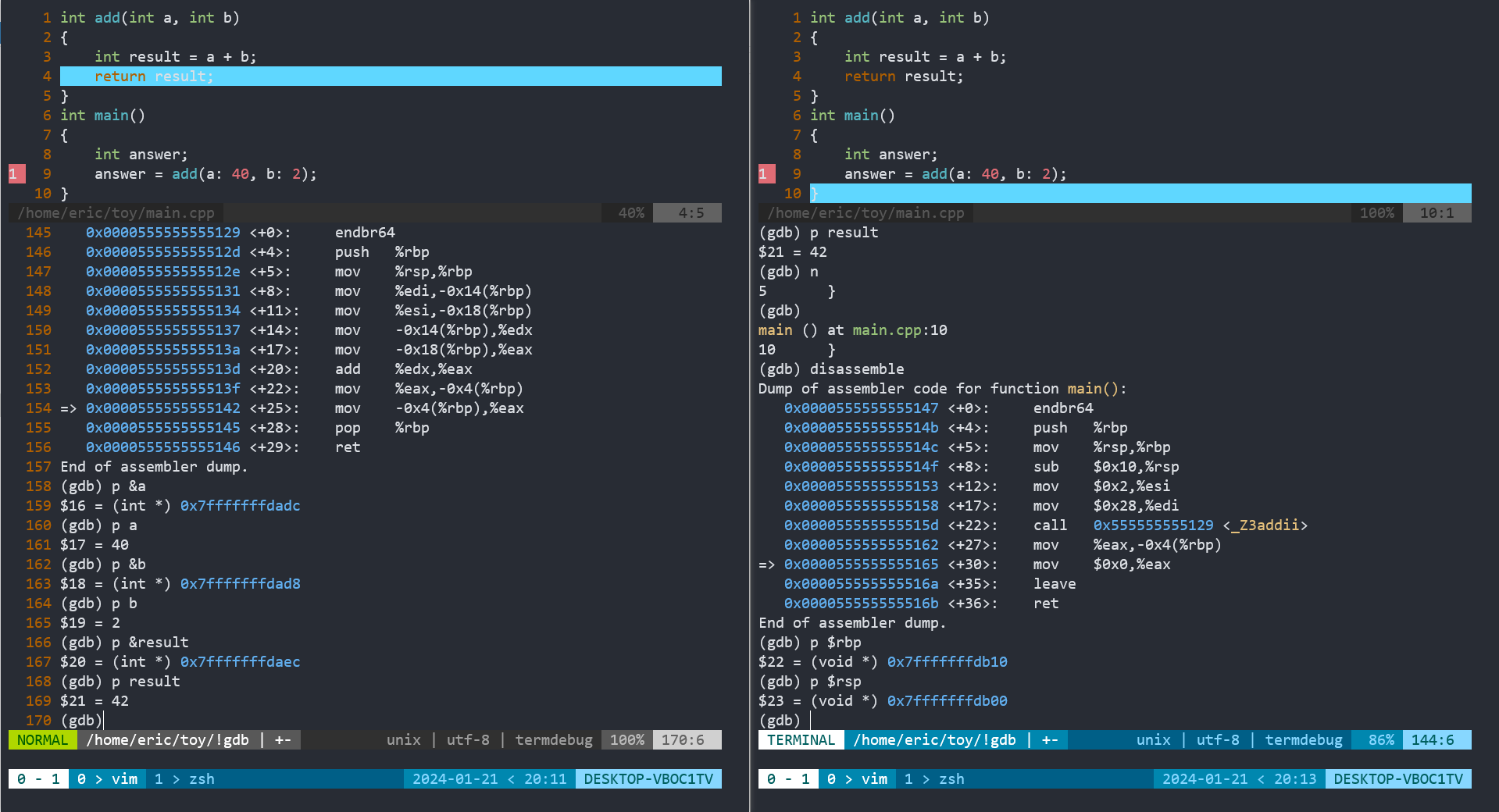
此时,我们再看图一右半部分,
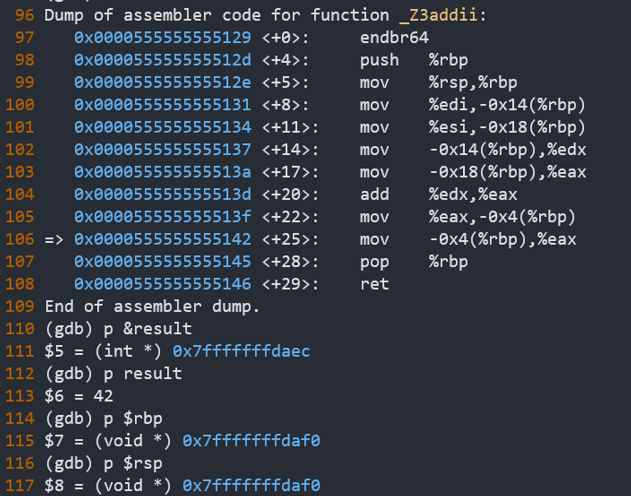
129 <+0>: endbr64
12d <+4>: push %rbp //rbp压栈
12e <+5>: mov %rsp,%rbp //rsp赋给rbp
131 <+8>: mov %edi,-0x14(%rbp) //把edi寄存器中的值赋给rbp-0x14
134 <+11>: mov %esi,-0x18(%rbp) //把esi寄存器中的值赋给rbp-0x18
137 <+14>: mov -0x14(%rbp),%edx //把rbp-0x14中的值赋给edx
13a <+17>: mov -0x18(%rbp),%eax //把rbp-0x18中的值赋给eax
13d <+20>: add %edx,%eax //把edx中的值加到eax中
13f <+22>: mov %eax,-0x4(%rbp) //把eax的值赋给rbp-0x4
142 <+25>: mov -0x4(%rbp),%eax //把rbp-0x4的值赋给eax
145 <+28>: pop %rbp //弹出栈顶的值,赋给rbp(即退回到main的栈底)
146 <+29>: ret //CALL指令之后的指令地址被弹出栈,恢复为当前指令的下一条指令地址
其对应的栈帧为
b 0x7fffffffdad8 2
a 0x7fffffffdadc 40
0x7fffffffdae0
0x7fffffffdae4
0x7fffffffdae8
result 0x7fffffffdaec 42
rbp(2) rsp(2)-> 0x7fffffffdaf0 0x00007fffffffdb10
0x7fffffffdaf4
0x7fffffffdaf8 0x0000555555555162
0x7fffffffdafc
rsp-> 0x7fffffffdb00
0x7fffffffdb04
0x7fffffffdb08
answer 0x7fffffffdb0c 21845
rbp-> 0x7fffffffdb10
0x7fffffffdb14
0x7fffffffdb18
图二给出了
- add函数执行完之后,参数a,b和result的地址和值(左半部分)
- 返回到main函数中,成功恢复到之前的栈帧(右半部分)
重点关注以下问题:
- add函数调用,参数是如何传递的
- add函数执行完,返回值是如何传递的
- add执行完后,怎么知道回到哪个函数中
- 回到main以后,如何知道从哪一行指令继续执行的
以下给出解答:
add函数调用,参数是如何传递的
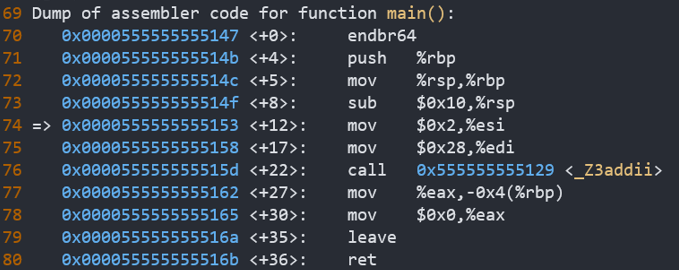
main函数中,在执行call指令之前,已经把实参传递到esi和edi通用寄存器中了,
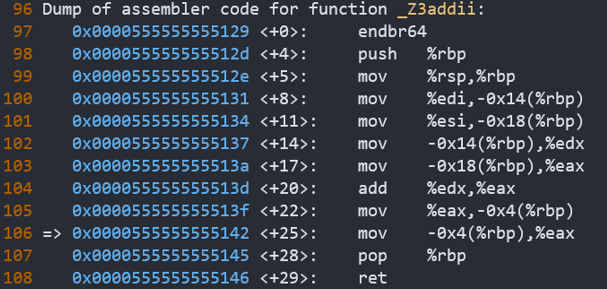
add函数中,从esi和edi通用寄存器中,把实参取出,分别放到了rbp-0x18和rbp-0x14中
add函数执行完,返回值是如何传递的
add函数中,把rbp-0x18和rbp-0x14中存放的实参,分别赋给了eax和edx寄存器,执行加法操作后,最终结果存放在eax中,然后赋给rbp-0x4,即result局部变量,然后把这个结果赋给eax寄存器,而main函数中,在call指令之后,mov %eax,-0x4(%rbp) 指令从eax寄存器中取出了返回值,放到了rbp-4即answer局部变量中
add执行完后,怎么知道回到哪个函数中,回到main以后,如何知道从哪一行指令继续执行的
- 在main函数中,调用call指令时,这个指令会把call指令后的下一条指令地址压栈 即
0x0000555555555162压入栈中; - 随后在add函数中,会把main函数栈帧的rbp压入栈中,即
0x00007fffffffdb10压入栈中; - add函数执行完毕,会执行
pop rbp指令,把0x00007fffffffdb10弹出栈,赋给rbp,此时就是回到了main函数的栈帧了; - 最后,
ret指令会把CALL指令之后的指令地址弹出栈,即把0x0000555555555162弹出栈赋给pc,恢复为当前指令的下一条指令地址。
这里给出一个截图,可以看到call指令后的下一条指令地址和rbp确实先后压入栈中了
再补充一个例子,这个例子节选自函数调用过程中栈到底是怎么压入和弹出的? - 一八七四的回答 - 知乎
void func_B(arg_B1, arg_B2){
var_B1;
var_B2;
}
void func_A(arg_A1, arg_A2){
var_A;
func_B(arg_B1, arg_B2);
}
int main(int argc, char *argv[], char **envp){
func_A(arg_A1, arg_A2);
}
8. inline 内联函数
内联函数
- 没有函数调用开销,直接在调用点处进行代码展开
- 不再产生函数符号
- inline只是建议编译器处理为内联,但是否采用取决于代码的复杂程度
- 在debug模式下,内联不起作用
- 类内部定义的函数 默认内联
9. static关键字
static关键字
- 静态成员变量:类的所有对象之间共享的变量,而不是每个对象拥有自己的副本。静态成员变量必须在类的定义外部进行初始化。
class MyClass {
public:
static int count;
};
// 必须在类的定义外部进行初始化
int MyClass::count = 0;
int main() {
MyClass obj1;
MyClass obj2;
obj1.count = 5;
cout << obj2.count; // 输出 5,因为 count 是静态成员变量,obj1 和 obj2 共享同一个变量
return 0;
}
- 静态成员函数:不依赖于类的任何对象,因此无需通过对象进行调用,可以直接使用类名加作用域解析运算符来调用。静态成员函数不能访问非静态成员变量,只能访问静态成员变量。
class MyClass {
public:
static void printMessage() {
cout << "Hello, World!" << endl;
}
};
int main() {
MyClass::printMessage(); // 输出 Hello, World!
return 0;
}
- 静态局部变量: 静态局部变量在第一次执行到其声明语句时初始化,并在函数调用之间保持其值。
void foo() {
static int counter = 0;
counter++;
cout << "Counter: " << counter << endl;
}
int main() {
foo(); // 输出 Counter: 1
foo(); // 输出 Counter: 2
foo(); // 输出 Counter: 3
return 0;
}
- 静态全局变量:在全局作用域内声明的静态变量,其作用范围仅限于当前源文件。它与普通的全局变量类似,但只能在声明它的源文件中访问,其他源文件无法直接访问该变量。
Note: 静态全局变量的主要特点是它们具有文件作用域(File Scope)和内部链接(Internal Linkage)。文件作用域意味着该变量在声明它的源文件中的任何位置都是可见的。内部链接意味着该变量只能在声明它的源文件中访问,其他源文件无法直接访问。
- 静态全局函数:全局作用域内声明的静态函数,其作用范围仅限于当前源文件。静态全局函数只能在声明它的源文件中访问,其他源文件无法直接调用该函数。
10. 定义指向类的成员的指针
类的普通成员变量和普通成员
#include <iostream>
using namespace std;
class MyClass {
public:
static int staticValue;
int value;
static void staticFunction() {
cout << "Static Function" << endl;
}
void printValue() {
cout << "Value: " << value << endl;
}
};
// 静态成员变量必须在类外定义
int MyClass::staticValue = 42;
int main() {
MyClass obj;
obj.value = 10;
// 定义指向成员变量的指针
int MyClass::*ptr = &MyClass::value;
// 定义指向静态成员变量的指针
int* staticPtr = &MyClass::staticValue;
// 通过指针访问和修改成员变量
obj.*ptr = 100;
*staticPtr = 200;
cout << "Modified Value: " << obj.value << endl;
cout << "Modified Static Value: " << MyClass::staticValue << endl;
// 定义指向成员函数的指针
void (MyClass::*funcPtr)() = &MyClass::printValue;
// 定义指向静态成员函数的指针
void (*staticFuncPtr)() = &MyClass::staticFunction;
// 通过指针调用成员函数
(obj.*funcPtr)();
// 通过指针调用静态成员函数
(*staticFuncPtr)();
return 0;
}
11. this指针
在C++中,this指针是一个特殊的指针,它指向当前对象的地址。它是作为类的非静态成员函数的隐含参数存在的,允许在类的成员函数中访问当前对象的成员。可以选择省略this->操作符,直接使用成员变量或调用成员函数的名称,编译器会自动将其解析为当前对象的成员。然而,显式地使用this指针可以增强代码的可读性,并且在某些情况下可能是必需的,例如当成员变量与参数名称冲突时。
12. 常成员方法
在C++中,常成员方法是指在类中声明为const的成员方法。常成员方法承诺不会修改类的成员变量。通过将成员方法声明为常量,你可以确保在对象被视为常量时仍然可以调用该方法。在常成员方法内部,你不能修改类的成员变量,除非它们被声明为mutable。
常成员方法具有以下特点:
- 可以被常量对象调用:常量对象是指被声明为const的对象。常量对象只能调用常成员方法,因为常成员方法不会修改对象的状态。
- 不能修改成员变量:在常成员方法内部,你不能直接修改类的非静态成员变量,除非它们被声明为mutable。
- 不能调用非常量成员方法:常成员方法只能调用类中被声明为常量的成员方法。这是因为常量对象不允许对其状态进行修改。
class MyClass {
private:
int x;
public:
void setX(int value) {
this->x = value;
}
int getX() const {
return this->x;
}
};
int main() {
const MyClass obj; // 声明一个常量对象
int value = obj.getX(); // 可以调用常成员方法
// obj.setX(42); // 错误!常量对象不能调用非常量方法
return 0;
}
getX()方法被声明为常量方法,因此可以被常量对象obj调用。然而,setX()方法没有被声明为常量方法,所以常量对象不能调用它。
Note: 可以结合
this指针记忆,每个非静态成员函数,都是需要对象去调用的,编译器会自动给非静态成员函数添加this指针,而常量对象的指针就是常指针,比如代码中obj的指针类型是const MyClass *,而MyClass::setX()中的隐式this参数的类型是MyClass *,所以,常量对象不能调用非常量方法。编程实践中,如果方法可以定义为常量方法,那么我们就尽可能添加const。
以下情况下,将成员方法定义为常量可能是不合适的:
- 当方法需要修改对象的状态时,例如修改成员变量的值。
- 当方法需要调用其他非常量成员方法时,例如在常量方法内部需要调用一个修改对象状态的方法。
13. 函数模板与类模板
函数模板
模板的意义:对类型进行参数化
以下是一个简单的函数模板
template <typename T> // 模板参数列表,可以是类型参数(使用typename/class定义),也可以是非类型参数
bool compare(T a, T b) { // compare是一个函数模板,通过这个模板可以创建具体的函数
return a > b;
}
// 编译器在函数调用点,根据用户指定的参数类型,由原模板实例化一份函数代码出来,得到模板函数
// 可以根据用户传入的实参的具体类型,推导出模板类型参数的具体类型
int main() {
// compare<int> 模板名 + 参数列表 才是函数名
compare<int>(10, 20); // 函数调用点
compare<double>(1.2, 2.1);
}
一些重要的概念:
- 函数模板 用于创建函数的模板,不进行编译,因为参数类型还不知道
- 模板的实例化 在函数调用点进行实例化
- 模板函数 对函数模板进行实例化得到的函数
- 模板类型参数 使用typename/class定义一个类型参数
- 模板非类型参数 不是一个类型,而是一个具体的值。这意味着非类型参数可以是整数、枚举、指针或引用等。
- 模板的实参推演 根据用户传入的实参类型,推导出模板的参数类型
- 模板的特例化 模板函数不是由编译器提供,而是用户提供的实例化版本
- 模板函数、模板的特例化、非模板函数的重载关系 优先级为 普通非模板函数 > 特例化 > 函数模板
模板可以有非类型参数
以下是一段使用模板非类型参数的示例代码,使用冒泡排序实现数组的排序
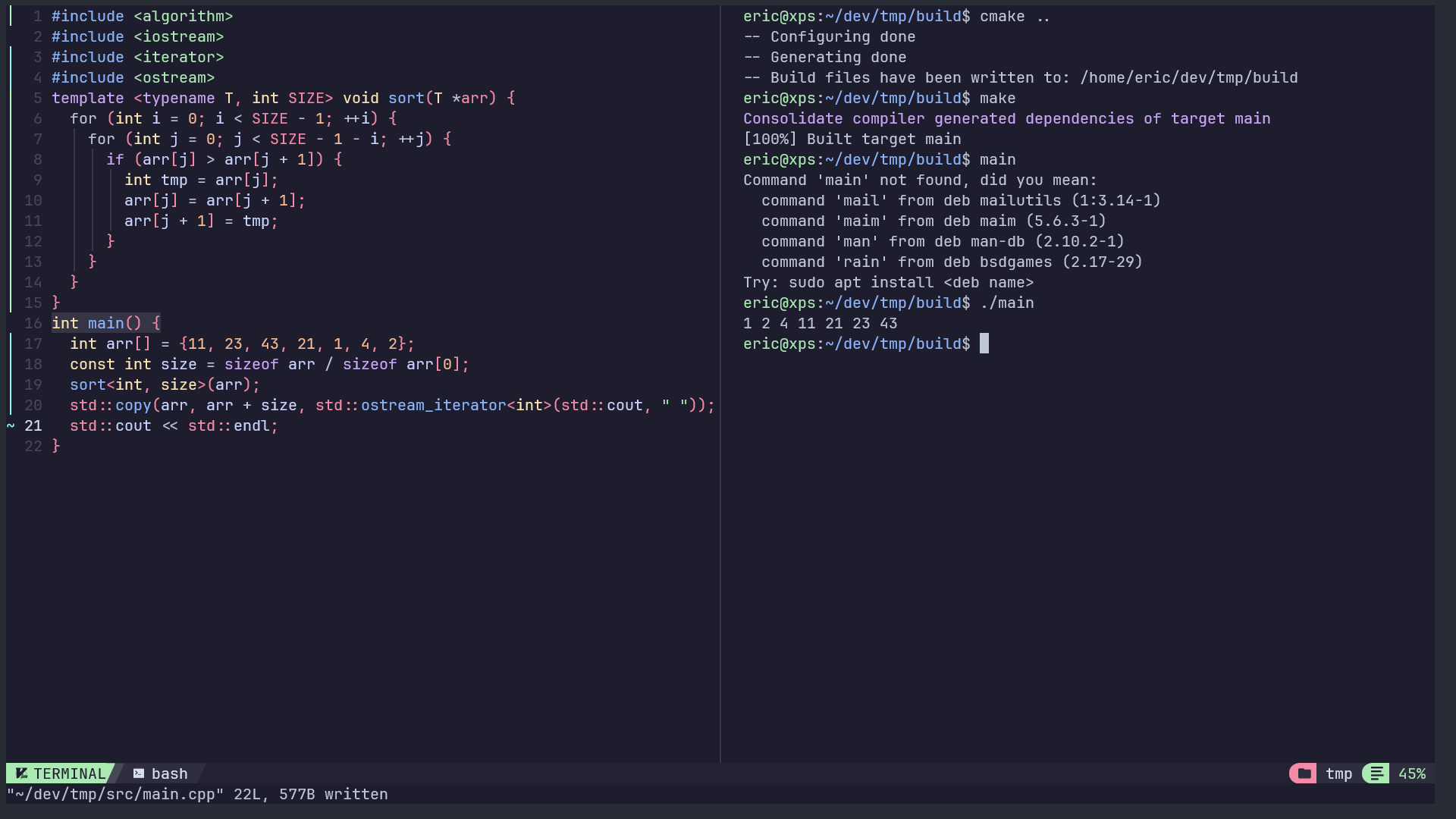
Note: 非类型参数必须在编译时确定其值,因此它们通常需要是常数表达式。
模板实参推演
函数模板特例化
// 这是一个函数模板的特例化示例, 提供了const char*类型的特例化版本
template <>
bool compare(const char *a, const char *b) {
return strcmp(a, b) > 0;
}
类模板
用类模板实现一个顺序栈
#include <iostream>
template <typename T> class SeqStack {
public:
SeqStack(int capacity = 10)
: _data(new T[capacity]), _top(0), _capacity(capacity) {}
~SeqStack() {
delete[] _data;
_data = nullptr;
}
SeqStack(const SeqStack<T> &val) : _top(val._top), _capacity(val._capacity) {
_data = new T[_capacity];
for (int i = 0; i < _top; ++i) {
_data[i] = val._data[i];
}
}
SeqStack<T> &operator=(const SeqStack<T> &val) {
if (this == &val) {
// 自赋值
return *this;
}
delete[] _data;
_top = val._top;
_capacity = val._capacity;
_data = new T[_capacity];
for (int i = 0; i < _top; ++i) {
_data[i] = val._data[i];
}
return *this;
}
void push(const T &val) {
if (full())
expand();
_data[_top++] = val;
}
void pop() {
if (empty())
return;
--_top;
}
T top() const { return _data[_top - 1]; }
bool full() const { return _top == _capacity; }
bool empty() const { return _top == 0; }
private:
// 顺序栈底层数组2倍扩容
void expand() {
T *ptmp = new T[_capacity * 2];
for (int i = 0; i < _top; ++i) {
ptmp[i] = _data[i];
}
delete[] _data;
_data = ptmp;
_capacity *= 2;
}
private:
T *_data;
int _top;
int _capacity;
};
int main() {
// 类模板中调用了的方法才会实例化
SeqStack<int> s;
s.push(1);
s.push(2);
s.push(3);
s.pop();
std::cout << s.top() << std::endl;
}
用类模板实现vector
#include <iostream>
template <typename T> class vector {
public:
vector(int capacity = 10) {
_first = new T[capacity];
_last = _first;
_end = _first + capacity;
}
~vector() {
delete[] _first;
_first = _last = _end = nullptr;
}
vector(const vector<T> &val) {
auto capacity = val._end - val._first;
auto size = val._last - val._first;
_first = new T[capacity];
for (int i = 0; i < size; ++i) {
_first[i] = val._first[i];
}
_last = _first + size;
_end = _first + capacity;
}
vector<T> &operator=(const vector<T> &val) {
if (this == &val) {
return *this;
}
delete[] _first;
auto capacity = val._end - val._first;
auto size = val._last - val._first;
_first = new T[capacity];
for (int i = 0; i < size; ++i) {
_first[i] = val._first[i];
}
_last = _first + size;
_end = _first + capacity;
return *this;
}
void push_back(const T &val) {
if (full())
expand();
*_last++ = val;
}
void pop_back() {
if (empty())
return;
--_last;
}
T back() const { return *(_last - 1); }
bool full() const { return _last == _end; }
bool empty() const { return _first == _last; }
int size() const { return _last - _first; }
private:
void expand() {
int capacity = _end - _first;
int size = _last - _first;
T *ptmp = new T[capacity * 2];
for (int i = 0; i < size; ++i) {
ptmp[i] = _first[i];
}
delete[] _first;
_first = ptmp;
_last = _first + size;
_end = _first + capacity * 2;
}
private:
T *_first;
T *_last;
T *_end;
};
int main() {
vector<int> vec;
for (size_t i = 0; i < 10; i++) {
vec.push_back(i);
}
while (!vec.empty()) {
std::cout << vec.back() << std::endl;
vec.pop_back();
}
}
14. 容器空间配置器
在学习容器空间配置器之前,先了解其存在的必要性。继续看上面用类模板实现的vector容器类,它存在以下几个问题:
内存开辟与对象创建没有分开
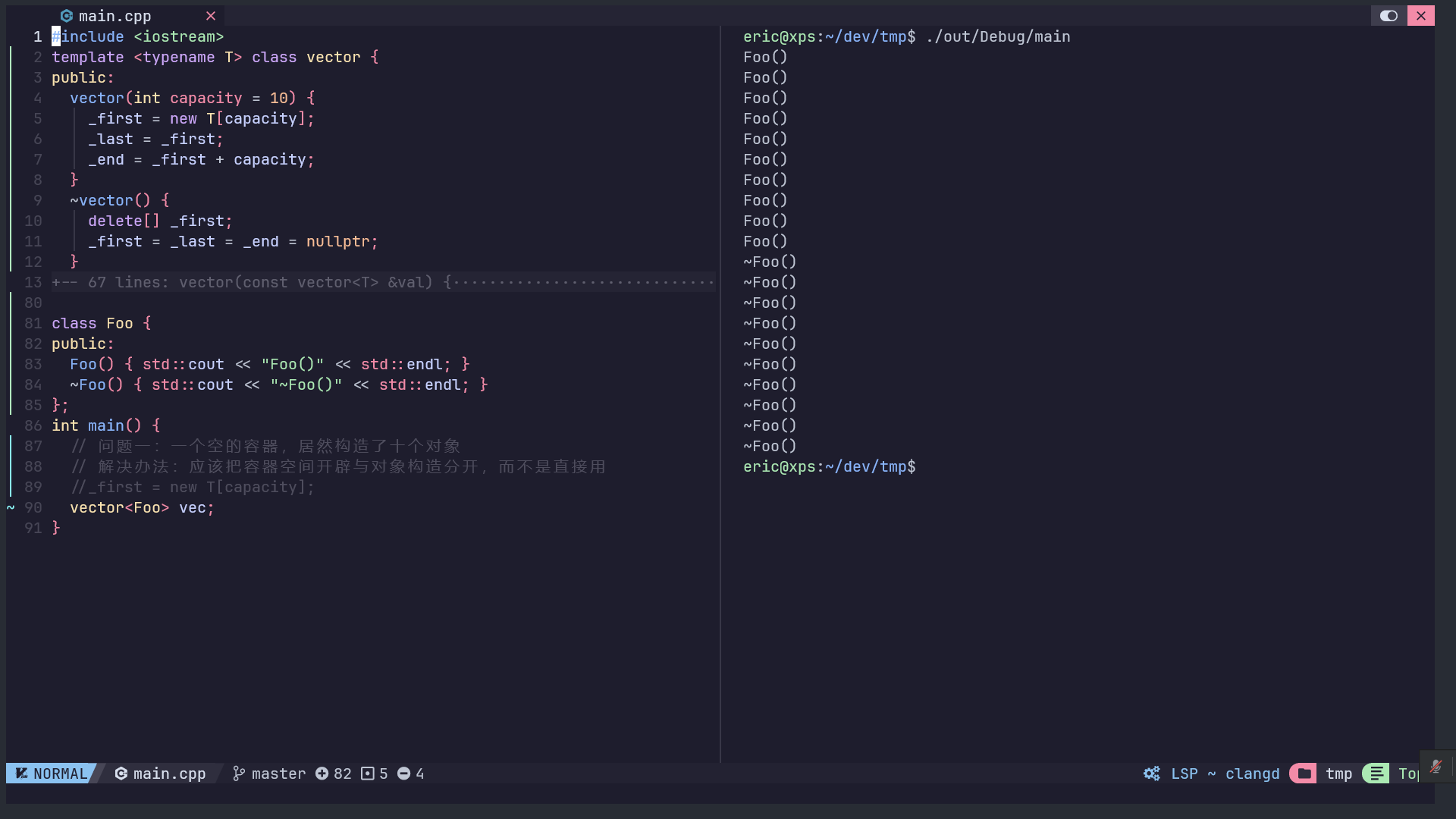
创建一个类,在构造和析构函数中分别打印一些东西,然后创建这个对象的vector容器,这是容器类的构造方法中,就会通过new运算符开辟空间,同时调用对象的构造方法,但其实这只是一个空容器,对象构造既无必要结果也不对内存释放与对象析构没有分开

添加元素时应该是拷贝构造而非拷贝赋值
这个很显然,往容器中添加元素时,正确的步骤就应该是在对应内存位置发生拷贝构造,而不是拷贝赋值。发生拷贝赋值还是因为容器的构造方法中,把内存开辟和对象构造都执行了,所以一个空容器里面也装满了对象(通过对象的默认构造方法,这在对象没有无参默认构造时又是另一个潜在的问题)。所以这个问题的解决办法,也是需要把容器的内存开辟和对象构造分开。删除元素时仅移动top指针而没有析构对象
删除元素没有用delete是因为会把内存释放掉,而我们不想释放内存,只是想把对象析构而已。移动top指针可以把这个对象从容器中删除,使这个对象不再可用,但却没有真正释放这个对象,如果这个对象占用了外部资源的话,这就会导致资源泄露了。
解决办法也很明显,做到能够析构对象的同时,又不释放相应的内存空间,用delete运算符肯定是做不到的,这时析构函数就可以派上用场了,这是少数的需要人为调用析构函数的场景。
Note: 在使用了placement new时,大多都需要用到直接调用析构函数
以下是通过容器空间配置器实现的vector容器,它完美的解决了这四个问题
#include <iostream>
// 容器空间配置器
template <typename T> class Allocator {
public:
T *allocate(size_t size) { return (T *)malloc(sizeof(T) * size); }
void deallocate(void *p) { free(p); }
void construct(T *p, const T &val) { new (p) T(val); } // placement new,也叫定位new
void destry(T *p) { p->~T(); }
};
template <typename T, typename Alloc = Allocator<T>> class vector {
public:
vector(int capacity = 10) {
// _first = new T[capacity];
_first = _alloc.allocate(capacity);
_last = _first;
_end = _first + capacity;
}
~vector() {
// delete[] _first;
for (T *p = _first; p != _last; ++p) {
_alloc.destry(p);
}
_alloc.deallocate(_first);
_first = _last = _end = nullptr;
}
vector(const vector<T> &val) {
auto capacity = val._end - val._first;
auto size = val._last - val._first;
// _first = new T[capacity];
_first = _alloc.allocate(capacity);
for (int i = 0; i < size; ++i) {
// _first[i] = val._first[i];
_alloc.construct(_first + i, val._first[i]);
}
_last = _first + size;
_end = _first + capacity;
}
vector<T> &operator=(const vector<T> &val) {
if (this == &val) {
return *this;
}
// delete[] _first;
for (T *p = _first; p != _last; ++p) {
_alloc.destry(p);
}
_alloc.deallocate(_first);
auto capacity = val._end - val._first;
auto size = val._last - val._first;
// _first = new T[capacity];
_first = _alloc.allocate(capacity);
for (int i = 0; i < size; ++i) {
// _first[i] = val._first[i];
_alloc.construct(_first + i, val._first[i]);
}
_last = _first + size;
_end = _first + capacity;
return *this;
}
void push_back(const T &val) {
if (full())
expand();
// *_last++ = val;
_alloc.construct(_last, val);
++_last;
}
void pop_back() {
if (empty())
return;
// --_last;
--_last;
_alloc.destry(_last);
}
T back() const { return *(_last - 1); }
bool full() const { return _last == _end; }
bool empty() const { return _first == _last; }
int size() const { return _last - _first; }
private:
void expand() {
int capacity = _end - _first;
int size = _last - _first;
// T *ptmp = new T[capacity * 2];
T *ptmp = _alloc.allocate(2 * capacity);
for (int i = 0; i < size; ++i) {
// ptmp[i] = _first[i];
_alloc.construct(ptmp + i, _first[i]);
}
// delete[] _first;
for (T *p = _first; p != _last; ++p) {
_alloc.destry(p);
}
_alloc.deallocate(_first);
_first = ptmp;
_last = _first + size;
_end = _first + capacity * 2;
}
private:
T *_first;
T *_last;
T *_end;
Alloc _alloc;
};
class Foo {
public:
Foo() { std::cout << "Foo()" << std::endl; }
~Foo() { std::cout << "~Foo()" << std::endl; }
};
int main() { vector<Foo> vec; }
15. 运算符重载
运算符重载的作用:使对象的运算表现得和编译器内置类型一样
以下示例代码演示了如何进行运算符的重载,实现一个Complex类
#include <iostream>
class Complex {
public:
friend std::ostream &operator<<(std::ostream &cout, const Complex &val);
friend Complex operator+(const Complex &l, const Complex &r);
Complex(int real = 0, int image = 0) : _real(real), _image(image) {}
Complex operator+(const Complex &val) {
return {_real + val._real, _image + val._image};
}
// 前置加
Complex &operator++() {
_real += 1;
_image += 1;
return *this; // 在返回*this的函数里,我们都可以考虑返回值添加引用
}
// 后置加
Complex operator++(int) {
// 一种写法
// Complex tmp = *this;
// _real += 1;
// _image += 1;
// return tmp;
// 优化后的另一种写法
return {_real++, _image++};
}
void operator+=(const Complex &val) {
_real += val._real;
_image += val._image;
}
private:
int _real;
int _image;
};
std::ostream &operator<<(std::ostream &cout, const Complex &val) {
cout << val._real << "," << val._image;
return cout;
}
Complex operator+(const Complex &l, const Complex &r) {
return {l._real + r._real, l._image + r._image};
}
int main() {
Complex c1{1, 2}, c2{3, 4};
Complex c3 = c1 + c2;
std::cout << c3 << std::endl;
Complex c4 = c1 + 10; // int -> Complex
std::cout << c4 << std::endl;
// 上面能够成功执行是因为 c1.operator+(10),
// 10会自动进行隐式类型转换,变为Complex
// 当然,这个隐式类型转换要求Complex有相应的构造方法,即由一个int构造Complex的方法(这种写法并不推荐)
// 下面不可行,则是因为左操作数是一个int,而int没有相应的operator+(Complex)方法
// 如果要让下面的代码可行,我们需要定义一个全局的operator+(const Complex& l,
// const Complex& r);
//
// Complex c5 = 10 + c1; // Invalid operands to binary
// expression ('int' and 'Complex')
std::cout << ++c4 << std::endl;
std::cout << c4++ << std::endl;
c4 += c1;
std::cout << c4 << std::endl;
}
上述代码中需要注意以下要点:
0. 前置加和后置加的函数名相同,但是后置加有一个int参数
- 在返回对象时,尽量考虑代码优化,不构造临时对象,这有助于编译器对代码进行优化,方便直接在调用处构造对象。比如在前置加时,既然要返回的对象就是修改后的,我们可以返回*this即当前对象,那么就可以让返回值类型添加&,以减少不必要的拷贝,而后置加,则可以直接{member1++,member2++,...},这样既把当前状态返回了,又在返回之后将当前状态修改了,编译器会优化为直接在调用处构造新对象,而不必发生局部对象的创建和拷贝构造。 todo: add one more section to specify this problem
- 运算符重载有全局和成员之分,全局的运算符重载函数将不限制必须使用类的对象进行调用,任何可以构造为或者隐式转换为第一个形参类型的都能调用该全局运算符重载函数
16. 实现一个string类
以下是一个实现了包括普通构造,析构,拷贝构造,拷贝赋值,移动构造,移动赋值和运算符重载的string类
#include <cstring>
#include <iostream>
class string {
public:
friend string operator+(const string &l, const string &r);
string(const char *p = nullptr) {
std::cout << "default ctor" << std::endl;
if (p != nullptr) {
_data = new char[strlen(p) + 1];
strcpy(_data, p);
} else {
_data = new char[1];
*_data = '\0';
}
}
~string() {
delete[] _data;
_data = nullptr;
}
string(const string &str) {
std::cout << "copy ctor" << std::endl;
_data = new char[strlen(str._data) + 1];
strcpy(_data, str._data);
}
string &operator=(const string &str) {
if (this == &str) {
return *this;
}
delete[] _data;
_data = new char[strlen(str._data) + 1];
strcpy(_data, str._data);
return *this;
}
string(string &&str) {
std::cout << "move ctor" << std::endl;
_data = str._data;
str._data = nullptr;
}
string &operator=(string &&str) {
if (this == &str)
return *this;
delete[] _data;
_data = str._data;
str._data = new char[1];
str._data[0] = '\0';
return *this;
}
bool operator>(const string &val) const {
return strcmp(_data, val._data) > 0;
}
bool operator<(const string &val) const {
return strcmp(_data, val._data) < 0;
}
bool operator==(const string &val) const {
return strcmp(_data, val._data) == 0;
}
// 仅普通对象能调用,可以读,也可以写
// 读 char ch = str[1];
// 写 str[1] = 'c';
char &operator[](int idx) { return _data[idx]; }
// 普通对象和常对象都能调用,只可以读
// 读 char ch = str[1];
const char &operator[](int idx) const { return _data[idx]; }
//
const char *c_str() const { return _data; }
int length() const { return strlen(_data); }
private:
char *_data;
};
std::ostream &operator<<(std::ostream &out, const string &val) {
out << val.c_str();
return out;
}
string operator+(const string &l, const string &r) {
string tmp; // default
delete[] tmp._data;
tmp._data = new char[strlen(l._data) + strlen(r._data) + 1];
strcpy(tmp._data, l._data);
strcpy(tmp._data + strlen(l._data), r._data);
// 默认情况下,编译器会把这种局部对象的拷贝构造或者拷贝赋值优化掉,减少一次拷贝
// 使用move进行强制移动构造或移动赋值反而会画蛇添足
return std::move(tmp);
}
int main() {
string s1 = "hello"; // default
string s2 = "world"; // default
string s3 = s1 + s2; // move
std::cout << s3 << std::endl;
}
这些函数中,我们重点关注一下函数string operator+(const string &l, const string &r)
版本一
首先,我们还可以对该方法进行以下实现:
string operator+(const string& l,const string& r){
char * tmp = new char[strlen(l._data) + strlen(r._data) + 1];
strcpy(tmp, l._data);
strcat(tmp, r._data);
string s{tmp};
delete[] tmp;
return tmp;
}
注意到这个版本中,会进行三次new,其中第一次new是为了构造tmp指针,第二次new是为了构造临时对象s(在s的构造函数中,发生了new和内存拷贝),第三次则是为了构造或者赋值到接收对象。这个版本可谓是效率低下。
版本二
string operator+(const string &l, const string &r) {
string tmp; // default
delete[] tmp._data;
tmp._data = new char[strlen(l._data) + strlen(r._data) + 1];
strcpy(tmp._data, l._data);
strcpy(tmp._data + strlen(l._data), r._data);
return tmp;
}
这个版本中,通过直接构造string对象,然后通过友元直接修改成员属性,这减少了不必要的内存开辟和拷贝操作,同时编译器会自动优化,去掉了返回到接收对象的拷贝操作。
版本三
string operator+(const string &l, const string &r) {
string tmp; // default
delete[] tmp._data;
tmp._data = new char[strlen(l._data) + strlen(r._data) + 1];
strcpy(tmp._data, l._data);
strcpy(tmp._data + strlen(l._data), r._data);
return std::move(tmp);
}
这个版本有点弄巧成拙了,虽然在返回时,想要通过移动构造或者移动赋值减少对象构造,但其实也让编译器优化失去了效果,所以很多时候,不用太关注这种细节,让编译器优化就能有很好的性能。
17. 容器迭代器实现原理
迭代器可以用于透明地访问容器中的元素。
给自定义string类添加迭代器
在上面的自定义string类的基础上,实现string容器内部的迭代器类型。
#include <cstring>
#include <iostream>
class string {
public:
friend string operator+(const string &l, const string &r);
string(const char *p = nullptr) {
std::cout << "default ctor" << std::endl;
if (p != nullptr) {
_data = new char[strlen(p) + 1];
strcpy(_data, p);
} else {
_data = new char[1];
*_data = '\0';
}
}
~string() {
delete[] _data;
_data = nullptr;
}
string(const string &str) {
std::cout << "copy ctor" << std::endl;
_data = new char[strlen(str._data) + 1];
strcpy(_data, str._data);
}
string &operator=(const string &str) {
if (this == &str) {
return *this;
}
delete[] _data;
_data = new char[strlen(str._data) + 1];
strcpy(_data, str._data);
return *this;
}
string(string &&str) {
std::cout << "move ctor" << std::endl;
_data = str._data;
str._data = nullptr;
}
string &operator=(string &&str) {
if (this == &str)
return *this;
delete[] _data;
_data = str._data;
str._data = new char[1];
str._data[0] = '\0';
return *this;
}
bool operator>(const string &val) const {
return strcmp(_data, val._data) > 0;
}
bool operator<(const string &val) const {
return strcmp(_data, val._data) < 0;
}
bool operator==(const string &val) const {
return strcmp(_data, val._data) == 0;
}
// 仅普通对象能调用,可以读,也可以写
// 读 char ch = str[1];
// 写 str[1] = 'c';
char &operator[](int idx) { return _data[idx]; }
// 普通对象和常对象都能调用,只可以读
// 读 char ch = str[1];
const char &operator[](int idx) const { return _data[idx]; }
//
const char *c_str() const { return _data; }
int length() const { return strlen(_data); }
// 迭代器可以透明地访问容器内部的元素
class iterator {
public:
iterator(char *p = nullptr) : _p(p) {}
bool operator!=(const iterator &it) { return _p != it._p; }
void operator++() { ++_p; }
char &operator*() { return *_p; }
private:
char *_p;
};
iterator begin() { return {_data}; }
iterator end() { return {_data + length()}; }
private:
char *_data;
};
std::ostream &operator<<(std::ostream &out, const string &val) {
out << val.c_str();
return out;
}
string operator+(const string &l, const string &r) {
string tmp; // default
delete[] tmp._data;
tmp._data = new char[strlen(l._data) + strlen(r._data) + 1];
strcpy(tmp._data, l._data);
strcpy(tmp._data + strlen(l._data), r._data);
// 默认情况下,编译器会把这种局部对象到接收对象的拷贝构造或者拷贝赋值优化掉,减少一次拷贝
// 使用move进行强制移动构造或移动赋值反而会画蛇添足
return std::move(tmp);
}
int main() {
string s1 = "hello"; // default
string s2 = "world"; // default
string s3 = s1 + s2; // move
std::cout << s3 << std::endl;
std::cout << "================" << std::endl;
for (auto it = s3.begin(); it != s3.end(); ++it) {
std::cout << *it;
}
std::cout << std::endl;
std::cout << "================" << std::endl;
// 增强for依赖容器的begin和end方法
for (char c : s3) {
std::cout << c;
}
std::cout << std::endl;
}
给自定义vector类添加迭代器
#include <algorithm>
#include <iostream>
#include <iterator>
// 容器空间配置器
template <typename T> class Allocator {
public:
T *allocate(size_t size) { return (T *)malloc(sizeof(T) * size); }
void deallocate(void *p) { free(p); }
void construct(T *p, const T &val) {
new (p) T(val);
} // placement new,也叫定位new
void destry(T *p) { p->~T(); }
};
template <typename T, typename Alloc = Allocator<T>> class vector {
public:
vector(int capacity = 10) {
// _first = new T[capacity];
_first = _alloc.allocate(capacity);
_last = _first;
_end = _first + capacity;
}
~vector() {
// delete[] _first;
for (T *p = _first; p != _last; ++p) {
_alloc.destry(p);
}
_alloc.deallocate(_first);
_first = _last = _end = nullptr;
}
vector(const vector<T> &val) {
auto capacity = val._end - val._first;
auto size = val._last - val._first;
// _first = new T[capacity];
_first = _alloc.allocate(capacity);
for (int i = 0; i < size; ++i) {
// _first[i] = val._first[i];
_alloc.construct(_first + i, val._first[i]);
}
_last = _first + size;
_end = _first + capacity;
}
vector<T> &operator=(const vector<T> &val) {
if (this == &val) {
return *this;
}
// delete[] _first;
for (T *p = _first; p != _last; ++p) {
_alloc.destry(p);
}
_alloc.deallocate(_first);
auto capacity = val._end - val._first;
auto size = val._last - val._first;
// _first = new T[capacity];
_first = _alloc.allocate(capacity);
for (int i = 0; i < size; ++i) {
// _first[i] = val._first[i];
_alloc.construct(_first + i, val._first[i]);
}
_last = _first + size;
_end = _first + capacity;
return *this;
}
void push_back(const T &val) {
if (full())
expand();
// *_last++ = val;
_alloc.construct(_last, val);
++_last;
}
void pop_back() {
if (empty())
return;
// --_last;
--_last;
_alloc.destry(_last);
}
T back() const { return *(_last - 1); }
bool full() const { return _last == _end; }
bool empty() const { return _first == _last; }
int size() const { return _last - _first; }
T &operator[](int index) { return _first[index]; }
class iterator {
public:
iterator(T *ptr = nullptr) : _p(ptr) {}
bool operator!=(const iterator &val) const { return _p != val._p; }
void operator++() { ++_p; }
T &operator*() { return *_p; }
private:
T *_p;
};
iterator begin() { return {_first}; }
iterator end() { return {_last}; }
private:
void expand() {
int capacity = _end - _first;
int size = _last - _first;
// T *ptmp = new T[capacity * 2];
T *ptmp = _alloc.allocate(2 * capacity);
for (int i = 0; i < size; ++i) {
// ptmp[i] = _first[i];
_alloc.construct(ptmp + i, _first[i]);
}
// delete[] _first;
for (T *p = _first; p != _last; ++p) {
_alloc.destry(p);
}
_alloc.deallocate(_first);
_first = ptmp;
_last = _first + size;
_end = _first + capacity * 2;
}
private:
T *_first;
T *_last;
T *_end;
Alloc _alloc;
};
int main() {
vector<int> v;
for (int i = 0; i < 10; ++i) {
v.push_back(i);
}
for (auto i : v) {
std::cout << i << " ";
}
std::cout << std::endl;
for (auto it = v.begin(); it != v.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
}
18. 迭代器失效问题
首先考虑删除元素导致的迭代器失效问题
std::vector<int> v = {84, 87, 78, 16, 94, 36, 87, 93, 50, 22};
std::copy(v.begin(), v.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
for (auto it = v.begin(); it != v.end(); ++it) {
if (*it % 2 == 0) {
v.erase(it); // 第一次调用erase方法后,迭代器就失效了
}
}
std::copy(v.begin(), v.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
在第一次调用erase方法后,vector内部删除一个元素,会将后续元素向前移动一个位置,这就导致后续的所有迭代器均失效。
上述代码执行的过程中,vector中的元素变化过程为:
84, 87, 78, 16, 94, 36, 87, 93, 50, 22
87, 78, 16, 94, 36, 87, 93, 50, 22
87, 16, 94, 36, 87, 93, 50, 22
87, 16, 36, 87, 93, 50, 22
87, 16, 36, 87, 93, 22
在判断84为偶数时,删除84,后续元素向前移动,然后it加一指向了78(因为87移动到了84元素所在位置)
之后删除元素均是如此,每次删除元素之后执行++it,相当于指针向后移动了两个单位(删除元素会导致后续元素移动一个单位,之后执行++it也是移动一个单位)
正确的删除操作如下:
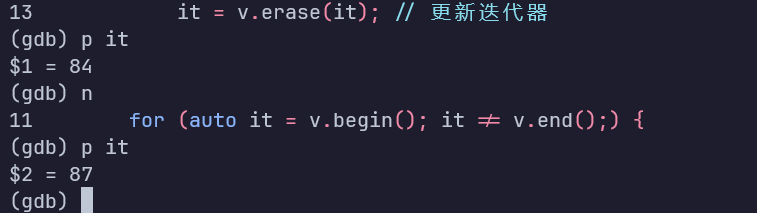
for (auto it = v.begin(); it != v.end();) {
if (*it % 2 == 0) {
v.erase(it); // 不更新迭代器
} else {
++it; // 如果没有删除,则迭代器自增
}
}
上述代码在执行删除操作之后,删除位置之后的元素往前移一个,同时it不更新
// 连续插入元素,迭代器失效
for (auto it = v2.begin(); it != v2.end(); ++it) {
if (*it % 2 == 0) {
// free(): invalid pointer
v2.insert(it, *it - 1); // 第一次调用insert方法后,迭代器就失效了
}
}
再考虑插入元素的情况,这种情况比较复杂,因为容器在插入元素时有可能发生扩容操作,也可能底层空间足够,不需要扩容。不管是哪一种情况,都会导致插入位置之后的元素向后移动,之后的迭代器均失效。
参考上面的解决方案,很容易想到,再插入成功时,更新it,使其能够顺利指向下一个元素。
for (auto it = v.begin(); it != v.end(); ++it) {
if (*it % 2 == 0) {
it = v.insert(it, *it - 1);
++it; // 新元素插入后,更新迭代器
}
}
updating....
C++常见面试题整理的更多相关文章
- HashMap常见面试题整理
花了三天时间来仔细阅读hashMap的源码,期间补了下不少数据结构的知识,刷了不少相关的面试题并进行了整理 1.谈一下HashMap的特性? 1.HashMap存储键值对实现快速存取,允许为null. ...
- 【持续更新】JavaScript常见面试题整理
[重点提前说]这篇博客里的问题涉及到了了JS中常见的的基础知识点,也是面试中常见的一些问题,建议初入职场的园友Mark收藏,本文会持续更新~ 1. 引入JS的三种方式 1.在HTML标签中直接使用,直 ...
- 常见面试题整理--Python概念篇
希望此文可以长期更新并作为一篇Python的面试宝典.每一道题目都附有详细解答,以及更加详细的回答链接.此篇是概念篇,下一篇会更新面试题代码篇. (一).这两个参数是什么意思:*args,**kwar ...
- Java 常见面试题整理
操作系统 说一下线程和进程,它们的区别 同步和异步的区别 阻塞和非阻塞的区别 操作系统中死锁的四个必要条件 mmap和普通文件读写的区别,mmap的注意点 CPU密集型和IO密集型的区别 Linux ...
- 整理的最全 python常见面试题(基本必考)
整理的最全 python常见面试题(基本必考) python 2018-05-17 作者 大蛇王 1.大数据的文件读取 ① 利用生成器generator ②迭代器进行迭代遍历:for line in ...
- 整理的最全 python常见面试题
整理的最全 python常见面试题(基本必考)① ②③④⑤⑥⑦⑧⑨⑩ 1.大数据的文件读取: ① 利用生成器generator: ②迭代器进行迭代遍历:for line in file; 2.迭代 ...
- java常见面试题及答案
java常见面试题及答案 来源 https://blog.csdn.net/hsk256/article/details/49052293 来源 https://blog.csdn.net/hsk25 ...
- Java 常见面试题(一)
1)什么是Java虚拟机?为什么Java被称作是“平台无关的编程语言”? Java虚拟机是一个可以执行Java字节码的虚拟机进程.Java源文件被编译成能被Java虚拟机执行的字节码文件.Java被设 ...
- python爬虫常见面试题(二)
前言 之所以在这里写下python爬虫常见面试题及解答,一是用作笔记,方便日后回忆:二是给自己一个和大家交流的机会,互相学习.进步,希望不正之处大家能给予指正:三是我也是互联网寒潮下岗的那批人之一,为 ...
- 【javascript常见面试题】常见前端面试题及答案
转自:http://www.cnblogs.com/syfwhu/p/4434132.html 前言 本文是在GitHub上看到一个大牛总结的前端常见面试题,很多问题问的都很好,很经典.很有代表性.上 ...
随机推荐
- Apache log4j2远程代码执行漏洞
漏洞描述 Apache Log4j2是一个基于Java的日志记录工具.该工具重写了Log4j框架,并且引入了大量丰富的特性.该日志框架被大量用于业务系统开发,用来记录日志信息.大多数情况下,开发者可能 ...
- RESTful架构与RPC架构
RESTful架构与RPC架构 在RESTful架构中,关注点在于资源,操作资源时使用标准方法检索并操作信息片段,在RPC架构中,关注点在于方法,调用方法时将像调用本地方法一样调用服务器的方法. RE ...
- docker 常用命令 快捷命令
一.查询节点 docker ps -a 二.docker重启停止 systemctl restart docker systemctl stop docker docker restart * 三.一 ...
- 【Android 逆向】【攻防世界】RememberOther
1. apk安装到手机,提示输入用户名注册码 2. jadx 打开apk public boolean checkSN(String userName, String sn) { try { if ( ...
- 本地启动RocketMQ未映射主机名产生的超时问题
问题描述 参考RocketMQ官方文档在本地启动一个验证环境的时候遇到超时报错问题. 本地环境OS:CentOS Linux release 8.5.2111 首先,进入到RocketMQ安装目录,如 ...
- django学习第十五天-modelform的补充
基于form组件和modelform组件改造图书管理系统 详情可以去图书管理系统分类中查看 基于form组件和modelform组件改造图书管理系统 modelform的补充 class BookMo ...
- python中partial用法
应用 典型的,函数在执行时,要带上所有必要的参数进行调用.然后,有时参数可以在函数被调用之前提前获知.这种情况下,一个函数有一个或多个参数预先就能用上,以便函数能用更少的参数进行调用. 示例pyqt5 ...
- vue运行时报错Error from chokidar
原文博客地址 Error from chokidar (/home/youyou/文档/vue/vuetask01/node_modules/lodash): Error: ENOSPC: Syste ...
- 【LeetCode回溯算法#02】组合总和III
组合总和III 力扣题目链接(opens new window) 找出所有相加之和为 n 的 k 个数的组合.组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字. 说明: 所有数字 ...
- 用Docker发布Study.BlazorOne.Blazor到公网测试服务器
# 1.准备公网上的测试数据库. 之前我们在Visual Studio里面调试的时候,使用的都是localhost的数据库.现在需要在公网上准备一个SQL Server.然后执行下面的步骤 1)把St ...