PyTorch程序练习(一):PyTorch实现CIFAR-10多分类
一、准备数据
代码
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# ========================================准备数据========================================
# 定义预处理函数
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
"""
①transfom.Compose可以把一些转换函数组合在一起。
②transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))对张量进行归一化:图像有三个通道,每个通道均值0.5,方差0.5。)
"""
# 下载CIFAR10数据,并对数据进行预处理
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=False, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform)
# 得到一个生成器
trainloader = DataLoader(trainset, batch_size=4, shuffle=True)
testloader = DataLoader(testset, batch_size=4, shuffle=False) # 数据分批
"""
①dataloader是一个可迭代对象,可以使用迭代器一样使用。
②用DataLoader得到生成器,这可节省内存。
"""
# 分类类别
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# ========================================可视化源数据========================================
import matplotlib.pyplot as plt
import numpy as np
# 显示图像
def imshow(img):
img = img / 2 + 0.5 # unnormalize反归一化:img = img * std + mu
npimg = img.numpy() # 将图片转换为数组
plt.imshow(np.transpose(npimg, (1, 2, 0))) # transpose对高维矩阵进行轴对换:把图片中表示颜色顺序的RGB改为GBR
# 显示图像
plt.xticks([])
plt.yticks([])
plt.show()
# 随机获取部分训练数据
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 打印标签
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
# 显示图像
imshow(torchvision.utils.make_grid(images))运行结果
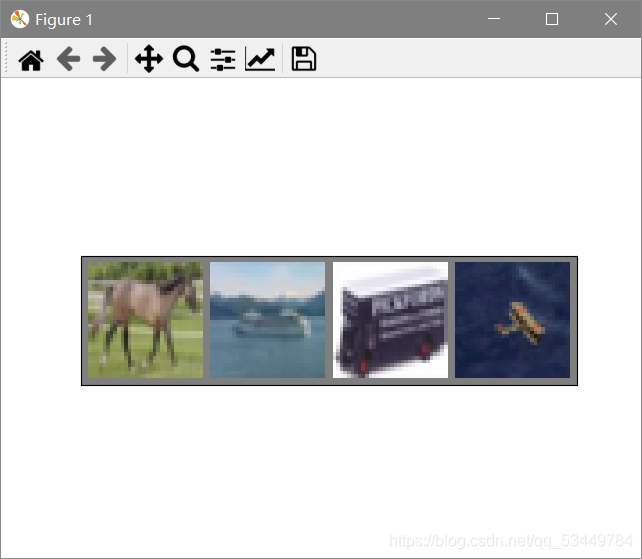
horse ship truck plane二、全连接层FC
代码
from 准备数据 import trainloader,images,classes,testloader
# ========================================构建网络========================================
import torch
import torch.nn as nn
import torch.nn.functional as F
# 检测是否有GPU,有则使用,否则使用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda:0表示使用第一块GPU;若有显卡torch.cuda.is_available()返回True
"""
#若有多块显卡可并行化训练:
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs")
dim = 0 [20, xxx] -> [10, ...], [10, ...] on 2GPUs
model = nn.DataParallel(model)
"""
# --------------------构建卷积网络--------------------
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=(5,5), stride=(1,1)) #卷积层1
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) #池化层1
self.conv2 = nn.Conv2d(in_channels=16, out_channels=36, kernel_size=(3,3), stride=(1,1)) #卷积层2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) #池化层2
self.fc1 = nn.Linear(1296, 128) #全连接层1
self.fc2 = nn.Linear(128, 10) #全连接层2
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1, 36 * 6 * 6)
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return x
# --------------------实例化网络--------------------
net = CNNNet() #实例化网络
net = net.to(device) #使用GPU训练
# 定义损失函数和优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
#optimizer = optim.Adam(net.parameters(), lr=0.001)
"""
model.parameters():传入模型参数;
lr:学习率;
momentum:动量,更新缩减和平移参数的频率和幅度,结合当前梯度与上一次更新信息用于当前更新
"""
# ========================================训练模型========================================
import time
for epoch in range(10):
start = time.time()
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取训练数据
inputs, labels = data #解包元组
inputs, labels = inputs.to(device), labels.to(device) #将数据放在GPU上
# 前向传播
outputs = net(inputs)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad() #清空上一步的残余更新参数值,将神经网络参数梯度降为0
loss.backward() #误差反向传递,计算参数更新值
optimizer.step() #优化梯度,将参数更新值施加到net的parameters上
# 记录误差
running_loss += loss.item()
# 每2000步打印损失
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f, time:%.2f' % (epoch + 1, i + 1, running_loss / 2000, time.time()-start))
running_loss = 0.0
print('训练完成')
# 预测结果
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1) #输出值的最大值作为预测值
print('预测结果: ', ' '.join('%5s' % classes[predicted[j]]for j in range(4)))
# ========================================测试模型========================================
# --------------------整体预测准确率--------------------
correct = 0
total = 0
with torch.no_grad():
# 从测试数据中取出数据
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) #模型预测的最大值作为预测值
total += labels.size(0) #统计测试图片个数
correct += (predicted == labels).sum().item() #统计正确预测的图片数
print('10000张测试图片的准确率:%d%%' % (100 * correct / total))
# --------------------每个类别预测准确率--------------------
class_correct = list(0. for i in range(10)) #正确的类别个数
class_total = list(0. for i in range(10)) #一共10个类别
with torch.no_grad():
# 从测试数据中取出数据
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze() #预测正确的返回True,预测错误的返回False;squeeze将数据转换为一维数据
for i in range(4):
label = labels[i] #提取标签
class_correct[label] += c[i].item() #预测正确个数
class_total[label] += 1 #总数
for i in range(10):
print('%5s的准确率:%2d%%' % (classes[i], 100 * class_correct[i] / class_total[i]))运行结果
plane car deer horse[1, 2000] loss: 2.167, time:5.35
[1, 4000] loss: 1.979, time:9.37
[1, 6000] loss: 1.842, time:13.38
[1, 8000] loss: 1.732, time:17.44
[1, 10000] loss: 1.474, time:21.50
[1, 12000] loss: 1.380, time:25.49
[2, 2000] loss: 1.246, time:4.10
[2, 4000] loss: 1.210, time:8.21
[2, 6000] loss: 1.180, time:12.33
[2, 8000] loss: 1.156, time:16.47
[2, 10000] loss: 1.088, time:20.49
[2, 12000] loss: 1.063, time:24.45
[3, 2000] loss: 0.987, time:3.99
[3, 4000] loss: 0.975, time:7.97
[3, 6000] loss: 0.970, time:11.93
[3, 8000] loss: 0.947, time:15.89
[3, 10000] loss: 0.964, time:19.85
[3, 12000] loss: 0.930, time:23.81
[4, 2000] loss: 0.814, time:3.98
[4, 4000] loss: 0.831, time:7.93
[4, 6000] loss: 0.833, time:11.91
[4, 8000] loss: 0.829, time:15.86
[4, 10000] loss: 0.841, time:19.81
[4, 12000] loss: 0.826, time:23.78
[5, 2000] loss: 0.701, time:3.98
[5, 4000] loss: 0.708, time:7.93
[5, 6000] loss: 0.710, time:11.88
[5, 8000] loss: 0.746, time:15.84
[5, 10000] loss: 0.734, time:19.81
[5, 12000] loss: 0.756, time:23.78
[6, 2000] loss: 0.582, time:4.23
[6, 4000] loss: 0.597, time:8.23
[6, 6000] loss: 0.628, time:12.22
[6, 8000] loss: 0.661, time:16.20
[6, 10000] loss: 0.667, time:20.18
[6, 12000] loss: 0.678, time:24.14
[7, 2000] loss: 0.494, time:3.98
[7, 4000] loss: 0.543, time:7.94
[7, 6000] loss: 0.576, time:11.92
[7, 8000] loss: 0.577, time:15.89
[7, 10000] loss: 0.586, time:19.85
[7, 12000] loss: 0.604, time:23.83
[8, 2000] loss: 0.442, time:4.02
[8, 4000] loss: 0.457, time:7.97
[8, 6000] loss: 0.494, time:11.96
[8, 8000] loss: 0.524, time:15.93
[8, 10000] loss: 0.521, time:19.92
[8, 12000] loss: 0.558, time:23.90
[9, 2000] loss: 0.349, time:3.99
[9, 4000] loss: 0.389, time:7.96
[9, 6000] loss: 0.408, time:11.92
[9, 8000] loss: 0.464, time:15.88
[9, 10000] loss: 0.500, time:19.85
[9, 12000] loss: 0.490, time:23.82
[10, 2000] loss: 0.319, time:4.00
[10, 4000] loss: 0.354, time:7.98
[10, 6000] loss: 0.356, time:12.02
[10, 8000] loss: 0.428, time:16.11
[10, 10000] loss: 0.422, time:20.06
[10, 12000] loss: 0.447, time:24.25
训练完成
预测结果: plane car dog horse
10000张测试图片的准确率:66%
plane的准确率:72%
car的准确率:74%
bird的准确率:60%
cat的准确率:50%
deer的准确率:54%
dog的准确率:60%
frog的准确率:72%
horse的准确率:68%
ship的准确率:80%
truck的准确率:73%三、全局平均池化层GAP
代码
from 准备数据 import trainloader, testloader, classes, images
# ========================================构建网络========================================
import torch
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# --------------------构建卷积网络--------------------
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5) #卷积层1
self.pool1 = nn.MaxPool2d(2, 2) #池化层1
self.conv2 = nn.Conv2d(16, 36, 5) #卷积层2
self.pool2 = nn.MaxPool2d(2, 2) #池化层2
self.aap=nn.AdaptiveAvgPool2d(1) #全局平均池化层
self.fc3 = nn.Linear(36, 10) #全连接层
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x))) #卷积层1->激励函数层->池化层1
x = self.pool2(F.relu(self.conv2(x))) #卷积层2->激励函数层->池化层2
x = self.aap(x)
x = x.view(x.shape[0], -1)
x = self.fc3(x)
return x
# --------------------实例化网络--------------------
net = Net()
net=net.to(device)
# 定义损失函数和优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# ========================================训练模型========================================
import time
for epoch in range(10):
start=time.time()
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取训练数据
inputs, labels = data #解包元组
inputs, labels = inputs.to(device), labels.to(device) #将数据放在GPU上
# 前向传播
outputs = net(inputs)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad() # 清空上一步的残余更新参数值,将神经网络参数梯度降为0
loss.backward() # 误差反向传递,计算参数更新值
optimizer.step() # 优化梯度,将参数更新值施加到net的parameters上
# 记录误差
running_loss += loss.item()
# 每2000步打印损失
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f, time:%.2f' % (epoch + 1, i + 1, running_loss / 2000, time.time()-start))
running_loss = 0.0
print('训练完成')
# 预测结果
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1) #输出值的最大值作为预测值
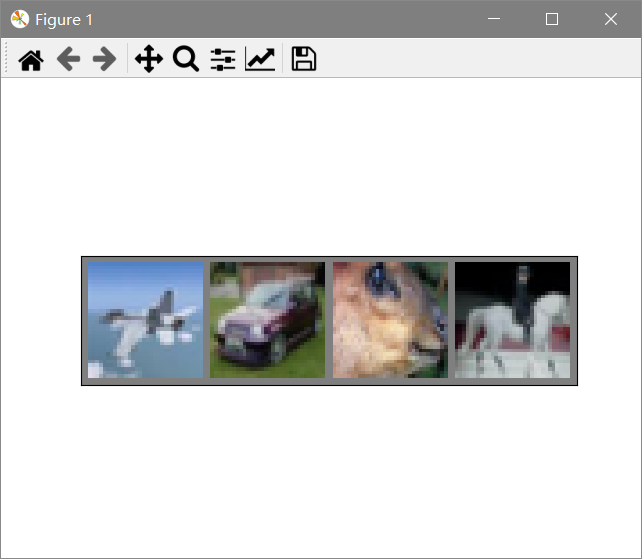
print('预测结果: ', ' '.join('%5s' % classes[predicted[j]]for j in range(4)))
# ========================================测试模型========================================
# --------------------整体预测准确率--------------------
correct = 0
total = 0
with torch.no_grad():
# 从测试数据中取出数据
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) #模型预测的最大值作为预测值
total += labels.size(0) #统计测试图片个数
correct += (predicted == labels).sum().item() #统计正确预测的图片数
print('10000张测试图片的准确率:%d%%' % (100 * correct / total))
# --------------------每个类别预测准确率--------------------
class_correct = list(0. for i in range(10)) #正确的类别个数
class_total = list(0. for i in range(10)) #一共10个类别
with torch.no_grad():
# 从测试数据中取出数据
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze() #预测正确的返回True,预测错误的返回False;squeeze将数据转换为一维数据
for i in range(4):
label = labels[i] #提取标签
class_correct[label] += c[i].item() #预测正确个数
class_total[label] += 1 #总数
for i in range(10):
print('%5s的准确率:%2d%%' % (classes[i], 100 * class_correct[i] / class_total[i]))
运行结果

deer ship horse plane[1, 2000] loss: 2.129, time:5.14
[1, 4000] loss: 1.875, time:8.86
[1, 6000] loss: 1.741, time:12.61
[1, 8000] loss: 1.693, time:16.29
[1, 10000] loss: 1.638, time:20.04
[1, 12000] loss: 1.598, time:23.71
[2, 2000] loss: 1.549, time:3.71
[2, 4000] loss: 1.504, time:7.43
[2, 6000] loss: 1.484, time:11.13
[2, 8000] loss: 1.461, time:14.89
[2, 10000] loss: 1.431, time:18.68
[2, 12000] loss: 1.407, time:22.37
[3, 2000] loss: 1.376, time:3.69
[3, 4000] loss: 1.343, time:7.37
[3, 6000] loss: 1.349, time:11.18
[3, 8000] loss: 1.324, time:14.89
[3, 10000] loss: 1.303, time:18.60
[3, 12000] loss: 1.297, time:22.36
[4, 2000] loss: 1.262, time:3.69
[4, 4000] loss: 1.250, time:7.36
[4, 6000] loss: 1.246, time:11.01
[4, 8000] loss: 1.240, time:14.68
[4, 10000] loss: 1.239, time:18.35
[4, 12000] loss: 1.232, time:22.00
[5, 2000] loss: 1.185, time:3.69
[5, 4000] loss: 1.214, time:7.34
[5, 6000] loss: 1.194, time:11.01
[5, 8000] loss: 1.175, time:14.67
[5, 10000] loss: 1.148, time:18.36
[5, 12000] loss: 1.174, time:22.03
[6, 2000] loss: 1.113, time:3.70
[6, 4000] loss: 1.160, time:7.36
[6, 6000] loss: 1.129, time:11.03
[6, 8000] loss: 1.144, time:14.70
[6, 10000] loss: 1.125, time:18.35
[6, 12000] loss: 1.110, time:22.01
[7, 2000] loss: 1.103, time:3.70
[7, 4000] loss: 1.100, time:7.34
[7, 6000] loss: 1.098, time:11.02
[7, 8000] loss: 1.091, time:14.67
[7, 10000] loss: 1.077, time:18.32
[7, 12000] loss: 1.076, time:21.97
[8, 2000] loss: 1.065, time:3.68
[8, 4000] loss: 1.066, time:7.33
[8, 6000] loss: 1.037, time:10.99
[8, 8000] loss: 1.058, time:14.65
[8, 10000] loss: 1.054, time:18.31
[8, 12000] loss: 1.064, time:21.96
[9, 2000] loss: 1.060, time:3.68
[9, 4000] loss: 1.024, time:7.33
[9, 6000] loss: 1.032, time:10.99
[9, 8000] loss: 1.029, time:14.66
[9, 10000] loss: 1.029, time:18.30
[9, 12000] loss: 1.011, time:21.96
[10, 2000] loss: 0.995, time:3.67
[10, 4000] loss: 1.023, time:7.33
[10, 6000] loss: 1.007, time:11.00
[10, 8000] loss: 1.020, time:14.64
[10, 10000] loss: 0.996, time:18.29
[10, 12000] loss: 1.014, time:21.96
训练完成
预测结果: frog car horse plane
10000张测试图片的准确率:63%
plane的准确率:66%
car的准确率:73%
bird的准确率:51%
cat的准确率:57%
deer的准确率:43%
dog的准确率:32%
frog的准确率:76%
horse的准确率:74%
ship的准确率:81%
truck的准确率:79%四、程序分析
本程序用了两种方法构建卷积神经网络,即全局平均池化和不采用全局平均池化。通过程序的运行结果可以看出,不采用全局平均池化相较采用全局平均池化准确率更高,但训练时间更长。
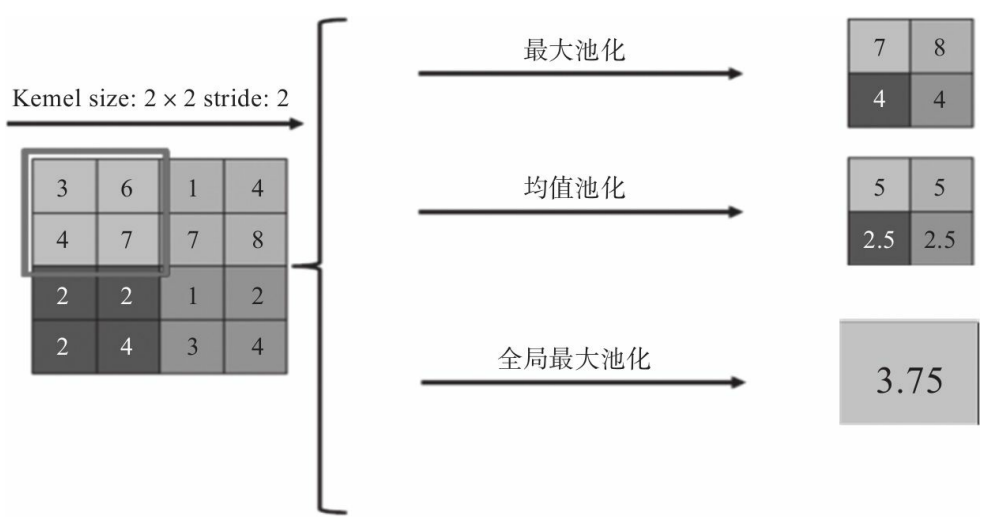
两种方法构建卷积神经网络时,同样采用两个卷积层和两个池化层(MaxPool2d),但不采用全局平均池化的神经网络使用了两个全连接层,采用全局平均池化的神经网络只使用了一个全连接测。
相较之下,使用全局平均池化层能减少很多参数,可以减轻过拟合的发生,而且在减少参数的同时,其泛化能力也比较好。
PyTorch程序练习(一):PyTorch实现CIFAR-10多分类的更多相关文章
- 【翻译】TensorFlow卷积神经网络识别CIFAR 10Convolutional Neural Network (CNN)| CIFAR 10 TensorFlow
原网址:https://data-flair.training/blogs/cnn-tensorflow-cifar-10/ by DataFlair Team · Published May 21, ...
- 解决运行pytorch程序多线程问题
当我使用pycharm运行 (https://github.com/Joyce94/cnn-text-classification-pytorch ) pytorch程序的时候,在Linux服务器 ...
- 转:程序员最值得关注的10个C开源项目
程序员最值得关注的10个C开源项目 1. Webbench Webbench 是一个在 linux 下使用的非常简单的网站压测工具.它使用 fork ()模拟多个客户端同时访问我们设定的 URL,测试 ...
- 程序员从初级到中级10个秘诀——摘自CSDN
程序员从初级到中级10个秘诀 1.学习先进的搜索技术.手段和及策略 2.帮助别人 教别人始终是学习一切东西的最好方法之一.相对而言,由于你在开发领域还是个新手,认为自己没什么可教给人家的,这可以理解. ...
- 【转载】PyTorch系列 (二):pytorch数据读取
原文:https://likewind.top/2019/02/01/Pytorch-dataprocess/ Pytorch系列: PyTorch系列(一) - PyTorch使用总览 PyTorc ...
- DL Practice:Cifar 10分类
Step 1:数据加载和处理 一般使用深度学习框架会经过下面几个流程: 模型定义(包括损失函数的选择)——>数据处理和加载——>训练(可能包括训练过程可视化)——>测试 所以自己写代 ...
- Pytorch学习--编程实战:猫和狗二分类
Pytorch学习系列(一)至(四)均摘自<深度学习框架PyTorch入门与实践>陈云 目录: 1.程序的主要功能 2.文件组织架构 3. 关于`__init__.py` 4.数据处理 5 ...
- PyTorch迁移学习-私人数据集上的蚂蚁蜜蜂分类
迁移学习的两个主要场景 微调CNN:使用预训练的网络来初始化自己的网络,而不是随机初始化,然后训练即可 将CNN看成固定的特征提取器:固定前面的层,重写最后的全连接层,只有这个新的层会被训练 下面修改 ...
- 【小白学PyTorch】15 TF2实现一个简单的服装分类任务
[新闻]:机器学习炼丹术的粉丝的人工智能交流群已经建立,目前有目标检测.医学图像.时间序列等多个目标为技术学习的分群和水群唠嗑的总群,欢迎大家加炼丹兄为好友,加入炼丹协会.微信:cyx64501661 ...
- 了解Pytorch|Get Started with PyTorch
一个开源的机器学习框架,加速了从研究原型到生产部署的路径. !pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple import ...
随机推荐
- Competition Set - AtCoder I
这里记录的是这个账号的比赛情况. ARC172 2024-2-18 Solved:4/6 D(Hard-,2936) 给定所有数对 \((i,j),1\le i\lt j\le n\) 的一个排列 \ ...
- 程序员天天 CURD,怎么才能成长,职业发展的思考 ?
前言 关于程序员成长的话题,我前面写过一篇文章 - 程序员天天CURD,职业生涯怎么发展的思考. 现在回头看,对程序员这个职业发展的认识以及怎么发展还是有一些局限性.有一句话是这么说的:人的成长就是不 ...
- neovim 使用系统剪贴板
neovim 使用系统剪贴板 1.vim 与 neovim 使用系统剪切板的不同 Nvim has no direct connection to the system clipboard. Inst ...
- 【GUI界面软件】快手评论区采集:自动采集10000多条,含二级评论、展开评论!
目录 一.背景说明 1.1 效果演示 1.2 演示视频 1.3 软件说明 二.代码讲解 2.1 爬虫采集模块 2.2 软件界面模块 2.3 日志模块 三.获取源码及软件 一.背景说明 1.1 效果演示 ...
- 【动画进阶】巧用 CSS/SVG 实现复杂线条光效动画
最近,群里在讨论一个很有意思的线条动画效果,效果大致如下: 简单而言,就是线条沿着不规则路径的行进动画,其中的线条动画可以理解为是特殊的光效. 本文,我们将一起探索,看看在不使用 JavaScript ...
- Typecho博客网站迁移:MySQL ➡️ MarialDB
目录 1. 引言 2. Typecho的自定义配置迁移 3. 数据库迁移:MySQL- > MarialDB 3.1 在原服务器中备份并导出数据库文件 3.2 将"backupdb.s ...
- nvm环境安装
目录 nvm是什么 使用背景 nvm的坑. nvm,node,npm之间的区别. nvm.nodejs.npm的关系: nvm-windows下载地址 安装 linux . mac 源码包下载地址 解 ...
- gorm使用小结
增 db.Create(user) db.Save(user) 参数只能用**结构体指针****,因为要根据指针写入该条插入的数据, 所以user可以作为该条数据使用. 新增只能用结构体 save方法 ...
- PaliGemma 正式发布 — Google 最新发布的前沿开放视觉语言模型
PaliGemma 是 Google 推出的新一代视觉语言模型家族,能够接收图像与文本输入并生成文本输出. Google 团队已推出三种类型的模型:预训练(PT)模型.混合模型和微调(FT)模型,这些 ...
- Python:global、local与nonlocal变量
1 local和global变量 先来看一个最简单的Python程序例子: import numpy as np n = 2 def func(a): b = 1 return a + b print ...