JuiceFS 在多云架构中加速大模型推理
在大模型的开发与应用中,数据预处理、模型开发、训练和推理构成四个关键环节。本文将重点探讨推理环节。在之前的博客中,社区用户 BentoML 和贝壳的案例提到了使用 JuiceFS 社区版来提高模型加载的效率。本文将结合我们的实际经验,详细介绍企业版在此场景下的优势。
下图是一个典型的大模型推理服务的架构。我们可以观察到几个关键特点。首先,架构跨越多个云服务或多个数据中心。目前在大模型领域, GPU 资源紧张,多数厂商或公司倾向于采用多云、多数据中心或混合云的策略来部署他们的推理服务。
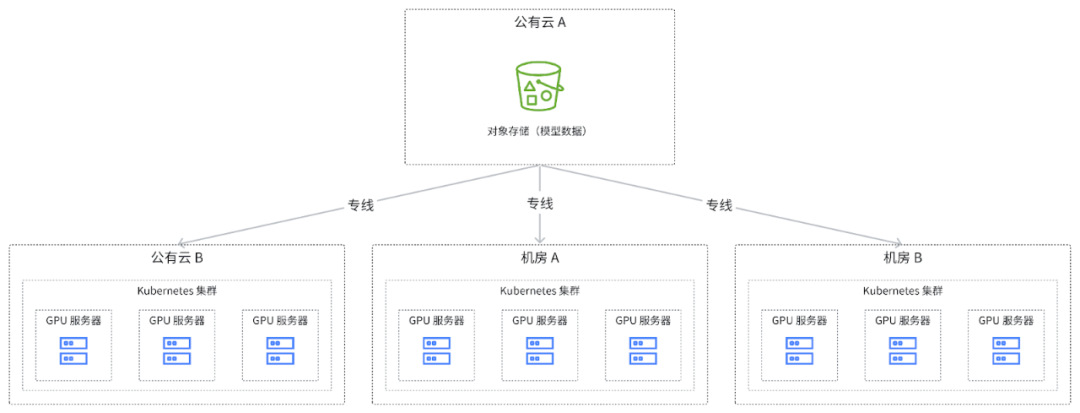
另一个特点是,为了确保数据一致性和管理的便捷性,会在特定地区选择公有云的对象存储作为所有模型数据的存储点。当进行推理任务调度时,可能会选取特定云服务进行任务调度。数据模型的拉取过程需要人工介入,如提前进行数据拷贝。这是因为调度系统不清楚当前数据中心具体需要哪些数据,而这些数据又是动态变化的,所以数据拷贝过程会带来额外成本。
此外,从每个推理计算集群的内部情况来看,由于是规模庞大的集群,会有数百到数千 GPU 卡,因此在推理服务器初始化时,会有高并发模型数据拉取需求。
因此,概括地说在大模型推理与存储相关的挑战主要集中这样几个方面:高效访问数据、跨区域数据快速分发、存量数据读取以及资源优化。接下来将逐个为大家介绍我们在这些场景中的实践经验。
挑战 1:如何保证大模型数据的高吞吐、高并发读取?
推理环节常需处理百 GB 级别的模型文件,满足高并发顺序读取需求。加载速度是用户最关注的问题之一。
为了满足这种场景的性能需求,可以借助 JuiceFS 企业版的分布式缓存构建大规模的缓存空间。将常用模型数据集中存储在缓存集群中,能显著提高数据读取速度,特别是在同时启动数千个推理实例时。此外,对于需要频繁切换模型的 AI 应用场景,如 Stable Diffusion 文生图服务,缓存集群可以大幅减少模型加载时间,从而直接提升用户体验。
例如在单机单卡加载 Safetensors 格式的 Stable Diffusion 模型时,从缓存集群读取数据的延迟可低至 0.5ms,而从对象存储读取的延迟通常在 20ms 左右, 性能提升了将近 40 倍。
下图是 JuiceFS 分布式缓存的架构图,上层为推理集群,中间层为 JuiceFS 缓存集群,底层为对象存储,右上角是元数据服务。在推理服务部署后,首先通过推理集群上挂载的 JuiceFS 访问所需的模型数据。如果数据可以在推理集群的本地内存缓存中找到,则直接使用;若未命中,则查询位于中间的缓存集群。缓存集群如果也未命中,最后会从对象存储读取数据。
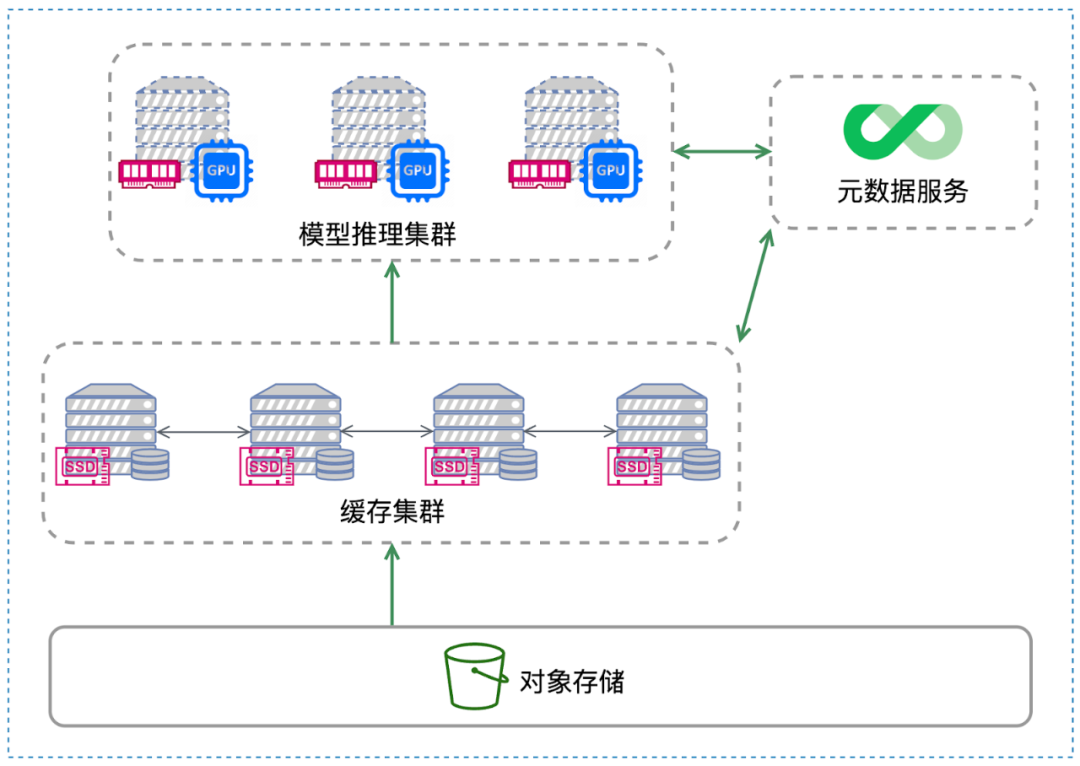
虽然推理集群和缓存层从图上看似乎是分开的两个层次,但在实际应用或部署中,如果GPU 机器上有 NVMe SSD,这两层可以合并。
在每个 GPU 机器都配备多块 SSD 的情况下,下图示例中,每个 GPU 机器配有三块 SSD,其中一块 SSD 用作本地缓存,其余两块 SSD 则用作分布式缓存的存储盘。这种情况下,我们推荐一个部署方式:在一个 GPU 服务器上部署两个客户端,FUSE daemon 和缓存集群客户端。当推理任务需要读取数据时,它首先会尝试从本地 FUSE 挂载点读取数据。如果本地缓存中没有相应的模型数据,推理任务将通过同一台机器上的另一个 JuiceFS 客户端访问分布式缓存。完成数据读取后,数据将返回给推理任务,并在缓存集群管理的两块 SSD 及本地 FUSE 挂载点上缓存,以便未来快速访问。
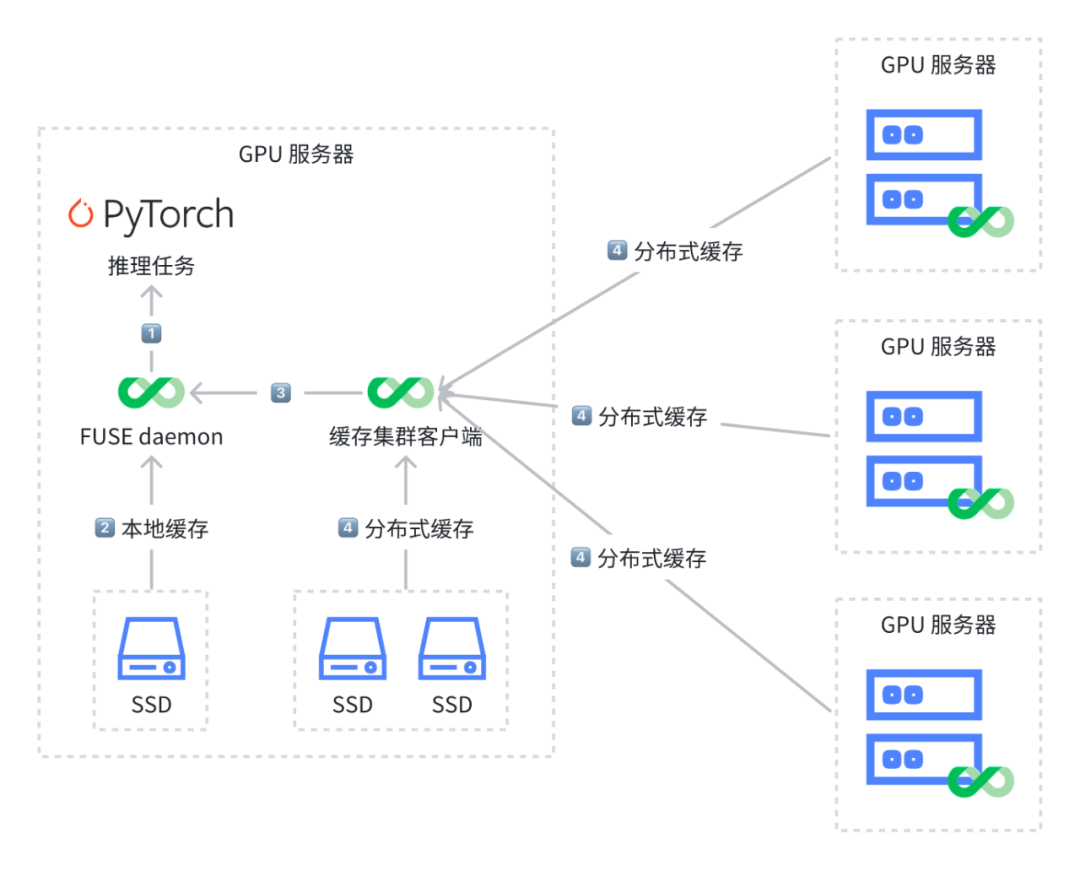
这种在一个 GPU 服务器上部署两个客户端的做法有两个主要好处:
- 首先,通过本地缓存,可以尽量减少网络通信的开销,虽然 GPU 服务器间通过高速网卡进行网络通信,但网络通信本身还是会产生大量的开销;
- 其次,通过缓存集群客户端,可以让推理任务访问其它 GPU 服务器上的数据,实现一个分布式缓存集群的效果。
挑战 2:如何在多云、混合云架构中有效地分发模型数据到各计算节点?
在多云和混合云架构中,由于数据分散在不同的云平台和数据中心,传统的手动介入、拷贝和迁移方法不仅成本高,而且管理和维护也较为复杂,包括权限控制在内的各种问题都十分棘手。
JuiceFS 企业版镜像文件系统功能允许用户将数据从一个地区复制到多个地区,形成一对多的复制关系。整个复制流程对用户和应用来说是透明的:只需将数据写入指定区域,系统便会自动规划并复制到其它多个区域。
下图展示了在镜像文件系统中数据写入与数据读取时的流程。图中展示了两个区域:源区域和镜像区域。当数据在源区域写入时,JuiceFS 会自动将数据从源区域复制到镜像区域。
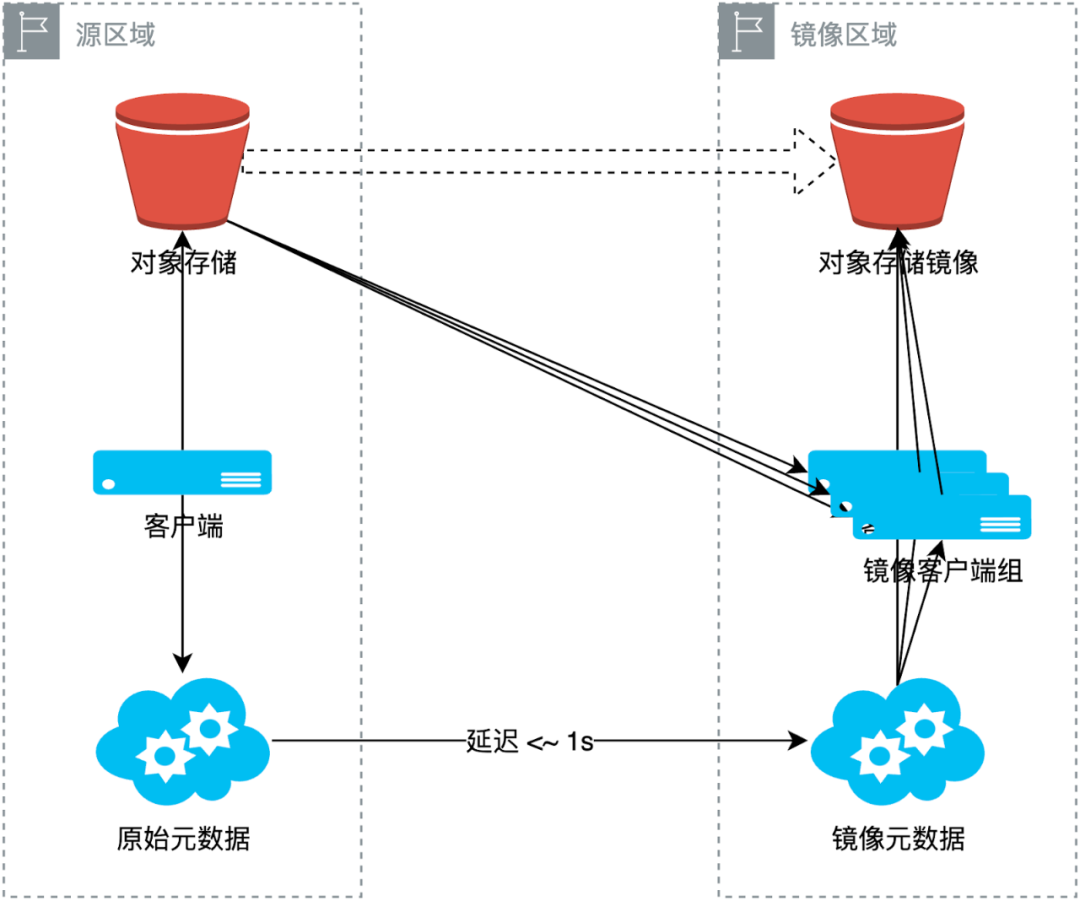
在读取数据时,镜像区域的客户端首先尝试从其所在区域的对象存储中拉取数据。如果数据不存在或因同步延迟未到达,则自动回退到源区域存储,通过备用数据源链路拉取数据。因此,镜像区域的所有客户端最终都能访问到数据,虽然部分数据可能来自备用数据源。
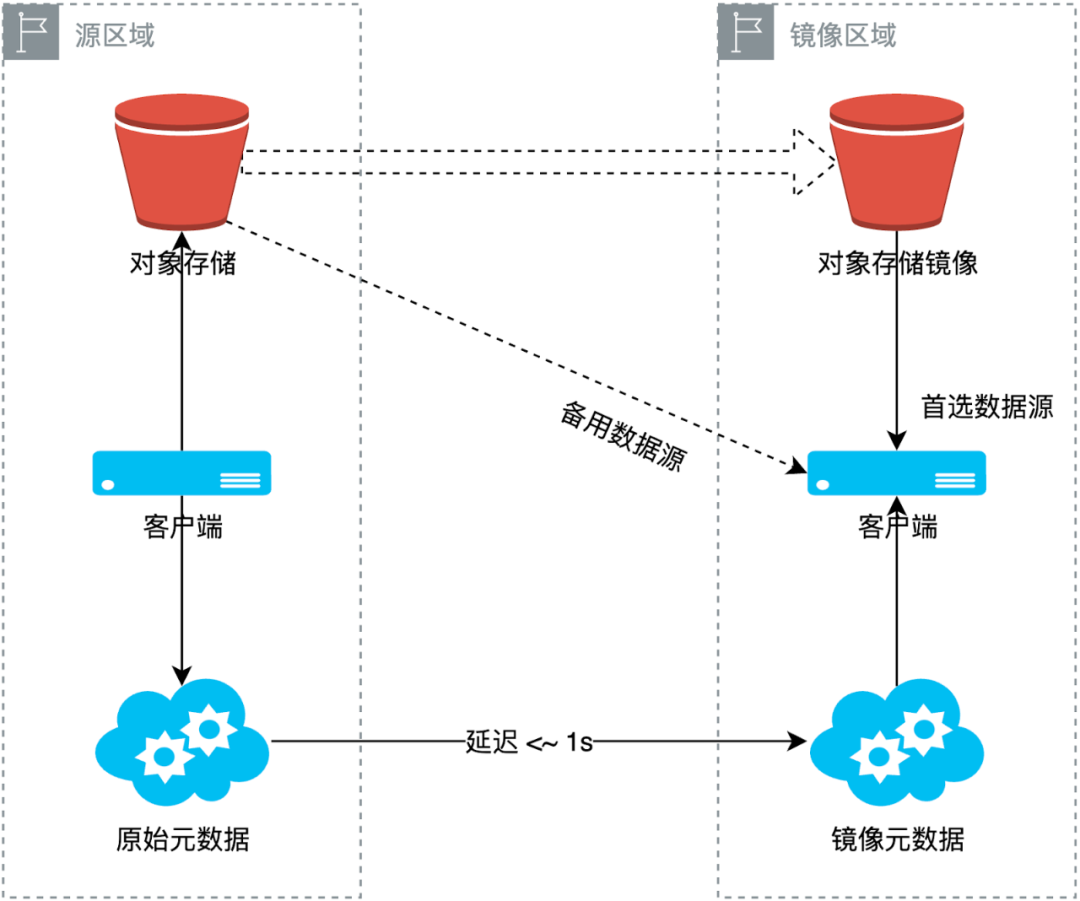
写数据流程示例
这里展示了一个大模型企业实际部署镜像文件系统的案例,其架构与文章开头展示的典型架构图相似。在图的顶部有一个中心集群,该集群作为数据生产的源头。
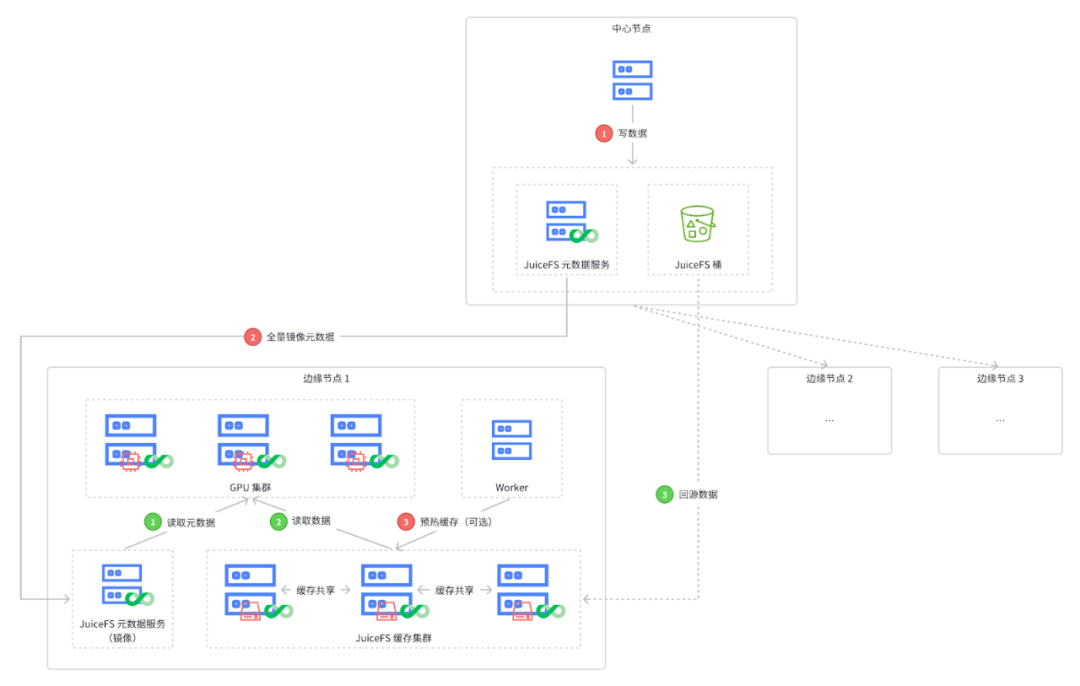
- 步骤 1:写数据。数据首先在中心集群中被创建并写入;
- 步骤 2:全量镜像元数据。数据生产完成后,将写入到 JuiceFS 中,触发元数据的全量镜像流程。如图所示,数据从中心的 JuiceFS 元数据服务被镜像到一个或多个边缘集群(本例中为三个),使得边缘集群能够就近访问本地集群内的元数据;
- 步骤 3:预热缓存(可选)。这一步是为了优化数据访问速度。当有新数据添加后,除了复制元数据外,还希望能够就近访问这些数据。在没有对象存储的环境中,可以结合分布式缓存功能,在每个机房内部署一个分布式缓存集群。然后通过缓存预热,将新增的数据复制到每个边缘集群的缓存集群中,从而加速数据访问。
读数据流程示例
- 步骤 1:访问镜像的元数据服务。如上图绿色编号所示,当 GPU 集群需要获取模型数据时,首先会访问镜像的元数据服务;
- 步骤 2:读取元数据并获取数据。在读取到元数据后,客户端会首先尝试通过机房内的缓存集群获取所需数据。如果之前进行了缓存预热,那么大多数情况下可以直接在机房内的缓存集群中命中所需的模型数据;
- 步骤 3:回源数据。如果由于某种原因未能在缓存集群中找到数据,也无需担心,因为所有缓存集群的节点都会自动回源至中心的对象存储桶中获取最终的原始数据。
因此,整个数据读取流程是畅通无阻的。即使部分数据未被预热或新数据尚未预热成功,也可以通过自动回源的方式,从中心的 JuiceFS 存储桶中拉取数据。
挑战 3:低成本高效读取海量存量数据
除了多云、混合云架构下数据分发的挑战,还有一个常见的需求,在与多家大模型公司的交流中,我们了解到许多公司希望将其积累的大量原始数据(如数 PB 级别)直接迁移到 JuiceFS 中。这种需求增加了大规模数据管理的复杂性,并可能需要进行数据双写等调整,这些都可能影响业务流程的正常运作。
JuiceFS 企业版的「导入对象存储元数据」功能使得企业可以更高效地完成数据导入,同时减少对业务的侵入性。用户无需进行数据拷贝,只需持续导入元数据即可。同时,导入的数据可以通过 JuiceFS 的分布式缓存进行加速,从而提升数据访问速度。下图是该功能的工作流程示意图:
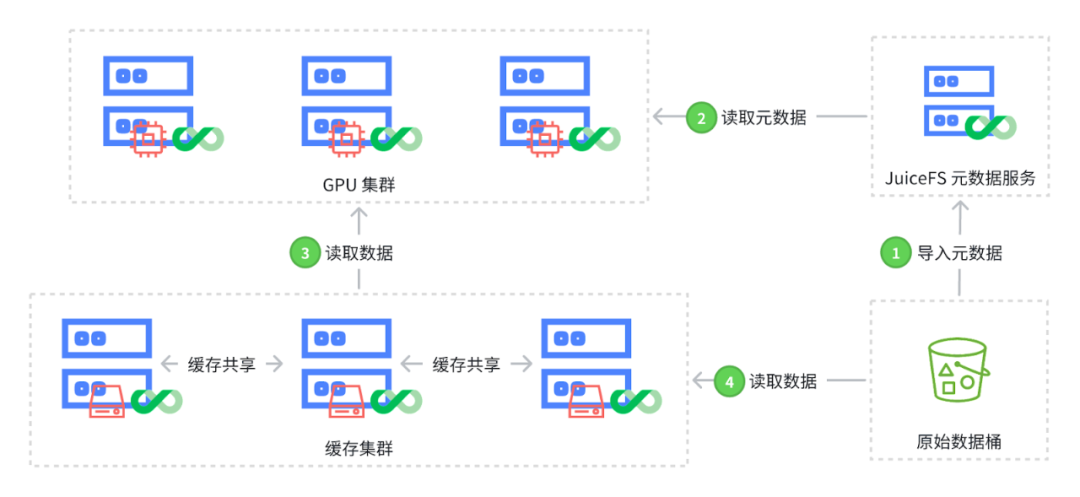
第一步,导入元数据。通过 JuiceFS 的命令行工具,用户可以选择性地导入原始数据桶中的部分数据,而不必导入整个存储桶。这一过程主要通过前缀匹配实现,此步骤仅涉及元数据的导入,不拷贝对象存储中的数据,因此导入流程会很快完成。
元数据导入不是一次性的操作,随着原始数据的增加或修改,用户可以再次执行增量导入,无需担心重复导入造成额外开销。每次增量导入时,系统只会导入新增或修改的部分数据的元数据,不会重复导入已处理的文件,从而避免额外负担。
第二步,读取元数据。当元数据导入到 JuiceFS 后,应用(例如推理任务)便能通过 JuiceFS 客户端访问这些导入的数据。因此,应用可以立即开始执行,无需等待原始数据桶中的数据拷贝到 JuiceFS 中。
第三步,读取数据。在推理等场景中,通常会配置分布式缓存以优化数据读取。由于在第一步中仅导入了元数据而未导入实际数据,初次通过分布式缓存读取时将无法直接获取数据。
第四步,回源原始桶并缓存数据。这一步需要通过分布式缓存系统回源到原始数据桶中,从中检索并读取数据。读取完成后,数据会自动缓存到 JuiceFS 的分布式缓存中,这样在后续访问相同数据时,就无需重新回到原始数据桶中进行数据读取,从而提高数据访问效率。
经过这几个步骤,推理任务便能够快速访问存量数据,并获得高性能分布式缓存的加速效果。
挑战 4:在异构环境中,如何充分利用硬件资源以优化存储和计算性能?
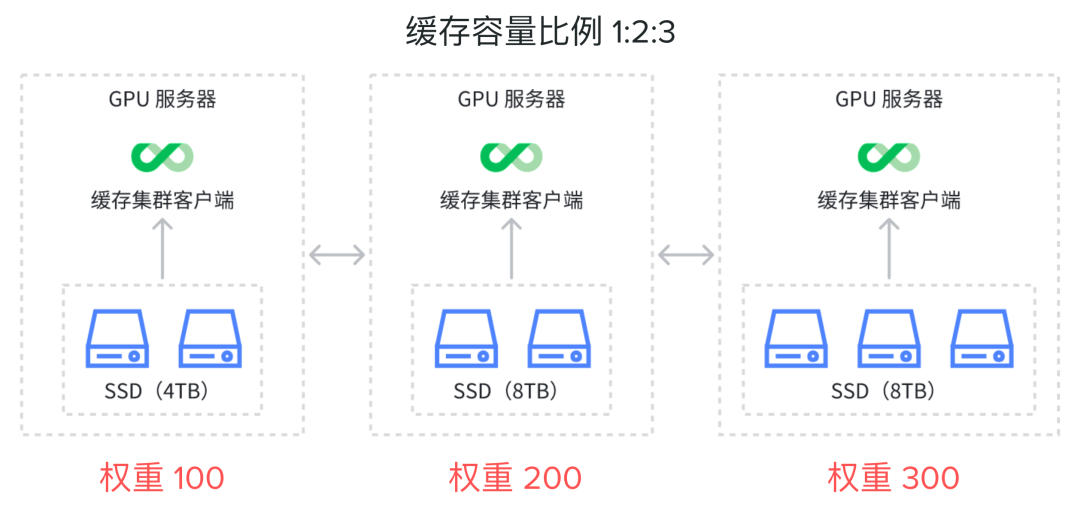
异构环境涉及到一个系统内部集成多种不同类型或配置的硬件设备,只有充分利用异构的硬件资源才能为企业带来最大价值。在下面这个示例中,我们有三台机器,每台机器配备的 SSD 数量和容量如下表所示,根据每台机器的总存储容量,这三台机器的缓存容量比例为 1:2:3。
| 编号 | SSD 数量 | 单块 SSD 容量(TB) | 总容量(TB) |
|---|---|---|---|
| 机器 1 | 2 | 4 | 8 |
| 机器 2 | 2 | 8 | 16 |
| 机器 3 | 3 | 8 | 24 |
默认情况下,JuiceFS 的分布式缓存假设所有机器的硬件配置是同构的,因此所有缓存节点的权重相同。在这种配置下,整个系统的性能将被最小容量机器的容量上限所限制,在这个示例中是 8TB,其它机器缓存盘无法被充分利用,第三台机器中甚至有 ⅔ 可能未被利用。
为了避免这种情况,我们引入了「缓存节点权重」的概念,允许用户根据实际环境动态或静态地调整每个 GPU 节点的权重。例如,第一台 GPU 服务器的缓存权重可以设置为默认值 100,第二台为 200,第三台为 300,这些权重与 SSD 容量的比例(1:2:3)相对应。通过这种差异化权重设置,可以更有效地利用各缓存机器的存储资源,优化整体系统的性能。这种方法为处理不同硬件配置的机器提供了一个典型的解决方案。
除了上述这个场景外,缓存节点权重还可以应用于其它场景。例如,GPU 机器容易出现故障,用户可能每周需要对一两台机器进行下线和更换硬件等常规运维操作。因机器直接停机将导致该机器上的缓存数据丢失或暂时无法访问,这可能影响整个缓存集群的命中率。在这个场景中,也可以使用「缓存节点权重」功能,来尽可能减少机器故障或维护过程中对缓存集群利用率的影响。
未来展望
最后,让我们探讨一下未来我们在推理场景以及其它潜在应用场景中将要进行哪些改进。
首先,引入分布式缓存的多副本特性。目前,分布式缓存系统中的数据通常是单副本形式,意味着如果某台机器(如 GPU 服务器)意外宕机,该机器上的缓存数据将因缺乏备份而丢失,从而直接影响缓存命中率。由于这种情况是突发的,我们无法通过人工干预来逐步迁移数据至其它节点。
在这种背景下,单副本缓存将不可避免地影响整个缓存集群的效率。因此,我们正在考虑将其从单副本升级为多副本。这种升级的好处显而易见:尽管使用了更多的存储空间,但是可以显著提高机器频繁故障场景的缓存命中率和缓存的可用性。
第二点,我们正在探索用户态客户端的实现。当前,基于 FUSE 挂载方式的文件系统虽然能有效地实现文件系统功能,但由于其依赖 Linux 系统内核,涉及用户态与内核态之间的多次切换和数据拷贝,因此带来了一定的性能开销。尤其在云上的无服务器(serverless)和 Kubernetes 环境中,FUSE 挂载可能无权限使用,这限制了 JuiceFS 的应用场景。
因此,我们正在考虑开发一个纯用户态的客户端,这将是一个不依赖内核态的组件,可以显著降低使用门槛,并在不支持 FUSE 的环境中提供服务。此外,由于避免了内核态与用户态的频繁切换和内存拷贝,这种客户端在性能上也可能有显著提升,特别是在需要高吞吐量的 GPU 密集型环境中。
然而,这种客户端的一个潜在缺点是它可能不如 POSIX 接口透明,因为它可能需要用户通过引入特定的库(如 JuiceFS 库)来实现功能,这种方式可能会对应用程序产生一定的侵入性。
第三,提升可观测性。鉴于 JuiceFS 架构中包含多个复杂环节,如从 GPU 机器到缓存集群,再通过专线回到中心的对象存储,以及缓存预热等,我们计划引入更便捷的工具和方法来增强整体架构的可观测性。这将有助于 JuiceFS 的用户更快更方便地定位及分析问题。未来我们将进一步优化包括分布式缓存在内的各个组件的可观测性,帮助用户在出现问题时进行快速的问题排查和解决。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。
JuiceFS 在多云架构中加速大模型推理的更多相关文章
- PyQt(Python+Qt)学习随笔:Model/View架构中的Model模型概念
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 Model/View架构中的Model模型Model与数据源通信,为体系结构中的其他组件提供数据接口 ...
- 优化故事: BLOOM 模型推理
经过"九九八十一难",大模型终于炼成.下一步就是架设服务,准备开门营业了.真这么简单?恐怕未必!行百里者半九十,推理优化又是新的雄关漫道.如何进行延迟优化?如何进行成本优化 (别忘 ...
- 如何借助分布式存储 JuiceFS 加速 AI 模型训练
传统的机器学习模型,数据集比较小,模型的算法也比较简单,使用单机存储,或者本地硬盘就足够了,像 JuiceFS 这样的分布式存储并不是必需品. 随着近几年深度学习的蓬勃发展,越来越多的团队开始遇到了单 ...
- Flume在企业大数据仓库架构中位置及功能
Flume在企业大数据仓库架构中位置及功能 hadoop 数据仓库 flume 数据仓库架构 1.如下图所示,外部数据中,关系型数据库导入到HDFS用sqoop,由Nginx产生的文件实时监控用Flu ...
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
- PyQt(Python+Qt)学习随笔:model/view架构中的排序和代理模型QSortFilterProxyModel
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 在Model/View体系架构中,有两种方法可以进行排序:选择哪种方法取决于底层模型. 如 ...
- 庐山真面目之十三微服务架构中如何在Docker上使用Redis缓存
一.介绍 1.开始说明 在微服务器架构中,有一个组件是不能少的,那就是缓存组件.其实来说,缓存组件,这个叫法不是完全正确,因为除了缓存功能,它还能完成其他很多功能.我就不隐瞒了,今天我们要探讨 ...
- 大型 JavaScript 应用架构中的模式
原文:Patterns For Large-Scale JavaScript Application Architecture by @Addy Osmani 今天我们要讨论大型 JavaScript ...
- [转]大型 JavaScript 应用架构中的模式
目录 1.我是谁,以及我为什么写这个主题 2.可以用140个字概述这篇文章吗? 3.究竟什么是“大型”JavaScript应用程序? 4.让我们回顾一下当前的架构 5.想得长远一些 6.头脑风暴 7. ...
- TOGAF架构能力框架之架构合同、成熟度模型和架构技能框架
TOGAF架构能力框架之架构合同.成熟度模型和架构技能框架 5. 架构合同 架构合同是在开发团体和赞助者之间关于架构的交付物.质量以及适用目标的联合协议,并且通过有效的架构治理将会促使这些协议的成功施 ...
随机推荐
- python并发执行request请求
在Python中,我们可以使用requests库来发送HTTP请求,并使用threading.multiprocessing.asyncio(配合aiohttp)或concurrent.futures ...
- 在Linux应用层使用POSIX定时器
在Linux应用层使用POSIX定时器 ref : http://blog.chinaunix.net/uid-28458801-id-5035347.html http://blog.sina.co ...
- 解析QAnything启动命令过程
一.启动命令过程日志 启动命令bash ./run.sh -c local -i 0 -b hf -m Qwen-1_8B-Chat -t qwen-7b-chat.输入日志如下所示: root@MM ...
- Vue 组件间通信有哪几种方式?
父子通信 (1)父组件向子组件传值props <button-counter :title="send"></button-counter> Vue.com ...
- Mybatis ResultMap复杂对象一对一查询结果映射之association
Mybatis复杂对象映射配置ResultMap的association association:映射到POJO的某个复杂类型属性,比如订单order对象里面包含user对象 表结构 项目结构 pom ...
- SpringBoot注解配置文件映射属性和实体类
配置文件加载 方式一 Controller上面配置@PropertySource({"classpath:pay.properties"}) 添加属性@Value("wx ...
- Webpack3.x升级至 4.x 小记
近期项目部署遇到点问题,需要升级webpack版本,特此整理一小记,记录升级过程中的依赖包及报错处理. 本次升级的依赖包及对应版本对照表: npm 包 当前版本 升级版本 S/D vue ^2.5.1 ...
- Django REST framework的10个常见组件
Django REST framework的10个常见组件: 权限组件 认证组件 访问频率限制组件 序列化组件 路由组件 视图组件 分页组件 解析器组件 渲染组件 版本组件
- 魔百和s905l3a蓝牙系列 在armbian驱动并使用蓝牙!
文章已废弃,因为现在x大的dtb不需要驱动直接可以使用 之后我会重新写文章,感谢大家
- [oeasy]python0033_任务管理_jobs_切换任务_进程树结构_fg
查看进程 回忆上次内容 上次先进程查询 ps -elf 查看所有进程信息 ps -lf 查看本终端相关进程信息 杀死进程 kill -9 PID 给进程发送死亡信号 运行多个 python3 sh ...