Numpy计算近邻表时间对比
技术背景
所谓的近邻表求解,就是给定N个原子的体系,找出满足cutoff要求的每一对原子。在前面的几篇博客中,我们分别介绍过CUDA近邻表计算与JAX-MD关于格点法求解近邻表的实现。虽然我们从理论上可以知道,用格点法求解近邻表,在复杂度上肯定是要优于传统的算法。本文主要从Python代码的实现上来具体测试一下二者的速度差异,这里使用的硬件还是CPU。
算法解析
若一对原子A和B满足下述条件,则称A、B为一对近邻原子:
\]
传统的求解方法,就是把所有原子间距都计算一遍,然后对每个原子的近邻原子进行排序,最终按照给定的cutoff截断值确定相关的近邻原子。在Python中的实现,因为有numpy这样的强力工具,我们在计算原子两两间距时,只需要对一组维度为(N,D)的原子坐标进行扩维,分别变成(1,N,D)和(N,1,D)大小的原子坐标。然后将二者相减,计算过程中会自动广播(Broadcast)成(N,N,D)和(N,N,D)的两个数组进行计算。对得到的结果做一个Norm,就可以得到维度为(N,N)的两两间距矩阵。该算法的计算复杂度为O(N^2)。
相对高效的一种求解方案是将原子坐标所在的空间划分成众多的小区域,通常我们设定这些小区域为边长等于cutoff的小正方体。这种设定有一个好处是,我们可以确定每一个正方体的近邻原子,一定在最靠近其周边的26个小正方体区域内。这样一来,我们就不需要去计算全局的两两间距,只需要计算单个小正方体内(假定有M个原子)的两两间距(M,M),以及单个正方体与周边正方体内原子的配对间距(M,26M)。之所以这样分开计算,是为了减少原子跟自身间距的这一项重复计算。那么对于整个空间的原子,就需要计算(N,27M)这么多次的原子间距,是一个复杂度为O(NlogN)的算法。
Numpy代码实现
这里我们基于Python中的numpy框架来实现这两个不同的计算近邻表的算法。其实当我们使用numpy来进行计算的时候,应当尽可能的避免循环体的使用。但是这里仅演示两种算法的差异性,因此在实现格点法的时候偷了点懒,用了两个for循环,感兴趣的童鞋可以自行优化。
import time
from itertools import chain
from operator import itemgetter
import numpy as np
# 在格点法中,为了避免重复计算,我们可以仅计算一半的近邻格点中的原子间距
NEIGHBOUR_GRID = np.array([
[-1, 1, 0],
[-1, -1, 1],
[-1, 0, 1],
[-1, 1, 1],
[ 0, -1, 1],
[ 0, 0, 1],
[ 0, 1, 0],
[ 0, 1, 1],
[ 1, -1, 1],
[ 1, 0, 0],
[ 1, 0, 1],
[ 1, 1, 0],
[ 1, 1, 1]], np.int32)
# 原始的两两间距计算方法,需要排序
def get_neighbours_by_dist(crd, cutoff):
large_dis = np.tril(np.ones((crd.shape[0], crd.shape[0])) * 999)
# (N, N)
dis = np.linalg.norm(crd[None] - crd[:, None], axis=-1) + large_dis
# (N, M)
neigh = np.argsort(dis, axis=-1)
# (N, M)
cut = np.take_along_axis(dis, neigh, axis=1)
# (2, P)
pairs = np.where(cut <= cutoff)
# (P, )
pairs_id0 = pairs[0]
pairs_id1 = neigh[pairs]
# (P, 2)
sort_args = np.argsort(pairs_id0)
return np.hstack((pairs_id0[..., None], pairs_id1[..., None]))[sort_args]
# 格点法计算近邻表,先分格点,然后分两个模块计算单格点内原子间距,和中心格点-周边格点内的原子间距
def get_neighbours_by_grid(crd, cutoff):
# (D, )
min_xyz = np.min(crd, axis=0)
max_xyz = np.max(crd, axis=0)
space = max_xyz - min_xyz
grids = np.ceil(space / cutoff).astype(np.int32)
num_grids = np.product(grids)
buffer = (grids * cutoff - space) / 2
start_crd = min_xyz - buffer
# (N, D)
grid_id = ((crd - start_crd) // cutoff).astype(np.int32)
grid_coe = np.array([1, grids[0], grids[1]], np.int32)
# (N, )
grid_id_1d = np.sum(grid_id * grid_coe, axis=-1).astype(np.int32)
# (N, 2)
grid_id_dict = np.ndenumerate(grid_id_1d)
# (G, *)
grid_dict = dict.fromkeys(range(num_grids), ())
for index, value in grid_id_dict:
grid_dict[value] += index
neighbour_grid = (NEIGHBOUR_GRID * grid_coe).sum(axis=-1).astype(np.int32)
neighbour_pairs = []
for i in range(num_grids):
if grid_dict[i]:
keeps = np.where((neighbour_grid + i < num_grids) & (neighbour_grid + i >= 0))[0]
neighbour_grid_keep = neighbour_grid[keeps] + i
grid_atoms = np.array(list(grid_dict[i]), np.int32)
try:
grid_neighbours = np.array(list(chain(*itemgetter(*neighbour_grid_keep)(grid_dict))), np.int32)
except TypeError:
if neighbour_grid_keep.size == 0:
grid_neighbours = np.array([], np.int32)
else:
grid_neighbours = np.array(list(itemgetter(*neighbour_grid_keep)(grid_dict)), np.int32)
grid_crds = crd[grid_atoms]
grid_neighbour_crds = crd[grid_neighbours]
large_dis = np.tril(np.ones((grid_crds.shape[0], grid_crds.shape[0])) * 999)
# 单格点内部原子间距
grid_dis = np.linalg.norm(grid_crds[None] - grid_crds[:, None], axis=-1) + large_dis
grid_pairs = np.argsort(grid_dis, axis=-1)
grid_cut = np.take_along_axis(grid_dis, grid_pairs, axis=-1)
pairs = np.where(grid_cut <= cutoff)
pairs_id0 = grid_atoms[pairs[0]]
pairs_id1 = grid_atoms[grid_pairs[pairs]]
neighbour_pairs.extend(list(np.hstack((pairs_id0[..., None], pairs_id1[..., None]))))
# 中心格点-周边格点内原子间距
grid_dis = np.linalg.norm(grid_crds[:, None] - grid_neighbour_crds[None], axis=-1)
grid_pairs = np.argsort(grid_dis, axis=-1)
grid_cut = np.take_along_axis(grid_dis, grid_pairs, axis=-1)
pairs = np.where(grid_cut <= cutoff)
pairs_id0 = grid_atoms[pairs[0]]
pairs_id1 = grid_neighbours[grid_pairs[pairs]]
neighbour_pairs.extend(list(np.hstack((pairs_id0[..., None], pairs_id1[..., None]))))
neighbour_pairs = np.sort(np.array(neighbour_pairs), axis=-1)
sort_args = np.argsort(neighbour_pairs[:, 0])
return neighbour_pairs[sort_args]
# 时间测算函数
def benchmark(N, cutoff=0.3, D=3):
crd = np.random.random((N, D)).astype(np.float32) * np.array([3., 4., 5.], np.float32)
# Solution 1
time0 = time.time()
neighbours_1 = get_neighbours_by_dist(crd, cutoff)
time1 = time.time()
record_1 = time1 - time0
# Solution 2
time0 = time.time()
neighbours_2 = get_neighbours_by_grid(crd, cutoff)
time1 = time.time()
record_2 = time1 - time0
for pair in neighbours_1:
if (np.isin(neighbours_2, pair).sum(axis=-1) < 2).all():
print (pair)
assert neighbours_1.shape == neighbours_2.shape
return record_1, record_2
# 绘图主函数
if __name__ == '__main__':
import matplotlib.pyplot as plt
sizes = range(1000, 10000, 1000)
time_dis = []
time_grid = []
for size in sizes:
print (size)
times = benchmark(size)
time_dis.append(times[0])
time_grid.append(times[1])
plt.figure()
plt.title('Neighbour List Calculation Time')
plt.plot(sizes, time_dis, color='black', label='Full Connect')
plt.plot(sizes, time_grid, color='blue', label='Cell List')
plt.xlabel('Size')
plt.ylabel('Time/s')
plt.legend()
plt.grid()
plt.show()
上述代码的运行结果如下图所示:
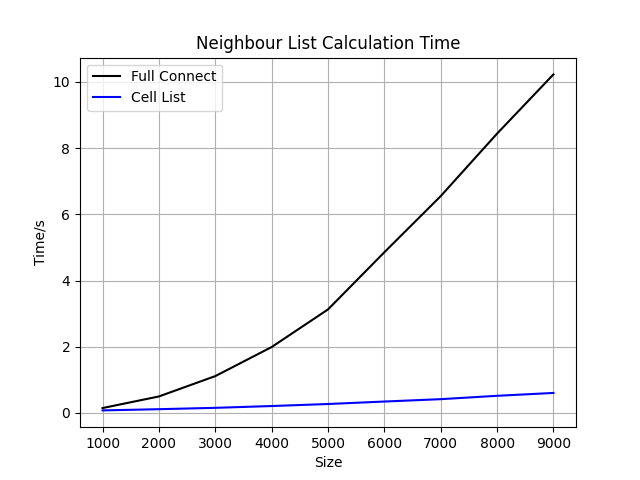
其实因为格点法中使用了for循环的问题,函数效率并不高。因此在体系非常小的场景下(比如只有几十个原子的体系),本文用到的格点法代码效率并不如计算所有的原子两两间距。但是毕竟格点法的复杂度较低,因此在运行过程中随着体系的增长,格点法的优势也越来越大。
近邻表计算与分子动力学模拟
在分子动力学模拟中计算长程相互作用时,会经常使用到近邻表。如果要在GPU上实现格点近邻算法,有可能会遇到这样的一些问题:
- GPU更加擅长处理静态Shape的张量,因此往往会使用一个
最大近邻数,对每一个原子的近邻原子标号进行限制,一般不允许满足cutoff的近邻原子数超过最大近邻数,否则这个cutoff就失去意义了。而如果单个原子的近邻原子数量低于最大近邻数,这时候就会用一个没有意义的数对剩下分配好的张量空间进行填充(Padding),这样一来会带来很多不必要的计算。 - 在运行分子动力学模拟的过程中,体系原子的坐标在不断的变化,近邻表也会随之变化,而此时的最大近邻数有可能无法存储完整的cutoff内的原子。
总结概要
本文介绍了在Python的numpy框架下计算近邻表的两种不同算法的原理以及复杂度,另有分别对应的两种代码实现。在实际使用中,我们更偏向于第二种算法的使用。因为对于第一种算法来说,哪怕是一个10000个原子的小体系,如果要计算两两间距,也会变成10000*10000这么大的一个张量的运算。可想而知,这样计算的效率肯定是比较低下的。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/cell-list.html
作者ID:DechinPhy
更多原著文章:https://www.cnblogs.com/dechinphy/
请博主喝咖啡:https://www.cnblogs.com/dechinphy/gallery/image/379634.html
Numpy计算近邻表时间对比的更多相关文章
- JAX-MD在近邻表的计算中,使用了什么奇技淫巧?(一)
技术背景 JAX-MD是一款基于JAX的纯Python高性能分子动力学模拟软件,应该说在纯Python的软件中很难超越其性能.当然,比一部分直接基于CUDA的分子动力学模拟软件性能还是有些差距.而在计 ...
- Python的GPU编程实例——近邻表计算
技术背景 GPU加速是现代工业各种场景中非常常用的一种技术,这得益于GPU计算的高度并行化.在Python中存在有多种GPU并行优化的解决方案,包括之前的博客中提到的cupy.pycuda和numba ...
- select … into outfile 备份恢复(load data)以及mysqldump时间对比
select … into outfile 'path' 备份 此种方式恢复速度非常快,比insert的插入速度要快的多,他跟有备份功能丰富的mysqldump不同的是,他只能备份表中的数据,并不能包 ...
- numpy计算数组中满足条件的个数
Numpy计算数组中满足条件元素个数 需求:有一个非常大的数组比如1亿个数字,求出里面数字小于5000的数字数目 1. 使用numpy的random模块生成1亿个数字 2. 使用Python原生语法实 ...
- mysql对比表结构对比同步,sqlyog架构同步工具
mysql对比表结构对比同步,sqlyog架构同步工具 对比后的结果示例: 执行后的结果示例: 点击:"另存为(S)" 按钮可以把更新sql导出来.
- C#计算两个时间年份月份差
C#计算两个时间年份月份差 https://blog.csdn.net/u011127019/article/details/79142612
- python init 方法 与 sql语句当前时间对比
def init(self,cr): tools.sql.drop_view_if_exists(cr, 'custrom_product_infomation_report') cr.execute ...
- 计算2个时间之间经过多少Ticks
Ticks是一个周期,存储的是一百纳秒,换算为秒,一千万分之一秒.我们需要计算2个时间之间,经过多少Ticks,可以使用下面的方法来实现,使用2个时间相减. 得到结果为正数,是使用较晚的时间减去较早的 ...
- C# 计算传入的时间距离今天的时间差
/// <summary> /// 计算传入的时间距离今天的时间差 /// </summary> /// <param name="dt">&l ...
- numpy计算路线距离
numpy计算路线距离 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 enumerate遍历数组 np.diff函数 numpy适用数组作为索引 标记路线上的点 \[X={X1,X ...
随机推荐
- IDEA2019 Debug傻瓜式上手教程
Step Into (F7):步入,如果当前行有方法,可以进入方法内部,一般用于进入自定义方法内,不会进入官方类库的方法. Force Step Into (Alt + Shift + F7) ...
- 前端三件套系例之CSS——响应式布局
文章目录 1.什么是响应式设计 1-1 定义 1-2 响应式设计的优势 2.屏幕的相关概念 3.viewport 视口 3-1 什么是viewport 3-2 设置viewport 4.媒体查询 @m ...
- Python经典编程题40题(二)
Python经典编程题40题(二) 题目 给你一个list L, 如 L=[2,8,3,50], 对L进行降序排序并输出, 如样例L的结果为[50,8,3,2] 输入示例 输入:L = [4, ...
- CF862B
题目简化和分析: 这是一道较为经典的二分图染色题. 二分图的基本概念 但这题让我们求得是完全二分图. 什么是完全二分图 \(cnt_{1}\) 表示染成颜色种类为 \(1\) 的个数. \(cnt_{ ...
- for遍历
for遍历 一:常规方式 1.遍历数组 int arr[10] = {1,2,3,4,5,6,7,8,9,10}; for(int i = 0;i<10;i++) { cout<<a ...
- 如何优雅重启 kubernetes 的 Pod
最近在升级服务网格 Istio,升级后有个必要的流程就是需要重启数据面的所有的 Pod,也就是业务的 Pod,这样才能将这些 Pod 的 sidecar 更新为新版本. 方案 1 因为我们不同环境的 ...
- RSA总结 From La神
常用工具 分解大素数 factordb (http://www.factordb.com / API: http://factordb.com/api?query=) yafu (p q 相差过大或过 ...
- coco漫画获取隐藏的图片链接
网站分析 打开目标网站:https://www.cocomanhua.com/, 随便打开一部漫画: https://www.cocomanhua.com/10330/1/205.html F12 打 ...
- SNN_文献阅读_Text Classification in Memristor-based Spiking Neural Networks
SNN中局部学习和非局部学习,基于梯度的规则都需要对用于表示单个连续值的脉冲训练窗口上的累积误差进行平均,这种方法在更新权重时考虑了每一个脉冲的影响.在计算速度和空间效率等方面,特别是当代表单个数值的 ...
- C语言一个单链表L=(a1 , a2 , … , an-1 , an),其逆单链表定义为L’=( an , an-1 , … , a2 , a1),要求逆单链表仍占用原单链表的空间。
/* 开发者:慢蜗牛 开发时间:2020.6.11 程序功能:顺序输出和逆序输出 */ #include<stdio.h> #include<malloc.h> #define ...