字节跳动基于 Apache Hudi 的多流拼接实践方案
字节跳动数据湖团队在实时数仓构建宽表的业务场景中,探索实践出的一种基于 Hudi Payload 的合并机制提出的全新解决方案。
字节跳动数据湖团队在实时数仓构建宽表的业务场景中,探索实践出的一种基于 Hudi Payload 的合并机制提出的全新解决方案。
该方案在存储层提供对多流数据的关联能力,旨在解决实时场景下多流 JOIN 遇到的一系列问题。接下来,本文会详细介绍多流拼接方案的背景以及实践经验。
业务面临的挑战
字节跳动存在较多业务场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。
业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:
- 维表 JOIN
场景挑战:指标数据与维度数据进行关联,其中维度数据量比较大,指标数据 QPS 比较高,导致数据可能会产出延迟。
当前方案:将部分维度数据缓存起起来,缓解高 QPS 下访问维度数据存储引擎产生的任务背压问题。
存在问题:由于业务方的维度数据和指标数据时间差比较大,所以指标数据流无法设置合理的 TTL;而且存在 Cache 中维度数据没有及时更新,导致下游数据不准确的问题。
- 多流 JOIN
- 场景挑战:多个指标数据进行关联,不同指标数据可能会出现时间差比较大的异常情况。
- 当前方案:使用基于窗口的 JOIN,并且维持一个比较大的状态。
- 存在问题:维持大的状态不仅会给内存带来的一定的压力,同时 Checkpoint 和 Restore 的时间会变 得更长,可能会导致任务背压.
分析与对策
总结上述场景遇到的挑战,主要可归结为以下两点:
- 由于多流之间时间差比较大,需要维持大状态,同时 TTL 不好设置。
- 由于对维度数据做了 Cache,维度数据数据更新不及时,导致下游数据不准确。
针对这些问题,并结合业务场景对数据延迟有一定容忍,但对数据准确性要求比较高的背景,我们在不断的实践中探索出了基于 Hudi Payload 机制的多流拼接方案:
- 多流数据完全在存储层进行拼接,与计算引擎无关,因此不需要保留状态及其 TTL 的设置。
- 维度数据和指标数据作为不同的流独立更新,更新过程中不需要做多流数据合并,下游读取时再 Merge 多流数据,因此不需要缓存维度数据,同时可以在执行 Compact 时进行 Merge,加速下游查询。
此外,多流拼接方案还支持:
- 内置通用模板,支持数据去重等通用接口,同时可满足用户定制化数据处理需求。
- 支持离线场景和流批混合场景。
方案介绍
基本概念
首先简单介绍下本方案依赖 Hudi 的一些核心概念:
- Hudi MetaStore
这是一个中心化的数据湖元数据管理系统。它基于 Timeline 乐观锁实现并发写控制,可以支持列级别的冲突检查。这在 Hudi 多流拼接方案中能够实现并发写入至关重要,更多细节可参考字节跳动数据湖团队向社区贡献的 RFC-36。
- MergeOnRead 表读写逻辑
MergeOnRead 表里面的文件包含两种, LogFile (行存) 和 BaseFile (列存),适用于实时高频更新场景,更新数据会直接写入 LogFile 中,读时再进行合并。为了减少读放大的问题,会定期合并 LogFile 到 BaseFile 中,此过程叫 Compact。
原理概述
针对上述业务场景,我们设计了一种完全基于存储层的多流拼接方案,支持多个数据流并发写入,读时按照主键合并多流数据,此外还支持异步 Compact 来加速下游读取数据。
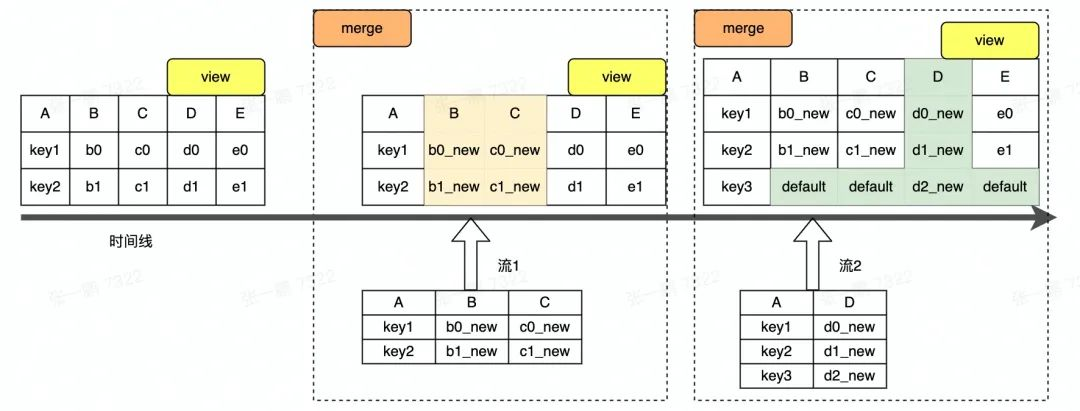
图 1 Hudi 多流拼接概念图(本文所有图中示例数据均与图 1 一致)
现以一个简单的示例流程对方案原理进行阐述,图 1 为多流拼接示意图。图中的宽表包含 BCDE 五列,是由两个实时流和一个离线流拼接而成,其中 A 是主键列,实时流 1 负责写入 ABC 三列,实时 流 2 负责写入 AD 两列,离线流负责写入 AE 两列,此处仅对两个实时流的拼接过程进行介绍。
图 1 中显示两个流写入数据以 LogFile 形式存储,Merge 过程是合并 LogFile 和 BaseFile 中的数据。合并过程中,LogFile 中每一列的值被更新到 BaseFile 中对应的列上,BaseFile 中未被更新的列保持原来的值不变,如图 1 中 BCD 三列被更新成新值,E 列保持旧值不变。
写入过程
多流数据拼接方案支持多流并发写入,相互独立。对于单个流的写入,逻辑与 Hudi 原有写入流程一致,即数据以 Upsert 的方式写入 Hudi 表,以 LogFile 的形式存储,并在数据写入的过程中对数据去重。在多流写入的场景,核心点在于如何处理并发问题。
图 2 显示了数据并发写入的流程。流 1 和 流 2 是两个并发的任务,检查这两个任务写入的列除了主键以外是不是存在其它交集。例如:
流 1 的 Schema 包含三列 (A,B,C),流 2 的 Schema 包含两列 (A,D)。
在并发写入的时候,先在 Hudi MetaStore 对两个任务发起的 DeltaCommit 做列冲突检查,即除了主键列外的其它列是否存在交集,如图中的 (B,C) 和 (D):
- 如果有交集,则后发起的 DeltaCommit 失败。
- 如果没有交集,则两个任务继续后续的写入。
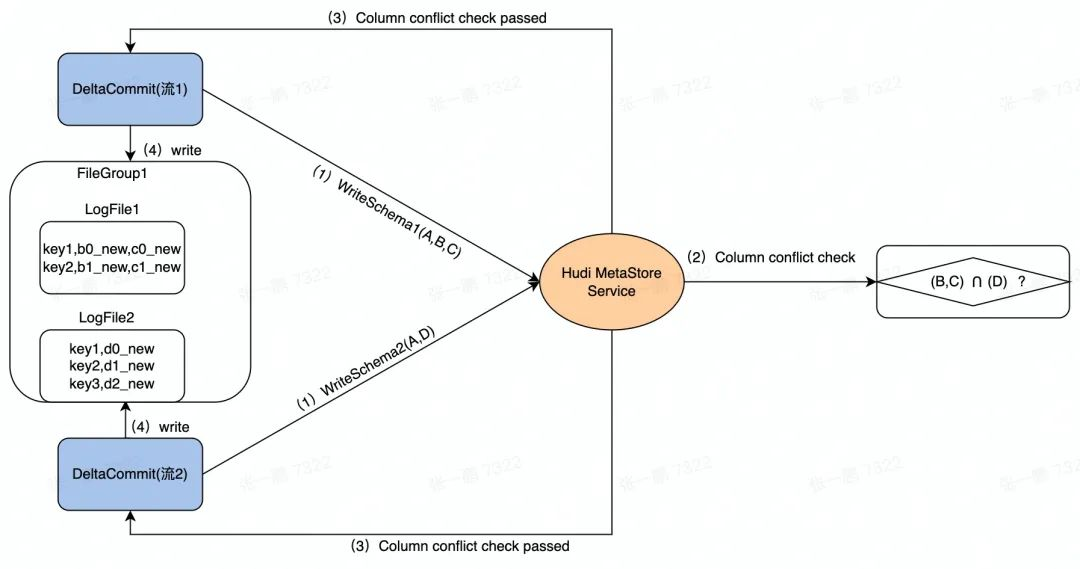
图 2 数据写入过程示意图
读取过程
接下来,介绍多流拼接场景下 Snapshot Query 的核心过程,即先对 LogFile 进行去重合并,然后再合并 BaseFile 和 去重后的 LogFile 中的数据。图 3 显示了整个数据合并的过程,具体可以拆分成以下 两个过程:
- Merge LogFile
Hudi 现有逻辑是将 LogFile 中的数据读出来存放在 Map 中,对于 LogFile 中每条 Record,如果 Key 不存在 Map 中,则直接放入 Map,如果 Key 已经存在于 Map 中,则需要更新操作。
在多流拼接中,因为 LogFile 中存在不同数据流写入的数据,即每条数据的列可能不相同,所以在更新的时候需要判断相同 Key 的两个 Record 是否来自同一个流,是则做更新,不是则做拼接。
如图 3 所示,读到 LogFile2 中的主键是 key1 的 Record 时,key1 对应的 Record 在 Map 中已经存在,但这两个 Record 来自不同流,则需要拼接形成一条新的 Record (key1,b0_new,c0_new,d0_new) 放入 Map 中。
- Merge BaseFile and LogFile
Hudi 现有默认逻辑是对于每一条存在于 BaseFile 中的 Record,查看 Map 中是否存在 key 相同的 Record,如果存在,则用 Map 中的 Record 覆盖 BaseFile 中的 Record。在多流拼接中,Map 中的 Record 不会完整覆盖 BaseFile 中对应的 Record,可能只会更新部分列的值,即 Map 中的 Record 对应的列。
如图 3 所示,以最简单的覆盖逻辑为例,当读到 BaseFile 中的主键是 key1 的 Record 时,发现 key1 在 Map 中已经存在并且对应的 Record 有 BCD 三列的值,则更新 BaseFile 中的 BCD 列,得到新的 Record(key1,b0_new,c0_new,d0_new,e0),注意 E 列没有被更新,所以保持原来的值 e0。
对于新增的 Key 如 Key3 对应的 Record,则需要将 BCE 三列补上默认值形成一条完整的 Record。
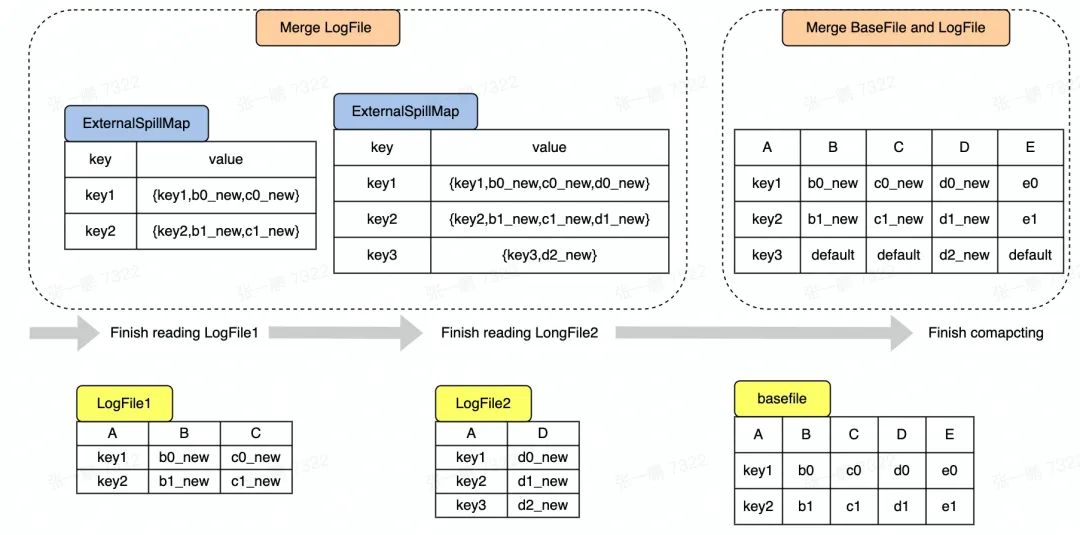
图3 SnapShot Query 中数据合并过程
异步 Compaction
为了提升读取性能,某些数据源的写入任务会同步执行 Compaction,但实践过程中发现同步执行 Compaction 会阻塞写入任务,而且 Compaction 任务需要资源比较多,可能会抢占流式导入任务的资源。
针对这类场景,通过独立的 Compaction Service 来隔离 Compaction 任务和流式数据导入任务。与 Hudi 本身自带的异步 Compaction 不同的是,用户无需指定要执行的 Compaction Instant,且有一个独立的 Compaction Service 负责所有的表的 Compaction 操作。关于 Compaction Service 的细节就不在本文展开,详情可参考 RFC-43。
具体过程是流式导入任务同步生成 Schedule Compaction Plan,并将 Plan 存入 Hudi MetaStore。有一个独立于流式导入任务的 Async Compactor,它从 Hudi MetaStore 循环拉取 Compaction Plan 并执行。
场景实践与未来规划
最终,基于 Hudi 多流拼接的方案,在实时数仓的 DWS 层落地,单表支持了 3+ 数据流的并发导入,覆盖了数百 TB 的数据。
此外,在使用 Spark 对宽表数据进行查询时,在单次扫描量几十 TB 的查询中,性能相比于直接使用多表关联性能提升在 200% 以上,在一些更加复杂的查询下,也有 40-140% 的性能提升。
目前,基于 Hudi 多流拼接方案易用性不足,单个任务至少需要配置超过 10 个参数,为了进一步降低用户使用成本,后续会做部分列插入和更新的 SQL 的语法支持以及参数的收敛。
除此之外,为了进一步提升宽表数据查询性能,还计划在多流拼接场景下支持基于列存格式的 LogFile,提供列裁剪和过滤条件下推等功能。
数据湖团队正在招人,
欢迎关注字节跳动数据平台同名公众号
相关产品
- 火山引擎湖仓一体分析服务 LAS
面向湖仓一体架构的Serverless数据处理分析服务,提供一站式的海量数据存储计算和交互分析能力,完全兼容 Spark、Presto、Flink 生态,帮助企业轻松完成数据价值洞察。点击了解
- 火山引擎E-MapReduce
支持构建开源 Hadoop 生态的企业级大数据分析系统,完全兼容开源,提供 Hadoop、Spark、Hive、Flink 集成和管理,帮助用户轻松完成企业大数据平台的构建,降低运维门槛,快速形成大数据分析能力。点击了解
字节跳动基于 Apache Hudi 的多流拼接实践方案的更多相关文章
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
背景 湖仓一体(LakeHouse)是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素,是当下大数据领域的重要发展方向. 华为云早在2020年就开始着手相关技术的预研,并落地在华为云 Fusio ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- OnZoom 基于Apache Hudi的流批一体架构实践
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创 ...
- 基于 Apache Hudi 构建增量和无限回放事件流的 OLAP 平台
1. 摘要 在本博客中,我们将讨论在构建流数据平台时如何利用 Hudi 的两个最令人难以置信的能力. 增量消费--每 30 分钟处理一次数据,并在我们的组织内构建每小时级别的OLAP平台 事件流的无限 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
随机推荐
- moment日期处理类库
Moment 被设计为在浏览器和 Node.js 中都能工作. 安装 npm install moment --save # npm yarn add moment # Yarn 使用 /** * F ...
- QT中级(2)QTableView自定义委托(二)实现QProgressBar委托
同系列文章 QT中级(1)QTableView自定义委托(一)实现QSpinBox.QDoubleSpinBox委托 QT中级(2)QTableView自定义委托(二)实现QProgressBar委托 ...
- html5学习内容-6(flex)
弹性布局–flex (一)视口单位主要包括以下4个: vw:1vw等于视口宽度的1% vh:1vh等于视口高度的1% vmin:选取vm和vh中最小的那个 vmax:选取vm和vh中最大的那个 常用于 ...
- @ApiImplicitParam dataType属性失效
最近在弄swagger,老是碰到注解属性失效问题.百度看了一大推,都是说什么版本问题.但是都不是我遇到的情况,下面直接上我遇到的问题及答案 可以看到,我直接用Integer,或者int,去到swa ...
- Langchain-Chatchat项目:4.1-P-Tuning v2实现过程
常见参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)有哪些呢?主要是Prompt系列和LoRA系列.本文主要介绍P-Tuning v2微调方法.如下所示 ...
- eclipse安装velocity插件(转)
http://www.jspxcms.com/knowledge/46.html http://blog.csdn.net/superbeck/article/details/5721382 插件地址 ...
- Mybatis和其他主流框架的整合使用
Mybatis简介 MyBatis历史 MyBatis最初是Apache的一个开源项目iBatis, 2010年6月这个项目由Apache Software Foundation迁移到了Google ...
- 动态规划——提高Ⅴ(DP优化)
单调队列优化DP 其实单调队列就是一种队列内的元素有单调性(单调递增或者单调递减)的队列,答案(也就是最优解)就存在队首,而队尾则是最后进队的元素.因为其单调性所以经常会被用来维护区间最值或者降低DP ...
- 文心一言 VS 讯飞星火 VS chatgpt (145)-- 算法导论12.1 5题
五.用go语言,因为在基于比较的排序模型中,完成n个元素的排序,其最坏情况下需要 Ω(nlgn) 时间.试证明:任何基于比较的算法从 n 个元素的任意序列中构造一棵二又搜索树,其最坏情况下需要 Ω(n ...
- H5自适应
一.设置html的font-size,使用rem作为单位 假设设计稿宽度750px,屏幕宽高750px, 1.1rem=屏幕宽度/设计稿宽度*100px,适合用px表示宽度 1rem=100px re ...