在深度学习的视觉VISION领域数据预处理的魔法常数magic constant、黄金数值的复现: mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]
代码:
https://gist.github.com/pmeier/f5e05285cd5987027a98854a5d155e27
import argparse
import multiprocessing
from math import ceil
import torch
from torch.utils import data
from torchvision import datasets, transforms class FiniteRandomSampler(data.Sampler):
def __init__(self, data_source, num_samples):
super().__init__(data_source)
self.data_source = data_source
self.num_samples = num_samples def __iter__(self):
return iter(torch.randperm(len(self.data_source)).tolist()[: self.num_samples]) def __len__(self):
return self.num_samples class RunningAverage:
def __init__(self, num_channels=3, **meta):
self.num_channels = num_channels
self.avg = torch.zeros(num_channels, **meta) self.num_samples = 0 def update(self, vals):
batch_size, num_channels = vals.size() if num_channels != self.num_channels:
raise RuntimeError updated_num_samples = self.num_samples + batch_size
correction_factor = self.num_samples / updated_num_samples updated_avg = self.avg * correction_factor
updated_avg += torch.sum(vals, dim=0) / updated_num_samples self.avg = updated_avg
self.num_samples = updated_num_samples def tolist(self):
return self.avg.detach().cpu().tolist() def __str__(self):
return "[" + ", ".join([f"{val:.3f}" for val in self.tolist()]) + "]" def make_reproducible(seed):
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False def main(args):
if args.seed is not None:
make_reproducible(args.seed) transform = transforms.Compose(
[transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()]
)
dataset = datasets.ImageNet(args.root, split="train", transform=transform) num_samples = args.num_samples
if num_samples is None:
num_samples = len(dataset)
if num_samples < len(dataset):
sampler = FiniteRandomSampler(dataset, num_samples)
else:
sampler = data.SequentialSampler(dataset) loader = data.DataLoader(
dataset,
sampler=sampler,
num_workers=args.num_workers,
batch_size=args.batch_size,
) running_mean = RunningAverage(device=args.device)
running_std = RunningAverage(device=args.device)
num_batches = ceil(num_samples / args.batch_size) with torch.no_grad():
for batch, (images, _) in enumerate(loader, 1):
images = images.to(args.device)
images_flat = torch.flatten(images, 2) mean = torch.mean(images_flat, dim=2)
running_mean.update(mean) std = torch.std(images_flat, dim=2)
running_std.update(std) if not args.quiet and batch % args.print_freq == 0:
print(
(
f"[{batch:6d}/{num_batches}] "
f"mean={running_mean}, std={running_std}"
)
) print(f"mean={running_mean}, std={running_std}") return running_mean.tolist(), running_std.tolist() def parse_input():
parser = argparse.ArgumentParser(
description="Calculation of ImageNet z-score parameters"
)
parser.add_argument("root", help="path to ImageNet dataset root directory")
parser.add_argument(
"--num-samples",
metavar="N",
type=int,
default=None,
help="Number of images used in the calculation. Defaults to the complete dataset.",
)
parser.add_argument(
"--num-workers",
metavar="N",
type=int,
default=None,
help="Number of workers for the image loading. Defaults to the number of CPUs.",
)
parser.add_argument(
"--batch-size",
metavar="N",
type=int,
default=None,
help="Number of images processed in parallel. Defaults to the number of workers",
)
parser.add_argument(
"--device",
metavar="DEV",
type=str,
default=None,
help="Device to use for processing. Defaults to CUDA if available.",
)
parser.add_argument(
"--seed",
metavar="S",
type=int,
default=None,
help="If given, runs the calculation in deterministic mode with manual seed S.",
)
parser.add_argument(
"--print_freq",
metavar="F",
type=int,
default=50,
help="Frequency with which the intermediate results are printed. Defaults to 50.",
)
parser.add_argument(
"--quiet",
action="store_true",
help="If given, only the final results is printed",
) args = parser.parse_args() if args.num_workers is None:
args.num_workers = multiprocessing.cpu_count() if args.batch_size is None:
args.batch_size = args.num_workers if args.device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
args.device = torch.device(device) return args if __name__ == "__main__":
args = parse_input()
main(args)
命名为文件:
imagenet_normalization.py
下载好数据集:

官方给出的运行命令及结果:
Fortunately, varying the num_samples with seed=0 (python imagenet_normalization.py $IMAGENET_ROOT --num-samples N --seed 0)
num_samples |
mean |
std |
|---|---|---|
1000 |
[0.483, 0.454, 0.401] |
[0.226, 0.223, 0.222] |
2000 |
[0.482, 0.451, 0.396] |
[0.225, 0.222, 0.221] |
5000 |
[0.484, 0.454, 0.401] |
[0.225, 0.221, 0.221] |
10000 |
[0.485, 0.454, 0.401] |
[0.225, 0.221, 0.220] |
20000 |
[0.484, 0.453, 0.400] |
[0.224, 0.220, 0.219] |
as well as varying the seed with num_samples=1000 (python imagenet_normalization.py $IMAGENET_ROOT --num-samples 1000 --seed S)
seed |
mean |
std |
|---|---|---|
0 |
[0.483, 0.454, 0.401] |
[0.226, 0.223, 0.222] |
1 |
[0.485, 0.455, 0.402] |
[0.223, 0.218, 0.217] |
27 |
[0.479, 0.449, 0.398] |
[0.225, 0.220, 0.219] |
314 |
[0.480, 0.454, 0.403] |
[0.223, 0.218, 0.217] |
4669 |
[0.490, 0.458, 0.406] |
[0.224, 0.219, 0.219] |
运行命令:



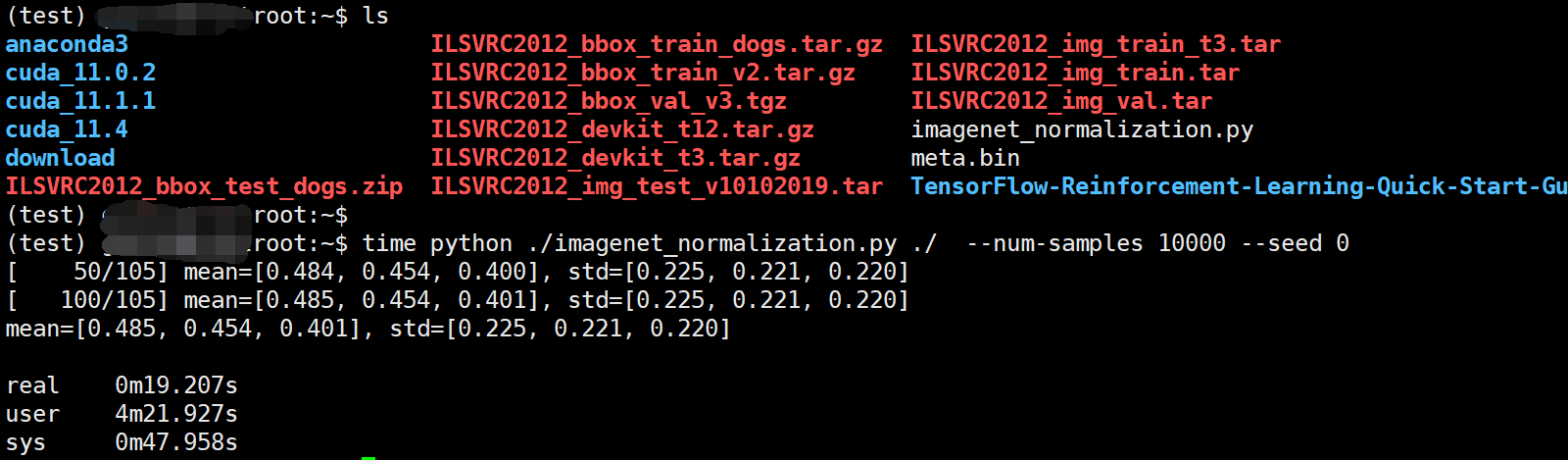
time python ./imagenet_normalization.py ./ --num-samples 10000 --seed 0
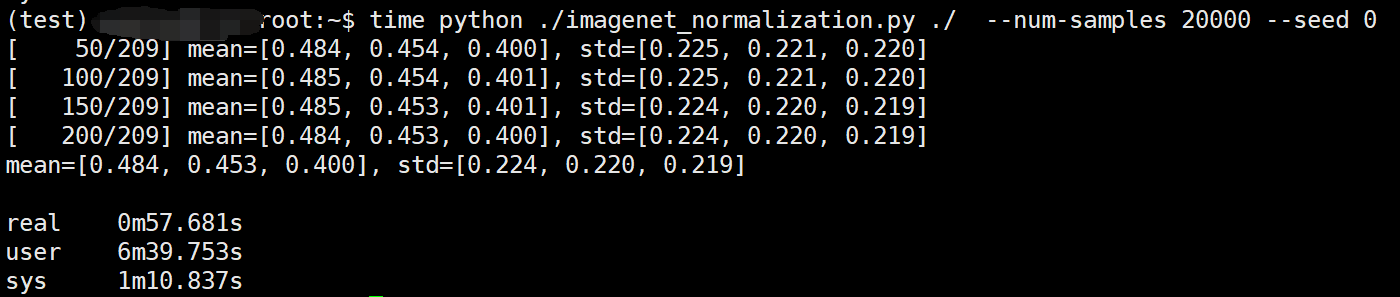
time python ./imagenet_normalization.py ./ --num-samples 20000 --seed 0
===============================================




在深度学习的视觉VISION领域数据预处理的魔法常数magic constant、黄金数值的复现: mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]的更多相关文章
- 【深度学习系列】PaddlePaddle之数据预处理
上篇文章讲了卷积神经网络的基本知识,本来这篇文章准备继续深入讲CNN的相关知识和手写CNN,但是有很多同学跟我发邮件或私信问我关于PaddlePaddle如何读取数据.做数据预处理相关的内容.网上看的 ...
- 深度学习变革视觉计算总结(CCF-GAIR)
孙剑博士分享的是<深度学习变革视觉计算>,分别从视觉智能.计算机摄影学和AI计算三个方面去介绍. 他首先回顾了深度学习发展历史,深度学习发展到今天并不容易,过程中遇到了两个主要障碍: 第一 ...
- sklearn学习笔记(一)——数据预处理 sklearn.preprocessing
https://blog.csdn.net/zhangyang10d/article/details/53418227 数据预处理 sklearn.preprocessing 标准化 (Standar ...
- 深度学习与自动驾驶领域的数据集(KITTI,Oxford,Cityscape,Comma.ai,BDDV,TORCS,Udacity,GTA,CARLA,Carcraft)
http://blog.csdn.net/solomon1558/article/details/70173223 Torontocity HCI middlebury caltech 行人检测数据集 ...
- 【数据分析 R语言实战】学习笔记 第三章 数据预处理 (下)
3.3缺失值处理 R中缺失值以NA表示,判断数据是否存在缺失值的函数有两个,最基本的函数是is.na()它可以应用于向量.数据框等多种对象,返回逻辑值. > attach(data) The f ...
- 【深度学习系列】关于PaddlePaddle的一些避“坑”技巧
最近除了工作以外,业余在参加Paddle的AI比赛,在用Paddle训练的过程中遇到了一些问题,并找到了解决方法,跟大家分享一下: PaddlePaddle的Anaconda的兼容问题 之前我是在服务 ...
- 【深度学习系列】PaddlePaddle垃圾邮件处理实战(二)
PaddlePaddle垃圾邮件处理实战(二) 前文回顾 在上篇文章中我们讲了如何用支持向量机对垃圾邮件进行分类,auc为73.3%,本篇讲继续讲如何用PaddlePaddle实现邮件分类,将深度 ...
- 机器学习&深度学习经典资料汇总,data.gov.uk大量公开数据
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 【AI in 美团】深度学习在文本领域的应用
背景 近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点.而深度学习技术突飞猛进的发展离不开海量数据的积累.计算能力的提升和算法模型的改进. ...
- 搜狗大数据总监、Polarr 联合创始人关于深度学习的分享交流 | 架构师小组交流会
架构师小组交流会是由国内知名公司技术专家参与的技术交流会,每期选择一个时下最热门的技术话题进行实践经验分享.第一期:来自沪江.滴滴.蘑菇街.扇贝架构师的 Docker 实践分享 第二期:来自滴滴.微博 ...
随机推荐
- Angular项目简单使用拦截器 httpClient 请求响应处理
1:为啥要使用拦截器 httpClient 请求响应处理,其作用我们主要是: 目前我的Angular版本是Angular 17.3,版本中实现请求和响应的拦截处理了.这种机制非常适合添加如身份验证头. ...
- 简单的解释下什么是CNAME
今天在用阿里云的安全防护给接口域名做web应用防火墙,需要配置cname,原来有用到过但是一直没去了解过,只知道怎么用今天搜了一下看看下面是原文,白话文好理解分享一下. 什么是CNAME?先简单的说下 ...
- opencv在MAC下的安装
版本信息 MAC版本:10.10.5 Xcode版本:7.2 openCV版本:2.4.13 安装步骤: 联网 安装brew,在终端输入指令 /usr/bin/ruby -e "$(curl ...
- 数据标注工具 doccano | 命名实体识别(Named Entity Recognition,简称NER)
目录 安装 数据准备 创建项目 创建抽取式任务 上传 定义标签 构建抽取式任务标签 任务标注 命名实体识别 导出数据 查看数据 命名实体识别(Named Entity Recognition,简称NE ...
- 背包DP——多重背包
多重背包也是 0-1 背包的一个变式.与 0-1 背包的区别在于每种物品有 k 个,而非一个. 朴素 直接把相同的每个物品视作各个单独的物品,没有关联,仅条件相同: 转换后直接用01背包的状态转移方程 ...
- 缩小50%,Mini版T3/A40i核心板,让您的设备更小巧!
小尺寸核心板给用户带来何种价值? 创龙科技常收到用户对于小尺寸核心板的需求反馈,尤其在电力数据采集器.电力DTU.电力通讯管理机.运动控制器.工业HMI.工业网关等工业设备中. 小尺寸核心板3大优势将 ...
- python3 json.dumps(OrderDict类型) 报错:TypeError: Object of type datetime is not JSON serializable
chatgpt给出的解决方案, 在json.dumps()函数调用中传入default参数来指定如何处理datetime对象 import json from datetime import date ...
- Java集合框架总结图
Collection 接口的接口(对象集合) ├---List 接口:元素都有索引,可以重复,有序(迭代器顺序). │------├ LinkedList 接口实现类, 双向链表, 查询慢,增删快,效 ...
- 创业型公司和BAT大厂招聘要求有什么不同?
背景 很多Java初学都关心这么一个问题,Java学到什么程度以后可以找到第一份工作.大家的目标都很明确,也很实在,学习Java无非就是为了找工作,那到底我要学多少Java知识,才可以找到第一份工作呢 ...
- nodejs-mime类型
mime是一个互联网标准,通过设定它就可以设定文件在浏览器的打开方式. mime使用方法: 使用mime模块查询文件的MIME类型: mime.getType('/path/to/file.txt') ...