【大语言模型基础】-详解Transformer原理
一、Transformer
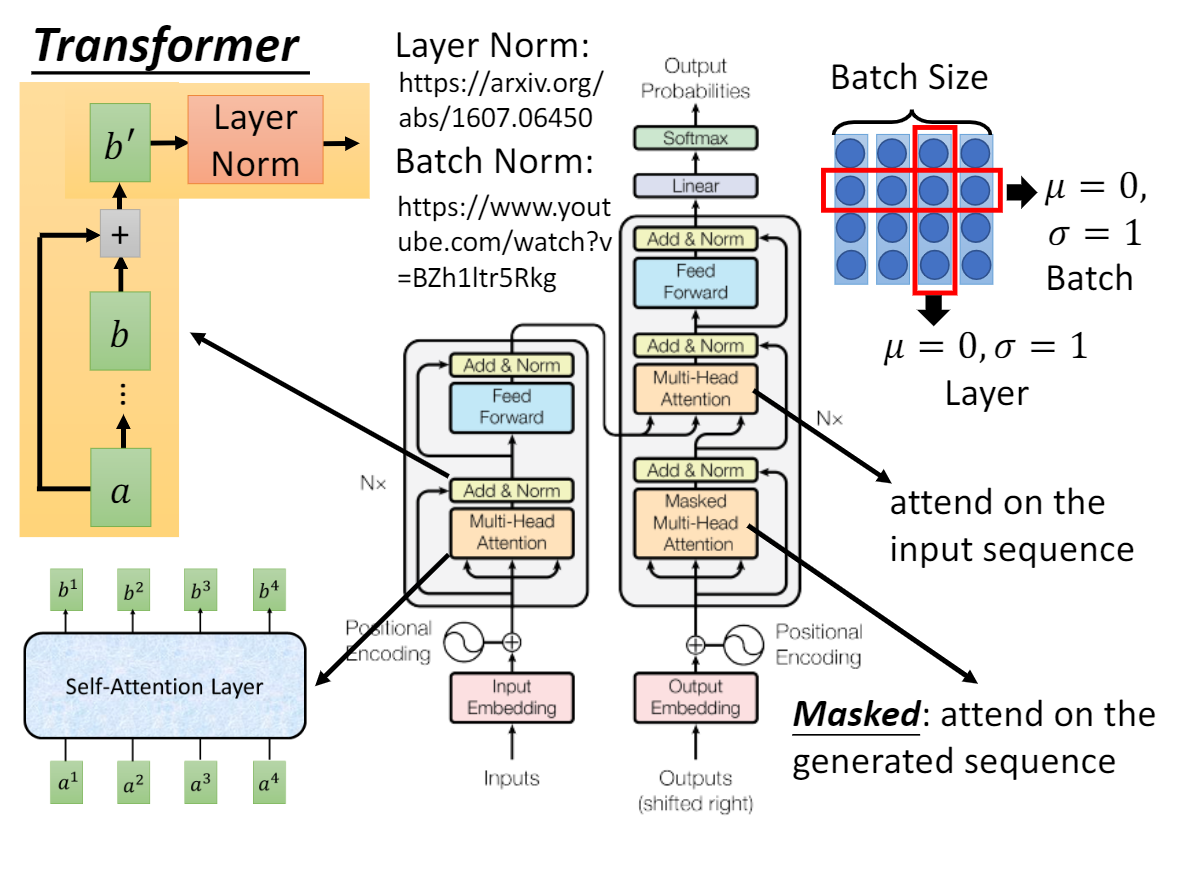
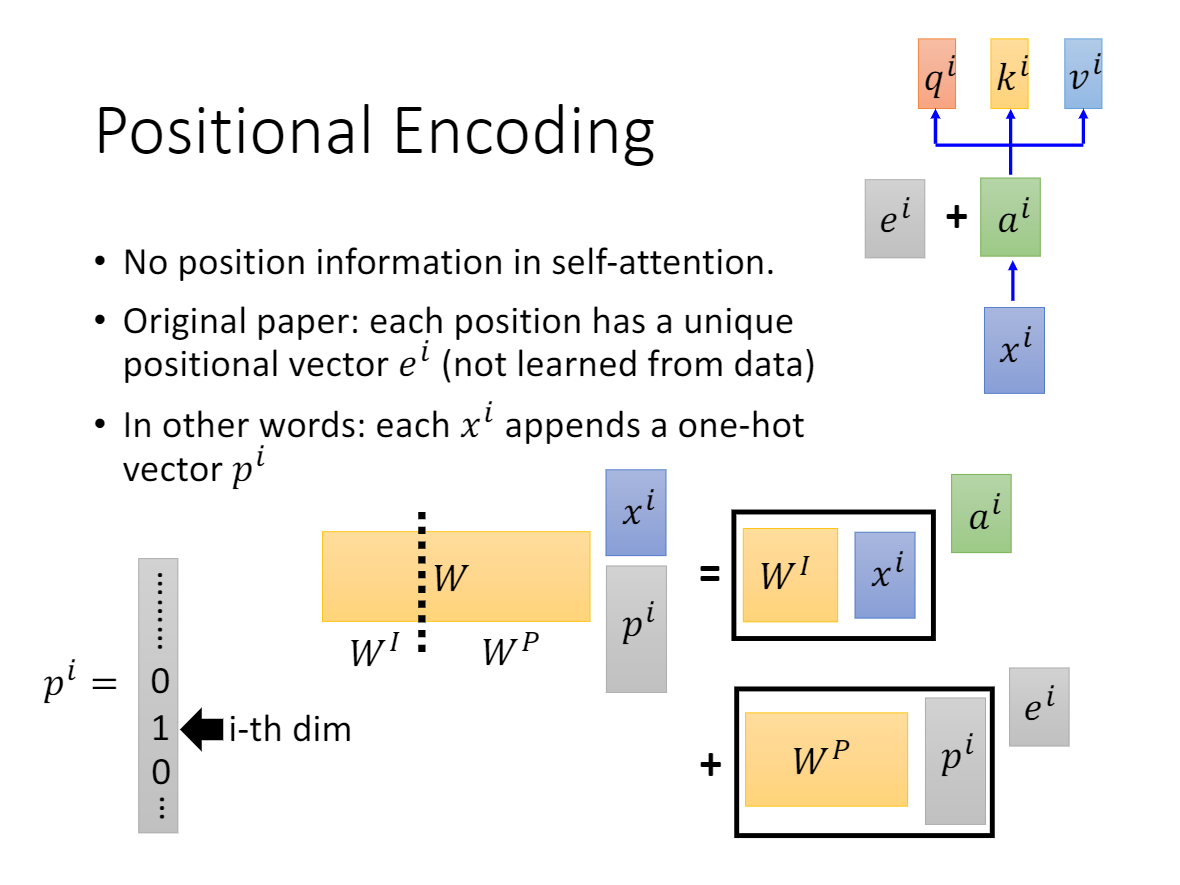
1.1 自注意力
分解式
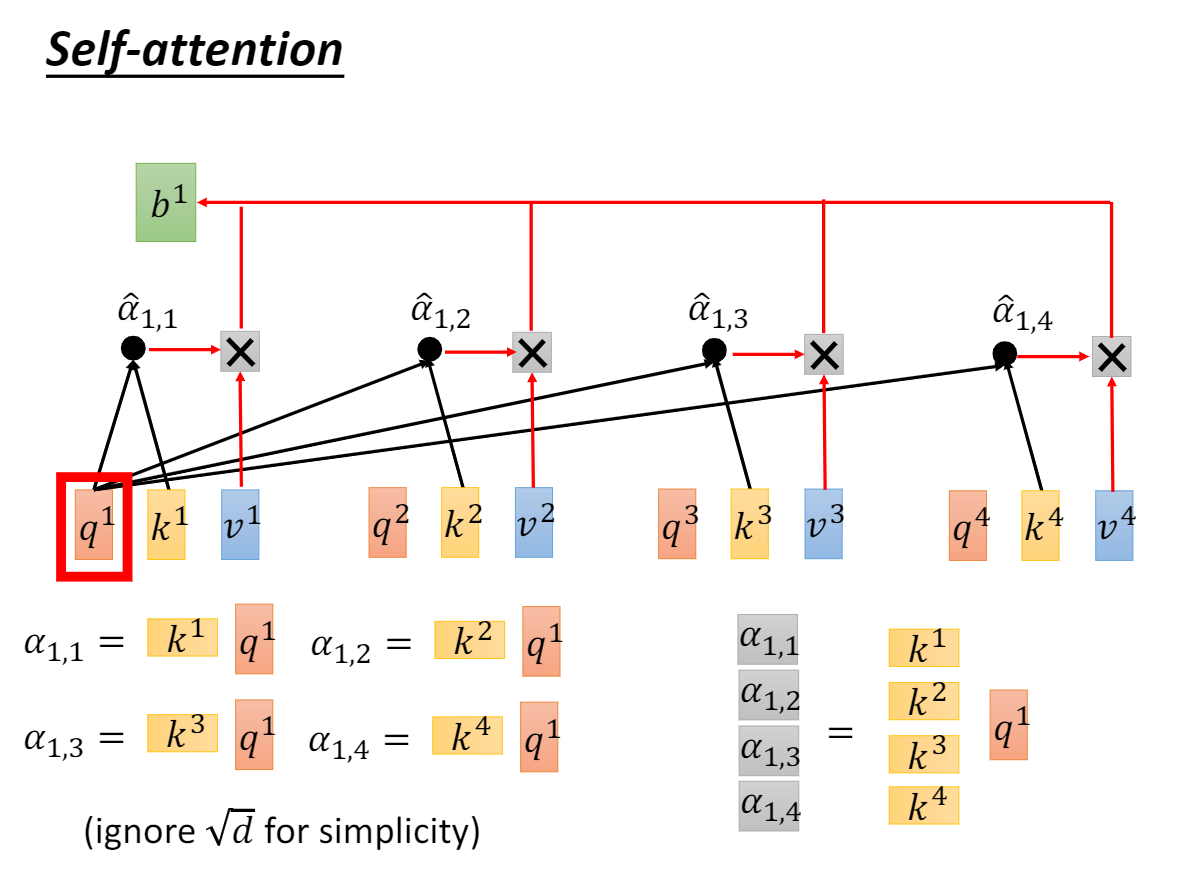
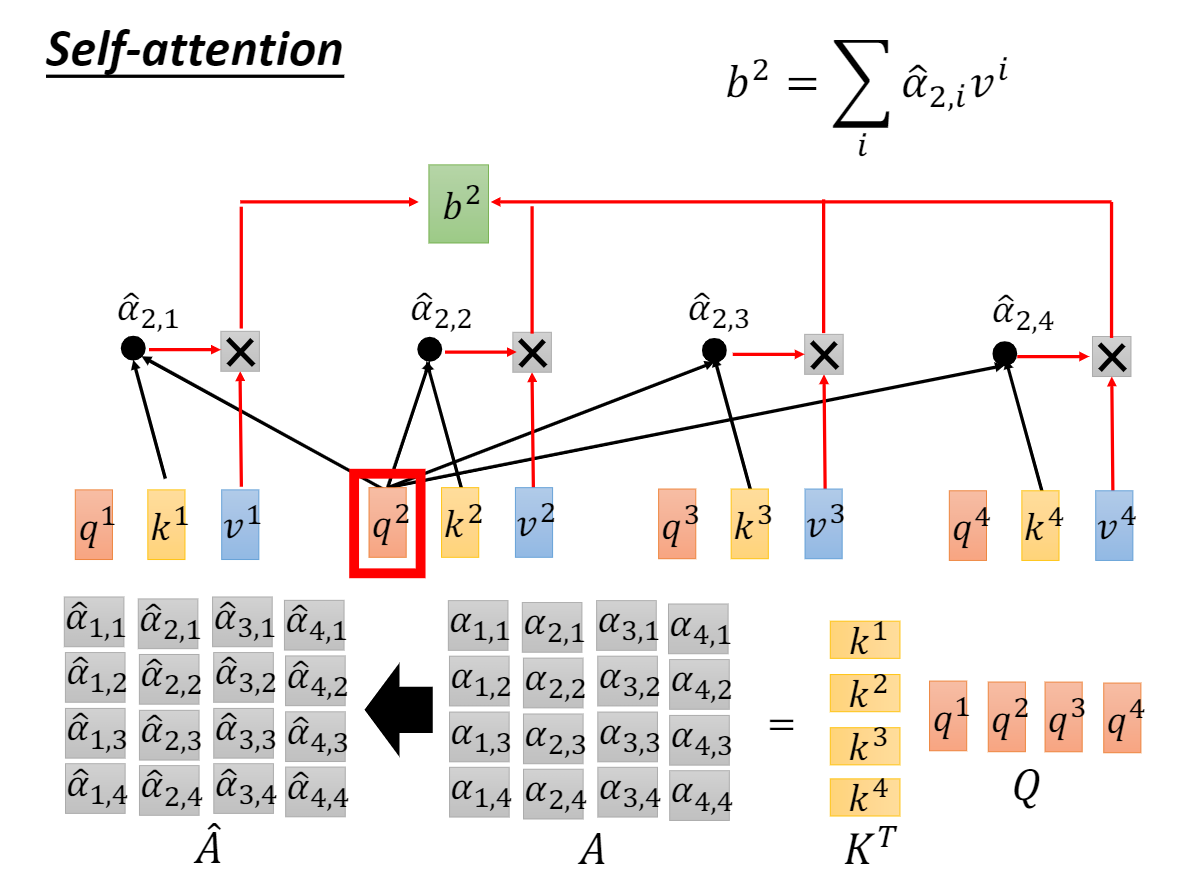
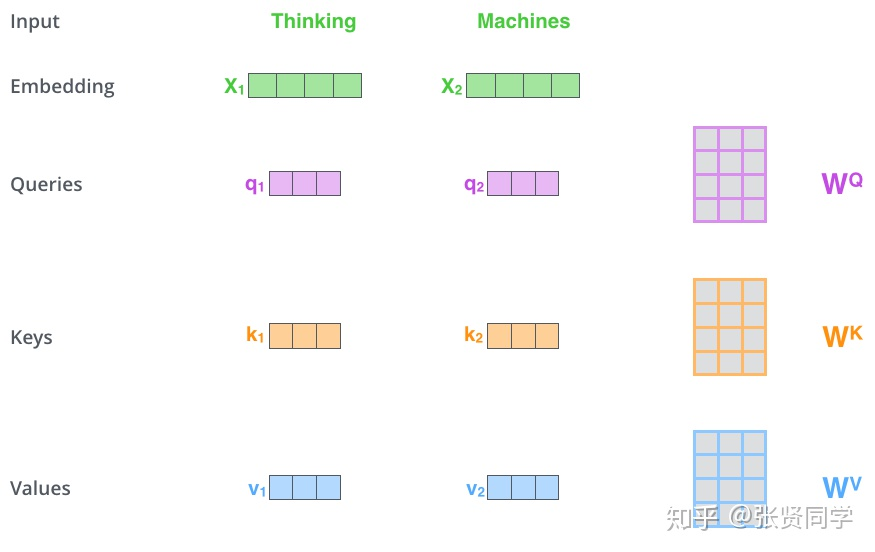
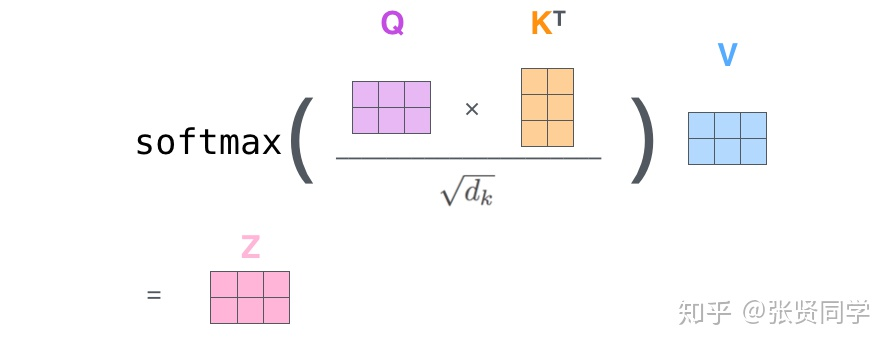
We suspect that for large values d_k, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.To counteract this effect, we scale the dot products by sqrt(d_k)
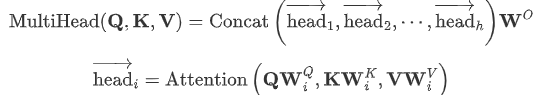
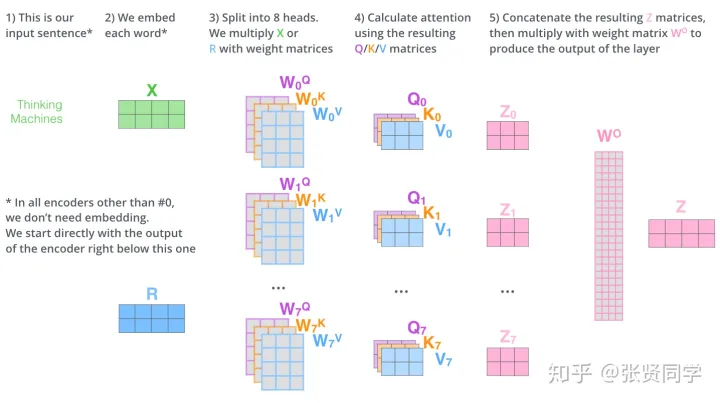
- 它扩展了模型关注不同位置的能力。不同注意力头,关注不同的位置。长距离依赖
- 多头注意力机制赋予 attention 层多个“子表示空间(训练之后,每组注意力可以看作是把输入的向量映射到一个”子表示空间“)
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
- embed_dim:最终输出的 K、Q、V 矩阵的维度,这个维度需要和词向量的维度一样
- num_heads:设置多头注意力的数量。如果设置为 1,那么只使用一组注意力。如果设置为其他数值,那么 num_heads 的值需要能够被 embed_dim 整除
- dropout:这个 dropout 加在 attention score 后面
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
- query:对应于 Query 矩阵,形状是 (L,N,E) 。其中 L 是输出序列长度,N 是 batch size,E 是词向量的维度
- key:对应于 Key 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
- value:对应于 Value 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
- key_padding_mask:如果提供了这个参数,那么计算 attention score 时,忽略 Key 矩阵中某些 padding 元素,不参与计算 attention(序列长度不同)。形状是 (N,S)。其中 N 是 batch size,S 是输入序列长度。
- 如果 key_padding_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
- 如果 key_padding_mask 是 BoolTensor,那么 True 对应的位置会被忽略
- attn_mask:计算输出时,忽略某些位置。形状可以是 2D (L,S),或者 3D (N∗numheads,L,S)。其中 L 是输出序列长度,S 是输入序列长度,N 是 batch size。
- 如果 attn_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
- 如果 attn_mask 是 BoolTensor,那么 True 对应的位置会被忽略
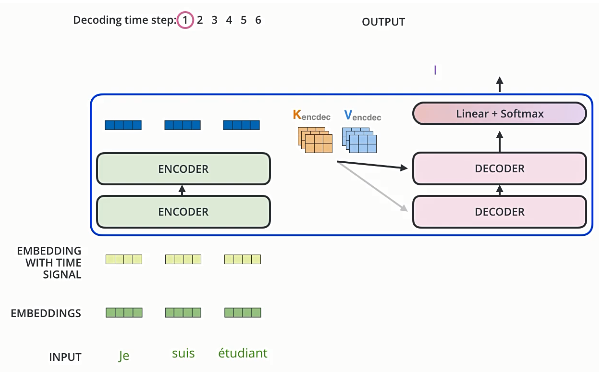
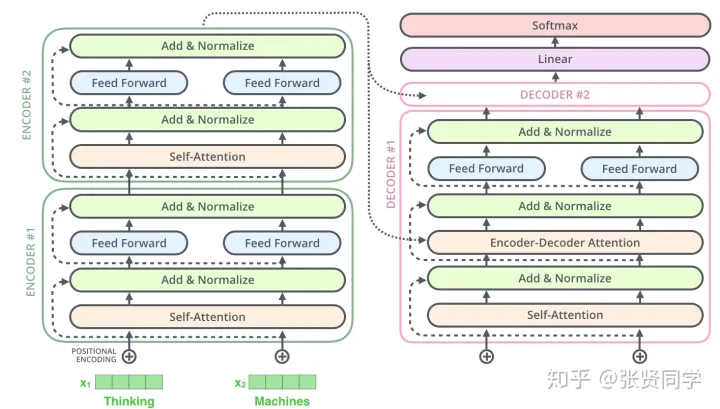
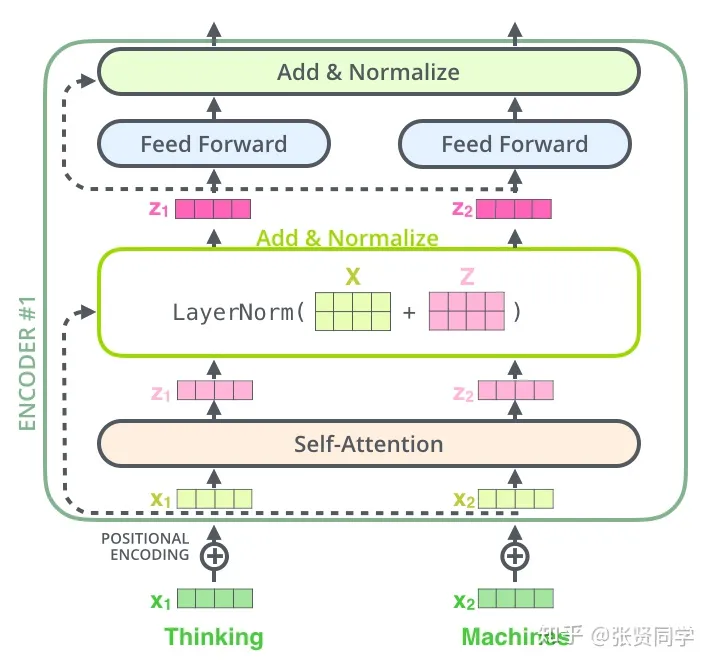
2. Encoder 和 Decoder
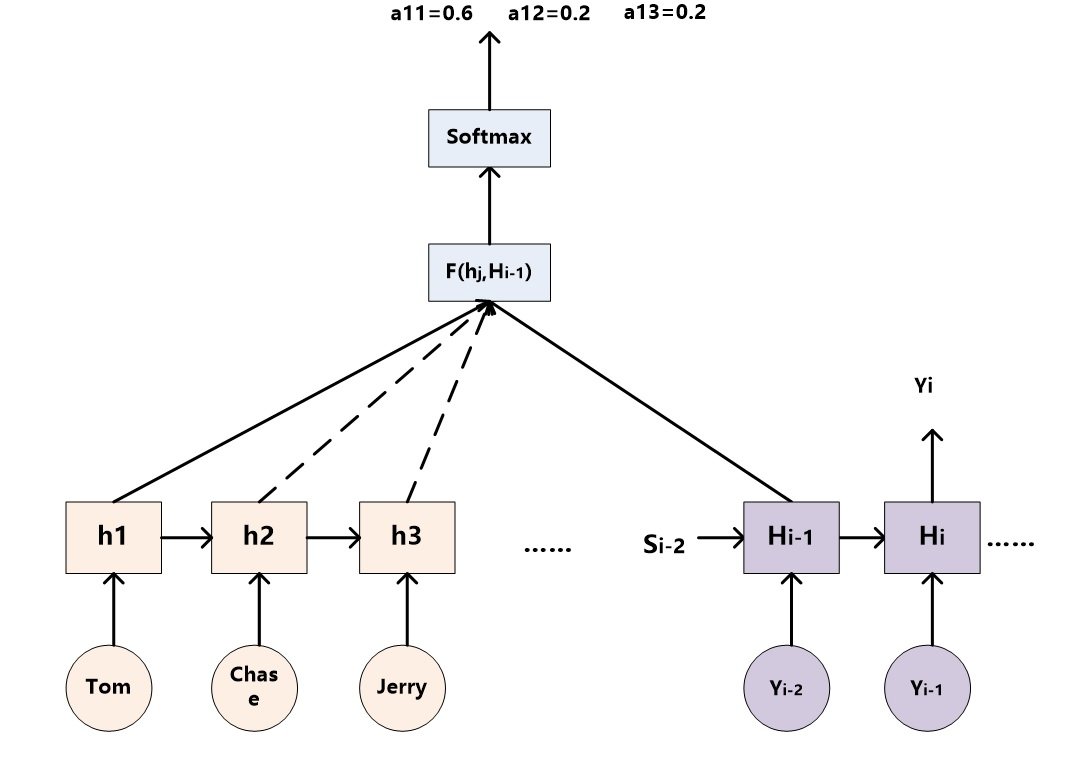
Self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.We need to prevent leftward information flow in the decoder to preserve the auto-regressive property.We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
避免信息泄露,在解码器中使用mask:
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10)
attention = self.do(torch.softmax(attention, dim=-1))
x = torch.matmul(attention, V)

【大语言模型基础】-详解Transformer原理的更多相关文章
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- Java基础学习总结(33)——Java8 十大新特性详解
Java8 十大新特性详解 本教程将Java8的新特新逐一列出,并将使用简单的代码示例来指导你如何使用默认接口方法,lambda表达式,方法引用以及多重Annotation,之后你将会学到最新的API ...
- 深入浅出DOM基础——《DOM探索之基础详解篇》学习笔记
来源于:https://github.com/jawil/blog/issues/9 之前通过深入学习DOM的相关知识,看了慕课网DOM探索之基础详解篇这个视频(在最近看第三遍的时候,准备记录一点东西 ...
- Android中Canvas绘图基础详解(附源码下载) (转)
Android中Canvas绘图基础详解(附源码下载) 原文链接 http://blog.csdn.net/iispring/article/details/49770651 AndroidCa ...
- Python学习二:词典基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7862377.html 邮箱:moyi@moyib ...
- 三剑客基础详解(grep、sed、awk)
目录 三剑客基础详解 三剑客之grep详解 1.通配符 2.基础正则 3.grep 讲解 4.拓展正则 5.POSIX字符类 三剑客之sed讲解 1.sed的执行流程 2.语法格式 三剑客之Awk 1 ...
- Dom探索之基础详解
认识DOM DOM级别 注::DOM 0级标准实际并不存在,只是历史坐标系的一个参照点而已,具体的说,它指IE4.0和Netscape Navigator4.0最初支持的DHTML. 节点类型 注:1 ...
- javaScript基础详解(1)
javaScript基础详解 首先讲javaScript的摆放位置:<script> 与 </script> 可以放在head和body之间,也可以body中或者head中 J ...
- Python学习一:序列基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7858473.html 邮箱:moyi@moyib ...
- java继承基础详解
java继承基础详解 继承是一种由已存在的类型创建一个或多个子类的机制,即在现有类的基础上构建子类. 在java中使用关键字extends表示继承关系. 基本语法结构: 访问控制符 class 子类名 ...
随机推荐
- Python 检测PE所启用保护方式
Python 通过pywin32模块调用WindowsAPI接口,实现对特定进程加载模块的枚举输出并检测该PE程序模块所启用的保护方式,此处枚举输出的是当前正在运行进程所加载模块的DLL模块信息,需要 ...
- 英特尔发布酷睿Ultra移动处理器:Intel 4制程工艺、AI性能飙升
英特尔今日发布了第一代酷睿Ultra移动处理器,是首款基于Intel 4制程工艺打造的处理器. 据了解,英特尔酷睿Ultra采用了英特尔首个用于客户端的片上AI加速器"神经网络处理单元(NP ...
- HarmonyOS 开发入门(三)
HarmonyOS 开发入门(三) 日常逼逼叨 在开发入门(一)和开发入门(二)中我们描述了 HarmonyOS 开发的语言ArKTs以及Ts简单的入门级语法操作以及开发环境的搭建,接下来我们进入第三 ...
- 逆天的全排列函数next_permutation()
next_permutation 是算法库(<algorithm>)里的一个用于求全排列的函数,其定义为 next_permutation(_BidIt _First, _BidIt _L ...
- Excel分类后数字类型的内容值后面变为0
背景 在工作中经常遇到从日志或者其他地方拷贝过来的文本,里面使用其他分隔符进行分割.然而,使用Excel的分列功能进行分列后,发现数字类型的数值后面变为0. 有时候我们就是需要原先的数值,该怎么办呢? ...
- [Java]Java类中的各元素初始化顺序
Java类中各元素的初始化顺序 初始化的原则是: 先初始化静态部分,再初始化动态部分:(先静再动) 先初始化父类部分,后初始化子类部分:(先父再子) 先初始化变量,次初始化代码块,再初始化构造器:(先 ...
- 《AI驱动下的开发者新生态》-2024长沙.NET技术社区活动-诚邀大家报名
回顾 2019年初,在.NET中文社区及包括苏州.广州.深圳等地区社区等大力推动.在众多企业的大力支持下,长沙地区的开发者们发起成立了长沙.NET技术社区,并组织了<2019年长沙开发者技术大会 ...
- JS 从零手写一个深拷贝(进阶篇)
壹 ❀ 引 在深拷贝与浅拷贝的区别,实现深拷贝的几种方法一文中,我们阐述了深浅拷贝的概念与区别,普及了部分具有迷惑性的浅拷贝api.当然,我们也实现了乞丐版的深拷贝方法,能解决部分拷贝场景,虽然它仍有 ...
- zookeeper源码(08)请求处理及数据读写流程
ServerCnxnFactory 用于接收客户端连接.管理客户端session.处理客户端请求. ServerCnxn抽象类 代表一个客户端连接对象: 从网络读写数据 数据编解码 将请求转发给上层组 ...
- OAuth2 Authorization Server
基于Spring Security 5 的 Authorization Server的写法 先看演示 pom.xml <?xml version="1.0" encoding ...