实战0-1,Java开发者也能看懂的大模型应用开发实践!!!
前言
在前几天的文章《续写AI技术新篇,融汇工程化实践》中,我分享说在RAG领域,很多都是工程上的实践,做AI大模型应用的开发其实Java也能写,那么本文就一个Java开发者的立场,构建实现一个最基础的大模型应用系统。
而大模型应用系统其实在目前阶段,可能应用最广的还是RAG领域,因此,本文也是通过在RAG领域的基础架构下,来实现应用的开发,主要需求点:让大模型理解文本(知识库)内容,基于知识库范围内的内容进行回答对话
而基于知识库的回答会帮助我们解决哪些问题呢?
- 节省大模型训练成本:我们知道ChatGPT的知识内容停留在2021年,最新的知识它并不知道,而检索增强生成则可以解决大模型无法快速学习的问题,训练大模型代价是非常昂贵的,不仅仅只是金钱,还包括时间,随着模型的参数大小成本成正相关。
- 让大模型更聪明:很多企业内部的私有数据大模型并没有学习,而通过RAG的方式可以让大模型在知识库范围的领域进行回答,避免胡说八道,基于底层大模型的基座,可以让我们的应用系统看上去更加的聪明。
在本文中,你将学习到:
- RAG工程的基本处理框架流程(基于Java)
- 向量数据库的基础使用及了解
技术栈
考虑到作者也是Java开发者,因此本文所选择的技术栈以及中间件也是Java人员都耳熟能详的,主要技术栈如下:
1、开发框架:Spring Boot、Spring Shell(命令行对话)
Java开发者对于Spring Boot的生态应该是非常熟悉的,而选择Spring Shell工具包主要是为了演示命令行的交互问答效果,和本次的技术无太大关系,算是一个最小雏形的产品交互体验。
2、HTTP组件:OkHTTP、OkHTTP-SSE
此次我们选择的大模型是以智谱AI开放的ChatGLM系列为主,因此我们需要HTTP组件和商业大模型的API进行接口的对接,当然开发者如果有足够的条件,也是可以在本地部署开源大模型并且开放API接口进行调试的,这个并不冲突,本文只是为了方便演示效果,所以使用了智谱的大模型API接口,而智谱AI注册后,默认提供了一个18元的免费Token消费额度,因此接口的API-Key只需要注册一个即可快速获取。
3、工具包:Hutool
非常好用的一个基础工具包组件,封装了很多工具类方法,包含字符、文件、时间、集合等等
本文会使用到Hutool包的文本读取和切割方法。
4、向量数据库:ElasticSearch
向量数据库是RAG应用程序的基础中间件,所有的文本Embedding向量都需要存储在向量数据库中间件中进行召回计算,当然在Java领域并没有类似Python中numpy这类本地化工具组件包,即可快速实现矩阵计算等需求(PS:最近Java21的发布中,不仅仅只是虚拟线程等新特性,提供的向量API相信在未来AI领域,Java也会有一席之地的),所以选择了独立部署的中间件。
本文选择ElasticSearch可能对于Java开发人员也是比较熟悉的一个组件,毕竟ES在Java领域用途还是非常广的,只是可能很多开发者并不知道ElasticSearch居然还有存储向量数据的功能?
对于向量数据库中间件的选择,目前市面上有非常多的向量数据库,包括:Milvus、Qdrant、Postgres(pgvector)、Chroma 等等,Java开发者可以在熟悉当前流程后,根据自己的实际需求,选择符合企业生产环境的向量数据库。
5、LLM大模型:ChatGLM-Std
为了演示方便,本文直接使用开放API接口的商业大模型,智谱AI提供的ChatGLM-Std
RAG工程的基本处理流程
在RAG检索增强生成领域中,最简单的核心处理流程架构图如下:
该架构图图是一个非常简单的流程图,在RAG领域中其实有非常多的处理细节,当我们深入了解后就会知道
我们后续根据该图来进行Java编码实现。
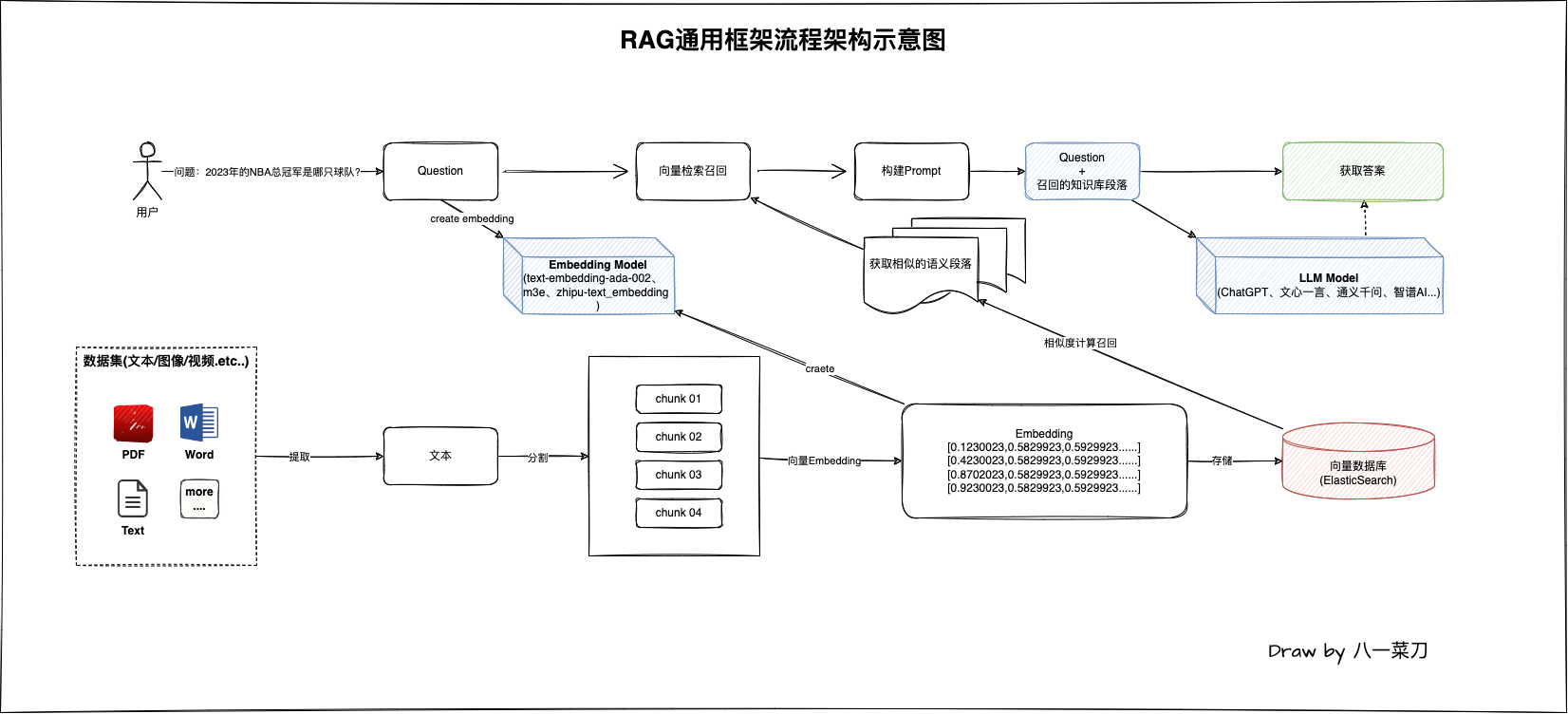
在RAG应用工程领域,其实整个程序的处理包含两部分:
- 问答:对用户提问的问题通过向量
Embedding模型处理,然后通过查询向量数据库(ElasticSearch)进行相似度计算获取和用户问题最相似的知识库段落内容,获取成功后,构建Prompt,最终发送给大模型获取最终的答案。 - 数据处理:数据的处理是将用户私有的数据进行提取,包括各种结构化及非结构化数据(例如
PDF/Word/Text等等),提取文本数据后进行分割处理,最终通过向量Embedding模型将这些分割后的段落进行向量化,最终向量数据存储在基础设施向量数据库组件中,以供后续的问答流程使用。
从图中我们可以知道,在我们所需要的大模型处于什么位置,以及它的作用,主要是两个模型的应用:
- 向量Embedding模型:对我们本地知识的向量表征处理,将文本内容转化为便于计算机理解的向量表示
- LLM问答大模型:大模型负责将我们通过语义召回的段落+用户的问题结合,构建的
Prompt送给大模型以获取最终的答案,问答大模型在这里充当的角色是理解我们送给他的内容,然后进行精准回答
Java编码实践
我们理解了基础的架构流程,接下来就是编码实现了
环境准备
Java:JDK 1.8
ElasticSearch:7.16.1
对于ElasticSearch的安装,可以通过docker-compose在本地快速部署一个
编写docker-compose.yml配置文件,当前部署目录建data文件夹挂载数据目录
version: "3"
services:
elasticsearch:
image: elasticsearch:7.16.1
ports:
- "9200:9200"
- "9300:9300"
environment:
node.name: es
cluster.name: elasticsearch
discovery.type: single-node
ES_JAVA_OPTS: -Xms4096m -Xmx4096m
volumes:
- ./data:/usr/share/elasticsearch/data
deploy:
resources:
limits:
cpus: "4"
memory: 5G
reservations:
cpus: "1"
memory: 2G
restart: always
启动Es:docker-compose up -d
应用初体验
先来看整个程序的应用效果,通过Spring Shell环境下,程序启动后,如下图所示:
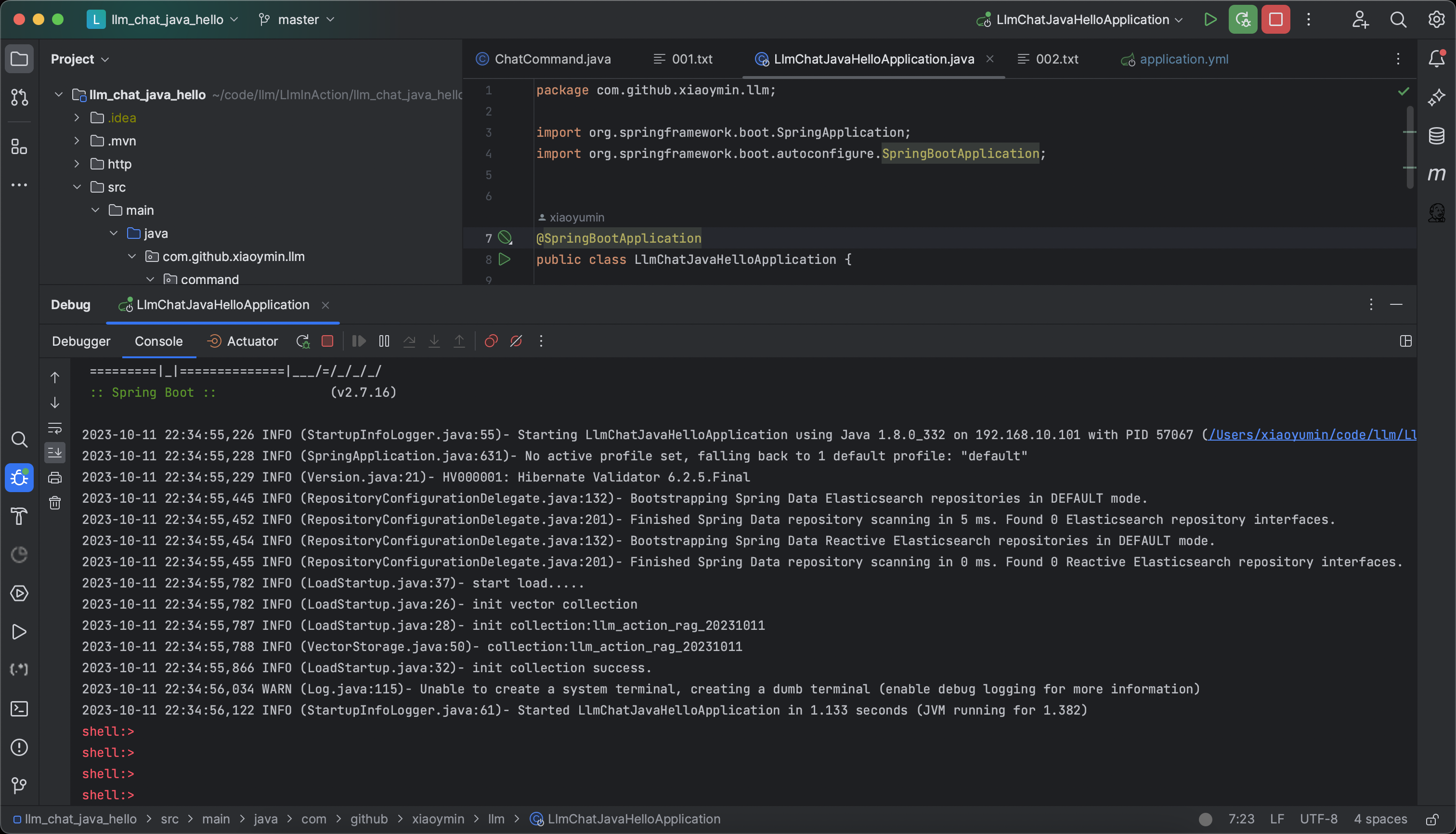
程序启动后,在命令行终端,我们可以看到一个可交互的命令行,此时,我们可以通过add和chat两个命令完成图1中的整个流程
先使用add命令加载文档,在data目录下分别存储了001.txt、002.txt两个文件,通过命令加载向量处理,如下图:
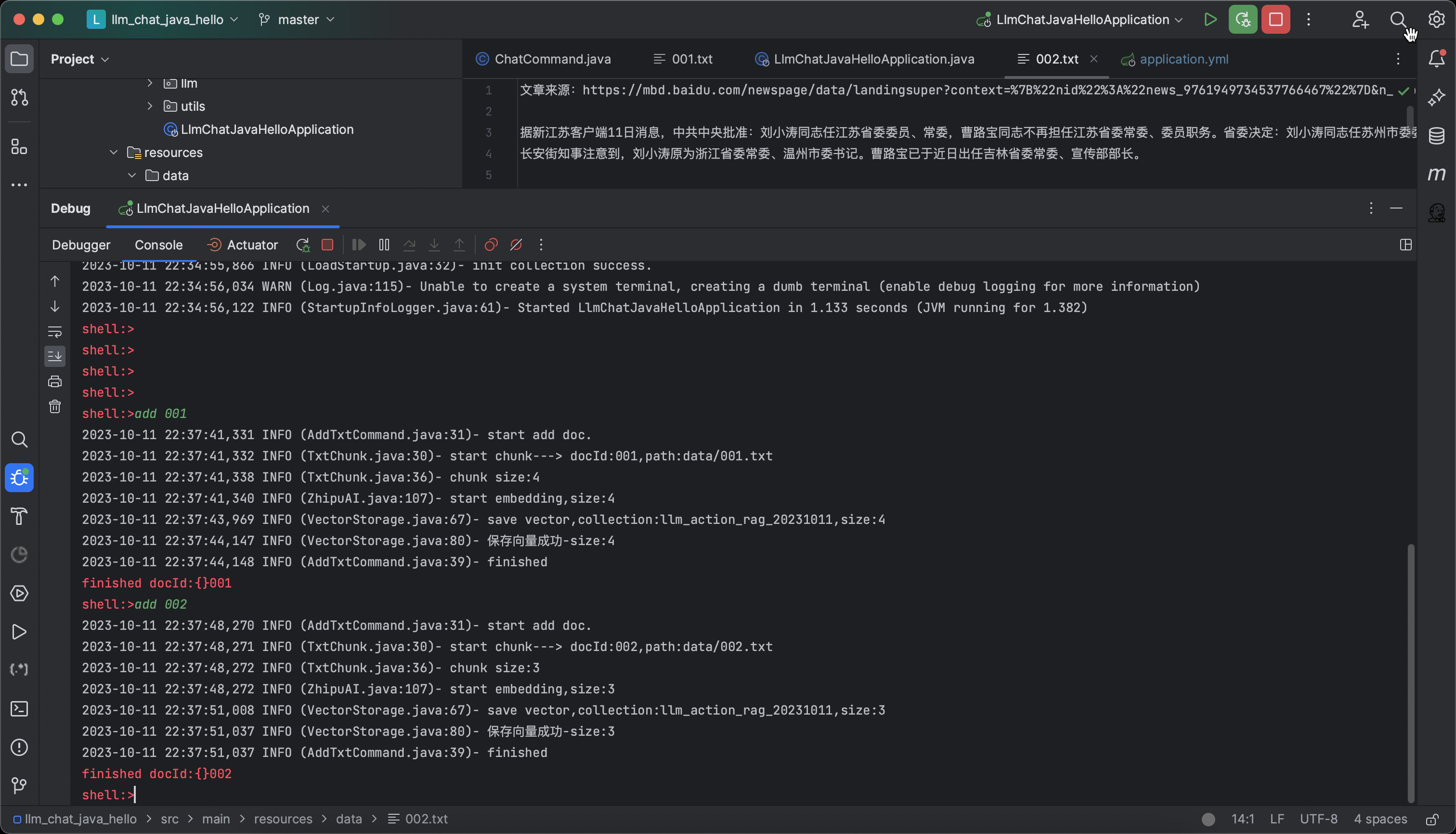
当日志显示保存向量成功后,此时,我们即可以通过chat命令进行对话了,我们先来看看002.txt的文本主要说了什么内容?
data目录下的文本,开发者在调试时可以自己随意添加,网上随便找的文章都可以
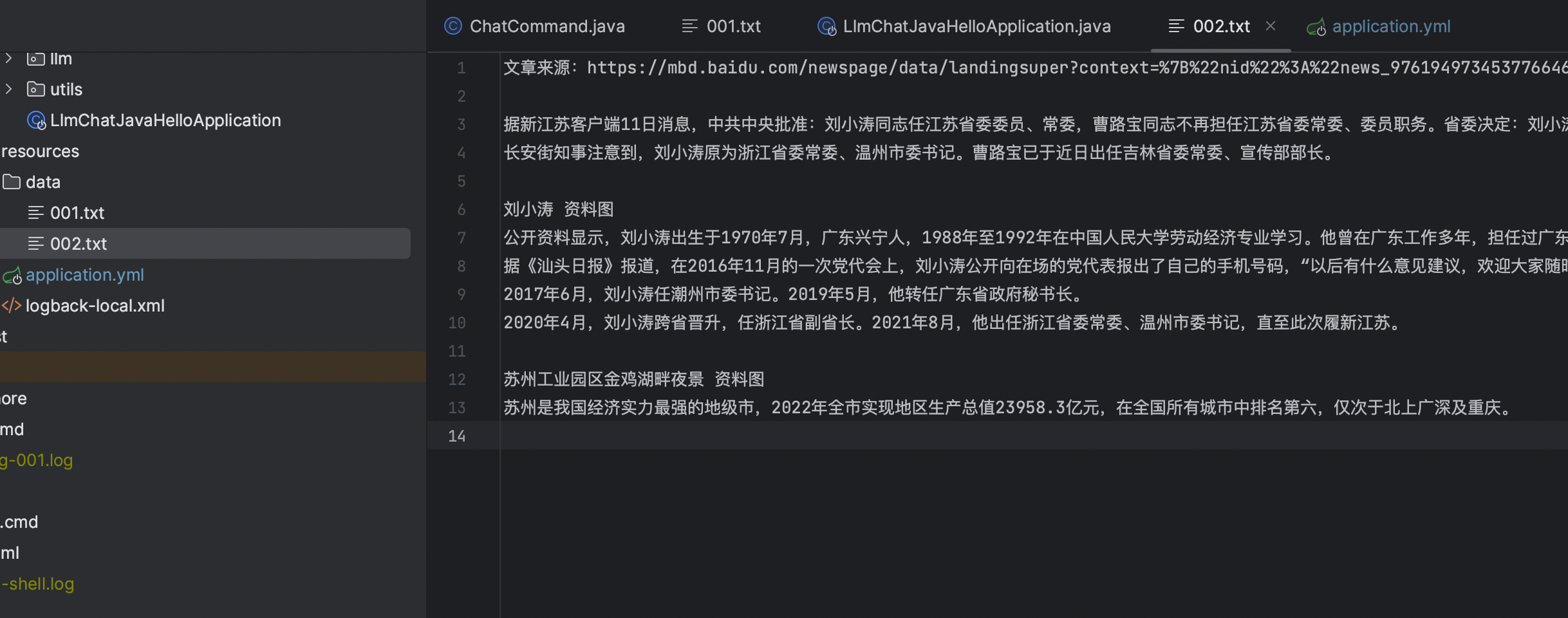
文章内容是一篇非常具有代表性的时政人物介绍新闻,那么我们就根据该文章的内容进行问答!
问题1:苏州2022年全市的GDP是多少?
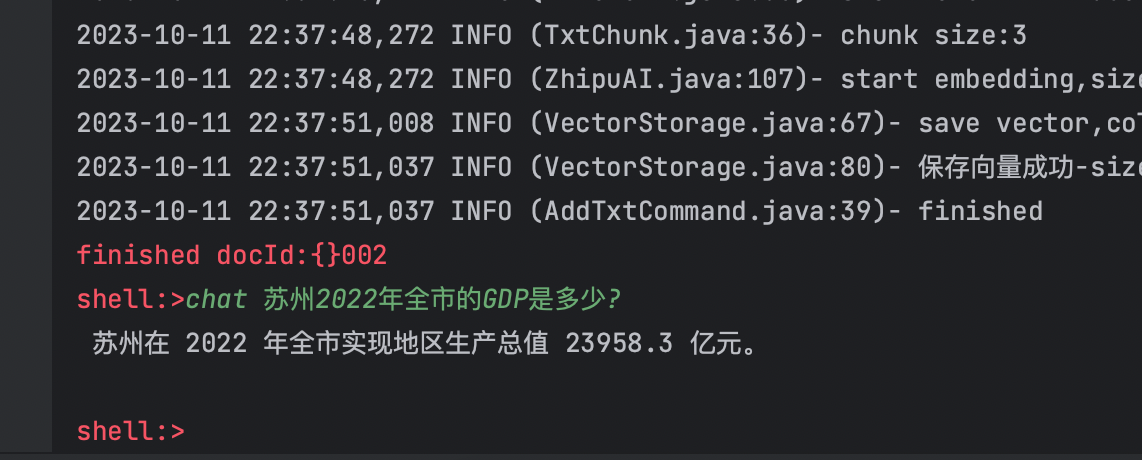
问题2:吉林省宣传部部长现在是谁?
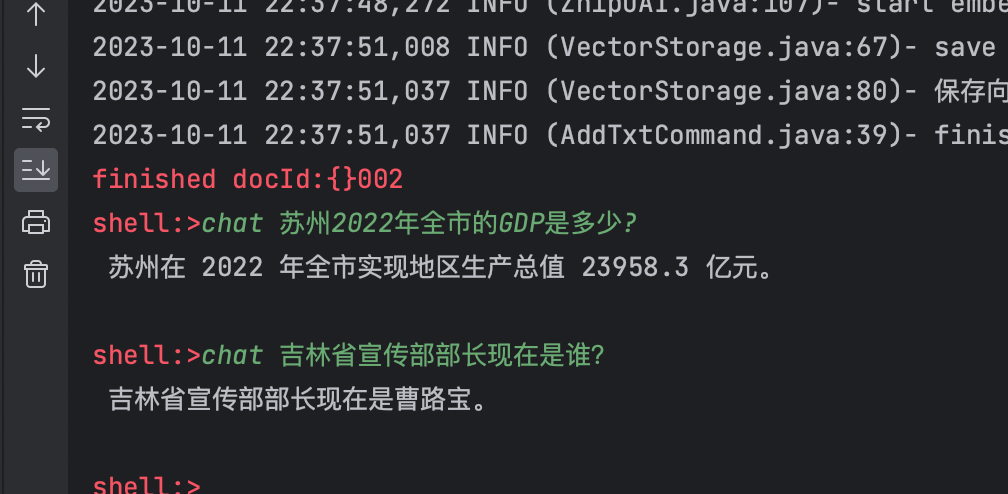
通过第一个问题,你是否可以发现问题呢?,如果你问ChatGPT一样的问题,它能准确回答吗?
以下是ChatGPT的回答
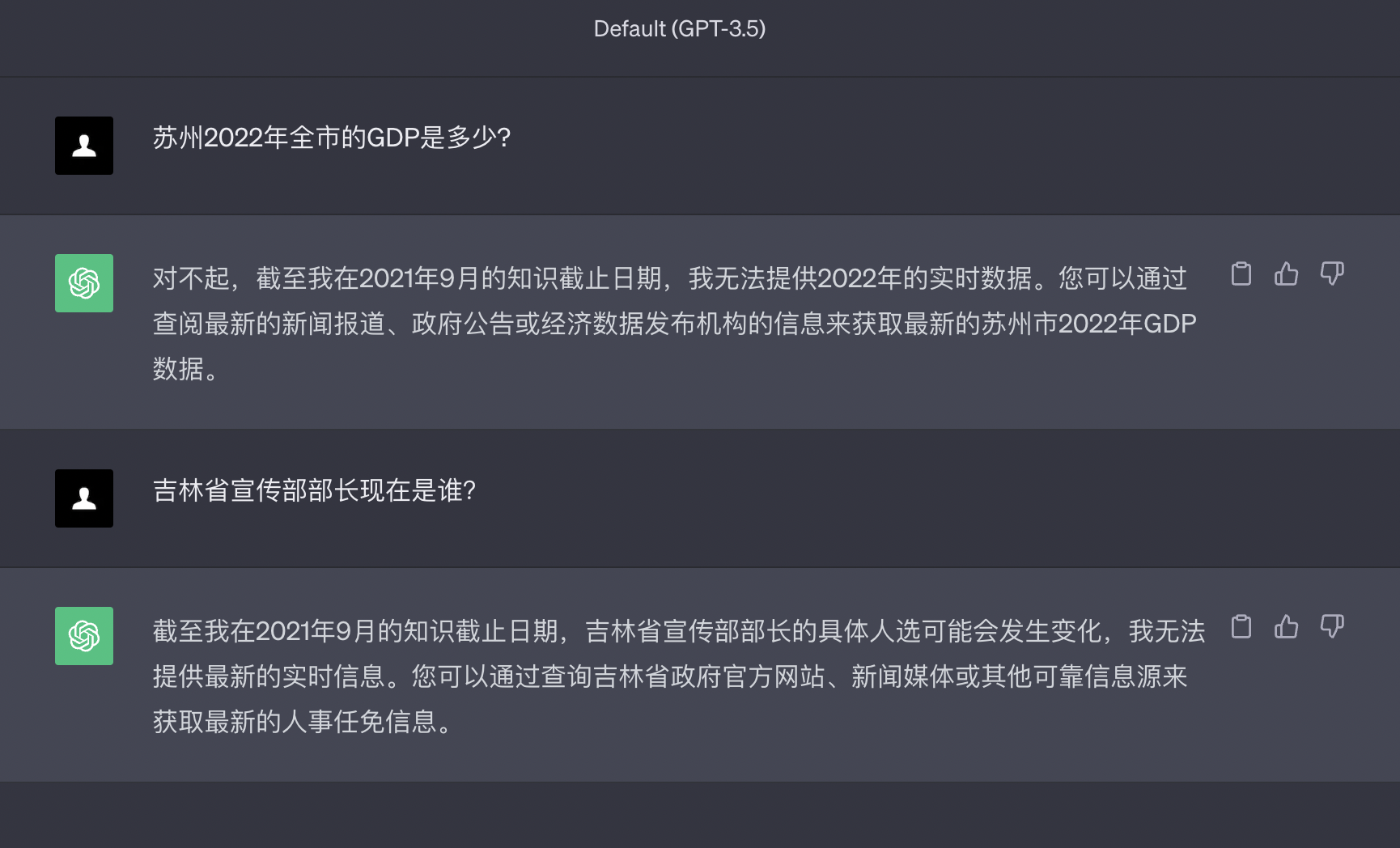
通过对比ChatGPT,开发者应该能看到一个基础的对比效果,主要体现:
- 我们都知道ChatGPT大模型的内容日期截止到2021年,之后世界发生了什么,它并不知道,同类的GPT大模型也会出现一样的问题,因为训练大模型的代价是非常昂贵的,不可能按周、月,甚至是年的频率去更新大模型。
- 基于现有的知识回答内容(RAG),能够有效的避免大模型胡说八道,而且回答的更精准
技术实现
进行问答体验后,我们来看具体的Java代码实现。
新建Spring Boot项目,工程目录如下:
GitHub:https://github.com/xiaoymin/LlmInAction/tree/master/llm_chat_java_hello
从上文的RAG流程图中,我们知道了主要分两个步骤来实现,分别是数据的向量处理和问答
由于是通过Spring Shell进行实现,因此这里我也分开,主要实现了两个Command命令:
- add:在data目录下,为了演示需要,存放了两个txt内容,可以通过
add file名称来实现文档的向量化流程加载处理,数据的处理开发者在实际的生产过程中可以通过定时任务、MQ消息等方式进行异步处理。 - chat:通过命令
chat 问题即可在Spring Shell的命令行终端进行对话,可以问data目录下相关的问题
为了方便后续的处理,程序启动时即会自动构建向量数据库的索引集合,代码如下:
/**
* 初始化向量数据库index
* @param collectionName 名称
* @param dim 维度
*/
public boolean initCollection(String collectionName,int dim){
log.info("collection:{}", collectionName);
// 查看向量索引是否存在,此方法为固定默认索引字段
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(collectionName));
if (!indexOperations.exists()) {
// 索引不存在,直接创建
log.info("index not exists,create");
//创建es的结构,简化处理
Document document = Document.from(this.elasticMapping(dim));
// 创建
indexOperations.create(new HashMap<>(), document);
return true;
}
return true;
}
Es中的Index的Mapping结构如下:

开发者需要注意vector字段,字段类型时dense_vector,并且指定向量维度为1024
向量维度的长度指定是和最终向量Embedding模型息息相关的,不同的模型有不同的维度,比如ChatGPT的向量模型维度是1536,百度文心一言也有368的,因此根据实际情况进行选择。
而这里因为我们选择的是智谱AI的向量模型,该模型返回的维度为1024,那么我们在向量数据库的维度就设置为1024
首先是add命令实现文档的向量化过程处理,代码如下:
@Slf4j
@AllArgsConstructor
@ShellComponent
public class AddTxtCommand {
final TxtChunk txtChunk;
final VectorStorage vectorStorage;
final ZhipuAI zhipuAI;
@ShellMethod(value = "add local txt data")
public String add(String doc){
log.info("start add doc.");
// 加载
List<ChunkResult> chunkResults= txtChunk.chunk(doc);
// embedding
List<EmbeddingResult> embeddingResults=zhipuAI.embedding(chunkResults);
// store vector
String collection= vectorStorage.getCollectionName();
vectorStorage.store(collection,embeddingResults);
log.info("finished");
return "finished docId:{}"+doc;
}
}
我们完全按照图1RAG的流程架构图进行代码的变现,主要的步骤:
1、加载指定的文档,并且将文档内容进行分割处理(按固定size大小进行分割处理),得到分割集合chunkResults,代码如下:
@Slf4j
@Component
@AllArgsConstructor
public class TxtChunk {
public List<ChunkResult> chunk(String docId){
String path="data/"+docId+".txt";
log.info("start chunk---> docId:{},path:{}",docId,path);
// 读取data目录下的文件流
ClassPathResource classPathResource=new ClassPathResource(path);
try {
// 读取为文本
String txt=IoUtil.read(classPathResource.getInputStream(), StandardCharsets.UTF_8);
//按固定字数分割,256
String[] lines=StrUtil.split(txt,256);
log.info("chunk size:{}", ArrayUtil.length(lines));
List<ChunkResult> results=new ArrayList<>();
//此处给每个文档一个固定的chunkId
AtomicInteger atomicInteger=new AtomicInteger(0);
for (String line:lines){
ChunkResult chunkResult=new ChunkResult();
chunkResult.setDocId(docId);
chunkResult.setContent(line);
chunkResult.setChunkId(atomicInteger.incrementAndGet());
results.add(chunkResult);
}
return results;
} catch (IOException e) {
log.error(e.getMessage());
}
return new ArrayList<>();
}
}
2、将分块的集合通过智谱AI提供的向量Embedding模型进行向量化处理,代码实现如下:
/**
* 批量
* @param chunkResults 批量文本
* @return 向量
*/
public List<EmbeddingResult> embedding(List<ChunkResult> chunkResults){
log.info("start embedding,size:{}",CollectionUtil.size(chunkResults));
if (CollectionUtil.isEmpty(chunkResults)){
return new ArrayList<>();
}
List<EmbeddingResult> embeddingResults=new ArrayList<>();
for (ChunkResult chunkResult:chunkResults){
//分别处理
embeddingResults.add(this.embedding(chunkResult));
}
return embeddingResults;
}
public EmbeddingResult embedding(ChunkResult chunkResult){
//获取智谱AI的开发Key
String apiKey= this.getApiKey();
// 初始化http客户端
OkHttpClient.Builder builder = new OkHttpClient.Builder()
.connectTimeout(20000, TimeUnit.MILLISECONDS)
.readTimeout(20000, TimeUnit.MILLISECONDS)
.writeTimeout(20000, TimeUnit.MILLISECONDS)
.addInterceptor(new ZhipuHeaderInterceptor(apiKey));
OkHttpClient okHttpClient = builder.build();
EmbeddingResult embedRequest=new EmbeddingResult();
embedRequest.setPrompt(chunkResult.getContent());
embedRequest.setRequestId(Objects.toString(chunkResult.getChunkId()));
// 智谱embedding模型接口
Request request = new Request.Builder()
.url("https://open.bigmodel.cn/api/paas/v3/model-api/text_embedding/invoke")
.post(RequestBody.create(MediaType.parse(ContentType.JSON.getValue()), GSON.toJson(embedRequest)))
.build();
try {
Response response= okHttpClient.newCall(request).execute();
String result=response.body().string();
ZhipuResult zhipuResult= GSON.fromJson(result, ZhipuResult.class);
EmbeddingResult ret= zhipuResult.getData();
ret.setPrompt(embedRequest.getPrompt());
ret.setRequestId(embedRequest.getRequestId());
return ret;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
3、向量处理成功后,我们即可将向量数据存储在向量数据库中间件(ElasticSearch)中,调用vectorStorage.store处理,代码如下:
public void store(String collectionName,List<EmbeddingResult> embeddingResults){
//保存向量
log.info("save vector,collection:{},size:{}",collectionName, CollectionUtil.size(embeddingResults));
List<IndexQuery> results = new ArrayList<>();
for (EmbeddingResult embeddingResult : embeddingResults) {
ElasticVectorData ele = new ElasticVectorData();
ele.setVector(embeddingResult.getEmbedding());
ele.setChunkId(embeddingResult.getRequestId());
ele.setContent(embeddingResult.getPrompt());
results.add(new IndexQueryBuilder().withObject(ele).build());
}
// 构建数据包
List<IndexedObjectInformation> bulkedResult = elasticsearchRestTemplate.bulkIndex(results, IndexCoordinates.of(collectionName));
int size = CollectionUtil.size(bulkedResult);
log.info("保存向量成功-size:{}", size);
}
}
至此,整个文本数据的Embedding处理就完成了。
数据处理完成后,接下来我们需要实现问答chat命令,来看代码实现:
@AllArgsConstructor
@Slf4j
@ShellComponent
public class ChatCommand {
final VectorStorage vectorStorage;
final ZhipuAI zhipuAI;
@ShellMethod(value = "chat with files")
public String chat(String question){
if (StrUtil.isBlank(question)){
return "You must send a question";
}
//句子转向量
double[] vector=zhipuAI.sentence(question);
// 向量召回
String collection= vectorStorage.getCollectionName();
String vectorData=vectorStorage.retrieval(collection,vector);
if (StrUtil.isBlank(vectorData)){
return "No Answer!";
}
// 构建Prompt
String prompt= LLMUtils.buildPrompt(question,vectorData);
zhipuAI.chat(prompt);
// 大模型对话
//return "you question:{}"+question+"finished.";
return StrUtil.EMPTY;
}
}
Chat命令主要包含的步骤如下:
1、将用户的问句首先通过向量Embedding模型转化得到一个多维的浮点型向量数组,代码如下:
/**
* 获取句子的向量
* @param sentence 句子
* @return 向量
*/
public double[] sentence(String sentence){
ChunkResult chunkResult=new ChunkResult();
chunkResult.setContent(sentence);
chunkResult.setChunkId(RandomUtil.randomInt());
EmbeddingResult embeddingResult=this.embedding(chunkResult);
return embeddingResult.getEmbedding();
}
2、根据向量数据查询向量数据库召回相似的段落内容,vectorStorage.retrieval方法代码如下:
public String retrieval(String collectionName,double[] vector){
// Build the script,查询向量
Map<String, Object> params = new HashMap<>();
params.put("query_vector", vector);
// 计算cos值+1,避免出现负数的情况,得到结果后,实际score值在减1再计算
Script script = new Script(ScriptType.INLINE, Script.DEFAULT_SCRIPT_LANG, "cosineSimilarity(params.query_vector, 'vector')+1", params);
ScriptScoreQueryBuilder scriptScoreQueryBuilder = new ScriptScoreQueryBuilder(QueryBuilders.boolQuery(), script);
// 构建请求
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(scriptScoreQueryBuilder)
.withPageable(Pageable.ofSize(3)).build();
SearchHits<ElasticVectorData> dataSearchHits = this.elasticsearchRestTemplate.search(nativeSearchQuery, ElasticVectorData.class, IndexCoordinates.of(collectionName));
//log.info("检索成功,size:{}", dataSearchHits.getTotalHits());
List<SearchHit<ElasticVectorData>> data = dataSearchHits.getSearchHits();
List<String> results = new LinkedList<>();
for (SearchHit<ElasticVectorData> ele : data) {
results.add(ele.getContent().getContent());
}
return CollectionUtil.join(results,"");
}
这里主要利用了ElasticSearch提供的cosineSimilarity余弦相似性函数,计算向量得到相似度的分值,分值会在区间[0,1]之间,如果无限趋近于1那么代表用户输入的句子和之前我们存储在向量中的句子是非常相似的,越相似代表我们找到了语义相近的文档内容,可以作为最终构建大模型Prompt的基础内容。
向量矩阵的计算除了余弦相似性,还有IP点积、欧几里得距离等等,根据实际情况选择不同的算法实现。
3、向量召回Top3得到相似的语义文本内容后,我们就可以构建Prompt了,并且发送给大模型,Prompt如下:
public static String buildPrompt(String question,String context){
return "请利用如下上下文的信息回答问题:" + "\n" +
question + "\n" +
"上下文信息如下:" + "\n" +
context + "\n" +
"如果上下文信息中没有帮助,则不允许胡乱回答!";
}
而在构建Prompt时,我们可以遵循一个最简单的框架范式,RTF框架(Role-Task-Format):
- R-Role:指定GPT大模型担任特定的角色
- T-Task:任务,需要大模型做的事情
- F-Format:大模型返回的内容格式(常规情况下可以忽略)
4、最后是调用大模型,实现sse流式调用输出,代码如下:
public void chat(String prompt){
try {
OkHttpClient.Builder builder = new OkHttpClient.Builder()
.connectTimeout(20000, TimeUnit.MILLISECONDS)
.readTimeout(20000, TimeUnit.MILLISECONDS)
.writeTimeout(20000, TimeUnit.MILLISECONDS)
.addInterceptor(new ZhipuHeaderInterceptor(this.getApiKey()));
OkHttpClient okHttpClient = builder.build();
ZhipuChatCompletion zhipuChatCompletion=new ZhipuChatCompletion();
zhipuChatCompletion.addPrompt(prompt);
// 采样温度,控制输出的随机性,必须为正数
// 值越大,会使输出更随机,更具创造性;值越小,输出会更加稳定或确定
zhipuChatCompletion.setTemperature(0.7f);
zhipuChatCompletion.setTop_p(0.7f);
EventSource.Factory factory = EventSources.createFactory(okHttpClient);
ObjectMapper mapper = new ObjectMapper();
String requestBody = mapper.writeValueAsString(zhipuChatCompletion);
Request request = new Request.Builder()
.url("https://open.bigmodel.cn/api/paas/v3/model-api/chatglm_std/sse-invoke")
.post(RequestBody.create(MediaType.parse(ContentType.JSON.getValue()), requestBody))
.build();
CountDownLatch countDownLatch=new CountDownLatch(1);
// 创建事件,控制台输出
EventSource eventSource = factory.newEventSource(request, new ConsoleEventSourceListener(countDownLatch));
countDownLatch.await();
} catch (Exception e) {
log.error("llm-chat异常:{}", e.getMessage());
}
}
SSE流式的调用我们使用了okhttp-sse组件提供的功能快速实现。
好了,整个工程层面的Java代码实现就已经全部完成了。
最后
以上就是本片分享的全部内容了,通过Java开发语言,实现一个最小可用级别的RAG大模型应用!相信你看完本文后,也能够对AI大模型应用的开发有一个基本的了解。
如果你也在关注大模型、RAG检索增强生成技术,欢迎关注我,一起探索学习、成长~!

附录
本文代码Github:https://github.com/xiaoymin/LlmInAction
智谱AI:https://open.bigmodel.cn/
实战0-1,Java开发者也能看懂的大模型应用开发实践!!!的更多相关文章
- Java开发者职业生涯要看的200+本书
作者:老刘链接:https://www.zhihu.com/question/29581524/answer/684872838来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- 十分钟看懂,未来Web前端开发最新趋势
首先,展望未来趋势我们就要弄懂过去的一年,也就是18年,web前端开发的重要新闻.重要事件和JavaScript的各种流行框架.模式发展趋势. 我们来快速回顾一下. NPM热门前端框架下载 先来看最热 ...
- 一图让你看懂CSS盒子模型
- 想入职阿里的Java开发者必看,阿里巴巴面试官实战经验分享!
最近社区Java技术进阶群的小伙伴总是会问,如何面试阿里Java技术岗,需要什么条件,做哪些准备:小编就这些问题找到了阿里技术团队中在一线真正带Java开发团队并直接参与技术面试的专家,分享了自身在筛 ...
- 实战java虚拟机的学习计划图(看懂java虚拟机)
啥也不说了,实战java虚拟机,好好学习,天天向上!针对自己的软肋制定学习计划. 一部分内容看完,自己做的学习笔记和感想. 学java很简单,但懂java会有难度,如果你的工资还没超过1W,那是时候深 ...
- Java 入门课程视频实战-0基础 上线了,猜拳游戏,ATM实战,欢迎围观
Java 入门课程视频实战-0基础 已经上传完了.欢迎小伙伴们过来围观 直接进入: http://edu.csdn.net/course/detail/196 课程文件夹例如以下: 1 初识Java ...
- JAVA程序员必看的15本书-JAVA自学书籍推荐
作为Java程序员来说,最痛苦的事情莫过于可以选择的范围太广,可以读的书太多,往往容易无所适从.我想就我自己读过的技术书籍中挑选出来一些,按照学习的先后顺序,推荐给大家,特别是那些想不断提高自己技术水 ...
- 轻量级Java EE企业应用实战(第4版):Struts 2+Spring 4+Hibernate整合开发(含CD光盘1张)
轻量级Java EE企业应用实战(第4版):Struts 2+Spring 4+Hibernate整合开发(含CD光盘1张)(国家级奖项获奖作品升级版,四版累计印刷27次发行量超10万册的轻量级Jav ...
- [译] 第三十天:Play Framework - Java开发者梦寐以求的框架 - 百花宫
前言 30天挑战的最后一天,我决定学习 Play Framework .我本来想写Sacla,但是研究几个小时后,我发现没法在一天内公正评价Scala,下个月花些时间来了解并分享经验.本文我们先来看看 ...
- 成为Java顶尖高手要看的11本书
成为Java顶尖高手要看的11本书 学习的最好途径就是看书",这是我自己学习并且小有了一定的积累之后的第一体会.个人认为看书有两点好处: 1.能出版出来的书一定是经过反复的思考.雕琢和审核的 ...
随机推荐
- Zabbix Timeout 设置不当导致的问题
哈喽大家好,我是咸鱼 今天跟大家分享一个关于 zabbix Timeout 值设置不当导致的问题,这个问题不知道大家有没有碰到过 问题 事情经过是这样的: 把某一台 zabbix agent 的模板由 ...
- Linux下Redis集群部署
一.Redis集群介绍 Redis 集群是一个提供在多个Redis节点间共享数据的程序集.Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性 ...
- FlutterWeb部署到服务器
目标:把flutter web项目部署到自己的服务器上,可以使用自己的服务器IP访问 前提:服务器已经安装了nginx, 这是我的flutter配置 edz@lwqdeMacBook-Pro ~ % ...
- .NET Core 3.1使用docker打包并部署
目录 简介 环境介绍 开发环境 部署环境 编写Dockerfile文件 生成Docker镜像 运行容器 访问接口 结语 简介 本文主要说明使用.NET Core 3.1搭建的站点如何使用docker打 ...
- PTA 21级数据结构与算法实验4—字符串和数组
目录 7-1 字符串模式匹配(KMP) 7-2 [模板]KMP字符串匹配 7-3 统计子串 7-4 好中缀 7-5 病毒变种 7-6 判断对称矩阵 7-7 三元组顺序表表示的稀疏矩阵转置运算Ⅰ 7-8 ...
- docker笔记-安装、操作和Registry
注意事项 强烈建议docker宿主机关闭firewalld,改用iptables 1 docker安装 1.1 离线安装 下载 Docker 二进制文件(https://download.docker ...
- Redis 集群偶数节点跨地域部署之高可用测试
笔者目前所在公司存在多套 Redis 集群: A 集群 主 + 从 共 60 个分片,部署在 3 + 3 台物理机上,每台机器各承载 10 个端口 主库 30 个端口在广州,从库 30 个端口在中山 ...
- Django: request.GET.get()
释义 query = request.GET.get('name', '') 寻找名为name的GET参数,而且如果参数没有提交,返回一个空的字符串. 对比request.GET() 如果使用requ ...
- ROC 曲线与 PR 曲线
ROC 曲线与 PR 曲线 ROC 曲线与 PR 曲线 ROC 曲线和 PR 曲线是评估机器学习算法性能的两条重要曲线,两者概念比较容易混淆,但是两者的使用场景是不同的.本文主要讲述两种曲线的含义以及 ...
- NAT与NAT实验
1.NAT与NAT实验 NAT(网络地址翻译) 一个数据包目的ip或者源ip为私网地址, 运营商的设备无法转发数据. 实际场景问题 如下图 201.0.0.1 公网地址? 买的 运营商给你的19 ...