Batch Normalization 批量归一化的运算过程
Batch Normalization 批量归一化
具体的运算过程:
假设经过卷积计算过后得到的feature map的尺寸为 2*3*2*2。
其中2代表的是batch的大小,3代表的是通道channel的个数,2*2代表的是feature map的长和宽。
对应图片如下所示:

过程:我们要对batch中的每一个通道channel中的元素求均值和方差,对于这里而言,就是2*2*2 这8个数相加再除以8得到元素的均值。方差根据公式进行计算。这一步完成之后得到方差和均值。
下一步,对这8个元素中的每一个元素分别进行 这个数减去均值和方差,得到的数乘以γ+β。
对应的公式如下所是:
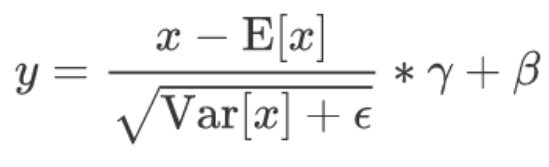
然后,对于每一个BN层,均值和方差只是对应channel的。每个channel都有一个,不能混用。
PS:最终经过BN层计算之后得到一个什么东西呢?
效果:
1、训练过程中遇到收敛速度很慢的问题时,可以通过引入BN层来加快网络模型的收敛速度。
2、遇到梯度消失或者梯度爆炸的问题时,可以考虑引入BN层来解决。
3、一般情况下,还可以通过引入BN层来加快网络的训练速度。
代码如下所是:
import torch
from torch import nn
# 在(0-1)范围内随机生成数据
# 其中2代表的是batch的大小
# 3代表的是通道channel的个数
# 2*2代表的是feature map的长和宽。
random_data=torch.rand(2,3,2,2)
# BatchNorm2d(3) 这里的3代表输入的通道数
bn=nn.BatchNorm2d(3)
ater_bn=bn(random_data)
# 随机生成的数据
print(random_data)
# BN之后的数据
print(ater_bn)
随机生成的图:4维的 2*3*2*2 全是 0到1之间的数据

BN之后的图:4维的 2*3*2*2
完结,撒花!!
Batch Normalization 批量归一化的运算过程的更多相关文章
- Batch Normalization批量归一化
BN的深度理解:https://www.cnblogs.com/guoyaohua/p/8724433.html BN: BN的意义:在激活函数之前将输入归一化到高斯分布,控制到激活函数的敏感区域,避 ...
- Batch Normalization 批量标准化
本篇博文转自:https://www.cnblogs.com/guoyaohua/p/8724433.html Batch Normalization作为最近一年来DL的重要成果,已经广泛被证明其有效 ...
- 激活函数,Batch Normalization和Dropout
神经网络中还有一些激活函数,池化函数,正则化和归一化函数等.需要详细看看,啃一啃吧.. 1. 激活函数 1.1 激活函数作用 在生物的神经传导中,神经元接受多个神经的输入电位,当电位超过一定值时,该神 ...
- 转载-通俗理解BN(Batch Normalization)
转自:参数优化方法 1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Prep ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- batch normalization学习理解笔记
batch normalization学习理解笔记 最近在Andrew Ng课程中学到了Batch Normalization相关内容,通过查阅资料和原始paper,基本上弄懂了一些算法的细节部分,现 ...
- Neural Network模型复杂度之Batch Normalization - Python实现
背景介绍 Neural Network之模型复杂度主要取决于优化参数个数与参数变化范围. 优化参数个数可手动调节, 参数变化范围可通过正则化技术加以限制. 本文从参数变化范围出发, 以Batch No ...
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- 从头学pytorch(十九):批量归一化batch normalization
批量归一化 论文地址:https://arxiv.org/abs/1502.03167 批量归一化基本上是现在模型的标配了. 说实在的,到今天我也没搞明白batch normalize能够使得模型训练 ...
- 【深度学习】批归一化(Batch Normalization)
BN是由Google于2015年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中"梯度弥散"的问题,从而使得训练深层网 ...
随机推荐
- MyBatis-plus自动填充功能
1.什么是mp的自动填充?这个功能是做什么的呢? 有的时候,我们可能有这样子的需求,在插入(insert)或者更新数据(update)的时候可以自动填充数据,比如密码,version等.在mp中为我们 ...
- PostgreSQL 12 文档: 部分 II. SQL 语言
部分 II. SQL 语言 这部份描述在PostgreSQL中SQL语言的使用.我们从描述SQL的一般语法开始,然后解释如何创建保存数据的结构.如何填充数据库以及如何查询它.中间的部分列出了在SQL命 ...
- influxdb常用sql总结
本文为博主原创,转载请注明出处: 1.登录influxdb influx -username admin -password "password" 2.查看数据库 ##查看有哪些数 ...
- Go 并发模型—Goroutines
前言 Goroutines 是 Go 语言主要的并发原语.它看起来非常像线程,但是相比于线程它的创建和管理成本很低.Go 在运行时将 goroutine 有效地调度到真实的线程上,以避免浪费资源,因此 ...
- Semantic Kernel(语义内核)秋季路线图
Semantic Kernel 是一个开源的 SDK,它允许开发人员将大型语言模型(LLM)与传统的编程语言进行混合使用. 微软Semantic Kernel团队 在博客上正式公布了Semantic ...
- quarkus实战之二:应用的创建、构建、部署
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<quarkus实战>系列 ...
- Llama2开源大模型的新篇章以及在阿里云的实践
Llama一直被誉为AI社区中最强大的开源大模型.然而,由于开源协议的限制,它一直不能被免费用于商业用途.然而,这一切在7月19日发生了改变,当Meta终于发布了大家期待已久的免费商用版本Llama2 ...
- 模型部署 — PaddleNLP 基于 Paddle Serving 快速使用(服务化部署 - Docker)— 图像识别 + 信息抽取(UIE-X)
目录 流程 版本 安装 Docker 安装 PaddleNLP 安装 环境准备 模型准备 压缩模型 下载模型 模型部署 环境配置 启动服务 测试 -- 暂时还没通过 重启 图像识别 + 信息抽取(UI ...
- FAQ:Linux 查看服务器型号(R730为例)
命令:dmidecode -t system | grep -e Manufacturer -e Product 查询结果: Manufacturer: Dell Inc. Product Name: ...
- Django: 获取头信息
如何获取请求头信息 使用如下函数request.META.get("HTTP_请求头函数"),需要注意的是,请求头变量需要全部大写. 其他注意事项如下所示: 如果headerkey ...