why’s kafka so fast
As we all know that Kafka is very fast, much faster than most of its competitors. So what’s the reason here?
Avoid Random Disk Access
Kafka writes everything onto the disk in order and consumers fetch data in order too. So disk access always works sequentially instead of randomly. For traditional hard disks(HDD), sequential access is much faster than random access. Here is a comparison:
| hardware | sequential writes | random writes |
|---|---|---|
| 6 * 7200rpm SATA RAID-5 | 300MB/s | 50KB/s |
Kafka Writes Everything Onto The Disk Instead of Memory
Yes, you read that right. Kafka writes everything onto the disk instead of memory. But wait a moment, isn’t memory supposed to be faster than disks? Typically it’s the case, for Random Disk Access. But for sequential access, the difference is much smaller. Here is a comparison taken from https://queue.acm.org/detail.cfm?id=1563874.

As you can see, it’s not that different. But still, sequential memory access is faster than Sequential Disk Access, why not choose memory? Because Kafka runs on top of JVM, which gives us two disadvantages.
1.The memory overhead of objects is very high, often doubling the size of the data stored(or even higher).
2.Garbage Collection happens every now and then, so creating objects in memory is very expensive as in-heap data increases because we will need more time to collect unused data(which is garbage).
So writing to file systems may be better than writing to memory. Even better, we can utilize MMAP(memory mapped files) to make it faster.
Memory Mapped Files(MMAP)
Basically, MMAP(Memory Mapped Files) can map the file contents from the disk into memory. And when we write something into the mapped memory, the OS will flush the change onto the disk sometime later. So everything is faster because we are using memory actually, but in an indirect way. So here comes the question. Why would we use MMAP to write data onto disks, which later will be mapped into memory? It seems to be a roundabout route. Why not just write data into memory directly? As we have learned previously, Kafka runs on top of JVM, if we wrote data into memory directly, the memory overhead would be high and GC would happen frequently. So we use MMAP here to avoid the issue.
Zero Copy
Suppose that we are fetching data from the memory and sending them to the Internet. What is happening in the process is usually twofold.
1.To fetch data from the memory, we need to copy those data from the Kernel Context into the Application Context.
2.To send those data to the Internet, we need to copy the data from the Application Context into the Kernel Context.
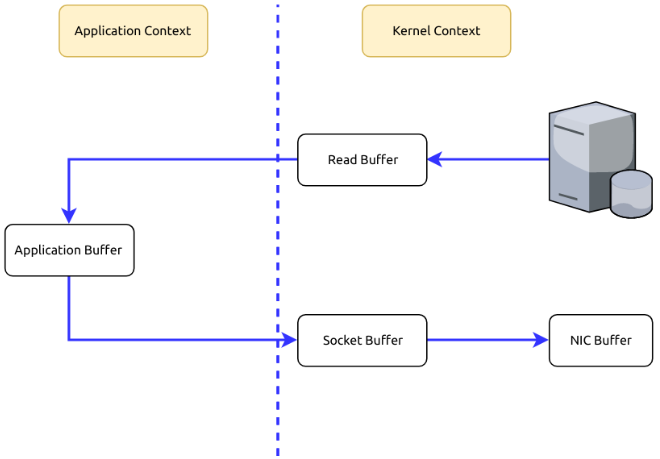
As you can see, it’s redundant to copy data between the Kernel Context and the Application Context. Can we avoid it? Yes, using Zero Copy we can copy data directly from the Kernel Context to the Kernel Context.

Batch Data
Kafka only sends data when batch.size is reached instead of one by one. Assuming the bandwidth is 10MB/s, sending 10MB data in one go is much faster than sending 10000 messages one by one(assuming each message takes 100 bytes).
"I would be fine and made no troubles."
why’s kafka so fast的更多相关文章
- Apache Kafka for Item Setup
At Walmart.com in the U.S. and at Walmart's 11 other websites around the world, we provide seamless ...
- Apache Kafka - Schema Registry
关于我们为什么需要Schema Registry? 参考, https://www.confluent.io/blog/how-i-learned-to-stop-worrying-and-love- ...
- Understanding, Operating and Monitoring Apache Kafka
Apache Kafka is an attractive service because it's conceptually simple and powerful. It's easy to un ...
- Build an ETL Pipeline With Kafka Connect via JDBC Connectors
This article is an in-depth tutorial for using Kafka to move data from PostgreSQL to Hadoop HDFS via ...
- How to choose the number of topics/partitions in a Kafka cluster?
This is a common question asked by many Kafka users. The goal of this post is to explain a few impor ...
- kafka producer源码
producer接口: /** * Licensed to the Apache Software Foundation (ASF) under one or more * contributor l ...
- Flume-ng+Kafka+storm的学习笔记
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- Apache Kafka: Next Generation Distributed Messaging System---reference
Introduction Apache Kafka is a distributed publish-subscribe messaging system. It was originally dev ...
- Exploring Message Brokers: RabbitMQ, Kafka, ActiveMQ, and Kestrel--reference
[This article was originally written by Yves Trudeau.] http://java.dzone.com/articles/exploring-mess ...
随机推荐
- java 学习 进阶之 一 (线程基础)
一.线程安全 线程安全的概念:当多个线程访问某一个类(对象或方法)时.这个类始终都能表现出正确的行为那么这个类(对象或方法)就是线程安全的. synchronized:可以在任何对象及方法上加锁,而加 ...
- java 微信自定义菜单 java微信接口开发 公众平台 SSM redis shiro 多数据源
A 调用摄像头拍照,自定义裁剪编辑头像,头像图片色度调节B 集成代码生成器 [正反双向](单表.主表.明细表.树形表,快速开发利器)+快速表单构建器 freemaker模版技术 ,0个代码不用写,生成 ...
- JDK1.8 —— 接口定义增强
使用default和static定义接口方法 JDK1.8(jre8)以后,接口中不在仅仅只允许定义抽象方法,开始允许定义普通方法了:而普通方法需要用default声明. interface IMes ...
- SolidWorks 2020新增功能之性能提升
SolidWorks解决方案组合的新功能和增强功能将帮助您最大程度地提高设计和制造资源的生产率,同时使您能够更快地交付创新产品.现在我们很激动地告诉你,三维设计SolidWorks 3D CAD 2 ...
- PMP备考-第三章-项目管理过程
过程:完成预定目标的,一系列相互关联的活动的集合,以便运用一些列工具与技术把特定的输入转化成特定的输出. 五大项目管理过程组:启动-规划-执行-监控-收尾 戴明环(PDCA循环):计划-实施-检查-行 ...
- Jmeter接口测试与数据驱动
一. 背景 数据驱动Data Driven Testing(DDT),是一种用于创建自动化测试的方法,或者说是一种架构, 本质是输入数据和用这些数据获取测试结果, 使测试逻辑和测试数据分离. DDT的 ...
- Fundebug后端Node.js插件更新至0.2.0,支持监控Express慢请求
摘要: 性能问题也是BUG,也需要监控. Fundebug后端Node.js异常监控服务 Fundebug是专业的应用异常监控平台,我们Node.js插件fundebug-nodejs可以提供全方位的 ...
- 便宜的回文 (USACO 2007)(c++)
2019-08-21便宜的回文(USACO 2007) 内存限制:128 MiB 时间限制:1000 ms 标准输入输出 题目类型:传统 评测方式:文本比较 题目描述 追踪每头奶牛的去向是一件棘手的任 ...
- React中ref的三种用法 可以用来获取表单中的值 这一种类似document.getXXId的方式
import React, { Component } from "react" export default class MyInput extends Component { ...
- pdfium 之二
https://www.foxitsoftware.cn/products/premium-pdfium/feature.php 基于谷歌PDFium开源代码 谷歌采用福昕的PDF技术为其PDF开源项 ...