CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术
对同一个对象不去update,而且记录下每一次的不同版本的值
存在不会消失,新值并不能抹杀原先的存在
所以update操作并不是对世界的真实反映,这是一种便于应用的简化实现

MVCC的历史可以追溯到70年代,数据库的主流技术大部分都停滞在那个年代
MVCC,可以解决2PC的频繁读写冲突;使用MVCC只有写写才会存在冲突,大大降低了冲突的概率
而且MVCC还能进行time-travel


例子,DB中有Begin,End表示该version生效的时间周期,write的时候会产生新的version,同时修改上一个version的end
右图,仍然读的是A0,因为t1的ts=1,在A0的范围中

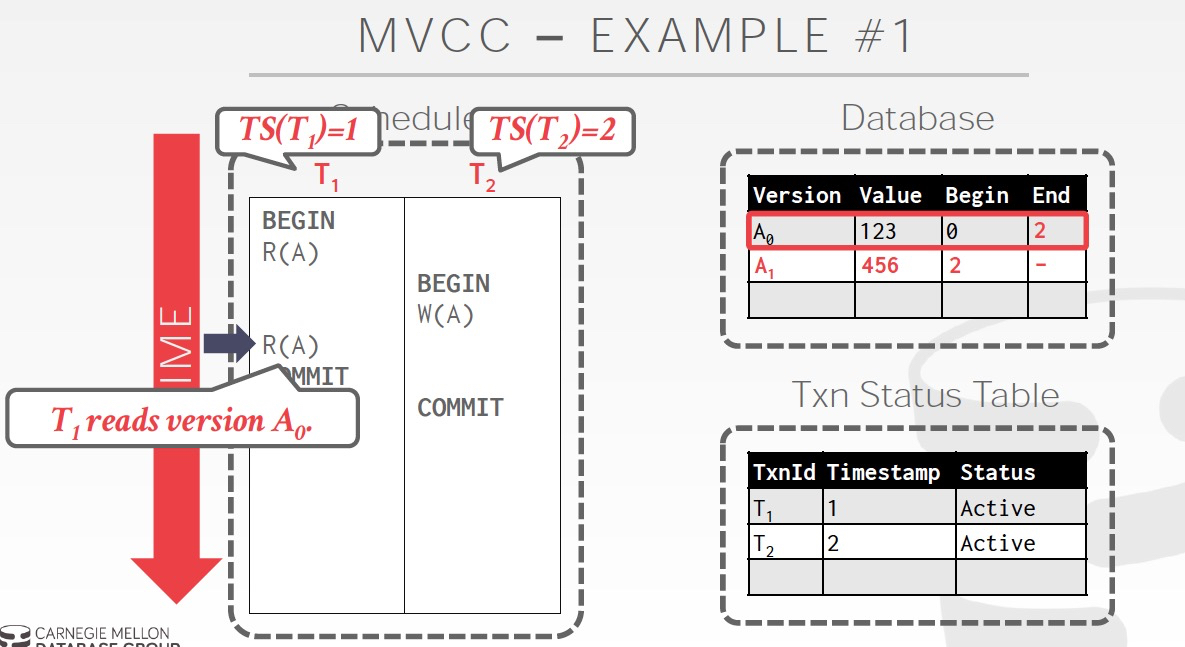
例子,
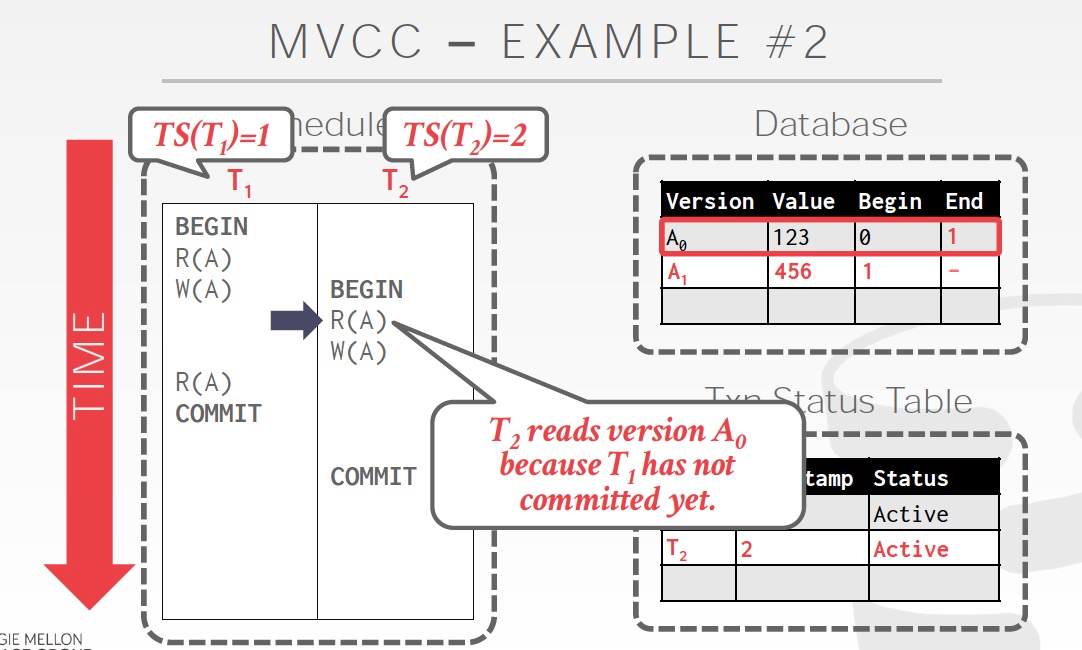
T2的R读到的是A0,因为T1还没有commit(取决于隔离程度) ;并且T2执行W的时候会锁等,因为写写发生冲突
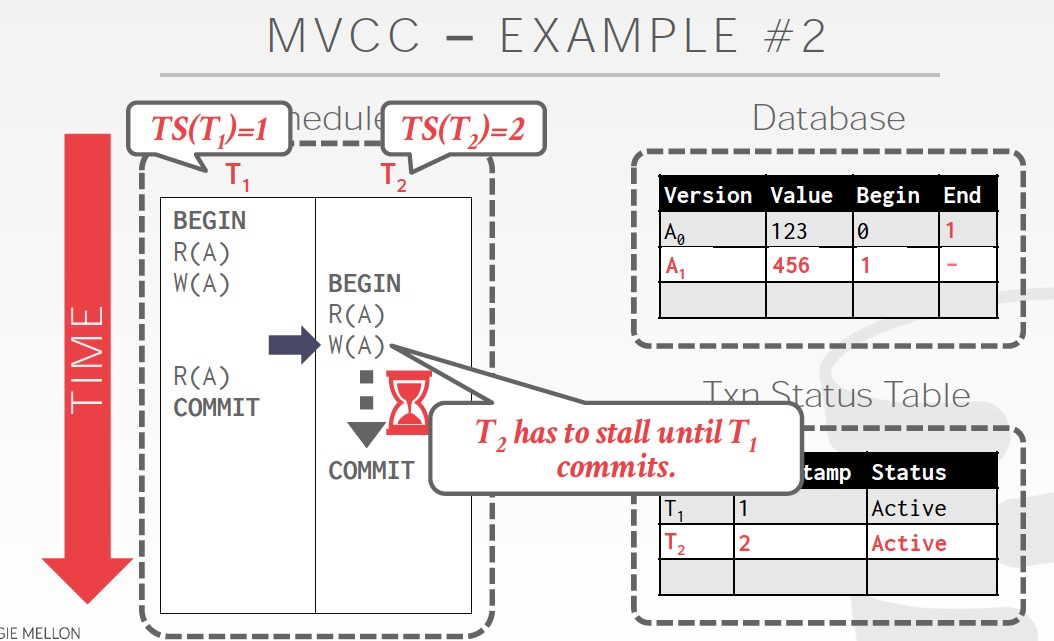
当T1 commit后,T2的锁释放,开始写入
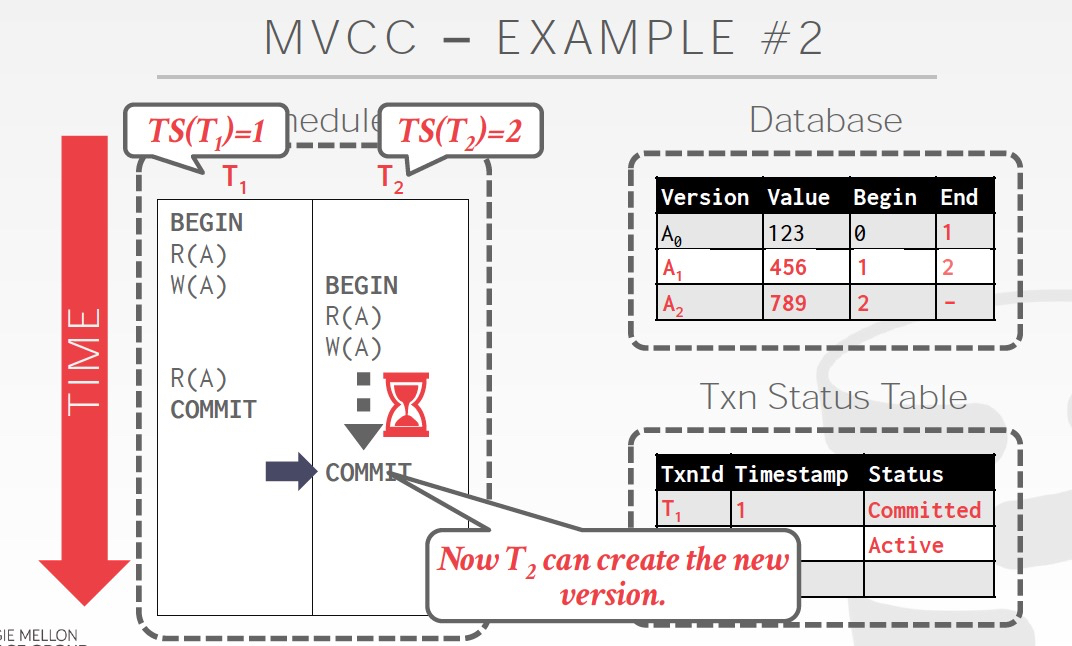
这时候的行为取决于隔离程度,如果serializable的,那么T2会失败,因为T2读的是A0,而这时看T2应该读的是A1,所以存在不一致
下面的图表明MVCC被大量的数据库所使用,

MVCC在发生写写冲突时,仍然是需要并发控制协议,主要是之前学习的2PC或OCC

多版本的存储方式,主要有如下的方式,


Append Only,比较直接的方式,HBase,PG都是采用这种方式
为了快速找到同一个对象的多个版本,可以用链表来组织,那么旧的放前面,还是新的放见面,完全是看场景
新的放前面比较直觉,因为一般都是需要读最新的数据,但是这样每次新增都需要更新head指针
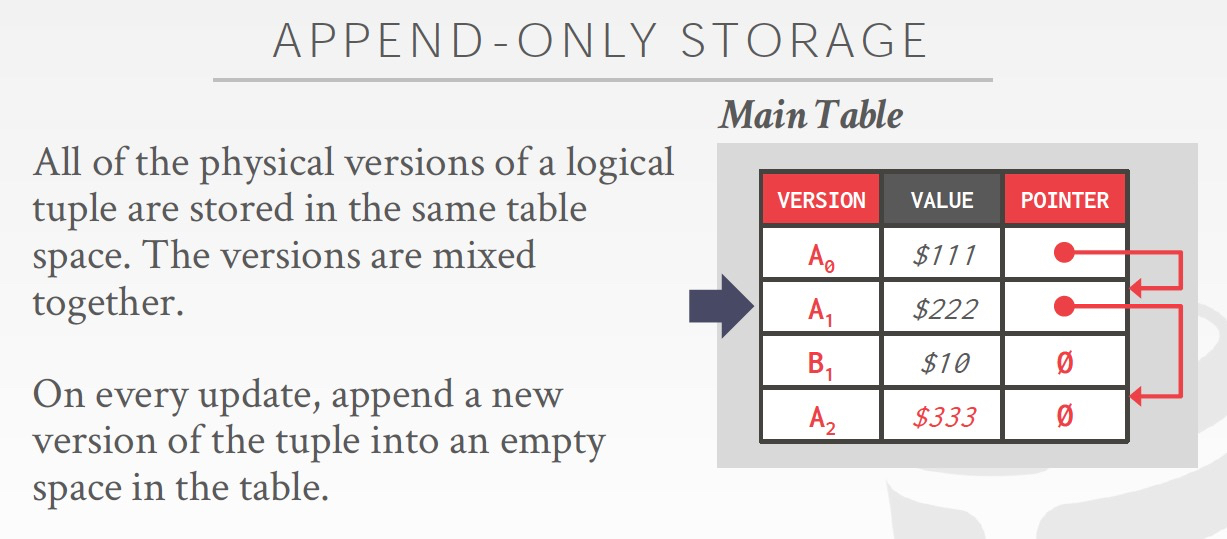

Time travel就是把最新的table和历史table分离
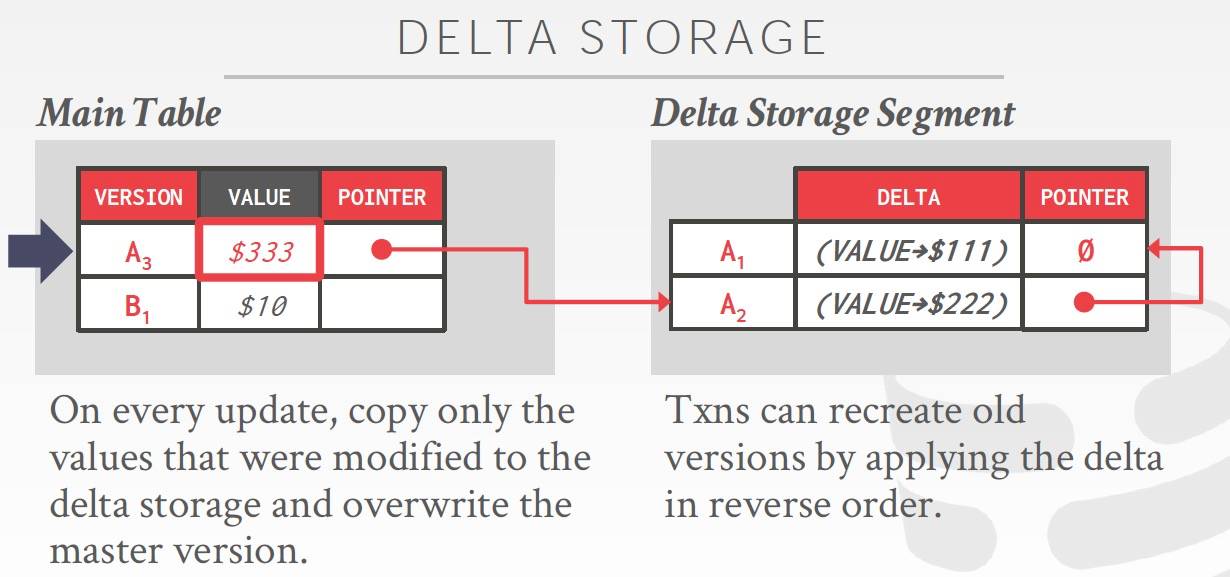
Delta只记录差值

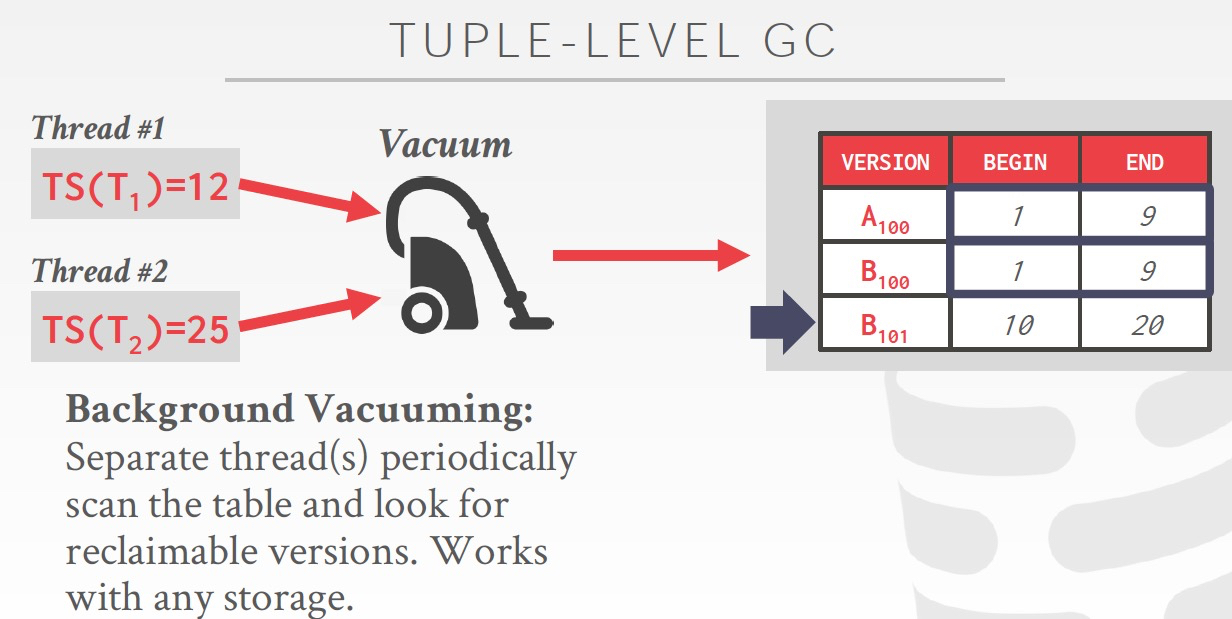
垃圾回收,纯粹是工程实践,


定期过期活跃thread已经不用时间段的数据,这里有个设计是,加上Bitmap来表示这个page是否有更新,这样Vacumm不用去检查每个page,没更新的就不用检查
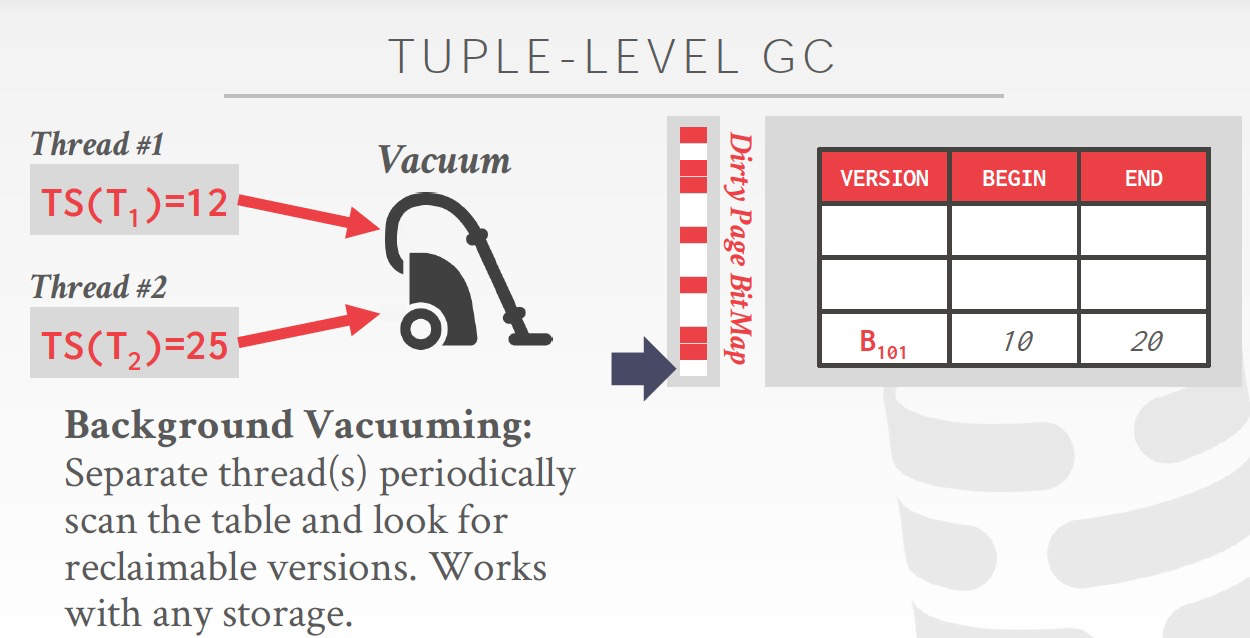
Worker thread在遍历的时候,随便找到过期的

如果用MVCC,那么index就需要指向chain head
可以看到对于secondary index,如果有很多,每次head变化都要更新很多,非常低效


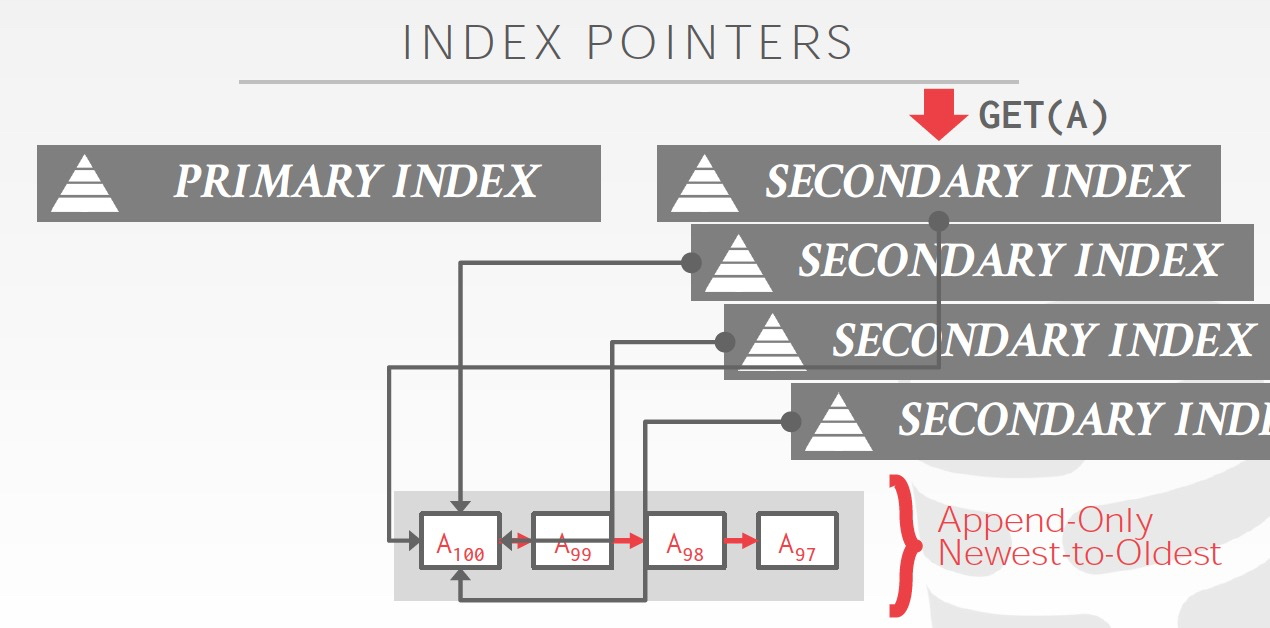
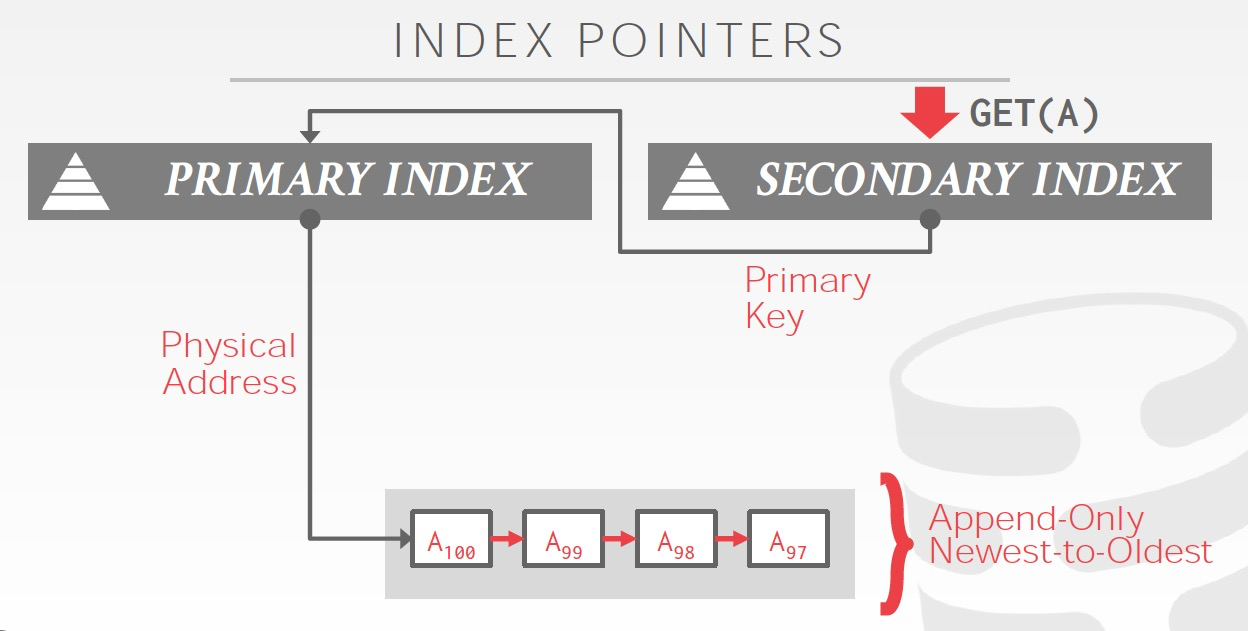
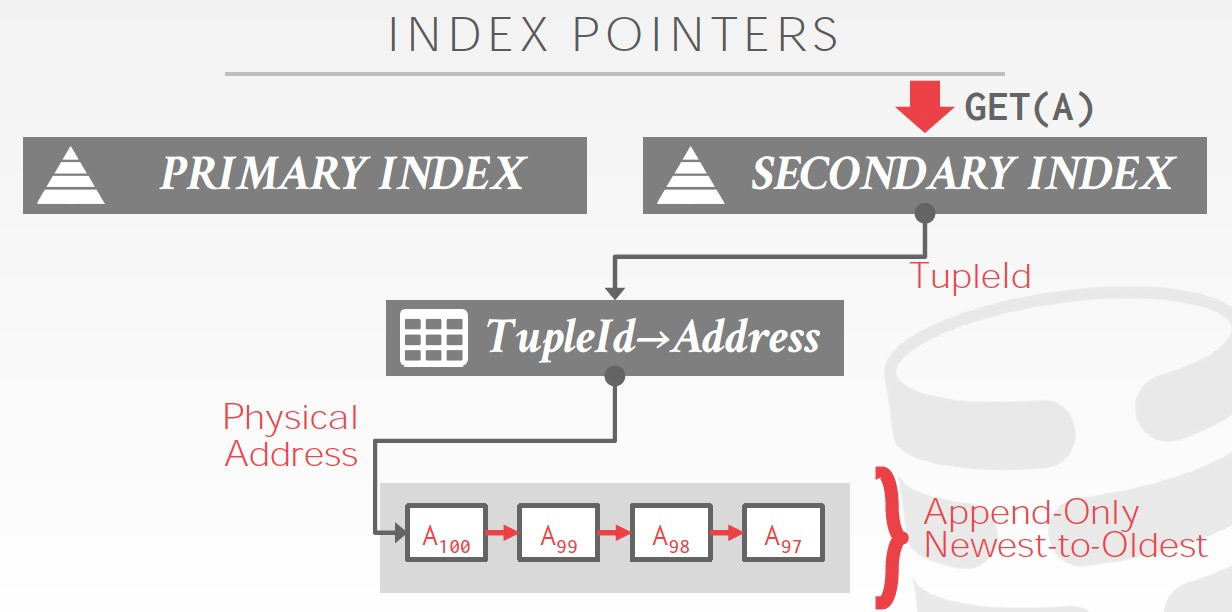
所以有两种方式,
思路都是,通过逻辑id,间接的指向Physical address,这样只需要改一个地方
这里列出所有数据库在MVCC上的实现方式

CMU Database Systems - MVCC的更多相关文章
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - Embedded Database Logic
正常应用和数据库交互的过程是这样的, 其实我们也可以把部分应用逻辑放到DB端去执行,来提升效率 User-defined Function Stored Procedures Triggers Cha ...
- CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性 先区分一组概念,parallel和distributed的区别 总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不 ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
随机推荐
- ES读写索引内幕分析
一.简介 ES中的索引都进行分片,每个分片都会保存多个副本.这些副本称为复制组,在添加或删除索引时必须同步副本.如果不这样,从不同的副本中读取的索引可能截然不同.保持分片副本同步并从中提供读取的过程被 ...
- php操作mysql,1分钟内插入百万数据
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_33862644/article/d ...
- 什么影响了mysql的性能-存储引擎层
5.6版本以前默认是MyISam存储引擎,5.6版本之后默认支持的Innodb存储引擎,这两种也是最常用的. 存储引擎层 MyISAM 5.5之前版本默认存储引擎 存储引擎表由MYD和MYI组成 特性 ...
- 191017 虚拟机centos修改IP
1. 虚拟机设置 1.1 编辑-->虚拟机网络编辑器-->VMnet8-->更改设置-->DHCP设置取消打勾 -->选择NAT模式,查看网关IP 2. 本地网络设置 更 ...
- Tensorflow简单实践系列(一):安装和运行
TensorFlow 是谷歌开发的机器学习框架. 安装 TensorFlow 直接使用 pip 安装即可,添加豆瓣镜像可以加快速度: pip install tensorflow -i https:/ ...
- docker学习2-快速搭建centos7-python3.6环境
前言 当我们在一台电脑上搭建了python3.6的环境,下次换了个电脑,或者换成linux的系统了,又得重新搭建一次,设置环境变量.下载pip等操作. 好不容易安装好,一会Scrips目录找不到pip ...
- 黑马2017年java就业班全套视频教程
黑马程序员培训班 黑马2017年java就业班全套视频教程 ava学习路线图.pptx等多个文件 - 2019-07-20 10:03 老师分享的资料 - 2019-07-20 10:03 ...
- Dubbo源码分析:Filter
类图 Filter链 在ProtocolFilterWrapper对象中完成Filter完成组建. 实现代码
- Windows用户模式调试内部组件
简介 允许用户模式调试工作的内部机制很少得到充分的解释.更糟糕的是,这些机制在Windows XP中已经发生了根本性的变化,当许多支持被重新编写时,还通过将ntdll中的大多数例程作为本地API的一部 ...
- 虚拟变量和独热编码的区别(Difference of Dummy Variable & One Hot Encoding)
在<定量变量和定性变量的转换(Transform of Quantitative & Qualitative Variables)>一文中,我们可以看到虚拟变量(Dummy Var ...