Classification and Decision Trees
分类和决策树(DT)。
决策树是预测建模机器学习的一种重要算法。
决策树模型的表示是二叉树。就是算法和数据结构中的二叉树,没什么特别的。每个节点表示一个单独的输入变量(x)和该变量上的左右孩子(假设变量为数值)。
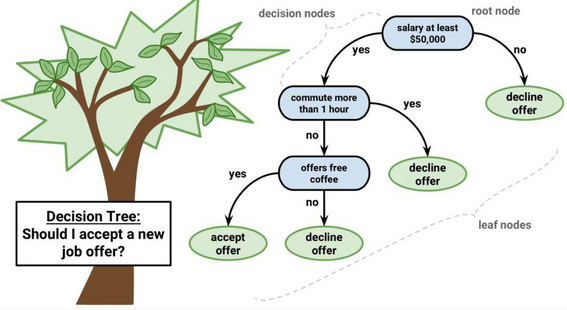
树的叶节点包含一个输出变量(y),用于进行预测。通过遍历树,直到到达叶节点并输出叶节点的类值,就可以做出预测。
树的学习速度很快,预测的速度也很快。它们通常也适用于广泛的问题,不需要对数据进行任何特别的准备。
决策树有很高的方差,并且可以在使用时产生更准确的预测。
特点及应用
决策树的特点是它总是在沿着特征做切分。随着层层递进,这个划分会越来越细。
虽然生成的树不容易给用户看,但是数据分析的时候,通过观察树的上层结构,能够对分类器的核心思路有一个直观的感受。
举个简单的例子,当我们预测一个孩子的身高的时候,决策树的第一层可能是这个孩子的性别。男生走左边的树进行进一步预测,女生则走右边的树。这就说明性别对身高有很强的影响。
因为DT能够生成清晰的基于特征(feature)选择不同预测结果的树状结构,数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。
同时它也是相对容易被攻击的分类器。这里的攻击是指人为的改变一些特征,使得分类器判断错误。常见于垃圾邮件躲避检测中。因为决策树最终在底层判断是基于单个条件的,攻击者往往只需要改变很少的特征就可以逃过监测。
受限于它的简单性,决策树更大的用处是作为一些更有用的算法的基石。
优点:
1.概念简单,计算复杂度不高,可解释性强,输出结果易于理解;
2.数据的准备工作简单, 能够同时处理数据型和常规型属性,其他的技术往往要求数据属性的单一。
3.对中间值得确实不敏感,比较适合处理有缺失属性值的样本,能够处理不相关的特征;
4.应用范围广,可以对很多属性的数据集构造决策树,可扩展性强。决策树可以用于不熟悉的数据集合,并从中提取出一些列规则 这一点强于KNN。
缺点:
1.容易出现过拟合;
2.对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
3. 信息缺失时处理起来比较困难。 忽略数据集中属性之间的相关性。
Classification and Decision Trees的更多相关文章
- Logistic Regression vs Decision Trees vs SVM: Part II
This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees ...
- Logistic Regression Vs Decision Trees Vs SVM: Part I
Classification is one of the major problems that we solve while working on standard business problem ...
- Machine Learning Methods: Decision trees and forests
Machine Learning Methods: Decision trees and forests This post contains our crib notes on the basics ...
- 壁虎书6 Decision Trees
Decision Trees are versatile Machine Learning algorithms that can perform both classification and re ...
- Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍
xgboost的可以参考:https://xgboost.readthedocs.io/en/latest/gpu/index.html 整体看加速5-6倍的样子. Gradient Boosting ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
- 机器学习算法 --- Decision Trees Algorithms
一.Decision Trees Agorithms的简介 决策树算法(Decision Trees Agorithms),是如今最流行的机器学习算法之一,它即能做分类又做回归(不像之前介绍的其他学习 ...
- Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)
https://www.quora.com/Why-do-people-use-gradient-boosted-decision-trees-to-do-feature-transform Why ...
- CatBoost使用GPU实现决策树的快速梯度提升CatBoost Enables Fast Gradient Boosting on Decision Trees Using GPUs
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
随机推荐
- Django框架之第四篇(视图层)--HttpRequest对象、HttpResponse对象、JsonResponse、CBV和FBV、文件上传
视图层 一.视图函数 一个视图函数,简称视图,是一个简单的python函数,它接收web请求并且会返回web响应.响应可以是一张网页的html,一个重定向,或者是一张图片...任何东西都可以.无论是什 ...
- android studio下 library打包文件(.aar)和本地引用
关键点: 利用Gradle发布本地maven库支持android library 打包文件(*.aar) 的本地引用 开发环境: windows7 64位操作系统 android studio0.5. ...
- 打家劫舍I
题目描述(LeetCode) 你是一个专业的小偷,计划偷窃沿街的房屋.每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系 ...
- golang ---cron
package main import ( l4g "github.com/alecthomas/log4go" "github.com/robfig/cron" ...
- 在Visual Studio 2019中安装Blend 4.5 SDK
Visual Studio 2017安装时可以指定Blend SDK,到Visual Studio 2019时,安装时已经没有这个选项了. 官方提供的只有老版本4.0的安装包.要使用Blend SDK ...
- nrm的安装和使用
1.安装nodejs,下载地址,http://nodejs.cn/download/,安装过程直接点击下一步即可 安装完成后cmd输入npm -v 查看当前安装的npm的版本,如下图提示所示则表示安装 ...
- sleep方法动态打印 C语言
#include<Windows.h> #include<stdio.h> #include<stdlib.h> #include<string.h> ...
- highcharts离线导出图表
到了这里,其实还没有结束,导出图片时,仍会发出两个请求 此时找到offline-exporting.js文件修改其中的libURL 修改为请求自己的网站
- 在Centos中安装.net core SDK
在Linux中运行.net core 项目必须要有.net core SDK 环境.之前配置过几次,但由于没有做总结.过了几天又配置的时候 感觉特别陌生,今天就记录一次.net core SDK 的安 ...
- Go内存分配器可视化指南【译】【精】
当我第一次开始尝试理解 Go 语言的内存分配器时,整个过程让我抓狂.一切看起来都像一个神秘的黑盒子.因为几乎所有技术魔法(technical wizardry)都隐藏在抽象之下,所以你需要一层一层的剥 ...