线程池的使用(ThreadPoolExecutor详解)
为什么要使用线程池?
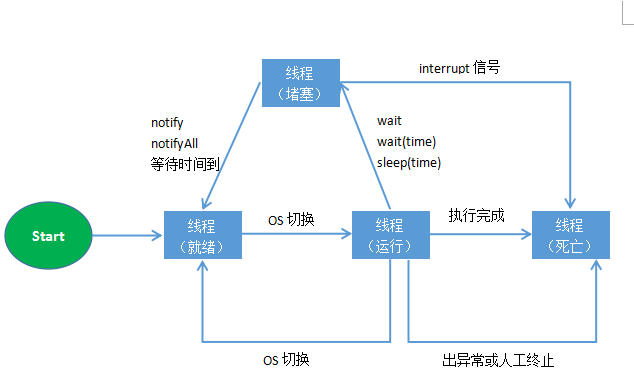
线程是一个操作系统概念。操作系统负责这个线程的创建、挂起、运行、阻塞和终结操作。而操作系统创建线程、切换线程状态、终结线程都要进行CPU调度——这是一个耗费时间和系统资源的事情。
另一方面,大多数实际场景中是这样的:处理某一次请求的时间是非常短暂的,但是请求数量是巨大的。这种技术背景下,如果我们为每一个请求都单独创建一个线程,那么物理机的所有资源基本上都被操作系统创建线程、切换线程状态、销毁线程这些操作所占用,用于业务请求处理的资源反而减少了。所以最理想的处理方式是,将处理请求的线程数量控制在一个范围,既保证后续的请求不会等待太长时间,又保证物理机将足够的资源用于请求处理本身。
另外,一些操作系统是有最大线程数量限制的。当运行的线程数量逼近这个值的时候,操作系统会变得不稳定。这也是我们要限制线程数量的原因。
线程池的基本使用方式
JAVA语言为我们提供了两种基础线程池的选择:ScheduledThreadPoolExecutor和ThreadPoolExecutor。它们都实现了ExecutorService接口(注意,ExecutorService接口本身和“线程池”并没有直接关系,它的定义更接近“执行器”,而“使用线程管理的方式进行实现”只是其中的一种实现方式)。这篇文章中,我们主要围绕ThreadPoolExecutor类进行讲解。
ThreadPoolExecutor类的使用方式:
public class PoolThreadSimple {
public static void main(String[] args) throws Throwable {
/* * corePoolSize:核心大小,线程池初始化的时候,就会有这么大 * maximumPoolSize:线程池最大线程数 * keepAliveTime:如果当前线程池中线程数大于corePoolSize。 * 多余的线程,在等待keepAliveTime时间后如果还没有新的线程任务指派给它,它就会被回收 * * unit:等待时间keepAliveTime的单位 * * workQueue:等待队列。这个对象的设置是本文将重点介绍的内容 * */
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 10, 1, TimeUnit.MINUTES, new SynchronousQueue());
for (int index = 0; index < 10; index++) {
poolExecutor.submit(new PoolThreadSimple.TestRunnable(index));
}
}
/**
* 这个就是测试用的线程
*/
private static class TestRunnable implements Runnable {
/**
* 日志
*/
private static Log LOGGER = LogFactory.getLog(TestRunnable.class);
/**
* 记录任务的唯一编号,这样在日志中好做识别
*/
private Integer index;
public TestRunnable(int index) {
this.index = index;
}
/**
* @return the index
*/
public Integer getIndex() {
return index;
}
@Override
public void run() {
/* * 线程中,就只做一件事情: * 等待60秒钟的事件,以便模拟业务操作过程 * */
Thread currentThread = Thread.currentThread();
TestRunnable.LOGGER.info("线程:" + currentThread.getId() + " 中的任务(" + this.getIndex() + ")开始执行===");
synchronized (currentThread) {
try {
currentThread.wait(60000);
} catch (InterruptedException e) {
TestRunnable.LOGGER.error(e.getMessage(), e);
}
}
TestRunnable.LOGGER.info("线程:" + currentThread.getId() + " 中的任务(" + this.getIndex() + ")执行完成");
}
}
}
下文中,将对线程池中的corePoolSize、maximumPoolSize、keepAliveTime、timeUnit、workQueue、threadFactory、handler参数和一些常用/不常用的设置项进行逐一讲解。
ThreadPoolExecutor逻辑结构和工作方式
在上面的代码中,我们创建线程池的时候使用了ThreadPoolExecutor中最简单的一个构造函数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue)
构造函数中需要传入的参数包括corePoolSize、maximumPoolSize、keepAliveTime、timeUnit和workQueue。要明确理解这些参数(和后续将要介绍的参数)的含义,就首先要搞清楚ThreadPoolExecutor线程池的逻辑结构。 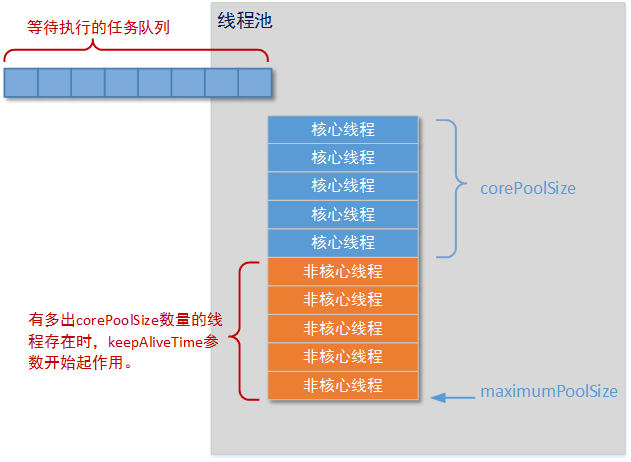
一定要注意一个概念,即存在于线程池中容器的一定是Thread对象,而不是你要求运行的任务(所以叫线程池而不叫任务池也不叫对象池);你要求运行的任务将被线程池分配给某一个空闲的Thread运行。
从上图中,我们可以看到构成线程池的几个重要元素:
● 等待队列:顾名思义,就是你调用线程池对象的submit()方法或者execute()方法,要求线程池运行的任务(这些任务必须实现Runnable接口或者Callable接口)。但是出于某些原因线程池并没有马上运行这些任务,而是送入一个队列等待执行。
● 核心线程:线程池主要用于执行任务的是“核心线程”,“核心线程”的数量是你创建线程时所设置的corePoolSize参数决定的。如果不进行特别的设定,线程池中始终会保持corePoolSize数量的线程数(不包括创建阶段)。
● 非核心线程:一旦任务数量过多(由等待队列的特性决定),线程池将创建“非核心线程”临时帮助运行任务。你设置的大于corePoolSize参数小于maximumPoolSize参数的部分,就是线程池可以临时创建的“非核心线程”的最大数量。这种情况下如果某个线程没有运行任何任务,在等待keepAliveTime时间后,这个线程将会被销毁,直到线程池的线程数量重新达到corePoolSize。
● maximumPoolSize参数也是当前线程池允许创建的最大线程数量。那么如果设置的corePoolSize参数和设置的maximumPoolSize参数一致时,线程池在任何情况下都不会回收空闲线程。keepAliveTime和timeUnit也就失去了意义。
● keepAliveTime参数和timeUnit参数也是配合使用的。keepAliveTime参数指明等待时间的量化值,timeUnit指明量化值单位。例如keepAliveTime=1,timeUnit为TimeUnit.MINUTES,代表空闲线程的回收阀值为1分钟。
说完了线程池的逻辑结构,下面我们讨论一下线程池是怎样处理某一个运行任务的。
1、首先可以通过线程池提供的submit()方法或者execute()方法,要求线程池执行某个任务。线程池收到这个要求执行的任务后,会有几种处理情况:
1.1、如果当前线程池中运行的线程数量还没有达到corePoolSize大小时,线程池会创建一个新的线程运行你的任务,无论之前已经创建的线程是否处于空闲状态。
1.2、如果当前线程池中运行的线程数量已经达到设置的corePoolSize大小,线程池会把你的这个任务加入到等待队列中。直到某一个的线程空闲了,线程池会根据设置的等待队列规则,从队列中取出一个新的任务执行。
1.3、如果根据队列规则,这个任务无法加入等待队列。这时线程池就会创建一个“非核心线程”直接运行这个任务。注意,如果这种情况下任务执行成功,那么当前线程池中的线程数量一定大于corePoolSize。
1.4、如果这个任务,无法被“核心线程”直接执行,又无法加入等待队列,又无法创建“非核心线程”直接执行,且你没有为线程池设置RejectedExecutionHandler。这时线程池会抛出RejectedExecutionException异常,即线程池拒绝接受这个任务。(实际上抛出RejectedExecutionException异常的操作,是ThreadPoolExecutor线程池中一个默认的RejectedExecutionHandler实现:AbortPolicy,这在后文会提到)
2、一旦线程池中某个线程完成了任务的执行,它就会试图到任务等待队列中拿去下一个等待任务(所有的等待任务都实现了BlockingQueue接口,按照接口字面上的理解,这是一个可阻塞的队列接口),它会调用等待队列的poll()方法,并停留在哪里。
3、当线程池中的线程超过你设置的corePoolSize参数,说明当前线程池中有所谓的“非核心线程”。那么当某个线程处理完任务后,如果等待keepAliveTime时间后仍然没有新的任务分配给它,那么这个线程将会被回收。线程池回收线程时,对所谓的“核心线程”和“非核心线程”是一视同仁的,直到线程池中线程的数量等于你设置的corePoolSize参数时,回收过程才会停止。
不常用的设置
在ThreadPoolExecutor线程池中,有一些不常用的甚至不需要的设置
allowCoreThreadTimeOut:
线程池回收线程只会发生在当前线程池中线程数量大于corePoolSize参数的时候;当线程池中线程数量小于等于corePoolSize参数的时候,回收过程就会停止。
allowCoreThreadTimeOut设置项可以要求线程池:将包括“核心线程”在内的,没有任务分配的任何线程,在等待keepAliveTime时间后全部进行回收:
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 10, TimeUnit.MINUTES, new ArrayBlockingQueue(1)); poolExecutor.allowCoreThreadTimeOut(true);
以下是设置前的效果: 
以下是设置后的效果:
prestartAllCoreThreads
前文我们还讨论到,当线程池中的线程还没有达到你设置的corePoolSize参数值的时候,如果有新的任务到来,线程池将创建新的线程运行这个任务,无论之前已经创建的线程是否处于空闲状态。这个描述可以用下面的示意图表示出来: 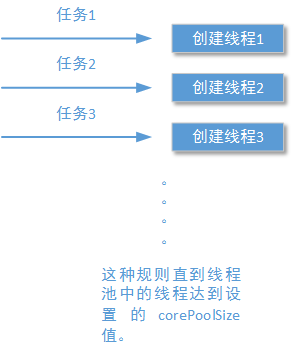
prestartAllCoreThreads设置项,可以在线程池创建,但还没有接收到任何任务的情况下,先行创建符合corePoolSize参数值的线程数:
ThreadPoolExecutor poolExecutor =new
ThreadPoolExecutor(5,10,1,
TimeUnit.MINUTES, new
ArrayBlockingQueue<Runnable>(1));
poolExecutor.prestartAllCoreThreads();
我们继续讨论ThreadPoolExecutor线程池。上面给出的最简单的ThreadPoolExecutor线程池的使用方式中,我们只采用了ThreadPoolExecutor最简单的一个构造函数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue)
实际上ThreadPoolExecutor线程池有很多种构造函数,其中最复杂的一种构造函数是:
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
在上文中我们还没有介绍的workQueue、threadFactory和handler参数,将是本文讲解的重点。
一:ThreadFactory的使用
线程池最主要的一项工作,就是在满足某些条件的情况下创建线程。而在ThreadPoolExecutor线程池中,创建线程的工作交给ThreadFactory来完成。要使用线程池,就必须要指定ThreadFactory。
类似于上文中,如果我们使用的构造函数时并没有指定使用的ThreadFactory,这个时候ThreadPoolExecutor会使用一个默认的ThreadFactory:DefaultThreadFactory。(这个类在Executors工具类中)
当然,在某些特殊业务场景下,还可以使用一个自定义的ThreadFactory线程工厂,如下代码片段:
java.util.concurrent.ThreadFactory;
/**
* 测试自定义的一个线程工厂
*/
public class TestThreadFactory implements ThreadFactory {
@Override
public Thread newThread(Runnable r) {
return new Thread(r);
}
}
二:线程池的等待队列
在使用ThreadPoolExecutor线程池的时候,需要指定一个实现了BlockingQueue接口的任务等待队列。在ThreadPoolExecutor线程池的API文档中,一共推荐了三种等待队列,它们是:SynchronousQueue、LinkedBlockingQueue和ArrayBlockingQueue;
队列和栈
● 队列:是一种特殊的线性结构,允许在线性结构的前端进行删除/读取操作;允许在线性结构的后端进行插入操作;这种线性结构具有“先进先出”的操作特点: 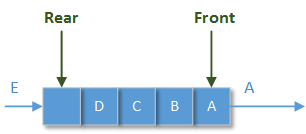
但是在实际应用中,队列中的元素有可能不是以“进入的顺序”为排序依据的。例如我们将要讲到的PriorityBlockingQueue队列。
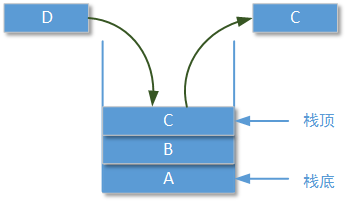
● 栈:栈也是一种线性结构,但是栈和队列相比只允许在线性结构的一端进行操作,入栈和出栈都是在一端完成。
2.1有限队列
● SynchronousQueue:
“是这样 一种阻塞队列,其中每个 put 必须等待一个 take,反之亦然。同步队列没有任何内部容量。翻译一下:这是一个内部没有任何容量的阻塞队列,任何一次插入操作的元素都要等待相对的删除/读取操作,否则进行插入操作的线程就要一直等待,反之亦然。
ronousQueue<Object> queue = new SynchronousQueue<Object>(); // 不要使用add,因为这个队列内部没有任何容量,所以会抛出异常“IllegalStateException” //
queue.add(new Object());
// 操作线程会在这里被阻塞,直到有其他操作线程取走这个对象
queue.put(new Object());
● ArrayBlockingQueue:
一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。新元素插入到队列的尾部,队列获取操作则是从队列头部开始获得元素。这是一个典型的“有界缓存区”,固定大小的数组在其中保持生产者插入的元素和使用者提取的元素。一旦创建了这样的缓存区,就不能再增加其容量。试图向已满队列中放入元素会导致操作受阻塞;试图从空队列中提取元素将导致类似阻塞。
们创建了一个ArrayBlockingQueue,并且设置队列空间为2
ArrayBlockingQueue<Object> arrayQueue = new ArrayBlockingQueue<Object>(2);
// 插入第一个对象 arrayQueue.put(new Object());
// 插入第二个对象 arrayQueue.put(new Object());
// 插入第三个对象时,这个操作线程就会被阻塞。
arrayQueue.put(new Object());
// 请不要使用add操作,和SynchronousQueue的add操作一样,它们都使用了AbstractQueue中的add实现
2.2无限队列
● LinkedBlockingQueue:
LinkedBlockingQueue是我们在ThreadPoolExecutor线程池中常用的等待队列。它可以指定容量也可以不指定容量。由于它具有“无限容量”的特性,所以我还是将它归入了无限队列的范畴(实际上任何无限容量的队列/栈都是有容量的,这个容量就是Integer.MAX_VALUE)。
LinkedBlockingQueue的实现是基于链表结构,而不是类似ArrayBlockingQueue那样的数组。但实际使用过程中,不需要关心它的内部实现,如果指定了LinkedBlockingQueue的容量大小,那么它反映出来的使用特性就和ArrayBlockingQueue类似了。
LinkedBlockingQueue<Object> linkedQueue = new LinkedBlockingQueue<Object>(2);
linkedQueue.put(new Object()); // 插入第二个对象 linkedQueue.put(new Object()); // 插入第三个对象时,这个操作线程就会被阻塞。 linkedQueue.put(new Object());
者如下使用:
LinkedBlockingQueue<Object> linkedQueue = new LinkedBlockingQueue<Object>();
linkedQueue.put(new Object()); // 插入第二个对象 linkedQueue.put(new Object()); // 插入第N个对象时,都不会阻塞 linkedQueue.put(new Object());
● LinkedBlockingDeque
LinkedBlockingDeque是一个基于链表的双端队列。LinkedBlockingQueue的内部结构决定了它只能从队列尾部插入,从队列头部取出元素;但是LinkedBlockingDeque既可以从尾部插入/取出元素,还可以从头部插入元素/取出元素。
LinkedBlockingDeque linkedDeque = new LinkedBlockingDeque();
// push ,可以从队列的头部插入元素
linkedDeque.push(new TempObject(1));
linkedDeque.push(new TempObject(2));
linkedDeque.push(new TempObject(3));
// poll , 可以从队列的头部取出元素
TempObject tempObject = linkedDeque.poll();
// 这里会打印
tempObject.index = 3 System.out.println("tempObject.index = " + tempObject.getIndex());
// put , 可以从队列的尾部插入元素
linkedDeque.put(new TempObject(4)); linkedDeque.put(new TempObject(5));
// pollLast , 可以从队列尾部取出元素
tempObject = linkedDeque.pollLast();
// 这里会打印
tempObject.index = 5 System.out.println("tempObject.index = " + tempObject.getIndex());
PriorityBlockingQueue
PriorityBlockingQueue是一个按照优先级进行内部元素排序的无限队列。存放在PriorityBlockingQueue中的元素必须实现Comparable接口,这样才能通过实现compareTo()方法进行排序。优先级最高的元素将始终排在队列的头部;PriorityBlockingQueue不会保证优先级一样的元素的排序,也不保证当前队列中除了优先级最高的元素以外的元素,随时处于正确排序的位置。
这是什么意思呢?PriorityBlockingQueue并不保证除了队列头部以外的元素排序一定是正确的。请看下面的示例代码:
PriorityBlockingQueue priorityQueue = new PriorityBlockingQueue();
priorityQueue.put(new TempObject(-5));
priorityQueue.put(new TempObject(5));
priorityQueue.put(new TempObject(-1));
priorityQueue.put(new TempObject(1)); // 第一个元素是5 // 实际上在还没有执行priorityQueue.poll()语句的时候,队列中的第二个元素不一定是1
TempObject targetTempObject = priorityQueue.poll();
System.out.println("tempObject.index = " + targetTempObject.getIndex()); // 第二个元素是1
targetTempObject = priorityQueue.poll();
System.out.println("tempObject.index = " + targetTempObject.getIndex()); // 第三个元素是-1
targetTempObject = priorityQueue.poll();
System.out.println("tempObject.index = " + targetTempObject.getIndex()); // 第四个元素是-5
targetTempObject = priorityQueue.poll();
System.out.println("tempObject.index = " + targetTempObject.getIndex());
// 这个元素类,必须实现Comparable接口
private static class TempObject implements Comparable<TempObject> {
private int index;
public TempObject(int index) {
this.index = index;
}
/**
* @return the index
*/
public int getIndex() {
return index;
} /* (non-Javadoc) * @see java.lang.Comparable#compareTo(java.lang.Object) */
@Override
public int compareTo(TempObject o) {
return o.getIndex() - this.index;
}
}
● LinkedTransferQueue
LinkedTransferQueue也是一个无限队列,它除了具有一般队列的操作特性外(先进先出),还具有一个阻塞特性:LinkedTransferQueue可以由一对生产者/消费者线程进行操作,当消费者将一个新的元素插入队列后,消费者线程将会一直等待,直到某一个消费者线程将这个元素取走,反之亦然。
LinkedTransferQueue的操作特性可以由下面这段代码提现。在下面的代码片段中,有两中类型的线程:生产者和消费者,这两类线程互相等待对方的操作:
/**
* 生产者线程
*/
private static class ProducerRunnable implements Runnable {
private LinkedTransferQueue linkedQueue; public ProducerRunnable(LinkedTransferQueue linkedQueue) {
this.linkedQueue = linkedQueue;
} @Override
public void run() {
for (int index = 1; ; index++
) {
try {
// 向LinkedTransferQueue队列插入一个新的元素 // 然后生产者线程就会等待,直到有一个消费者将这个元素从队列中取走
this.linkedQueue.transfer(new TempObject(index));
} catch (InterruptedException e) {
e.printStackTrace(System.out);
}
}
}
} /**
* 消费者线程
*/
private static class ConsumerRunnable implements Runnable {
private LinkedTransferQueue linkedQueue; public ConsumerRunnable(LinkedTransferQueue linkedQueue
) {
this.linkedQueue = linkedQueue;
} @Override
public void run() {
Thread currentThread = Thread.currentThread();
while (!currentThread.isInterrupted()) {
try { // 等待,直到从LinkedTransferQueue队列中得到一个元素
TempObject targetObject = this.linkedQueue.take();
System.out.println("线程(" + currentThread.getId() + ")取得targetObject.index = " + targetObject.getIndex());
} catch (InterruptedException e) {
e.printStackTrace(System.out);
}
}
}
}
LinkedTransferQueue<TempObject> linkedQueue = new LinkedTransferQueue<TempObject>();
// 这是一个生产者线程 Thread producerThread = new Thread(new ProducerRunnable(linkedQueue));
// 这里有两个消费者线程
Thread consumerRunnable1 = new Thread(new ConsumerRunnable(linkedQueue));
Thread consumerRunnable2 = new Thread(new ConsumerRunnable(linkedQueue)); // 开始运行
producerThread.start(); consumerRunnable1.start(); consumerRunnable2.start();
// 这里只是为了main不退出,没有任何演示含义
Thread currentThread = Thread.currentThread();
synchronized (currentThread)
{
currentThread.wait();
}
三:拒绝任务(handler)
在ThreadPoolExecutor线程池中还有一个重要的接口:RejectedExecutionHandler。当提交给线程池的某一个新任务无法直接被线程池中“核心线程”直接处理,又无法加入等待队列,也无法创建新的线程执行;又或者线程池已经调用shutdown()方法停止了工作;又或者线程池不是处于正常的工作状态;这时候ThreadPoolExecutor线程池会拒绝处理这个任务,触发创建ThreadPoolExecutor线程池时定义的RejectedExecutionHandler接口的实现
在创建ThreadPoolExecutor线程池时,一定会指定RejectedExecutionHandler接口的实现。如果调用的是不需要指定RejectedExecutionHandler接口的构造函数,如:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue)
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue, ThreadFactory threadFactory)
那么ThreadPoolExecutor线程池在创建时,会使用一个默认的RejectedExecutionHandler接口实现,源代码片段如下:
public class ThreadPoolExecutor extends AbstractExecutorService {
/**
* The default rejected execution handler
*/
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
// 可以看到,ThreadPoolExecutor中的两个没有指定RejectedExecutionHandler
// 接口的构造函数,都是使用了一个RejectedExecutionHandler接口的默认实现:
AbortPolicy
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue, ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, defaultHandler);
}
}
实际上,在ThreadPoolExecutor中已经提供了四种可以直接使用的RejectedExecutionHandler接口的实现:
● CallerRunsPolicy:
这个拒绝处理器,将直接运行这个任务的run方法。但是,请注意并不是在ThreadPoolExecutor线程池中的线程中运行,而是直接调用这个任务实现的run方法。源代码如下:
● AbortPolicy:
这个处理器,在任务被拒绝后会创建一个RejectedExecutionException异常并抛出。这个处理过程也是ThreadPoolExecutor线程池默认的RejectedExecutionHandler实现。
● DiscardPolicy:
DiscardPolicy处理器,将会默默丢弃这个被拒绝的任务,不会抛出异常,也不会通过其他方式执行这个任务的任何一个方法,更不会出现任何的日志提示。
● DiscardOldestPolicy:
这个处理器很有意思。它会检查当前ThreadPoolExecutor线程池的等待队列。并调用队列的poll()方法,将当前处于等待队列列头的等待任务强行取出,然后再试图将当前被拒绝的任务提交到线程池执行:
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() {
}
/**
* Executes task r in the caller's thread, unless the executor * has been shut down, in which case the task is discarded. * * @param r the runnable task requested to be executed * @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
实际上查阅这四种ThreadPoolExecutor线程池自带的拒绝处理器实现,您可以发现CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy处理器针对被拒绝的任务并不是一个很好的处理方式。
CallerRunsPolicy在非线程池以外直接调用任务的run方法,可能会造成线程安全上的问题;DiscardPolicy默默的忽略掉被拒绝任务,也没有输出日志或者提示,开发人员不会知道线程池的处理过程出现了错误;DiscardOldestPolicy中e.getQueue().poll()的方式好像是科学的,但是如果等待队列出现了容量问题,大多数情况下就是这个线程池的代码出现了BUG。最科学的的还是AbortPolicy提供的处理方式:抛出异常,由开发人员进行处理。
线程池的使用(ThreadPoolExecutor详解)的更多相关文章
- 【java】之常用四大线程池用法以及ThreadPoolExecutor详解
为什么用线程池? 1.创建/销毁线程伴随着系统开销,过于频繁的创建/销毁线程,会很大程度上影响处-理效率2.线程并发数量过多,抢占系统资源从而导致阻塞3.对线程进行一些简单的管理 在Java中,线程池 ...
- Java常用四大线程池用法以及ThreadPoolExecutor详解
为什么用线程池? 1.创建/销毁线程伴随着系统开销,过于频繁的创建/销毁线程,会很大程度上影响处-理效率 2.线程并发数量过多,抢占系统资源从而导致阻塞 3.对线程进行一些简单的管理 在Java中,线 ...
- java线程池的使用与详解
java线程池的使用与详解 [转载]本文转载自两篇博文: 1.Java并发编程:线程池的使用:http://www.cnblogs.com/dolphin0520/p/3932921.html ...
- Java线程池(ThreadPool)详解
线程五个状态(生命周期): 线程运行时间 假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间. 如果:T1 + T3 远大于 T2,则可以 ...
- 从线程池到synchronized关键字详解
线程池 BlockingQueue synchronized volatile 前段时间看了一篇关于"一名3年工作经验的程序员应该具备的技能"文章,倍受打击.很多熟悉而又陌生的知识 ...
- 【多线程】Java线程池七个参数详解
/** * Creates a new {@code ThreadPoolExecutor} with the given initial * parameters. * * @param coreP ...
- springBoot服务整合线程池ThreadPoolTaskExecutor与@Async详解使用
ThreadPoolExecutor:=======这个是java自己实现的线程池执行类,基本上创建线程池都是通过这个类进行的创建.ThreadPoolTaskExecutor:========这个是 ...
- Java线程池七个参数详解
Java多线程开发时,常常用到线程池技术,这篇文章是对创建java线程池时的七个参数的详细解释. 从源码中可以看出,线程池的构造函数有7个参数,分别是corePoolSize.maximumPoolS ...
- Java—线程池ThreadPoolExecutor详解
引导 要求:线程资源必须通过线程池提供,不允许在应用自行显式创建线程: 说明:使用线程池的好处是减少在创建和销毁线程上所花的时间以及系统资源的开销,解决资源不足的问题.如果不使用线程池,有可能造成系统 ...
- Java线程创建形式 Thread构造详解 多线程中篇(五)
Thread作为线程的抽象,Thread的实例用于描述线程,对线程的操纵,就是对Thread实例对象的管理与控制. 创建一个线程这个问题,也就转换为如何构造一个正确的Thread对象. 构造方法列表 ...
随机推荐
- Docker容器数据管理(数据卷&数据卷容器)
一:前言 在Docker容器的实际使用中,经常会遇到容器的数据持久化,容器之间的数据共享等问题,通常我们有两种解决方案: 1)数据卷(Data Volumes):就是将容器内数据直接映射到本地主机环境 ...
- C语言基础知识---认识C语言
2019.11.09 秋风 晴 最近一直在搞一套LoRa算法.总算有点效果了.心感慰藉(可能用错词语.但是也不管了) 初学者如何理解C语言? 无需刻板理解,笔者常用一个这样的例子助学生理解:法国人和法 ...
- C语言的变参列表 va_list
1. va_list的基本原理和用法 #include<stdio.h> #include<stdarg.h> void func(int i,char *ch,...){ / ...
- php mysqli 预处理操作数据库
用到的SQL表 CREATE TABLE `student_01` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARAC ...
- Mysql向新建表中插入数据, Incorrect string value: '\xE5\xBC\xA0\xE4\xB8\x89' for column 'UserName' at row 1
在本地通过MYSQL创建测试表 CREATE Table User ( UserId int not NULL PRIMARY KEY auto_increment, //主键自增 UserName ...
- loj#10067 构造完全图(最小生成树)
题目 loj#10067 构造完全图 解析 和kruscal类似,我们要构造一个完全图,考虑往这颗最小生成树里加边 我们先把每一条边存下来, 把两个端点分别放在不同的集合内,记录每个集合的大小,然后做 ...
- Fedora 30系统的升级方法
Fedora 30 已经发布了.你可能希望将系统升级到最新版本的 Fedora.Fedora 工作站版本有图形化升级的方法.另外,Fedora 也提供了一个命令行方法,用于将 Fedora 29 升级 ...
- Java框架之MyBatis框架(二)
Mybatis框架是相对于优化dao层的框架,其有效的减少了频繁的连接数据库(在配置文件xml中进行配置),将sql语句与java代码进行分离(写在XXXXmapper.xml文件中,一个表对应一个x ...
- mouseover和mouseenter两个事件的区别
mouseover(鼠标覆盖) mouseenter(鼠标进入) 二者的本质区别在于,mouseenter不会冒泡,简单的说,它不会被它本身的子元素的状态影响到.但是mouseover就会被它的子元素 ...
- Celery:Daemonization
参考文档:http://docs.celeryproject.org/en/latest/userguide/daemonizing.html#daemonizing