Redis采坑(一)——数据无法插入,内存溢出
一、采坑背景
在最大数据分析的过程中,redis是被当做热数据的缓存库使用的,在某一天中,redis数据库热数据无法插入,此时数据量大概在100万左右,很是纠结,为什么不能插入?程序的错误,不可能,没有异常。redis插入数据超时,查看正常。难道是redis的配置问题,试着寻找解决方案,在网上找到了不少类似的问题,今天我们就踩一下!
二、探索问题
(一)、redis内存异常
1、我们这里模拟一下当时异常的redis环境,现在数据库中有27条数据,大概内存占用2.4M左右,我们先把最大内存刻意设置到2M
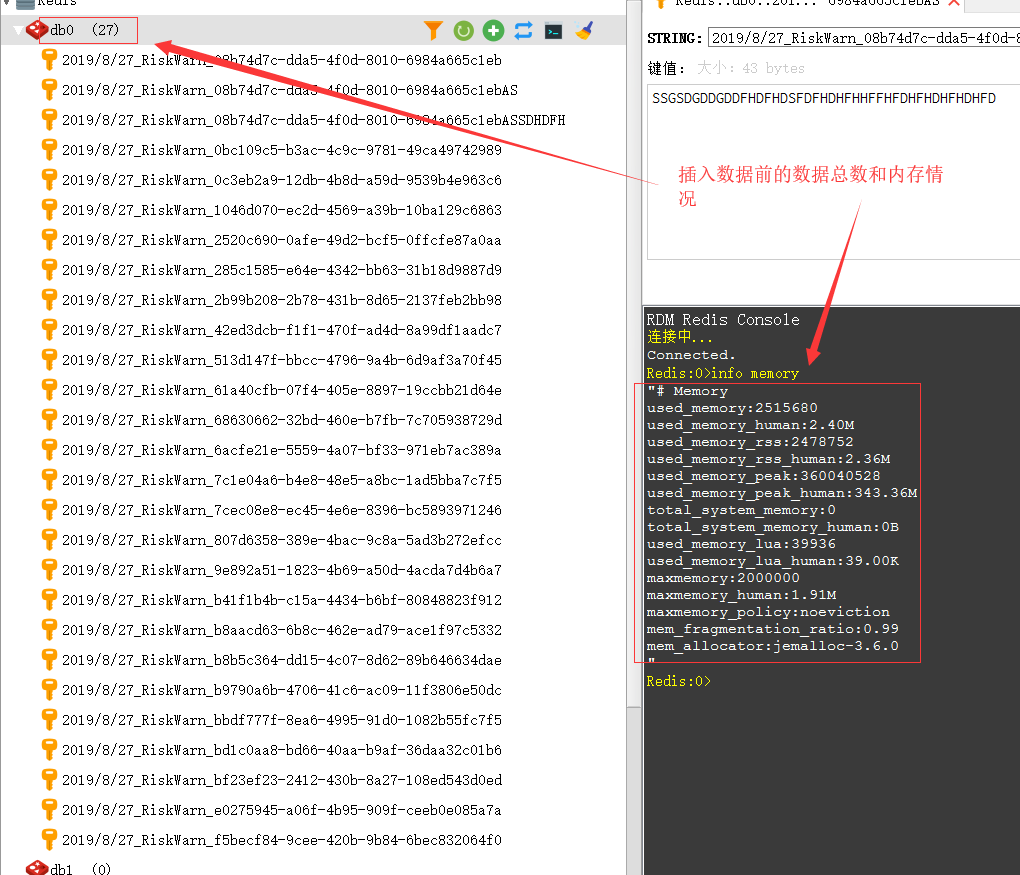
2、现在我们插入新的数据到redis当中
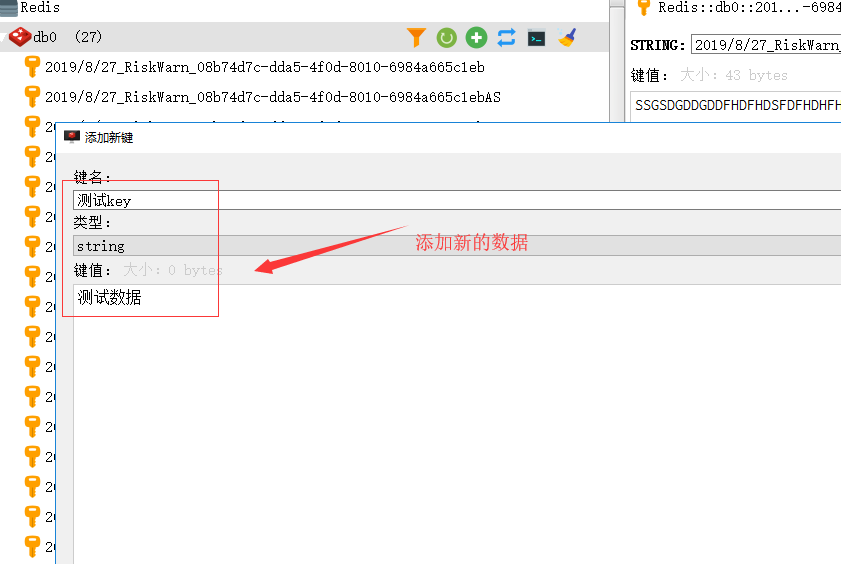
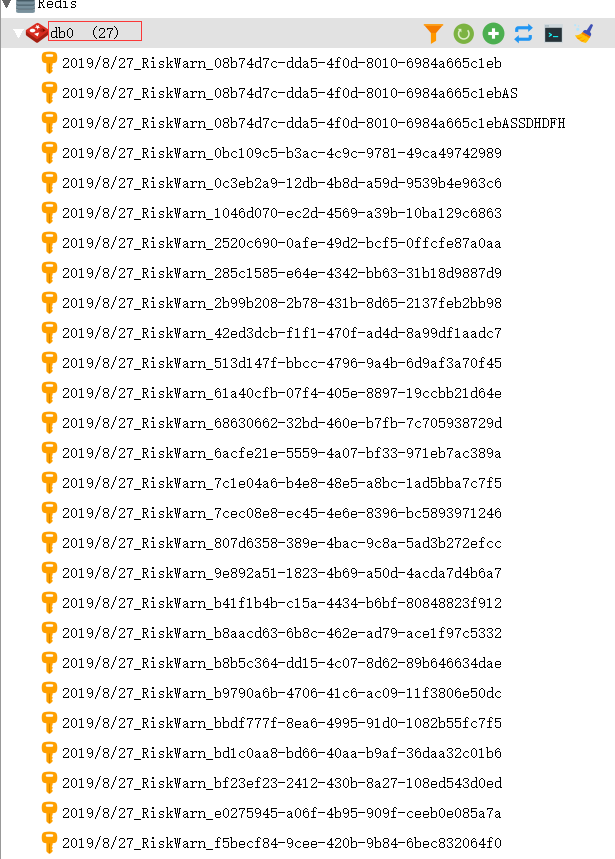
3、查看数据总数,依旧是27条,是不是很奇怪
(二)、redis内存恢复正常
1、现在我们将redis的内存设置到,大于现在已经使用的内存,问题即可解决

2、重新插入数据
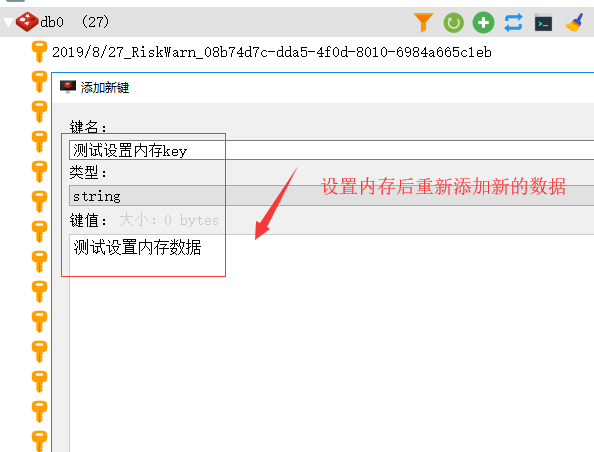
3、数据插入后,显示情况
到此为止,问题解决,我们是不是还有好多疑问,为什么这样就OK了?不要急,接下来给大家分析一下!
三、内存消耗
大家都知道Redis的所有的数据都是存在了内存中的,当最大内存不足以满足现状的情况下,就会出现数据插入异常的情况!,如何查看Redis中内存的消耗情况哪?可以通过 info memory命令,查看Redis内存消耗的相关指标,从而有助于更好的分析内存。执行命令之后有这么几个重要的指标: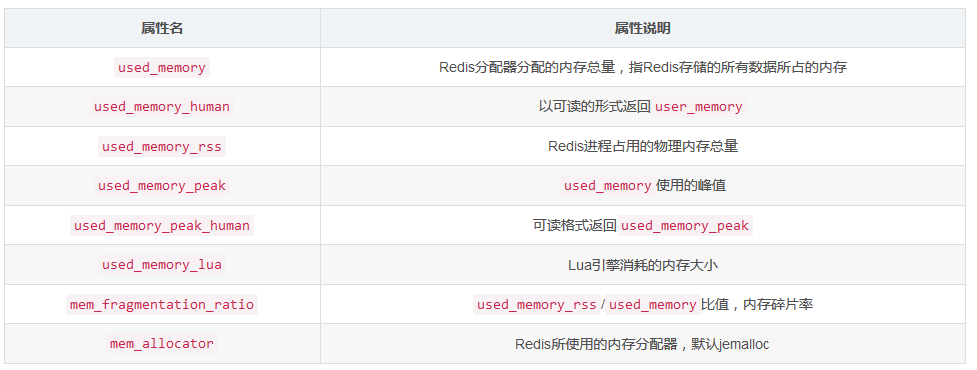
used_memory:
used_memory_human:2.40M
used_memory_rss:
used_memory_rss_human:2.36M
used_memory_peak:
used_memory_peak_human:343.36M
total_system_memory:
total_system_memory_human:0B
used_memory_lua:
used_memory_lua_human:.00K
maxmemory:
maxmemory_human:4.77M
maxmemory_policy:noeviction
mem_fragmentation_ratio:0.99
mem_allocator:jemalloc-3.6.
重点需要关注下mem_fragmentation_ratio这个值:
mem_fragmentation_ratio > 1 说明多出来的部分名没有用于数据存储,而是被内存碎片所消耗,相差越大,说明内存碎片率越严重。
mem_fragmentation_ratio < 1 一般出现在Redis内存交换(Swap)到硬盘导致(used_memory > 可用最大内存时,Redis会把旧的和不适用的数据写入到硬盘,这块空间就叫Swap空间),出现这种情况需要格外关注,硬盘速度远远慢于内存,Redis性能就会变得很差,甚至僵死。
(一)、内存消耗的划分
Redis的内存主要包括:对象内存+缓冲内存+自身内存+内存碎片。
这里写图片描述
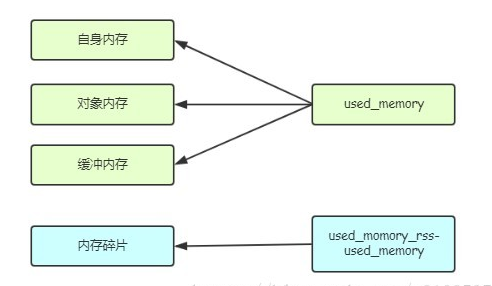
1、对象内存
对象内存是Redis内存中占用最大一块,存储着所有的用户的数据。Redis所有的数据都采用的是key-value型数据类型,每次创建键值对的时候,都要创建两个对象,key对象和value对象。key对象都是字符串,value对象的存储方式,五种数据类型–String,List,Hash,Set,Zset。每种存储方式在使用的时候长度、数据类型不同,则占用的内存就不同。
2、缓冲内存
主要包括:客户端缓冲、复制积压缓冲区、AOF缓冲区
客户端缓冲:普通的客户端的连接(大量连接),从客户端(主要是复制的时候,异地跨机房,或者主节点下有多个从节点),订阅客户端(发布订阅功能,生产大于消费就会造成积压)
复制积压缓冲:2.8版本之后提供的可重用的固定大小缓冲区用于实现部分复制功能,默认1MB,主要是在主从同步时用到。
AOF缓冲区:持久化用的,会先写入到缓冲区,然后根据响应的策略向磁盘进行同步,消耗的内存取决于写入的命令量和重写时间,通常很小。
3、内存碎片
目前可选的分配器有jemalloc、glibc、tcmalloc默认jemalloc
出现高内存碎片问题的情况:大量的更新操作,比如append、setrange;大量的过期键删除,释放的空间无法得到有效利用
解决办法:数据对齐,安全重启(高可用/主从切换)。
4、自身内存
主要指AOF/RDB重写时Redis创建的子进程内存的消耗,Linux具有写时复制技术(copy-on-write),父子进程会共享相同的物理内存页,当父进程写请求时会对需要修改的页复制出一份副本来完成写操作。
四、管理内存
(一)设置上限
Redis默认是无限使用内存。所以在使用的时候尽量的去配置maxmemory,给Redis设置内存使用上限,防止因Redis的无限使用造成系统内存耗尽。有一点需要注意的是maxmemory配置的是Redis实际使用的内存量,即used_memory,由于有内存碎片的存在,所以实际的内存使用比used_memory要大。
Redis可以动态的执行内存的调整:
config set maxmemory 6GB
(二)配置内存回收策略
Redis的内存回收机制主要体现在两个方面上:
对过期数据的处理
当内存使用情况达到maxmemory时触发内存回收策略
1. 过期键的删除
惰性删除:什么时候执行呢?就是在客户端读取带有超时属性的键时,如果已经超过键值设置的过期时间,则删除并返回空。这样做的目的主要是为了节省CPU成本考虑,不需要单独维护TTL链表来处理过期键的删除。但是,如果单独使用这种方式存在一个问题,如果当前的键值永远不再被访问呢?就不删除了吗?那肯定不行,这就会造成内存泄漏的问题。那Redis是怎么解决的呢?Redis提供了一个定时任务的删除机制来做补充。
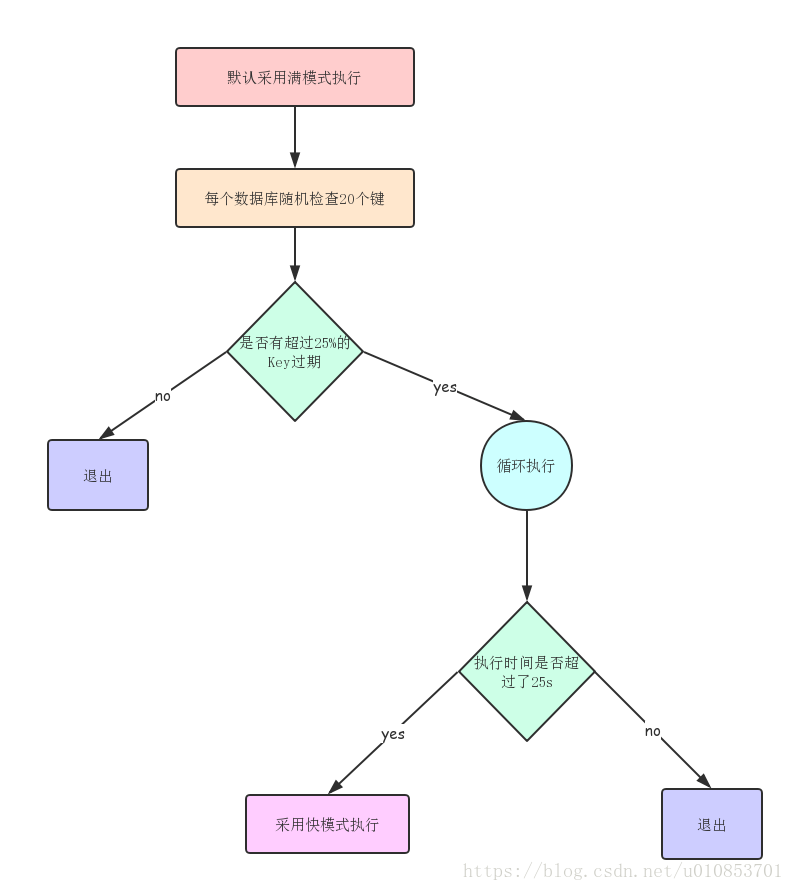
2. 定时任务删除
Redis内部维护了一个定时任务,默认是每秒运行十次。删除的逻辑如下图:
这里写图片描述
3.内存溢出控制策略
当Redis使用的内存达到上限maxmemory后,就会根据maxmemory-policy设置的相关策略进行对应的操作,Redis支持一下6中策略:
Redis采坑(一)——数据无法插入,内存溢出的更多相关文章
- Visual Studio (VC) Win32 程序由于数据大,内存溢出怎么办?
Visual Studio (VC) 内编写的Win32 程序由于数据大,内存溢出,即使转移到64位系统也不行.在国外网站上找到了答案. 原来,只需在project->property中的Lin ...
- 记录一笔关于PHPEXCEL导出大数据超时和内存溢出的问题
通过查阅资料可以找到PHPEXCEL本身已经有通过缓存来处理大数据的导出了.但是昨晚一直没有成功,这可捉急了.最后想来想去就替换了phpExcel的版本了.最后就成功了.话不多说,代码附上 <? ...
- 自己挖的坑自己填--JVM报内存溢出
在写定时任务时,对表数据进行批量操作,测试数据有10万条左右,在测试时发现跑着跑着出现内存溢出现象,最后发现创建的对象paramList 和tmBeanList没有被回收,经过资料查找,发现是循环内不 ...
- 全量导入数据 导致solr内存溢出 崩溃问题解决
在 data-config.xml 文件中 增加一个参数即可: batchSize="-1"
- redis哈希缓存数据表
redis哈希缓存数据表 REDIS HASH可以用来缓存数据表的数据,以后可以从REDIS内存数据库中读取数据. 从内存中取数,无疑是很快的. var FRedis: IRedisClient; F ...
- POI实现大数据EXCLE导入导出,解决内存溢出问题
使用POI能够导出大数据保证内存不溢出的一个重要原因是SXSSFWorkbook生成的EXCEL为2007版本,修改EXCEL2007文件后缀为ZIP打开可以看到,每一个Sheet都是一个xml文件, ...
- 自己挖的坑自己填--jxl进行Excel下载堆内存溢出问题
今天在进行使用 jxl 进行 Excel 下载时,由于数据量大(4万多条接近5万条数据的下载),数据结构过于负责,存在大量大对象(虽然在对象每次用完都设置为null,但还是存在内存溢出问题),加上本地 ...
- Tomcat报内存溢出
1.错误描述 严重:Exception occurred during processing request:null java.lang.reflect.InvocationTar ...
- Java内存溢出异常(上)
上一篇文章我们讲了JVM运行时数据区域与内存溢出异常,其中对于内存溢出异常这部分将的不够详细,这篇文章将着重讲解Java内存溢出异常的相关知识.如果有没看过上一篇文章的小伙伴们,请点击Java内存区域 ...
随机推荐
- synchronized关键字的使用
synchronized关键字是java并发编程中常使用的同步锁,用于锁住方法或者代码块,锁代码块时可以是synchronized(this){}.synchronized(Object){}.syn ...
- 机器学习 | 聚类分析总结 & 实战解析
聚类分析是没有给定划分类别的情况下,根据样本相似度进行样本分组的一种方法,是一种非监督的学习算法.聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度划分为若干组,划分的原则是组内距离最小化 ...
- java-ExceptionHandler全局异常处理
springmvc配置文件: <!-- 定义全局异常处理,只有一个全局异常处理器起作用 --> <bean id="exceptionResolver" clas ...
- AIX安装单实例11gR2 GRID+DB
AIX安装单实例11gR2 GRID+DB 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读和注意事项 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以 ...
- thrift简单示例 (go语言)
这个thrift的简单示例来自于官网 (http://thrift.apache.org/tutorial/go), 因为官方提供的例子简单易懂, 所以没有必要额外考虑新的例子. 关于安装的教程, 可 ...
- MySQL/MariaDB数据库的函数
MySQL/MariaDB数据库的函数 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. MySQL/MariaDB数据库的函数分为系统函数和用户自定义函数(user-define ...
- 如何预防SQL注入?预编译机制
1.预编译机制(一次编译多次执行,防止sql注入) 2.预编译机制
- Java输入流
import java.util.*; //java为小写public class TEST{ public static void main(String args[]){ Scanner inp ...
- sqlserver 智能提示插件
文章:SqlServer智能提示插件SQLPrompt 地址:https://blog.csdn.net/u013628152/article/details/83274478
- Python中str()与repr()函数的区别——repr() 的输出追求明确性,除了对象内容,还需要展示出对象的数据类型信息,适合开发和调试阶段使用
Python中str()与repr()函数的区别 from:https://www.jianshu.com/p/2a41315ca47e 在 Python 中要将某一类型的变量或者常量转换为字符串对象 ...