大数据应用期末总评(hadoop综合大作业)
作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
一、将爬虫大作业产生的csv文件上传到HDFS
(1)在/usr/local路径下创建bigdatacase目录,bigdatacase下创建dataset目录,再在 windows 通过共享文件夹将爬取的census_all_data.csv文件传进 Ubuntu ,使用cp命令讲census_all_data.csv文件复制到/usr/local/bigdatacase/dataset目录下。
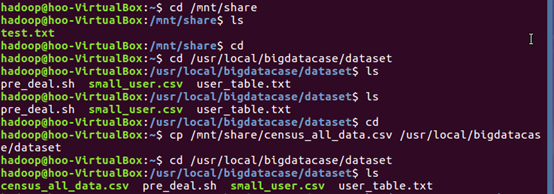
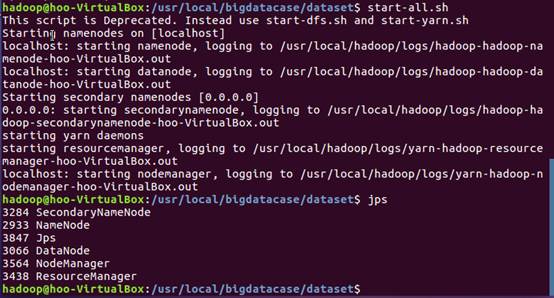
(2)启动服务并用jps命令查看服务启动情况。
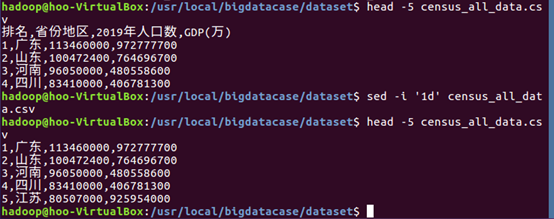
(3)查看文件前五条信息,使用sed命令去掉census_all_data.csv文件的第一行数据,再次查看文件前五条信息。
(4)创建hive目录,将census_all_data.csv文件上传到HDFS。

二、对CSV文件进行预处理生成无标题文本文件
(1)编辑pre_deal_census.sh预处理文件。

(2)pre_deal_census.sh预处理文件内容。

(3)对census_all_data.csv文件进行预处理并生成结果文件census_all_data.txt。

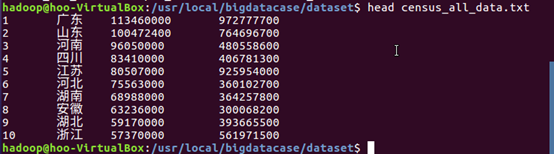
(4)查看处理结果,查看census_all_data.txt文件前十条信息。


三、把hdfs中的文本文件最终导入到数据仓库Hive中
(1)进入数据仓库 hive ,创建并使用censusdb数据库。
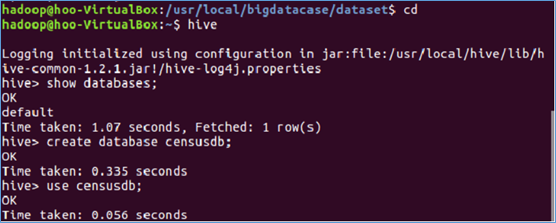
(2)创建表censustb,并为其指定census_all_data.txt文件上传路径为 /hive,将HDFS中的census_all_data.csv文件导入数据仓库hive中。

四、在Hive中查看并分析数据
(1)sql语句查询表censustb所有省份名。
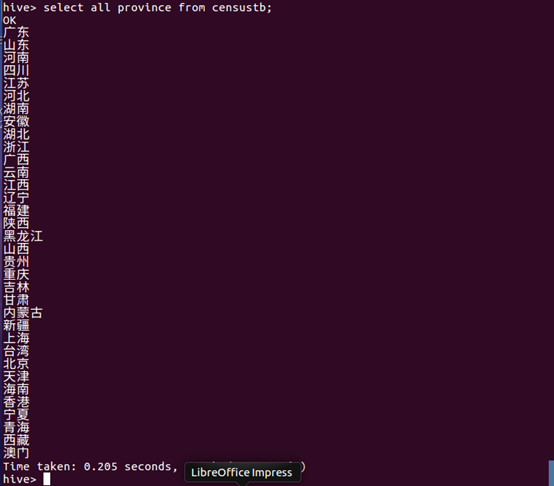
数据分析:censustb表已经按省份的人口数量从大到小排好了序,从查询结果可以看到,我国人口数量最多的省份地区是广东,人口数量最少的省份地区是澳门。
(2)sql语句查询表censustb的前10条信息。
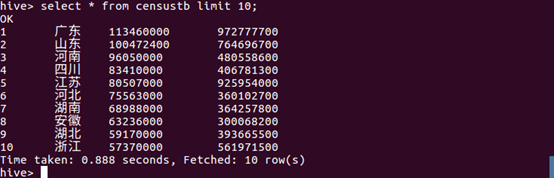
数据分析:从查询结果可知,省份的GDP值与省份的人口数量具有一定的正相关性。
(3)查询censustb表中的信息数量。
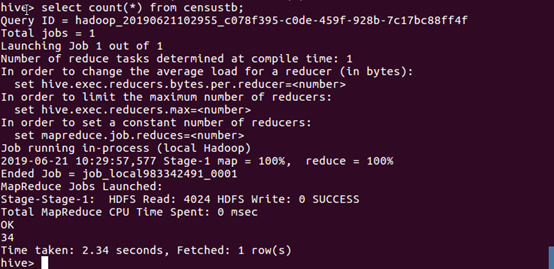
数据分析:从结果可以看出,我国共有34个省级行政区域。
(4)将censustb表排降序,并显示前十条信息中的province和GDP数据。
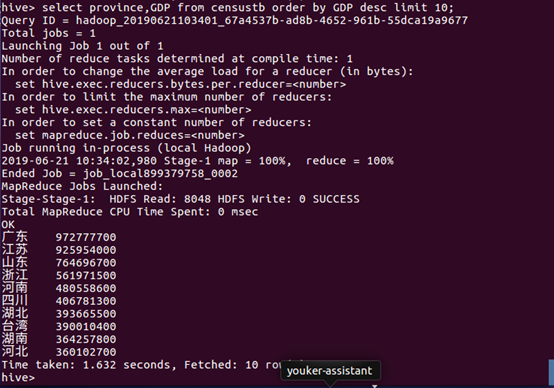
数据分析:从查询的结果可以看出,GDP值最大的省份是广东,其次是江苏,第三是山东。GDP值最大的十个省大都在沿海地区,说明GDP值与沿海的地理位置存在极大的关系。
(5)将人口数大于60000000的省份显示出来。
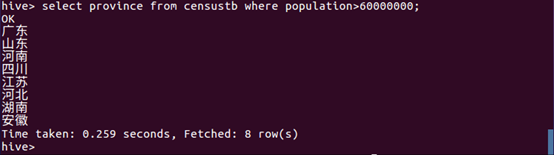
数据分析:从查询结果可以看出,广东、山东、河南、四川、江苏、河北、湖南和安徽这八个省的的人口数量已经超过六千万,结合上面的前十GDP省份可以知道:GDP越大,人数就越多。
(6)将censustb表中省份名与匹配字段相匹配的显示出来。

(7)将censustb表按人口数量排升序并将前五条数据的省份名与人口数量显示出来。
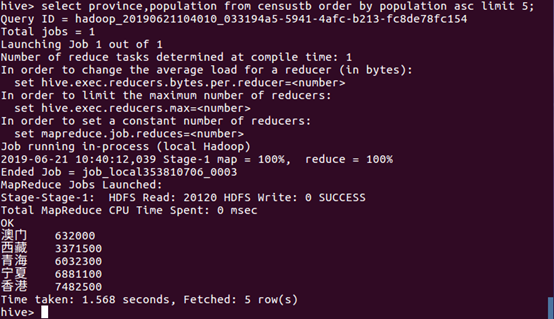
数据分析:从查询结果结果可以看出,人口数量最少的五个省份分别是香港、宁夏、青海、西藏以及澳门。
(8)使用SQL语句计算人口总数。
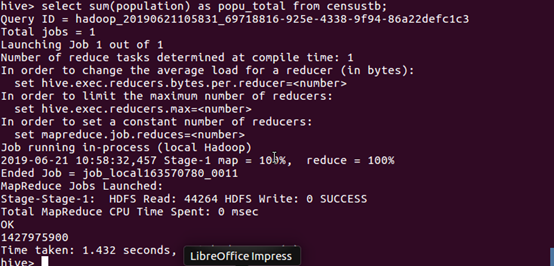
数据分析:从查询结果可以看出,2019年,我国的人口已达近 14.28 亿人,人口基数极大。
(9)显示最大的GDP值。
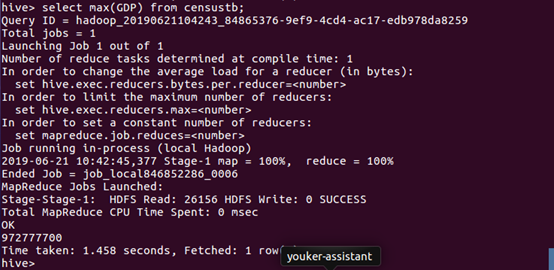
数据分析:在各省份中,最大的GDP值为 972777700 元。
(10)显示最少的人口数量。
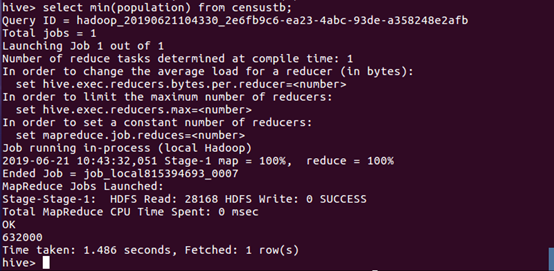
数据分析:从查询结果可知最少人口数量为632000人。
(11)使用SQL语句计算GDP总值。
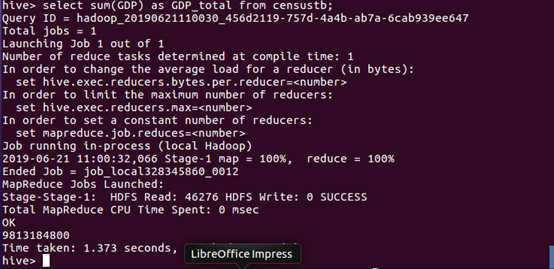
数据分析:我国GDP总值约为 98.13 亿元。
五、总结
通过对我国个省份地区的人口数量以及GDP总值数据分析,我们可以知道广东省不但是一个人口大省,还是一个国内生产总值较高的省,说明这个省的人们的生活水平比较高。我们还可以发现,我国的人口大多数都在东边沿海地区,沿海地区的经济也比内陆的地区更为发达,说明人口数量与经济呈现正相关的关系。我国的GDP生产总值(GDP)约为 98.13 亿元,虽然这个数看起来很大,但我国的人口也极多,约为14.28亿人,平均下来的GDP值也就没多少了,所以我国仍需大力发展经济。
大数据应用期末总评(hadoop综合大作业)的更多相关文章
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- 学习笔记之Vim
Vim (text editor) - Wikipedia https://en.wikipedia.org/wiki/Vim_(text_editor) Vim (/vɪm/;[4] a contr ...
- testNG helloWorld
1. 新建maven工程.File -> New -> Project -> Maven,不选Create from archetype,直接点击“Next”.GroupId和Art ...
- PHP使用Redis的Pub/Sub(发布订阅)命令
1.概念 名称 含义 channel 频道:生产者和消费者直接操作的对象 publish 生产者:向channel发送消息 subscribe 消费者:订阅一个或多个channel psubscrib ...
- MySQL Processlist--查看会话执行过的SQL情况
对于MySQL 5.7版本,可以使用sys.session视图来查看会话最后一次执行的SQL: SELECT * FROM sys.session WHERE CONN_ID = \G 其中sys.s ...
- zookeeper题目
1. ZooKeeper是什么?2. ZooKeeper提供了什么?3. Zookeeper文件系统4. ZAB协议?5. 四种类型的数据节点 Znode6. Zookeeper Watcher 机制 ...
- C#将文件转成16进制码流写入数据库存起来,访问的时候再还原成PDF文件。
转自https://blog.csdn.net/liubowei_0312/article/details/53378146 适合将文件写入数据库,远程访问的时候还原1.首先把文件转成十六进制文件流 ...
- ARTS-week2
Algorithm 给你一个有效的 IPv4 地址 address,返回这个 IP 地址的无效化版本.所谓无效化 IP 地址,其实就是用 "[.]" 代替了每个 ".&q ...
- IntToBinaryString
void IntToBinaryString(int devisor,char* pBinStr) { int i; int remainder; ;i<;i++) { remainder=de ...
- forever nodejs管理进程
何为forever forever可以看做是一个nodejs的守护进程,能够启动,停止,重启我们的app应用.官方的说明是说: A simple CLI tool for ensuring that ...
- 使用idea 调试java -jar xxx.jar方式启动
今日思语:希望是什么?希望就是 你还在挣扎中... idea是一个功能强大的java开发工具,可以很方便的帮助开发人员进行开发工作. 1.有时我们通过使用java -jar xxx.jar方式启动可执 ...