PageRank网页价值算法
一.简介
PageRank是Google提出的算法,用于衡量特定网页相对于其它网页而言的重要程度。是Google创始人拉里.佩奇和谢尔盖.布林于1997年创造的,用于实现将链接价值概念作为排名的重要因素。
二.算法原理
1.入链
PageRank让链接来投票,到一个页面的超链接相当于对该网页投一票。
2.入链个数
如果一个页面节点接收到的其它网页指向的入链数量越多,那么这个页面就越重要。
3.入链质量
指向页面A的不同入链质量不同,质量高的页面会通过链接向其它页面传递更大的权重。所有越是质量高的页面指向页面A,则页面A就越重要。
4..图解
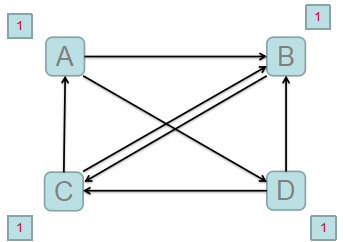
1.站在A的角度:需要将自己的PR值分给B,D。
2.站在B的角度:收到来自A,C,D的PR值。
3.PR值需要迭代计算,且其PR值会逐渐趋于稳定。
5.初始值
1.Google的每个页面设置相同的PR值,PageRank算法类似,每个页面的PR初始值为1。
2.迭代计算,Google不断的重复计算每个页面的PageRank,经过不断的迭代计算,这些页面的PR值会趋于稳定,这就是收敛的状态。
6.收敛标准
1.每个页面的PR值和上一次计算的PR值相等。
2.设定一个差值指标【例如:0.001】,当所有页面上一次计算的PR值差值平均小于该标准时,则认为其已经收敛。
3.设定一个百分比【例如:99%】,当99%的页面和上一次计算的PR值相等时认为其已收敛。
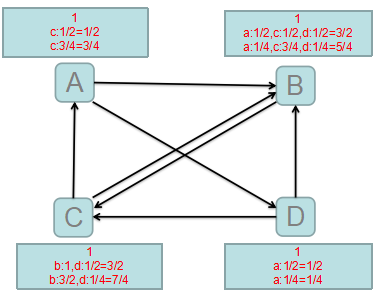
三.修正PageRank
1.站在互联网的角度看,只有出度而没有入度,PR值会趋向于0,只有入度而没有出度,PR值会趋向于很大。
2.修正PageRank计算公式,增加阻尼系数,一般取值为d=0.85。
3.完整PageRank计算公式:
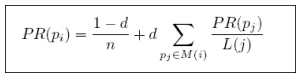
备注:
d:阻尼系数
M(i):指向i的页面集合
L(i):页面的出链数
PR(Pj):j页面的PR值
n:所有页面数
四.代码实现
package big.data.analyse.pageRank
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object PageRunJob {
def main(args: Array[String]): Unit = {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
val spark = SparkSession.builder//创建spark入口
.master("local[2]")//设置本地运行模式
.appName("pageRank")
.config("spark.sql.warehouse.dir","file:///D://warehouse")//设置本地仓库
.getOrCreate()
//读取关系矩阵
val firstInputPath = spark.read.textFile("src/big/data/analyse/pageRank/pagerank.txt")
// 求出n
val n = firstInputPath.count()
//获取所有节点
val onlyKey = firstInputPath.rdd.map(line => line.split(",")(0))
onlyKey.cache()//缓存(方便重用,后面多次使用时建议使用)
//获取所有映射关系
val kvMap = firstInputPath.rdd.map(line =>
{
val array = line.split(",").array
(array(0),array(1))
})
kvMap.cache()//缓存(方便重用)
val bk = onlyKey.map(k=>(k,1)).reduceByKey(_+_)
val d = 0.85 // 阻尼系数
//延迟加载
val first = onlyKey.map(k=>(k,1.0)) // 默认每个网页初始价值为1
.reduceByKey(_+_) // 求每个网页出度
.map(line =>(line._1,((1-d)/n) + d * 1/line._2)) // 出度越大,价值越小
.sortByKey()//排序
first.cache()//缓存(方便重用)
println("<<<<<<<<<<<<<<<<<<<正在进行第1迭代计算,当前误差为:"+first.count()+">>>>>>>>>>>>>>>>>>>")
first.foreach(println)
val frist_bk = first.join(bk)
.map(row => (row._1,row._2._1/row._2._2)) // 重新平衡每个网页的出度价值
var second = kvMap.join(frist_bk)
.map(row => row._2)
.reduceByKey(_+_)
.sortByKey()//排序
/**
* 统计初次误差
*/
val subValue = second.join(first).map(k=>k._2).sortByKey()
.map(line =>(line._2-line._1).abs).sum()
println("<<<<<<<<<<<<<<<<<<<正在进行第2迭代计算,当前误差为:"+subValue+">>>>>>>>>>>>>>>>>>>")
second.foreach(println) // 二次计算每个网页的价值
val precision = 0.001//设置精确度
var i = 3
while(true){
val mid_bk = second.join(bk)
.map(row => (row._1,((1-d)/n) + d * row._2._1/row._2._2)) // 重新平衡每个网页的出度价值
val second_mid = kvMap.join(mid_bk)
.map(row => row._2)
.reduceByKey(_+_)
.sortByKey()//排序
val subValue = second_mid.join(second).map(k=>k._2).sortByKey()//计算当前迭代的各节点的价值
.map(line =>(line._2-line._1).abs).sum()
println("<<<<<<<<<<<<<<<<<<<正在进行第"+i+"迭代计算,当前误差为:"+subValue+">>>>>>>>>>>>>>>>>>>")
second_mid.foreach(println) // 二次计算每个网页的价值
if(subValue<=precision){
println("<<<<<<<<<<<<<<<<<<<当前误差为:"+subValue+"已小于"+precision+",迭代完成!>>>>>>>>>>>>>>>>>>>")
return
}else{
second = second_mid
i += 1
}
}
spark.stop()//关闭
}
}
五.测试数据
百度,博客园
百度,Apache
博客园,GitHub
GitHub,百度
GitHub,博客园
GitHub,Apache
Apache,博客园
Apache,GitHub
Apache,百度
Apache,Apache
六.结果
<<<<<<<<<<<<<<<<<<<正在进行第1迭代计算,当前误差为:4>>>>>>>>>>>>>>>>>>>
(Apache,0.2275)
(GitHub,0.29833333333333334)
(博客园,0.865)
(百度,0.44)
<<<<<<<<<<<<<<<<<<<正在进行第2迭代计算,当前误差为:1.544722222222222>>>>>>>>>>>>>>>>>>>
(Apache,0.37631944444444443)
(GitHub,0.921875)
(博客园,0.37631944444444443)
(百度,0.15631944444444446)
<<<<<<<<<<<<<<<<<<<正在进行第3迭代计算,当前误差为:0.8594461805555556>>>>>>>>>>>>>>>>>>>
(Apache,0.4526015625)
(GitHub,0.42983940972222223)
(博客园,0.4526015625)
(百度,0.3711657986111111)
<<<<<<<<<<<<<<<<<<<正在进行第4迭代计算,当前误差为:0.26803075086805556>>>>>>>>>>>>>>>>>>>
(Apache,0.42071112919560183)
(GitHub,0.51088916015625)
(博客园,0.42071112919560183)
(百度,0.2479656647858796)
<<<<<<<<<<<<<<<<<<<正在进行第5迭代计算,当前误差为:0.1224163202582465>>>>>>>>>>>>>>>>>>>
(Apache,0.3845384511990017)
(GitHub,0.47700557477032696)
(博客园,0.3845384511990017)
(百度,0.26415304366500286)
<<<<<<<<<<<<<<<<<<<正在进行第6迭代计算,当前误差为:0.07653532812499986>>>>>>>>>>>>>>>>>>>
(Apache,0.3741310439556734)
(GitHub,0.43857210439893934)
(博客园,0.3741310439556734)
(百度,0.24686600039804718)
<<<<<<<<<<<<<<<<<<<正在进行第7迭代计算,当前误差为:0.06505502890625>>>>>>>>>>>>>>>>>>>
(Apache,0.3536829932561168)
(GitHub,0.427514234202903)
(博客园,0.3536829932561168)
(百度,0.23376494308694676)
<<<<<<<<<<<<<<<<<<<正在进行第8迭代计算,当前误差为:0.05529677457031257>>>>>>>>>>>>>>>>>>>
(Apache,0.34063676990303304)
(GitHub,0.40578818033462405)
(博客园,0.34063676990303304)
(百度,0.22628666909108067)
<<<<<<<<<<<<<<<<<<<正在进行第9迭代计算,当前误差为:0.04700225838476582>>>>>>>>>>>>>>>>>>>
(Apache,0.32853046572958056)
(GitHub,0.39192656802197257)
(博客园,0.32853046572958056)
(百度,0.2173586313658713)
<<<<<<<<<<<<<<<<<<<正在进行第10迭代计算,当前误差为:0.0399519196270508>>>>>>>>>>>>>>>>>>>
(Apache,0.31823600323759005)
(GitHub,0.37906361983767933)
(博客园,0.31823600323759005)
(百度,0.21085858490709475)
<<<<<<<<<<<<<<<<<<<正在进行第11迭代计算,当前误差为:0.03395913168299314>>>>>>>>>>>>>>>>>>>
(Apache,0.3096414082275123)
(GitHub,0.3681257534399394)
(博客园,0.3096414082275123)
(百度,0.20502650964199703)
<<<<<<<<<<<<<<<<<<<正在进行第12迭代计算,当前误差为:0.028865261930544117>>>>>>>>>>>>>>>>>>>
(Apache,0.30223736265417794)
(GitHub,0.35899399624173184)
(博客园,0.30223736265417794)
(百度,0.2001010960563292)
<<<<<<<<<<<<<<<<<<<正在进行第13迭代计算,当前误差为:0.024535472640962563>>>>>>>>>>>>>>>>>>>
(Apache,0.29598337098977673)
(GitHub,0.3511271978200641)
(博客园,0.29598337098977673)
(百度,0.19594040516583683)
<<<<<<<<<<<<<<<<<<<正在进行第14迭代计算,当前误差为:0.020855151744818112>>>>>>>>>>>>>>>>>>>
(Apache,0.2906571779131597)
(GitHub,0.3444823316766378)
(博客园,0.2906571779131597)
(百度,0.19238250571767906)
<<<<<<<<<<<<<<<<<<<正在进行第15迭代计算,当前误差为:0.017726878983095412>>>>>>>>>>>>>>>>>>>
(Apache,0.28613054254494075)
(GitHub,0.3388232515327322)
(博客园,0.28613054254494075)
(百度,0.18936797761492716)
<<<<<<<<<<<<<<<<<<<正在进行第16迭代计算,当前误差为:0.015067847135631168>>>>>>>>>>>>>>>>>>>
(Apache,0.2822840520447514)
(GitHub,0.33401370145399956)
(博客园,0.2822840520447514)
(百度,0.18680266155840736)
<<<<<<<<<<<<<<<<<<<正在进行第17迭代计算,当前误差为:0.012807670065286408>>>>>>>>>>>>>>>>>>>
(Apache,0.27901370763379935)
(GitHub,0.32992680529754836)
(博客园,0.27901370763379935)
(百度,0.1846225764714762)
<<<<<<<<<<<<<<<<<<<正在进行第18迭代计算,当前误差为:0.010886519555493496>>>>>>>>>>>>>>>>>>>
(Apache,0.2762342693735318)
(GitHub,0.3264520643609118)
(博客园,0.2762342693735318)
(百度,0.1827696743731544)
<<<<<<<<<<<<<<<<<<<正在进行第19迭代计算,当前误差为:0.009253541622169403>>>>>>>>>>>>>>>>>>>
(Apache,0.27387164541939113)
(GitHub,0.32349891120937757)
(博客园,0.27387164541939113)
(百度,0.18119453381080053)
<<<<<<<<<<<<<<<<<<<正在进行第20迭代计算,当前误差为:0.007865510378844143>>>>>>>>>>>>>>>>>>>
(Apache,0.2718634263638678)
(GitHub,0.32098862325810307)
(博客园,0.2718634263638678)
(百度,0.17985574949427757)
<<<<<<<<<<<<<<<<<<<正在进行第21迭代计算,当前误差为:0.0066856838220175074>>>>>>>>>>>>>>>>>>>
(Apache,0.2701564482271857)
(GitHub,0.31885489051160953)
(博客园,0.2701564482271857)
(百度,0.17871775469211776)
<<<<<<<<<<<<<<<<<<<正在进行第22迭代计算,当前误差为:0.005682831248714881>>>>>>>>>>>>>>>>>>>
(Apache,0.26870550997071635)
(GitHub,0.3170412262413848)
(博客园,0.26870550997071635)
(百度,0.17775046422656632)
<<<<<<<<<<<<<<<<<<<正在进行第23迭代计算,当前误差为:0.004830406561407652>>>>>>>>>>>>>>>>>>>
(Apache,0.2674722156001269)
(GitHub,0.31549960434388613)
(博客园,0.2674722156001269)
(百度,0.17692826830383623)
<<<<<<<<<<<<<<<<<<<正在进行第24迭代计算,当前误差为:0.004105845577196454>>>>>>>>>>>>>>>>>>>
(Apache,0.2664239144082584)
(GitHub,0.31418922907513486)
(博客园,0.2664239144082584)
(百度,0.17622940037912804)
<<<<<<<<<<<<<<<<<<<正在进行第25迭代计算,当前误差为:0.0034899687406169944>>>>>>>>>>>>>>>>>>>
(Apache,0.2655328585441725)
(GitHub,0.31307540905877457)
(博客园,0.2655328585441725)
(百度,0.1756353633830431)
<<<<<<<<<<<<<<<<<<<正在进行第26迭代计算,当前误差为:0.002966473429524441>>>>>>>>>>>>>>>>>>>
(Apache,0.26477546111174943)
(GitHub,0.3121286622031833)
(博客园,0.26477546111174943)
(百度,0.17513043167395612)
<<<<<<<<<<<<<<<<<<<正在进行第27迭代计算,当前误差为:0.002521502415095772>>>>>>>>>>>>>>>>>>>
(Apache,0.26413167323858)
(GitHub,0.3113239274312338)
(博客园,0.26413167323858)
(百度,0.1747012397771487)
<<<<<<<<<<<<<<<<<<<正在进行第28迭代计算,当前误差为:0.0021432770528314327>>>>>>>>>>>>>>>>>>>
(Apache,0.2635844535740027)
(GitHub,0.31063990281599124)
(博客园,0.2635844535740027)
(百度,0.1743364266687145)
<<<<<<<<<<<<<<<<<<<正在进行第29迭代计算,当前误差为:0.0018217854949066081>>>>>>>>>>>>>>>>>>>
(Apache,0.26311931684987677)
(GitHub,0.31005848192237784)
(博客园,0.26311931684987677)
(百度,0.1740263355156731)
<<<<<<<<<<<<<<<<<<<正在进行第30迭代计算,当前误差为:0.0015485176706707127>>>>>>>>>>>>>>>>>>>
(Apache,0.26272395063610027)
(GitHub,0.30956427415299403)
(博客园,0.26272395063610027)
(百度,0.1737627580419392)
<<<<<<<<<<<<<<<<<<<正在进行第31迭代计算,当前误差为:0.001316240020070053>>>>>>>>>>>>>>>>>>>
(Apache,0.2623878893546771)
(GitHub,0.30914419755085654)
(博客园,0.2623878893546771)
(百度,0.17353871718685296)
<<<<<<<<<<<<<<<<<<<正在进行第32迭代计算,当前误差为:0.001118804017059577>>>>>>>>>>>>>>>>>>>
(Apache,0.2621022372650241)
(GitHub,0.3087871324393444)
(博客园,0.2621022372650241)
(百度,0.17334828246061157)
<<<<<<<<<<<<<<<<<<<正在进行第33迭代计算,当前误差为:9.509834145005613E-4>>>>>>>>>>>>>>>>>>>
(Apache,0.26185943298905845)
(GitHub,0.3084836270940881)
(博客园,0.26185943298905845)
(百度,0.17318641294329856)
<<<<<<<<<<<<<<<<<<<当前误差为:9.509834145005613E-4已小于0.001,迭代完成!>>>>>>>>>>>>>>>>>>>
Process finished with exit code 0
PageRank网页价值算法的更多相关文章
- 谷歌的网页排序算法(PageRank Algorithm)
本文将介绍谷歌的网页排序算法(PageRank Algorithm),以及它如何从250亿份网页中捞到与你的搜索条件匹配的结果.它的匹配效果如此之好,以至于“谷歌”(google)今天已经成为一个被广 ...
- 网页排名算法PagaRank
网页排名算法PageRank PageRank,网页排名,又叫做网页级别.是一种利用网页之间的超链接数据进行计算的方法.它是由Google的两位创始人提出的. 对于用户而言,网页排名一般是比较主观的, ...
- 基于视觉信息的网页分块算法(VIPS) - yysdsyl的专栏 - 博客频道 - CSDN.NET
基于视觉信息的网页分块算法(VIPS) - yysdsyl的专栏 - 博客频道 - CSDN.NET 于视觉信息的网页分块算法(VIPS) 2012-07-29 15:22 1233人阅读 评论(1) ...
- 高效网页去重算法-SimHash
记得以前有人问过我,网页去重算法有哪些,我不假思索的说出了余弦向量相似度匹配,但如果是数十亿级别的网页去重呢?这下糟糕了,因为每两个网页都需要计算一次向量内积,查重效率太低了!我当时就想:论查找效率肯 ...
- 一个基于特征向量的近似网页去重算法——term用SVM人工提取训练,基于term的特征向量,倒排索引查询相似文档,同时利用cos计算相似度
摘 要 在搜索引擎的检索结果页面中,用户经常会得到内容相似的重复页面,它们中大多是由于网站之间转载造成的.为提高检索效率和用户满意度,提出一种基于特征向量的大规模中文近似网页检测算法DDW(Det ...
- JAVA分析html算法(JAVA网页蜘蛛算法)
近来有些朋友在做蜘蛛算法,或者在网页上面做深度的数据挖掘.但是遇到复杂而繁琐的html页面大家都望而却步.因为很难获取到相应的数据. 最古老的办法的是尝试用正则表达式,估计那么繁琐的东西得不偿失,浪费 ...
- 连接分析算法-HITS-算法
转自http://blog.csdn.net/Androidlushangderen/article/details/43311943 参考资料:http://blog.csdn.net/hguisu ...
- Learning Spark中文版--第四章--使用键值对(2)
Actions Available on Pair RDDs (键值对RDD可用的action) 和transformation(转换)一样,键值对RDD也可以使用基础RDD上的action(开工 ...
- PageRank算法--从原理到实现
本文将介绍PageRank算法的相关内容,具体如下: 1.算法来源 2.算法原理 3.算法证明 4.PR值计算方法 4.1 幂迭代法 4.2 特征值法 4.3 代数法 5.算法实现 5.1 基于迭代法 ...
随机推荐
- git clone或者git clone时遇到gnutls_handshake() failed: An unexpected TLS packet was received.如何处理?
答: 直接将https修改为http即可, 如: $ git clone https://github.com/Jello_Smith/my-example.git -> git clone ...
- 使用bugly热更新时自定义升级弹窗的UI样式
项目的热更新用的bugly,不过一直都只是使用他自带的升级弹窗. 不过UI小姐姐说弹窗太丑了,要自定义. bugly有提供自定义UI的官方文档:https://bugly.qq.com/docs/us ...
- asp.net core mvc 里的application中的start,end等事件
我们以前在用asp.net mvc或者webform的时候,经常用用到Application里的事件 start,end等.我们在.net core 里也同样有类似的方法. 在Startup类里,Co ...
- 梳理数据库(MySQL)的主要知识点
一.数据库类型 常用的关系型数据库 Oracle:功能强大,主要缺点就是贵 MySQL:互联网行业中最流行的数据库,免费.关系数据库场景中的功能 MySQL 都能很好的满足 MariaDB:MySQL ...
- 中国大互联网公司在github上的开源项目
公司名 账号数 账号名 总项目数 非fork项目数 百度 13 baidu.ApolloAuto. brpc. mipengine.Clouda-team.mesalock-linux. ecomfe ...
- 【APM】Pinpoint 使用教程(二)
本例介绍Pinpoint使用教程 Pinpoint安装部署参考:[APM]Pinpoint 安装部署(一) 查看应用调用关系拓扑图 进入pintpoint->选择应用-〉选择查看的时间周期,即可 ...
- MySQL 5.7 虚拟列 (virtual columns)(转)
原文地址:https://www.cnblogs.com/raichen/p/5227449.html 参考资料: Generated Columns in MySQL 5.7.5 MySQL 5.7 ...
- EasyDSS高性能流媒体服务器开发RTMP直播同步输出HLS(m3u8)录像功能实现时移回放的方案
EasyDSS商用流媒体服务器解决方案是由EasyDarwin开源团队原班人马开发的一套集流媒体点播.转码与管理.直播.录像.检索.时移回看于一体的一套完整的商用流媒体服务器解决方案,支持RTMP推流 ...
- [转]How to Install Oracle Java 11 in Ubuntu 18.04/18.10
链接地址:http://ubuntuhandbook.org/index.php/2018/11/how-to-install-oracle-java-11-in-ubuntu-18-04-18-10 ...
- oracle python操作 增删改查
oracle删除 删除表内容 truncate table new_userinfo; 删除表 drop table new_userinfo; 1.首先,python链接oracle数据库需要配置好 ...