【转】简易剖析Hadoop作业工作机制
原文地址:https://www.cnblogs.com/duma/p/10666269.html
建议:结合第四版Hadoop权威指南阅读,更有利于理解
运行机制
运行一个 MR 程序主要涉及以下 5 个部分:
- 客户端: 提交 MR 作业,也就是我们运行 hadoop jar xxx 的命令后,启动的 Java 程序
- YARN ResourceManager: YARN 集群主节点,负责协调集群上计算资源的分配
- YARN NodeManager:YARN 集群从节点,负责启动和监视机器上的容器(container)
- MapReduce Application Master:负责协调 MR 作业,当然 Spark 作业也有对应的 application master
运行 MR 任务的工作原理如下图,本图摘自《Hadoop 权威指南(第四版)》:
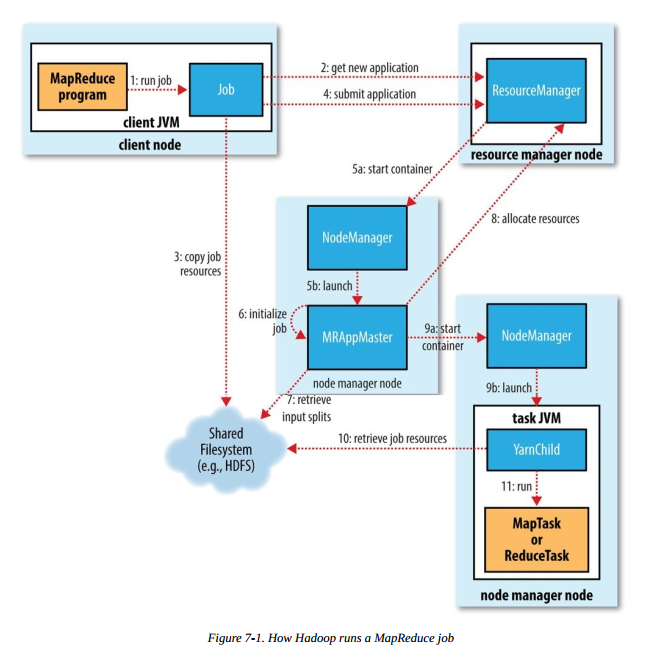
步骤1 是我们在客户端节点(集群中的某台机器)执行 hadoop jar xxx 命令后,启动 MR 作业的流程,后续会涉及以下几个重要流程
- 作业的提交和初始化
- 任务的分配与执行
- 进度和状态的更新
下面会详细介绍每个流程。这里我们将编写的整个 MR 程序叫做作业,MR作业运行后的 map 或 reduce 任务统称为任务。
任务的提交和初始化
作业的提交
- 向 ResourceManager 申请一个新的应用 ID(步骤 2),之前的 MR 例子我们可以看到,应用 ID 的形式为:application_1551593879638_0009
- 计算作业分片检查作业的输入输出,若输入文件不可分割或者输入路径不存在,报错返回;如果没有指定输出路径或者输出路径已存在,报错返回
- 将作业运行所需的资源(jar、配置文件和分片信息等)复制到共享文件系统中(步骤 3),默认为 HDFS 。目录名称以应用 ID 命名
- 调用 ResourceManager 的 submitApplication() 方法提交作业(步骤4)
以上的流程均在客户端节点完成。
作业的初始化
ResourceManager 收到调用它的
submitApplication() 方法后,会在 NodeManager 中分配一个 container (步骤 5a),在
container 中启动 application master(步骤 5b) 。MapReduce application master
的主类是 MRAppMaster。application master 完成初始化后(步骤
6),从共享文件系统(如:HDFS)获取分片信息(步骤 7)。对每个分片创建一个 map 任务和 reduce 任务,并分配任务 ID。如果
application master 判断该任务不是 uber 任务,那么接下来会进行任务分配。
任务分配与运行
任务分配
application master 会为 map 任务和 reduce
任务向 ResourceManager 申请分配资源。map 任务的优先级高于 reduce 任务,且直到 5% 的 map
任务完成时,reduce 任务请求才能发出。reduce 任务可以在集群的任意机器执行,但 map 任务有数据本地化的限制,理想情况下数据分片和
map 任务在同一节点运行,即数据本地化(data local),这样 map 任务直接读取本地的数据,不需要网络
IO。如果达不到理想情况,可以在数据节点同一机架上启动 map 任务,即机架本地化(rack local),这样 map
任务从同机架上其他节点将数据拷贝到自己的节点。最差的情况是分片和 map 任务不在同一机架,需要跨机架拷贝数据。application
master 申请的资源包括内存和 CPU 核心数,申请的大小可以通过 4 个属性指定:
- mapreduce.map.memory.mb:map 任务内存, 单位:MB,默认:1024
- mapreduce.map.cpu.vcores:map 任务 CPU 核心数,默认:1
- mapreduce.reduce.memory.mb:reduce 任务内存,单位:MB,默认:1024
- mapreduce.reduce.cpu.vcores:reduce 任务 CPU 核心数,默认:1
任务执行
ResourceManager 为任务在某个 NodeManager
上分配容器后(步骤 9a),application master 会与该 NodeManager 通信来启动容器(步骤 9b)。该任务的主类为
YarnChild,该任务运行前会先将共享文件系统(如:HDFS)上的文件本地化(步骤
10),文件包括:配置文件、JAR包和分布式缓存文件。最后,运行 map 或 reduce 任务(步骤 11)。
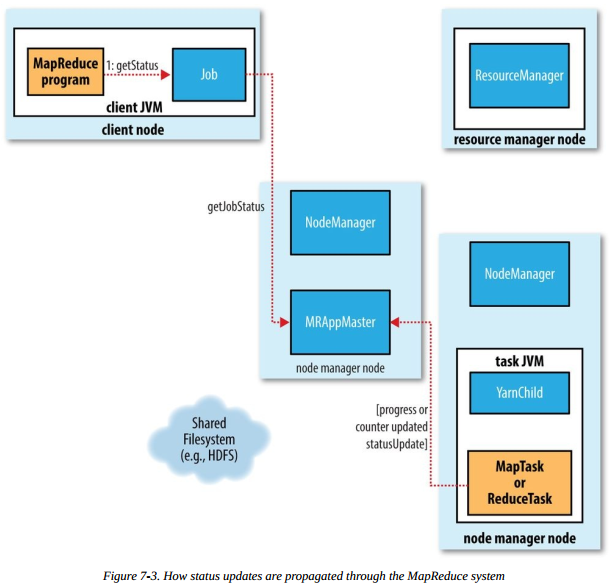
进度和状态更新
当用户成功提交并且作业成功运行后,用户希望能够看到作业的运行状态。一个作业和它的每个任务都有一个状态,包括:作业或任务的状态(比如,运行中、成功或失败),map 或 reduce 任务的进度以及计数器值等。
- 当 map 或 reduce 任务运行时,通过接口向自己的 application master 上报进度和状态
- 作业的运行期间,客户端请求 application master 以获得最新的状态
流程图如下:
作业的完成
application master
接到最后一个任务成功完成的通知后,便把作业置位成功得状态。可以端查询到任务成功完成后,从 waitCompletion()
方法返回。作业的统计信息和计数器值输出在控制台。最后,application master 会做一些清理工作,作业信息由
JobHistoryServer 存档,以便用户以后查询。
小结
本章主要介绍 MR 作业的运行机制,并且了解了 YARN 集群主从节点职责及其相互之间的配合。通过这篇文章的介绍希望读者对 MR 作业的运行机制有大致的了解。我们可以简单总结下本章介绍的相关组件的作用。本文主要参考《Hadoop 权威指南(第四版)》和 Hadoop 官方文档,有兴趣的读者可以深入研究,一起探讨。
【转】简易剖析Hadoop作业工作机制的更多相关文章
- hadoop MapReduce 工作机制
摸索了将近一个月的hadoop , 在centos上配了一个伪分布式的环境,又折腾了一把hadoop eclipse plugin,最后终于实现了在windows上编写MapReduce程序,在cen ...
- 通过库函数API和C代码中嵌入汇编代码剖析系统调用的工作机制
作者:吴乐 山东师范大学<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 本次实验的主要内容就是分别采用A ...
- 剖析MapReduce 作业运行机制
包含四个独立的实体: · Client Node 客户端:编写 MapReduce代码,配置作业,提交MapReduce作业. · JobTracker :初始化作业,分配作业,与 TaskTra ...
- MapReduce1 工作机制
本文转自:Hadoop MapReduce 工作机制 工作流程 作业配置 作业提交 作业初始化 作业分配 作业执行 进度和状态更新 作业完成 错误处理 作业调度 shule(mapreduce核心)和 ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- hadoop知识点总结(一)hadoop架构以及mapreduce工作机制
1,为什么需要hadoop 数据分析者面临的问题 数据日趋庞大,读写都出现性能瓶颈: 用户的应用和分析结果,对实时性和响应时间要求越来越高: 使用的模型越来越复杂,计算量指数级上升. 期待的解决方案 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
随机推荐
- Android中Activity的启动模式(LaunchMode)和使用场景
一.为什么需要启动模式在Android开发中,我们都知道,在默认的情况下,如果我们启动的是同一个Activity的话,系统会创建多个实例并把它们一一放入任务栈中.当我们点击返回(back)键,这些Ac ...
- [转]C++ 使用 curl 进行 http 请求(GET、POST、Download)的封装
原文连接:https://www.cnblogs.com/oftenlin/p/9478067.html CommonTools.h /* * CommonTools.h * * Created ...
- matlab学习笔记8 基本绘图命令-特殊图形绘制
一起来学matlab-matlab学习笔记8 基本绘图命令_3 特殊图形绘制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考书籍 <matlab 程序设计与综合应用>张德丰等 ...
- oracle plsql 异常
set serveroutput on DECLARE pename emp.ename%type; begin '; exception when no_data_found then dbms ...
- 映美FP-530K+打印发票的各种经验
本人虽然写了很多lodop博文,但是程序开发一般都是用虚拟打印机测试,实际打印机打印中还可能存在各种问题,毕竟理论都不如实践能获得更多的打印经验.当个人使用过的打印机不多,只有映美FP-530K+,用 ...
- IEDA中使用阿里插件Alibaba Cloud Toolkit和Arthas(阿尔萨斯)
在 IntelliJ IDEA 中安装和配置 Cloud Toolkit 在 IntelliJ IDEA 中安装和配置 Cloud Toolkit 后,您可以将本地应用快速部署到阿里云 ECS.EDA ...
- nginx下只能通过域名,禁止使用ip访问
今天来了一个需求,ip访问返回500,域名访问正常,只需在nginx.conf中添加 server { listen 80 default; #default 必须加的 return 500; } 也 ...
- zookeeper ACL权限
原文链接:https://www.jianshu.com/p/392248ab27f4 对zookeeper设置ACL属性 我们以zkCli为例,来说明zookeeper对ACL的设置. 使用zkCl ...
- 使用SnowFlake算法生成唯一ID
转自:https://segmentfault.com/a/1190000007769660 考虑过的方法有 直接用时间戳,或者以此衍生的一系列方法 Mysql自带的uuid 以上两种方法都可以查到就 ...
- 重回ubutntu12.04小记(装完ubuntu做的几件事)
原来一直是在windows下用虚拟机跑redhat 和debian 做实验和一些工程,以前也装过ubuntu和windows双系统,但是换电脑后,就一直懒得捣鼓了. 现在,由于长期需要在linux上做 ...