NLP之关键词提取(TF-IDF、Text-Rank)
1.文本关键词抽取的种类:
关键词提取方法分为有监督、半监督和无监督三种,有监督和半监督的关键词抽取方法需要浪费人力资源,所以现在使用的大多是无监督的关键词提取方法。
无监督的关键词提取方法又可以分为三类:基于统计特征的关键词抽取、基于词图模型的关键词抽取和基于主题模型的关键词抽取。
2.基于统计特征的有个最简单的方法,利用TF-IDF效果不错


对于未登录词其IDF值的常用计算以及TF-IDF的计算

3、TD-IDF的主要思想以及优缺点
主要思想:
tf-idf 模型的主要思想是:如果词w在一篇文档d中出现的频率高,并且在其他文档中很少出现,则认为词w具有很好的区分能力,适合用来把文章d和其他文章区分开来。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。IDF的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能。
4、基于词图模型的介绍一个TextRank
具体参考:
https://www.cnblogs.com/xueyinzhe/p/7101295.html
说到TextRank要先介绍PageRank:
PageRank算法
PageRank设计之初是用于Google的网页排名的,以该公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。PageRank通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种投票的思想来设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道有哪些网页链接到网页A,也就是要首先得到网页A的入链,然后通过入链给网页A的投票来计算网页A的PR值。这样设计可以保证达到这样一个效果:当某些高质量的网页指向网页A的时候,那么网页A的PR值会因为这些高质量的投票而变大,而网页A被较少网页指向或被一些PR值较低的网页指向的时候,A的PR值也不会很大,这样可以合理地反映一个网页的质量水平。那么根据以上思想,佩奇设计了下面的公式:

该公式中,Vi表示某个网页,Vj表示链接到Vi的网页(即Vi的入链),S(Vi)表示网页Vi的PR值,In(Vi)表示网页Vi的所有入链的集合,Out(Vj)表示网页,d表示阻尼系数,是用来克服这个公式中“d *”后面的部分的固有缺陷用的:如果仅仅有求和的部分,那么该公式将无法处理没有入链的网页的PR值,因为这时,根据该公式这些网页的PR值为0,但实际情况却不是这样,所以加入了一个阻尼系数来确保每个网页都有一个大于0的PR值,根据实验的结果,在0.85的阻尼系数下,大约100多次迭代PR值就能收敛到一个稳定的值,而当阻尼系数接近1时,需要的迭代次数会陡然增加很多,且排序不稳定。公式中S(Vj)前面的分数指的是Vj所有出链指向的网页应该平分Vj的PR值,这样才算是把自己的票分给了自己链接到的网页。
具体解释下后面的计算:即为网页所有入链的PR值之和再*阻尼系数,入链的PR值还要考虑到该入链是从哪个网页出来的,该入链的PR值=其出链的那个父节点/所有出去的路径。
TextRank算法提取关键词
TextRank是由PageRank改进而来,其公式有颇多相似之处,这里给出TextRank的公式:

可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。TextRank用于关键词提取的算法如下:
1)把给定的文本T按照完整句子进行分割,即

2)对于每个句子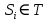 ,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即
,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即 ,其中 ti,j 是保留后的候选关键词。
,其中 ti,j 是保留后的候选关键词。
3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
4)根据上面公式,迭代传播各节点的权重,直至收敛。
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
6)由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
总结:将原文本拆分为句子,在每个句子中过滤掉停用词(可选),并只保留指定词性的单词(可选)。由此可以得到句子的集合和单词的集合。
每个单词作为pagerank中的一个节点。设定窗口大小为k,假设一个句子依次由下面的单词组成:w1,w2,w3,w4,w5,…,wn
[w1,w2,…,wk]、[w2,w3,…,wk+1]、[w3,w4,…,wk+2]等都是一个窗口。在一个窗口中的任两个单词对应的节点之间存在一个无向无权的边。
基于上面构成图,可以计算出每个单词节点的重要性。最重要的若干单词可以作为关键词。
5.文章关键词提取算法的对比
TF-IDF与TextRank的对比:tf-idf注重词频,词频和idf的乘积越大越关键,textrank注重词语之间的关联,和别的词关联性越大的词越重要。
tf-idf是纯粹用词频的思想(无论是tf还是idf都是)来计算一个词的得分,最终来提取关键词,完全没有用到词之间的关联性.而textrank用到了词之间的关联性(将相邻的词链接起来),这是其优于tf-idf的地方。tf-idf的idf值依赖于语料环境,这给他带来了统计上的优势,即它能够预先知道一个词的重要程度.这是它优于textrank的地方.而textrank只依赖文章本身,它认为一开始每个词的重要程度是一样的。
NLP之关键词提取(TF-IDF、Text-Rank)的更多相关文章
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- python实现关键词提取
今天我来弄一个简单的关键词提取的代码 文章内容关键词的提取分为三大步: (1) 分词 (2) 去停用词 (3) 关键词提取 分词方法有很多,我这里就选择常用的结巴jieba分词:去停用词,我用了一个停 ...
- Gradle +HanLP +SpringBoot 构建关键词提取,摘要提取 。入门篇
前段时间,领导要求出一个关键字提取的微服务,要求轻量级. 对于没写过微服务的一个小白来讲.有点赶鸭子上架,但是没办法,硬着头皮上也不能说不会啊. 首先了解下公司目前的架构体系,发现并不是分布式开发,只 ...
- 关键词提取算法TF-IDF与TextRank
一.前言 随着互联网的发展,数据的海量增长使得文本信息的分析与处理需求日益突显,而文本处理工作中关键词提取是基础工作之一. TF-IDF与TextRank是经典的关键词提取算法,需要掌握. 二.TF- ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- HanLP 关键词提取算法分析
HanLP 关键词提取算法分析 参考论文:<TextRank: Bringing Order into Texts> TextRank算法提取关键词的Java实现 TextRank算法自动 ...
- HanLP 关键词提取算法分析详解
HanLP 关键词提取算法分析详解 l 参考论文:<TextRank: Bringing Order into Texts> l TextRank算法提取关键词的Java实现 l Text ...
- 关键词提取TF-IDF算法/关键字提取之TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与信息探勘的常用加权技术.TF的意思是词频(Term - frequency), ...
随机推荐
- 【Java语言特性学习之六】扩展知识点
一.SPI机制 二.注解处理机制 三.java native关键字 https://www.cnblogs.com/KingIceMou/p/7239668.html
- QQ音乐2019客户端-获取任意歌单完整歌曲列表和下载音乐文件方法
步骤 1.在web网站上搜搜任意歌单 https://y.qq.com/#type=index/ 例如:中国好声音4.5.6.7.8季 打开后显示网址: https://y.qq.com/n/yqq ...
- python3爬虫筛选所需要数据
第一次使用博客园,也是第一篇文章,让我们一起开启学习之旅吧!! 昨天在为某授权系统做安全性测试的时候,可以未授权访问系统的用户登陆统计记录.由此想整理出部分用户名,作为暴力破解的用户名,检查是否存在用 ...
- .NET Core 学习笔记之 WebSocketsSample
1. 服务端 代码如下: Program: using Microsoft.AspNetCore; using Microsoft.AspNetCore.Hosting; namespace WebS ...
- WebApplicationInitializer启动分析
从Servlet 3.0 开始Tomcat已经支持注解式的配置.了解下,在注解的配置方式下,Web是怎样启动起来的. 通过注解配置一个Web应用 下面是一个通过注解实现一个简单的Web应用 publi ...
- QT+OpenGL(04)—freetype库的编译
1.freetype库的下载 https://www.freetype.org/download.html freetype-2.10.0.tar.bz2 2.解压 3.进入 freetype-2. ...
- python3的hashlib库sha256、pbkdf2_hmac、blake2b基本用法
hashlib.sha256: import hashlib x = hashlib.sha256()x.update(b"asd")print("x_1 = " ...
- 前端开发JS——快速入门
1.JS的核心标准ECMAScript 组成 ECMAScript------>核心语法标准 DOM------------->对文档节点的操作 ...
- CTF必备技能丨Linux Pwn入门教程——环境配置
说在前面 这是一套Linux Pwn入门教程系列,作者依据Atum师傅在i春秋上的Pwn入门课程中的技术分类,并结合近几年赛事中出现的一些题目和文章整理出一份相对完整的Linux Pwn教程. 问:为 ...
- BUUCTF Hack World
有返回 ,基于布尔得盲注这里用到异或注入(个人喜欢这样用)1^0 返回 Hello, glzjin wants a girlfriend.1^1 返回 Error Occured When Fetch ...