STL源码分析读书笔记--第三章--迭代器(iterator)概念与traits编程技法
1.准备知识
- typename用法
- 用法1:等效于模板编程中的class
- 用法2:用于显式地告诉编译器接下来的名称是类型名,对于这个区分,下面的参考链接中说得好,如果编译器不知道 T::bar 是类型名的话 T::bar * p可能就被理解成了T::bar 乘以p,T::bar & p可能就被理解成为了 T::bar 和p做逻辑与操作。 事实上,在模板编程时,如果传入的模板参数为T(T里面有模板参数的非独立名字bar),那么在不显示指定的话,c++或假定T::bar为变量名以消除歧义。
- “A name used in a template declaration or definition and that is dependent on a template-parameter is assumed not to name a type unless the applicable name lookup finds a type name or the name is qualified by the keyword typename.”
- 参考链接 : typename(wiki)
- traits编程技法(内嵌型别使用)
traits意为榨汁机,是在SGI 版本的STL实现中被广泛使用到的一个编程技法,需要使用的原因是我们不能根据一个不知道类型的变量直接推导出它的型别,听起来好像很奇怪,也就是不存在这么一个函数: typeof(),举个例子说明如下:
- 对于类型为 I 的变量 i ,I 可能是模板参数,如果对 I 来说 *操作有效,于是我们在程序中可以得到 *t ,然后需要将 *t 作为返回值返回,那么我们需要怎么做?下面问号的地方该怎么填?
{return *i;}我们经常需要在程序中获得迭代器相关的型别,由于迭代器与指针有某种类似的性质,所以迭代器所指型别很重要,经常需要在程序中使用,如上述问题之类的问题就被提出来了。这个问题的最终解决方案是---内嵌型别,对于刚才的函数,我们重新定义类 I ,在类 I 中声明一个内嵌型别,然后引用此内嵌型别,编译就可以通过,代码如下:
{//... T's other member ,ingored//T * ptr//myIter(T * p=0):ptr(p){}typedef typename T value_type;}template<class I>typename I::value_type func(I i){return *i;}到目前为止,问题好像解决了,根据上面的原理,我们可以定义traits,专门获取迭代器所指类型的型别:
{typedef typename I::value_type value_type;//...}但是在刚才分析时我们看到,要定义内嵌型别,首先 I 必须是一个类,对于有些类型的迭代器,可能就是一个原生指针,无法定义内嵌型别,这个时候就需要用到偏特化了,偏特化的内容在我的另一篇文章中讲过。在那边文章中我称作部分特化,这里遵从hj先生的翻译而已。偏特化只是提供另一份template定义,意思是对于某些特殊的类别作为模板参数时,使用不同的模板定义式,这些特殊的类别一般都是原生指针,const原生指针,或者是多个模板参数一样,比如对于原生指针,一个可以接受的traits特化版本就是:
{// typedef typename I value_type; (typename 可省略)typedef T value_type;//...}同样,对于const类型的原生指针,如果它作为迭代器,也必须定义一个偏特化的traits版本:
{//attention : const tag is removed because a value weith const type is useless.typedef T value_type;}
2.迭代器相关型别
迭代器相关的型别(侯捷先生翻译为相应型别,个人感觉不太准确)有五种:
- value type(所指型别)
- difference type(距离型别)
顾名思义,就是迭代器所指之物的型别,这个在上一节中作为例子讲过。
两个迭代器之间的距离
- reference type(所指型别的引用型别)
对于可以改变所指对象内容的迭代器,当需要引用所指对象时,用到的型别就是引用型别。
- pointer type(指针型别)
顾名思义
- iterator catalog(迭代器类型型别)
这个实现起来稍微复杂点,之所以要有这个型别,主要是效率考虑,对不同的类型迭代器,施加不同的算法以保证最高效率,书中给出的例子是advanced的实现根据不同的迭代器类型的不同变种。根据移动特性和施加的操作,迭代器被分为五类:
- input iterator
- output iterator
- foward iterator
- bidirectional iterator
- random acess iterator
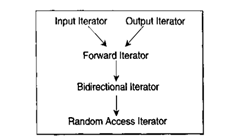
这五种类型的iterator从上往下概念一次强化,从概念上来说,关系如下:
图中直线表示的是逐层强化的概念,而非继承关系,具体实现时,要表示不同型别的迭代器,在迭代器中要定义相应的非独立名称,这个非独立名称可以用来标识迭代器的种类,假设这五种非独立名称的定义如下:
struct input_iterator_tag{};struct output_iterator_tag{};struct forward_iterator_tag:input_iterator_tag{};struct bidirectional_iterator_tag:forward_iterator_tag{};struct random_acess_iterator_tag:bidirectional_iterator_tag它的具体操作使用过程是这样的,对于具体实现算法的函数,有一个参数是tag类参数,调用时,调用一个封装函数,封装函数根据迭代器萃取出迭代器类型型别参数,然后作为参数传递到具体实现的算法中。如下:
{while(n--)++i;}template<class ForwardIterator,class Distance>inline void __advance(ForwardIterator &f,Distance n,forward_iterator_tag){//调用input_iterator_tag版本的__advance(f,n,input_iterator_tag());}template<class BidirectionalIterator,class Distance>inline void __advance(Bidirectional &b,Distance n,bidirectional_iterator_tag){if(n>=0)while(n--)b++;else while(n++)b--;}template<class RandomAccessIterator,class Distance>inline void __advance(RandomAccessIterator &r,Distance n,random_access_iterator_tag){r+=n;}
然后加上一个对外封装的壳子如下,让编译器自动寻找最接近的实现函数:
{__advance(i,n,iterator_traits<InputIterator>::iterator_catagory());// 或许觉得__advance(i,n,InputIterator::iterator_catagory())说不定也可以通过,但是一个很显然的事情就是类似于原生指针这种形式就不可用了}
3.std::iterator 的保证
任何iterator都应提供以上5种型别以供traits萃取,最好是继承下面的模板类:
struct iterator{typedef Catagory iterator_catagory;typedef T value_type;typedef Distance difference_type;typedef Pointer pointer_type;typedef Reference reference_type;}
4.总结
iterator是算法和数据结构之间的粘合剂,算法能统一地使用到stl的诸多数据结构中,iterator的设计功不可没,因此,对于stl中每一个容器,定好了底层的数据结构之后,设计相应的iterator就是接下来最重要的任务。(现在知道怎么回答iterator和指针的区别了吧)
STL源码分析读书笔记--第三章--迭代器(iterator)概念与traits编程技法的更多相关文章
- STL源码分析读书笔记--第5章--关联式容器
1.关联式容器的概念 上一篇文章讲序列式容器,序列式容器的概念与关联式容器相对,不提供按序索引.它分为set和map两大类,这两大类各自有各自的衍生体multiset和multimap,的底层机制都是 ...
- STL源码分析读书笔记--第二章--空间配置器(allocator)
声明:侯捷先生的STL源码剖析第二章个人感觉讲得蛮乱的,而且跟第三章有关,建议看完第三章再看第二章,网上有人上传了一篇读书笔记,觉得这个读书笔记的内容和编排还不错,我的这篇总结基本就延续了该读书笔记的 ...
- 重温《STL源码剖析》笔记 第三章
源码之前,了无秘密. --侯杰 第三章:迭代器概念与traits编程技法 迭代器是一种smart pointer auto_Ptr 是一个用来包装原生指针(native pointer)的对象,声明狼 ...
- STL源码剖析读书笔记--第四章--序列式容器
1.什么是序列式容器?什么是关联式容器? 书上给出的解释是,序列式容器中的元素是可序的(可理解为可以按序索引,不管这个索引是像数组一样的随机索引,还是像链表一样的顺序索引),但是元素值在索引顺序的方向 ...
- STL源码剖析读书笔记--第6章&第7章--算法与仿函数
老实说,这两章内容还蛮多的,但是其实在应用中一点点了解比较好.所以我决定这两张在以后使用过程中零零散散地总结,这个时候就说些基本概念好了.实际上,这两个STL组件都及其重要,我不详述一方面是自己偷懒, ...
- STL源码剖析读书笔记之vector
STL源码剖析读书笔记之vector 1.vector概述 vector是一种序列式容器,我的理解是vector就像数组.但是数组有一个很大的问题就是当我们分配 一个一定大小的数组的时候,起初也许我们 ...
- element-ui inputNumber、Card 、Breadcrumb组件源码分析整理笔记(三)
inputNumber组件 <template> <!--@dragstart.prevent禁止input中数字的拖动--> <div @dragstart.preve ...
- 重温《STL源码剖析》笔记 第五章
源码之前,了无秘密 ——侯杰 序列式容器 关联式容器 array(build in) RB-tree vector set heap map priority-queue multiset li ...
- 重温《STL源码剖析》笔记 第四章
源码之前,了无秘密 ——侯杰 序列式容器 关联式容器 array(build in) RB-tree vector set heap map priority-queue multiset li ...
随机推荐
- ssh: Could not resolve hostname gitcafe.com: nodename nor servname provided, or not known
今天 git push 的时候报如下错误: ssh: Could not resolve hostname gitcafe.com: nodename nor servname provided, o ...
- java中参数传递
一.参数是基本类型 相当于C++传值调用,方法中的形参是实参的副本. 二.参数是类类型 类类型的参数在方法调用中,相当于C++中的传址调用.形参是实参引用同一个对象.所有形参修改则实参也修改了 三.总 ...
- 使用Aspose.Cells组件生成Excel文件
生成带表头的Excel文件,格式如下显示. 当然更复杂的一些也可以通过 合并单元格的方法 public void Merge(int firstRow, int firstColumn, int to ...
- console.log的一个应用 -----用new方法生成一个img对象和document.createElement方法创建一个img对象的区别
我用两种方法来生成img对象,第一种方法是用new方法,第二种方法是用document.createElement方法. var img1 = new Image(); var img2 = docu ...
- php的webservice的soapheader认证问题
参数通过类传输:class authentication_header { private $username; private $password; public ...
- REDHAT YUM使用网易源
刚装好了 RedHat 6 系统,但是使用 yum 的时候总是提示 nothing to do,并且什么都做不了.后来经过一番搜索才知道,红帽的 yum 在线更新是收费的,而且必须注册系统之后才能使用 ...
- Android 开源项目PhotoView源码分析
https://github.com/chrisbanes/PhotoView/tree/master/library 这个就是项目地址,相信很多人都用过,我依然不去讲怎么使用.只讲他的原理和具体实现 ...
- XSS 前端防火墙(1):内联事件拦截
关于 XSS 怎样形成.如何注入.能做什么.如何防范,前人已有无数的探讨,这里就不再累述了.本文介绍的则是另一种预防思路. 几乎每篇谈论 XSS 的文章,结尾多少都会提到如何防止,然而大多万变不离其宗 ...
- Yii 框架创建自己的 web 应用
http://m.baidu.com/from=2001a/bd_page_type=1/ssid=0/uid=0/pu=usm%400%2Csz%401320_1003%2Cta%40iphone_ ...
- js画线
<body> <div id="main"> </div> <div id="fd" style="filt ...