(QA-LSTM)自然语言处理:智能问答 IBM 保险QA QA-LSTM 实现笔记.md
train集:
包含若干条与保险相关的问题,每一组问题对为一行,示意如下:
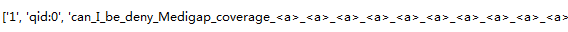
可分为四项,第三项为问题,第四项为答案:

1.build_vocab
统计训练集中出现的词,返回结果如下(一个包含3085个元素的dict,每个词作为一个key,value为这些词出现的顺序):
2. load_word_embedding(vocab,embedding_size)
vocab为第一步获取的词集,embedding_size=100
load_vectors()
获取预先训练好的保存在vectors.nobin中的词向量
返回的vector中保存有22353个词的向量
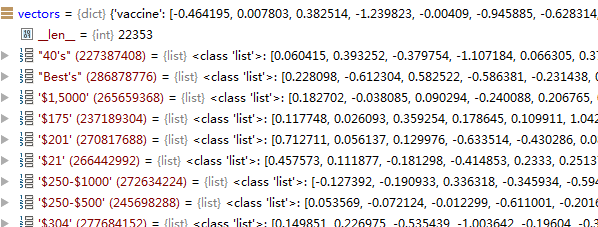
然后通过暴力匹配,获取vocab中每个词的词向量,存在embeddings中,embedding中的序数对应的是vacab中的key的value

3. load_train_list
获取保存在train中18540个问题与答案

4. load_test_list
获取保存在test.sample中的问题与答案,共10000条
在测试集中,共有20个问题,每个问题包含若干个正确答案与错误答案,共500个答案,由每一行的第一个元素标识,为1时为正确答案,为0时为错误答案
5.load_data(trainList,vocab,batch_size)
batch_size=256
encode_sent(vocab,string,size) 讲string中的词转换成vocab中所对应的的序号
得到一个batch_size的train_1(问题),train_2(正确答案), train_3(错误答案)
同时返回3个mask,用于标识数据集语句除去 < a > 后的真实的长度
6. LSTM Model

proj_size=100
初始化LSTM的参数
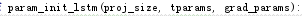
project_size=100
tparams={}
grad_params=[]
 随机生成ndimndim的矩阵W,对其进行SVD分解得到 u,s,v,返回floatX的u,维度100100
随机生成ndimndim的矩阵W,对其进行SVD分解得到 u,s,v,返回floatX的u,维度100100
初始化W,维度为100400

W_t=W
tparam[‘lstm_W’]=W_t
初始化U,维度为100400,U_T=U,tparam[‘lstm_U’]=W_t

初始化b,b的维度为4001,初始化为0,b_t=b,tparam[‘lstm_b’]=b_t
grad_params=[W_t, U_t,b_t]
返回tparam和grad_params
返回后的分别赋值给tparam和self.params
初始化CNN的参数

filter_sizes=[1,2,3,5]
num_filters=500
proj_size=100
tparam={lstm_U, lstm_w, lstm_b} 之前lstm初始化时赋好的值
self.params=lstm赋好的self.params
对于filter_sizes中的每一个元素(以2为例):
filter_shape=(num_filters,1,filter_size,proj_size)=(500,1,2,100)
fan_in=filter_shape[1:]的乘积=200
fan_out=filter_shape[0]np.prod(filter_shape[2:]) 500filter_shapefilter_sizeproj_size=100000
W_bound=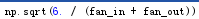
W初始化为最低值为-w_bound,最大值为w_bound,size=filter_shape
 =tparams[‘cnn_w_2’]=W
=tparams[‘cnn_w_2’]=W
初始化b为5001维的向量
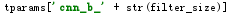 =tparams[‘cnn_b_2’]=b
=tparams[‘cnn_b_2’]=b
grand_params+=[W,b]
最终返回tparams和grad_params 各含有11个元素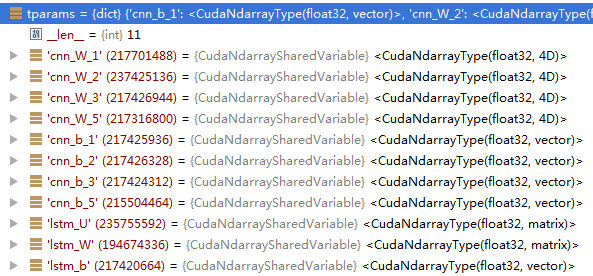
lookup_table=word_embedding
tparams[‘lookup_table’]=lookup_table


input1, input2, input3分别是问题,正确答案,错误答案

这一函数首先将input的训练集转成词向量模式的
将input的矩阵reshape成(sequence_len,batch_size, embedding_size)(100,256,100)的input_x
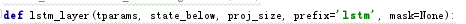
state_below就是input
nsteps=训练数据的sequence_len
n_samples=训练数据的batch_size
input=input*lstm_W+lstm_b
通过scan做lstm的相关步骤
得到的输出在输入CNN中,抽取特征,计算问题,正确答案,错误答案的相似度,余下的与QACNN类同
(QA-LSTM)自然语言处理:智能问答 IBM 保险QA QA-LSTM 实现笔记.md的更多相关文章
- (QACNN)自然语言处理:智能问答 IBM 保险QA QACNN 实现笔记
follow: https://github.com/white127/insuranceQA-cnn-lstm http://www.52nlp.cn/qa%E9%97%AE%E7%AD%94%E7 ...
- Android之智能问答机器人
本文主要利用图灵机器人的接口,所做的一个简单的智能问答机器人 实现 由于发送与接收消息都是不同的listView,所以要用有两个listVeiw的布局文件 接收消息布局文件 <?xml vers ...
- springboot+lucene实现公众号关键词回复智能问答
一.场景简介 最近在做公众号关键词回复方面的智能问答相关功能,发现用户输入提问内容和我们运营配置的关键词匹配回复率极低,原因是我们采用的是数据库的Like匹配. 这种模糊匹配首先不是很智能,而且也没有 ...
- 智能问答中的NLU意图识别流程梳理
NLU意图识别的流程说明 基于智能问答的业务流程,所谓的NLU意图识别就是针对已知的训练语料(如语料格式为\((x,y)\)格式的元组列表,其中\(x\)为训练语料,\(y\)为期望输出类别或者称为意 ...
- 自然语言处理:问答 + CNN 笔记
参考 Applying Deep Learning To Answer Selection: A Study And An Open Task follow: http://www.52nlp.cn/ ...
- 基于百度ai,图灵机器人,Flask 实现的网站语音智能问答
准备以下模块中的函数 from aip import AipSpeech import time import os import requests APP_ID = '15420654' API_K ...
- Android 智能问答机器人的实现
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/38498353 ,本文出自:[张鸿洋的博客] 今天看到一个ios写的图灵机器人,直 ...
- 《IBM BPM实战指南》读书笔记
理论 BPM不是一个IT术语,更不是因技术的发展而起源的,相反,BPM自始至终都是管理学的术语和概念.它关注的一直都是效率.成本.利润.质量等核心问题.BPM是一门学科和一种方法论,只是现代的企业管理 ...
- 深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.contrib.rnn.MultiRNNCell(堆叠多层LSTM) 4.mlstm_cell.zero_state(state初始化) 5.mlstm_cell(进行LSTM求解)
问题:LSTM的输出值output和state是否是一样的 1. rnn.LSTMCell(num_hidden, reuse=tf.get_variable_scope().reuse) # 构建 ...
随机推荐
- 浮窗WindowManager view返回和Home按键事件监听
出于功能需求,需要在所有的view之上显示浮窗,于是需要在WindowManager的View上处理返回键的响应, mFloatingWindowView = layoutInflater.infla ...
- 在C++ 程序中调用被C 编译器编译后的函数,为什么要加extern “C”
首先,作为extern是C/C++语言中表明函数和全局变量作用范围(可见性)的关键字,该关键字告诉编译器,其声明的函数和变量可以在本模块或其它模块中使用. 通常,在模块的头文件中对本模块提供给其它模块 ...
- 织梦dede如何去除Power by DedeCms
自从dedecms织梦系统更新到6.7日的版本,底部版权信息调用标签{dede:global.cfg_powerby/}会自动加上织梦官方的链接[Power by DedeCms ],想必很多新用户使 ...
- LibSVM 安装使用
知道这个库已经很长的时间了,一直没有实践,以前也看过svm的理论,今天开始安装一下一直感觉有错误,结果自己傻了,根本没有错,可以直接使用... libsvm参考资料: libsvm下载网址:http: ...
- Redis简单介绍以及数据类型存储
因为我们在大型互联网项目其中.用户訪问量比較大,比較多.会产生并发问题,对于此.我们该怎样解决呢.Redis横空出世,首先,我们来简单的认识一下Redis.具体介绍例如以下所看到的: Redis是一个 ...
- Linux C高级编程——网络编程基础(1)
Linux高级编程--BSD socket的网络编程 宗旨:技术的学习是有限的,分享的精神是无限的. 一网络通信基础 TCP/IP协议簇基础:之所以称TCP/IP是一个协议簇,是由于TCP/IP包括T ...
- WinDbg加载不同版本CLR
WinDbg调试.net2.0和.net4.0程序有所不同,因为.net4.0使用新版本的CLR.例如: mscoree.dll 变为 mscoree.dll 和 mscoreei.dll, msco ...
- windows下通过VNC图形化訪问Ubuntu桌面环境
要在windows下图形化訪问Ubuntu或其他Linux系统桌面环境有非常多方法.我比較喜欢的是使用VNC服务,须要在Ubuntu下安装vncserver和在windows下安装client訪问工具 ...
- 后端程序员看前端想死(三)是不是该学点js了
CSS盒子模型 div布局 js 这些都懂一点,但仅仅是懂一点,有时间就学一下咯
- 图像处理之滤波---gabor
http://blog.csdn.net/xiaowei_cqu/article/details/24745945 小魏北大