C++标准模板库(STL)和容器
1、什么是标准模板库(STL)?
(1)C++标准模板库与C++标准库的关系
C++标准模板库其实属于C++标准库的一部分,C++标准模板库主要是定义了标准模板的定义与声明,而这些模板主要都是
类模板,我们可以调用这些模板来定义一个具体的类;与之前的自己手动创建一个函数模版或者是类模板不一样,我们使用了
STL就不用自己来创建模板了,这些模板都定义在标准模板库中,我们只需要学会怎么使用这些类模板来定义一个具体的类,
然后能够使用类提供的各种方法来处理数据。
(2)STL六大组件:容器(containers)、算法(algorithms)、迭代器(iterators)、函数对象(functors)、适配器(adapters)、分配器(allocators)
2、迭代器
迭代器是一种对象,它能够用来遍历STL容器中的部分或全部元素,每个迭代器对象代表容器中的确定的地址,所以可以认为迭代器其实就是用来指向容器中数
据的指针,我们可以通过改变这个指针来遍历容器中的所有元素。
3、容器
首先,我们必须理解一下什么是容器,对比我们生活当中的容器,例如水杯、桶、水瓶等等这些东西,其实他们都是容器,他们的一个共同点就是:都是用来
存放液体的,能够用来存放一些东西;其实在我们的C++中说的这个容器其实作用也是用来存放"东西",但是存放的是数据,在C++中容器就是一种用来存放
数据的对象。
(1)C++中的容器其实是容器类实例化之后的一个具体的对象,那么可以办这个对象看成就是一个容器。
(2)因为C++中容器类是基于类模板定义的,也就是我们这里说的STL(标准模板类)。为什么需要做成模板的形式呢?因为我们的容器中存放的数据类型其实
是相同的,如果就因为数据类型不同而要定义多个具体的类,这样就不合适,而模板恰好又能够解决这种问题,所以C++中的容器类是通过类模板的方式定义的
,也就是STL。
(3)容器还有另一个特点是容器可以自行扩展。在解决问题时我们常常不知道我们需要存储多少个对象,也就是说我们不知道应该创建多大的内存空间来存放我们
的数据。显然,数组在这一方面也力不从心。容器的优势就在这里,它不需要你预先告诉它你要存储多少对象,只要你创建一个容器对象,并合理的调用它所提
供的方法,所有的处理细节将由容器来自身完成。它可以为你申请内存或释放内存,并且用最优的算法来执行您的命令。
(4)容器是随着面向对象语言的诞生而提出的,容器类在面向对象语言中特别重要,甚至它被认为是早期面向对象语言的基础。
4、容器的分类
STL对定义的通用容器分三类:顺序性容器、关联式容器和容器适配器。
我想说的是对于上面的每种类型的容器到底是是什么意思,其实没必要去搞懂,没什么价值,只要你能够大概理解知道即可,知道每种容器类型下有哪些具体的容器
即可。
顺序性容器:vector、deque、list
关联性容器:set、multiset、map、multimap
容器适配器:stack、queue、
本文主要介绍vector、list和map 这3种容器。
5、vector向量
vector向量是一种顺序行容器。相当于数组,但其大小可以不预先指定,并且自动扩展。它可以像数组一样被操作,由于它的特性我们完全可以将vector 看作动态数组。
在创建一个vector 后,它会自动在内存中分配一块连续的内存空间进行数据存储,初始的空间大小可以预先指定也可以由vector 默认指定。当存储的数据超过分配的
空间时vector 会重新分配一块内存块,但这样的分配是很耗时的,在重新分配空间时它会做这样的动作:
首先,vector 会申请一块更大的内存块;
然后,将原来的数据拷贝到新的内存块中;
其次,销毁掉原内存块中的对象(调用对象的析构函数);
最后,将原来的内存空间释放掉。
当vector保存的数据量很大时,如果此时进行插入数据导致需要更大的空间来存放这些数据量,那么将会大大的影响程序运行的效率,所以我们应该合理的使用vector。
(1)初始化vector对象的方式:
vector<T> v1; // 默认的初始化方式,内容为空
vector<T> v2(v1); // v2是v1的一个副本
vector<T> v3(n, i) // v3中包含了n个数值为i的元素
vector<T> v4(n); // v4中包含了n个元素,每个元素的值都是0
(2)vector常用函数
empty():判断向量是否为空,为空返回真,否则为假
begin():返回向量(数组)的首元素地址
end(): 返回向量(数组)的末元素的下一个元素的地址
clear():清空向量
front():返回得到向量的第一个元素的数据
back():返回得到向量的最后一个元素的数据
size():返回得到向量中元素的个数
push_back(数据):将数据插入到向量的尾部
pop_back():删除向量尾部的数据
.....
(3)遍历方式
vector向量支持两种方式遍历,因为可以认为vector是一种动态数组,所以可以使用数组下标的方式,也可以使用迭代器
#include <iostream>
#include <vector>
#include <list>
#include <map> using namespace std; int main(void)
{
vector<int> vec; vec.push_back();
vec.push_back();
vec.push_back();
vec.push_back();
vec.push_back(); cout << "向量的大小:" << vec.size() << endl; // 数组下标方式遍历vector
for (int i = ; i < vec.size(); i++)
cout << vec[i] << " ";
cout << endl; // 迭代器方式遍历vector
vector<int>::iterator itor = vec.begin();
for (; itor != vec.end(); itor++)
cout << *itor << " ";
cout << endl; return ;
}
6、双向链表list
对于链表我不想多说了,我之前已经学过链表,对于一个双向链表来说主要包括3个:指向前一个链表节点的前向指针、有效数据、指向后一个链表节点的后向指针
链表相对于vector向量来说的优点在于:(a)动态的分配内存,当需要添加数据的时候不会像vector那样,先将现有的内存空间释放,在次分配更大的空间,这样的话
效率就比较低了。(b)支持内部插入、头部插入和尾部插入
缺点:不能随机访问,不支持[]方式和vector.at()、占用的内存会多于vector(非有效数据占用的内存空间)
(1)初始化list对象的方式
list<int> L0; //空链表
list<int> L1(3); //建一个含三个默认值是0的元素的链表
list<int> L2(5,2); //建一个含五个元素的链表,值都是2
list<int> L3(L2); //L3是L2的副本
list<int> L4(L1.begin(),L1.end()); //c5含c1一个区域的元素[begin, end]。
(2)list常用函数
begin():返回list容器的第一个元素的地址
end():返回list容器的最后一个元素之后的地址
rbegin():返回逆向链表的第一个元素的地址(也就是最后一个元素的地址)
rend():返回逆向链表的最后一个元素之后的地址(也就是第一个元素再往前的位置)
front():返回链表中第一个数据值
back():返回链表中最后一个数据值
empty():判断链表是否为空
size():返回链表容器的元素个数
clear():清除容器中所有元素
insert(pos,num):将数据num插入到pos位置处(pos是一个地址)
insert(pos,n,num):在pos位置处插入n个元素num
erase(pos):删除pos位置处的元素
push_back(num):在链表尾部插入数据num
pop_back():删除链表尾部的元素
push_front(num):在链表头部插入数据num
pop_front():删除链表头部的元素
sort():将链表排序,默认升序
......
(3)遍历方式
双向链表list支持使用迭代器正向的遍历,也支持迭代器逆向的遍历,但是不能使用 [] 索引的方式进行遍历。
#include <iostream>
#include <vector>
#include <list>
#include <map> using namespace std; int main(void)
{
list<int> l1; // 插入元素方式演示
l1.push_front(); // 头部插入
l1.push_back(); // 尾部插入
l1.insert(l1.begin(), ); // 开始位置插入
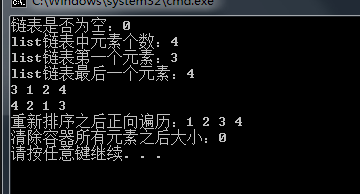
l1.insert(l1.end(), ); // 结束位置插入 cout << "链表是否为空:" << l1.empty() << endl;
cout << "list链表中元素个数:" << l1.size() << endl;
cout << "list链表第一个元素:" << l1.front() << endl;
cout << "list链表最后一个元素:" << l1.back() << endl; // 遍历链表正向
list<int>::iterator itor = l1.begin();
for (; itor != l1.end(); itor++)
cout << *itor << " ";
cout << endl; // 遍历链表逆向
list<int>::reverse_iterator reitor = l1.rbegin();
for (; reitor != l1.rend(); reitor++)
cout << *reitor << " ";
cout << endl; // 将链表排序
l1.sort();
itor = l1.begin();
cout << "重新排序之后正向遍历:";
for (; itor != l1.end(); itor++)
cout << *itor << " ";
cout << endl; // 清除容器中的所有元素
l1.clear();
cout << "清除容器所有元素之后大小:" << l1.size() << endl; return ;
}
代码运行结果:
7、map
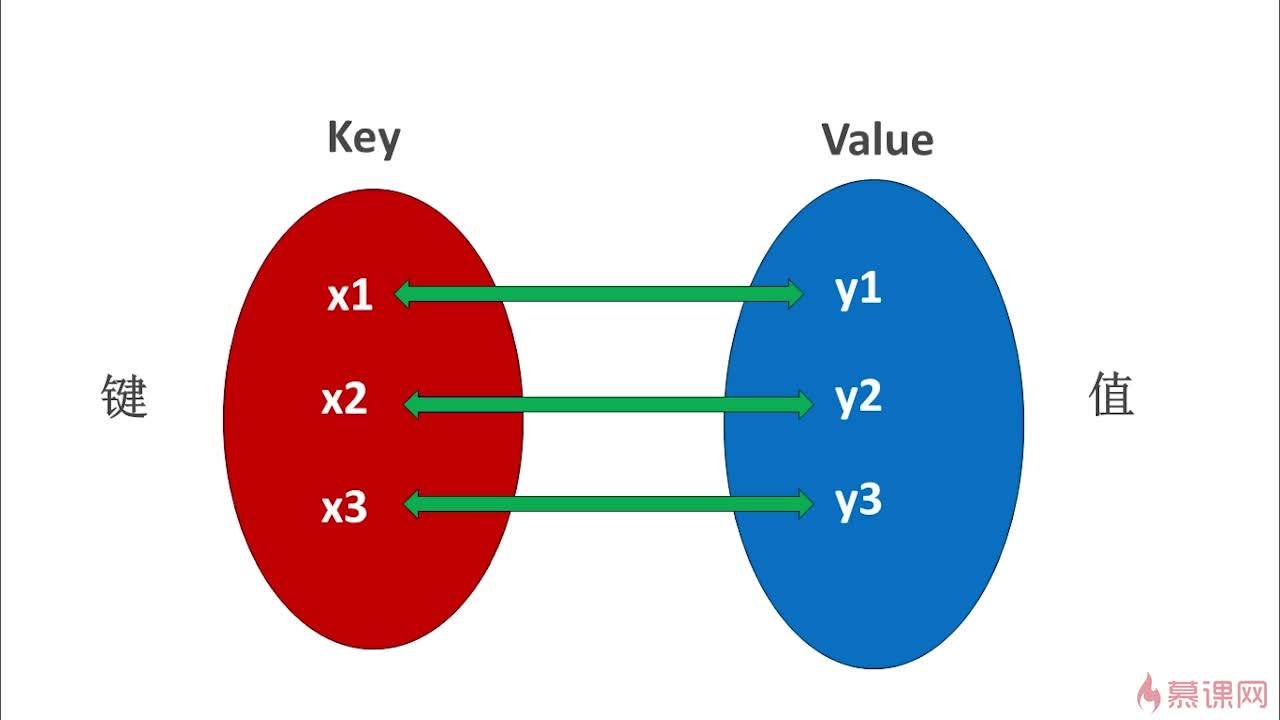
Map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。map内部自建一颗红黑树(一 种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的。至于二叉树这种数据结构,本人暂时没有任何了解。在map这个容器中,提供一种“键- 值”关系的一对一的数据存储能力。其“键”在容器中不可重复,且按一定顺序排列,至于怎么排列,那么红黑树这种数据结构的特性了。
(1)初始化map对象的方式
map<int, string> m1 = { { 1, "guangzhou" }, { 2, "shenzhen" }, { 3, "changsha" } }; // 实例化一个map容器,还有3组数据
map<char, string> m2; // 实例化一个空map容器
(2)map常用函数
begin():返回容器第一个元素的迭代器
end():返回容器最后一个元素之后的迭代器
rbegin():
rend():
clera():清除容器中所有元素
empty():判断容器是否为空
insert(p1):插入元素 p1 是通过pair函数建立的映射关系对
insert(pair<char, string>('S', "shenzhen")): 插入元素
size():返回容器中元素的个数
count():返回指定键对应的数据的出现的次数
get_allocator():返回map的配置器
swap():交换两个map容器的元素
.....
(3)遍历方式
map容器支持迭代器正向方式遍历和迭代器反向方式遍历,同时也支持 [] 方式访问数据,[]中的索引值是键值,这个一定要清楚
#include <iostream>
#include <stdio.h>
#include <string>
#include <stdlib.h>
#include <vector>
#include <list>
#include <map> using namespace std; int main(void)
{
map<int, string> m1 = { { , "guangzhou" }, { , "shenzhen" }, { , "changsha" } };
map<char, string> m2; // 建立映射关系对
pair<char, string> p1('G', "guangzhou");
pair<char, string> p2('S', "guangzhou");
pair<char, string> p3('C', "changsha"); // 插入数据
m2.insert(p1);
m2.insert(p2);
m2.insert(p3); cout << "map容器m1元素个数:" << m1.size() << endl;
cout << "map容器m2元素个数:" << m2.size() << endl; // 采用 [] 方式打印数据
cout << m1[] << " " << m1[] << " " << m1[] << endl;
cout << m2['G'] << " " << m2['S'] << " " << m2['C'] << endl; // 迭代器正向方式遍历
map<int, string>::iterator itor = m1.begin();
for (; itor != m1.end(); itor++)
{
cout << itor->first << ",";
cout << itor->second << endl;
} // 迭代器反向方式遍历
map<char, string>::reverse_iterator reitor = m2.rbegin();
for (; reitor != m2.rend(); reitor++)
{
cout << reitor->first << ",";
cout << reitor->second << endl;
} // 清空容器
m1.clear();
m2.clear(); return ;
}
8、顺序性容器和关联容器(本段来自其他博客,在此感谢)
(1)关联容器对元素的插入和删除操作比vector要快,因为vector是顺序存储,而关联容器是链式存储;比list 要慢,是因为即使它们同是链式结构,但list 是线性的,而关联容器是二叉树结构,其改变一个元素涉及到其它元素的变动比list 要多,并且它是排序的,每次插入和删除都需要对元素重新排序;
(2)关联容器对元素的检索操作比vector 慢,但是比list 要快很多。vector 是顺序的连续存储,当然是比不上的,但相对链式的list 要快很多是因为list 是逐个搜索,它搜索的时间是跟容器的大小成正比,而关联容器 查找的复杂度基本是Log(N) ,比如如果有1000 个记录,最多查找10 次,1,000,000 个记录,最多查找20 次。容器越大,关联容器相对list 的优越性就越能体现;
参考博客: http://www.cnblogs.com/xkfz007/articles/2534249.html
http://www.cnblogs.com/scandy-yuan/archive/2013/01/08/2851324.html
C++标准模板库(STL)和容器的更多相关文章
- 标准模板库(STL)学习探究之vector容器
标准模板库(STL)学习探究之vector容器 C++ Vectors vector是C++标准模板库中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库.vector之所以被 ...
- 【c++】标准模板库STL入门简介与常见用法
一.STL简介 1.什么是STL STL(Standard Template Library)标准模板库,主要由容器.迭代器.算法.函数对象.内存分配器和适配器六大部分组成.STL已是标准C++的一部 ...
- C++ 标准模板库(STL)
C++ 标准模板库(STL)C++ STL (Standard Template Library标准模板库) 是通用类模板和算法的集合,它提供给程序员一些标准的数据结构的实现如 queues(队列), ...
- STL学习系列之一——标准模板库STL介绍
库是一系列程序组件的集合,他们可以在不同的程序中重复使用.C++语言按照传统的习惯,提供了由各种各样的函数组成的库,用于完成诸如输入/输出.数学计算等功能. 1. STL介绍 标准模板库STL是当今每 ...
- 标准模板库--STL
标准模板库STL 1.泛型程序设计 C++ 语言的核心优势之一就是便于软件的重用 C++中有两个方面体现重用: 1.面向对象的思想:继承和多态,标准类库 2.泛型程序设计(generic progra ...
- 实验8 标准模板库STL
一.实验目的与要求: 了解标准模板库STL中的容器.迭代器.函数对象和算法等基本概念. 掌握STL,并能应用STL解决实际问题. 二.实验过程: 完成实验8标准模板库STL中练习题,见:http:// ...
- C++的标准模板库STL中实现的数据结构之链表std::list的分析与使用
摘要 本文主要借助对C++的标准模板库STL中实现的数据结构的学习和使用来加深对数据结构的理解,即联系数据结构的理论分析和详细的应用实现(STL),本文是系列总结的第二篇.主要针对线性表中的链表 ST ...
- C++ 标准模板库STL 队列 queue 使用方法与应用介绍
C++ 标准模板库STL 队列 queue 使用方法与应用介绍 queue queue模板类的定义在<queue>头文件中. 与stack模板类很相似,queue模板类也需要两个模板参数, ...
- 标准模板库(STL)学习探究之stack
标准模板库(STL)学习探究之stack queue priority_queue list map/multimap dequeue string
- C++的标准模板库STL中实现的数据结构之顺序表vector的分析与使用
摘要 本文主要借助对C++的标准模板库STL中实现的数据结构的学习和使用来加深对数据结构的理解.即联系数据结构的理论分析和详细的应用实现(STL),本文是系列总结的第一篇,主要针对线性表中的顺序表(动 ...
随机推荐
- 前端-CSS-8-浮动与清楚浮动(重点)
<!-- 浮动是css里面布局最多的一个属性 效果: 两个元素并排了,并且两个元素都能够设置宽度和高度 浮动想学好:一定要知道它的四个特性: 1.浮动的元素脱标 2.浮动的元素互相贴靠 3.浮动 ...
- python内置函数 eval()、exec()以及complie()函数
1.eval函数 eval() 函数用来执行一个字符串表达式,并返回表达式的值. eval(expression[, globals[, locals]]) 参数 expression -- 表达式. ...
- Oracle+Mybatis批量插入,更新和删除
1.插入 (1)第一种方式:利用<foreach>标签,将入参的list集合通过UNION ALL生成虚拟数据,从而实现批量插入(验证过) <insert id="inse ...
- 一个简单例子弄懂什么是javascript函数劫持
javascript函数劫持很简单,一般情况下,只要在目标函数触发之前,重写这个函数即可. 比如,劫持eval函数的代码如下: var _eval=eval; eval=function(x){ if ...
- AUC理解
https://www.zhihu.com/question/39840928 机器学习和统计里面的auc怎么理解?
- 两个onCreate方法?你真的了解onCreate()么?
Activity的onCreate方法一直是我们编写一个activity最先重载的方法.细心的小伙伴在编写代码的时候回看到这样一幕: 咦,这里怎么会有两个onCreate提供给我们重载?选择困难症患者 ...
- suse11 sp4(虚拟机) 安装程序时报错 找不到iso
一个可能原因是iso掉了.我用的virtualbox安装的suse,支持不是很好,suse启动后,因为驱动问题强制umount了iso,所以掉了.重启后,不要去动virtualbox插件问题,插件错误 ...
- CSS中的各种width(宽度)
一 window对象的innerWidth.outerWidth innerWidth是可用区域的宽度(内容区 + 滚动条) outerWidth是浏览器窗口的宽度(可用区域的宽度+审查元素区域的宽度 ...
- TZOJ 5279 马拉松比赛(广搜)
描述 有一块矩形的海域,其中有陆地也有海洋,这块海域是CSUFT_ACM集训队的训练基地,这一天,昌神说要集训队的队员不能总是训练,于是昌神提出了中南林ACM集训队第一场环陆马拉松比赛,顾名思义就是围 ...
- Java学生信息增删改查(并没用数据库)
一个泛型的应用,Java版本增删改查,写的简陋,望批评指正 2016-07-02 很久前写的一个程序了.拿出来存一下,不是为了展示啥,自己用的时候还可以看看.写的很粗糙. import java.io ...