Hadoop整理三(Hadoop分布式计算框架MapReduce)
一.概念
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
大规模数据处理时, MapReduce 在三个层面上的基本构思 。
如何对付大数据处理:分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。
上升到抽象模型: Mapper 与 Reducer
MPI等并行计算方法缺少高层并行编程模型,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
上升到构架:统一构架,为程序员隐藏系统层细节
MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统
层面的处理细节。
不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
序列化是指将结构化的数据转化为字节流以便在网络上传输或写入到磁盘进行永久存储的过程,反序列化是指将字节流转换为结构化对象的逆过程。序列化常见应用场景:进程间通信和永久存储。
Hadoop中,序列化要满足:紧凑,快速,可扩展,支持互相操作。Hadoop中使用了自己的序列化格式Writable。它绝对紧凑、速度快、但不容易扩展。
自定义数据类型:
实现Writable接口,以便该数据能被序列化后完成网络传输或文件输入/输出。
如果该数据需要作为主键key使用,或需要比较数值大小时,则需要实现WritableComparable接口。
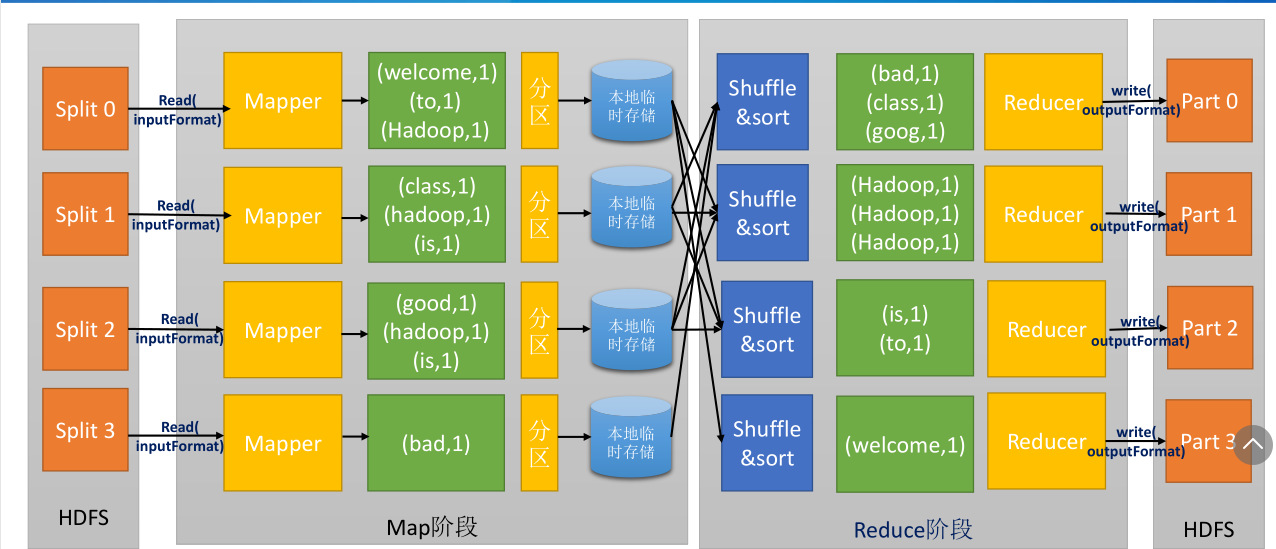
集群上最紧俏的资源便是网络带宽,因此尽量减少map和reduce阶段的网络传输对MapReduce的性能提升是很重要的。Hadoop为map任务的输出指定了一个合并函数(combiner),合并函数的输出作为reduce的输入。Combiner是的map的输出结果更加紧凑,同时减少了写磁盘和网络传输的数据量。 Combiner 又称为Local Reducer 。
Hadoop整理三(Hadoop分布式计算框架MapReduce)的更多相关文章
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- Hadoop 系列(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集. MapReduce ...
- Hadoop 三剑客之 —— 分布式计算框架 MapReduce
一.MapReduce概述 二.MapReduce编程模型简述 三.combiner & partitioner 四.MapReduce词频统计案例 4.1 项目简介 ...
- Hadoop整理四(Hadoop分布式计算框架MapReduce)
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提 ...
- 分布式计算框架-MapReduce 基本原理(MP用于分布式计算)
hadoop最主要的2个基本的内容要了解.上次了解了一下HDFS,本章节主要是了解了MapReduce的一些基本原理. MapReduce文件系统:它是一种编程模型,用于大规模数据集(大于1TB)的并 ...
- 2_分布式计算框架MapReduce
一.mr介绍 1.MapReduce设计理念是移动计算而不是移动数据,就是把分析计算的程序,分别拷贝一份到不同的机器上,而不是移动数据. 2.计算框架有很多,不是谁替换谁的问题,是谁更适合的问题.mr ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- Hadoop第三课
1.3Hadoop基础知识 1.3.1术语解释 1.Hadoop1.0 • 第一代Hadoop,由分布式文件系统HDFS 和分布式计算框架MapReduce组成 • HDFS由一个NameNode和多 ...
- hadoop深入研究:(十三)——序列化框架
hadoop深入研究:(十三)--序列化框架 Mapreduce之序列化框架(转自http://blog.csdn.net/lastsweetop/article/details/9376495) 框 ...
随机推荐
- C#委托Code
class Program { delegate double ProcessDelegate(double param1, double param2); static double Multipl ...
- java并发实践笔记
底层的并发功能与并发语义不存在一一对应的关系.同步和条件等底层机制在实现应用层协议与策略须始终保持一致.(需要设计级别策略.----底层机制与设计级策略不一致问题). 简介 1.并发简史.(资源利用率 ...
- [转载]WebStorm快捷键操作
http://www.cnblogs.com/yangjinjin/archive/2013/01/30/2883172.html 1. ctrl + shift + n: 打开工程中的文件,目的是打 ...
- Java内存模型简析
1.多线程基础 线程通信,是指线程之间以何种机制来交换信息.其中通信的机制有两种:内存共享和消息传递.内存共享是指线程之间通过写-读内存中的公共状态隐式进行通讯(Java):消息传递在线程之间没有公共 ...
- hdu 1253 胜利大逃亡 (广搜)
题目链接 Problem Description Ignatius被魔王抓走了,有一天魔王出差去了,这可是Ignatius逃亡的好机会. 魔王住在一个城堡里,城堡是一个ABC的立方体,可以被表示成A个 ...
- sklearn_模型遍历
# _*_ coding = utf_8 _*_ import matplotlib.pyplot as plt import seaborn as sns import pandas as pd f ...
- 兴人类TDD培训札记
兴人类TDD培训札记 恰同学少年,风华正茂:书生意气,挥斥方遒 -- <沁园春 长沙> 幸之 前不久,非常幸运地全程参与了公司与南京5所知名高校合作的"兴人类TDD培训" ...
- javaScript书写规范
命名规范. 常量名 全部大写并单词间用下划线分隔 如:CSS_BTN_CLOSE.TXT_LOADING对象的属性或方法名 小驼峰式(little camel-case) 如: ...
- C#事件实现文件下载时进度提醒
C#中的事件是建立在委托的基础上,标准的事件模型应该包括以下几点: 声明一个用于定义事件的委托,这里用系统自带的泛型委托原型EventHandler<TEventArgs>,如:publi ...
- 【转】GridView 加载空行并点击编辑每一个单元格
代码 <script runat="server"> protectedvoid Button1_Click(object sender, System.EventAr ...