Erlang数据类型的表示和实现(3)——列表
列表
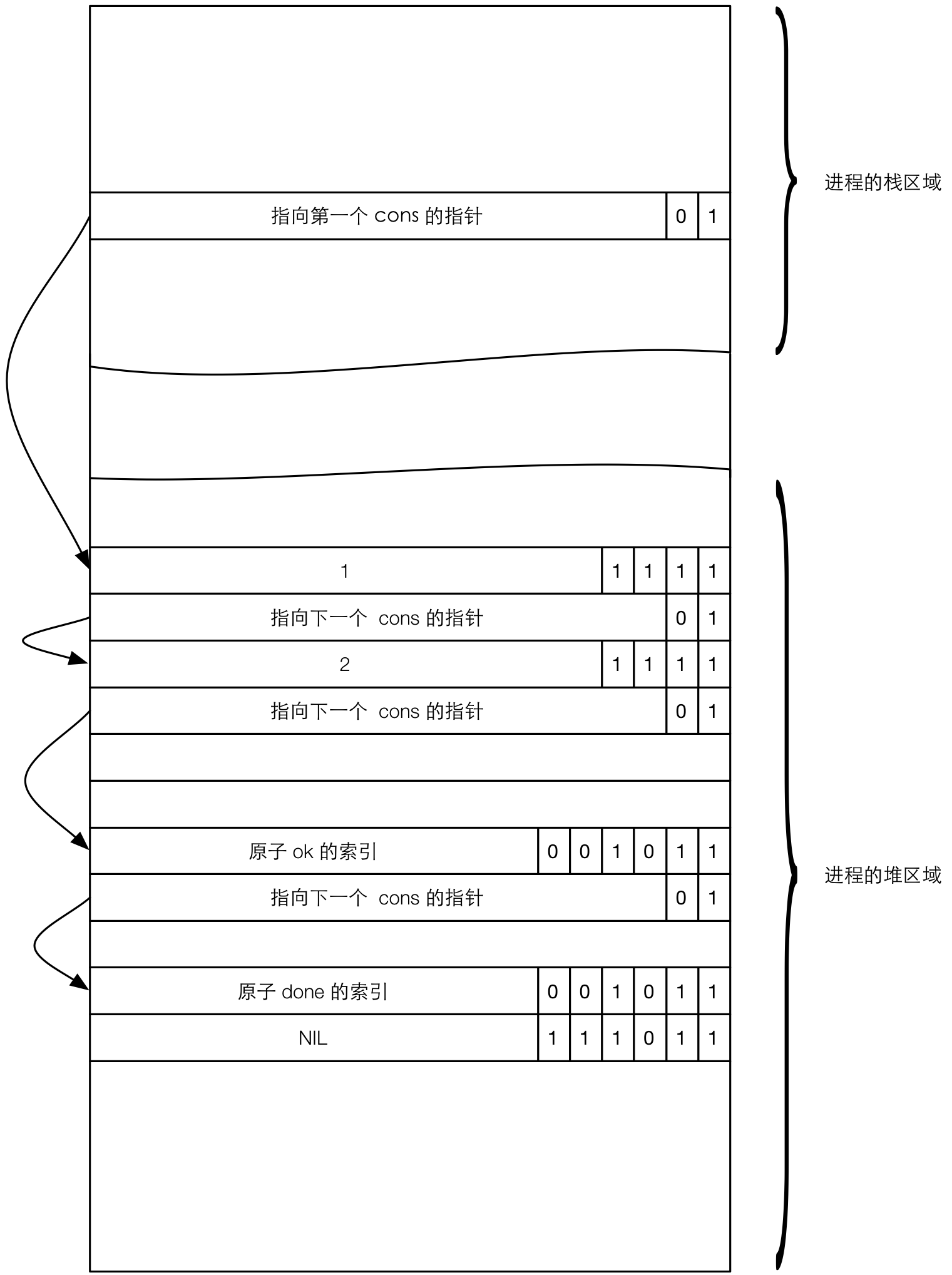
Erlang 中的列表是通过链表实现的,表示列表的 Eterm 就是这个链表的起点。列表 Eterm 中除去 2 位标签 01 之外,剩下的高 62 位表示指向列表中第一个元素的指针的高 62 位。我们在生成一个列表的时候,会采用这样的语法:L = [Head | Tail],Head 表示要添加到头部的单个元素,Tail 表示另一个列表。这种 Head 和 Tail 的组合称为一个 Cons 单元。在函数式语言里面,获得 Head 的操作称为 CAR,获得 Tail 的操作称为 CDR。结合我们对 Eterm 的理解,可以看出在 Erlang 的 Eterm 架构下,Head 可以是一个任意类型的 Eterm,Tail 则是一个列表类型的 Eterm。当 Tail 为 NIL 的时候(即表示为 []),这个列表称为是 well-formed 列表。指向列表第一个元素的 Eterm 一般放在进程的栈中。下面举个例子,假设我们有这样一个列表:L = [1,2,ok,done],现在暂时用这个简单的列表来作为示例,这个列表在进程内的示意图如下所示:
在构造一个新的列表的时候,如果新的列表引用了其他列表,那么引用了其他列表的元素本身就是一个 Cons 单元格。例如,我们有下面两个列表:
1 L1 = [1, 2, 3].
2 L2 = [L1, L1, L1].
L2 中存在 3 个对 L1 的引用,Erlang 可以很聪明地复用 L1,内存中实际上只有一份对 L1 的拷贝,如下图所示:
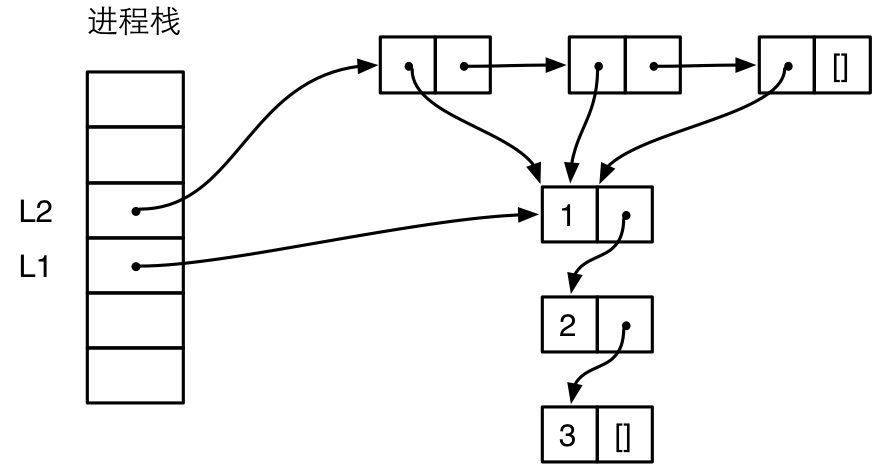
为了简洁,这个图相比前一个图简化了,不再严格表示栈和堆的相对位置,不再严格表示 Eterm 的标签。从图中可以看到,列表 L2 中的 3 个 cons 单元格都引用了 L1。通过未文档化的 BIF erts_debug:size() 可以获得一个对象占用的字数:
83> L1 = [1,2,3].
[1,2,3]
84> erts_debug:size(L1).
6
85> L2 = [L1,L1,L1].
[[1,2,3],[1,2,3],[1,2,3]]
86> erts_debug:size(L2).
12
L1 占用 6 个字,因为有 3 个 cons 单元格,每个占用 2 个字。L2 其实应该也占用 6 个字,因为 L2 本身占用的也是 3 个 cons 单元格。但是 erts_debug:size() 算法计算的是整个对象树的大小[注3],所以还要加上 L1 占用的 6 个字,一共是 12 个字。erts_debug:size() 在统计对象大小的时候会记住子对象是否已经被引用过,所以能反映出对象树的真实大小。通过另一个未文档化的 BIF 调用 erts_debug:flat_size() 可以得到对象平坦化后的大小:
88> erts_debug:flat_size(L1).
6
89> erts_debug:flat_size(L2).
24
Erlang 这种共享对象的方式想必是极好的,最直接的好处就是节省了内存。但是这种对象共享在一种情况下会被破坏,那就是跨进程的时候。由于进程之间是不能共享对象的,所以像列表这种复合对象跨进程传递的时候,例如当做参数传入 spawn 创建新进程的时候,以及通过消息发送给其他进城的时候,对象共享会被破坏。在上面的例子中,如果要把 L2 发送给另一个进程,为了严格执行进程间不共享数据的原则,L2 必须被深度拷贝到新的进程的堆中。在深度拷贝的时候,在新的进程的堆中会创建 3 份 L1 的拷贝,成了下面这样:
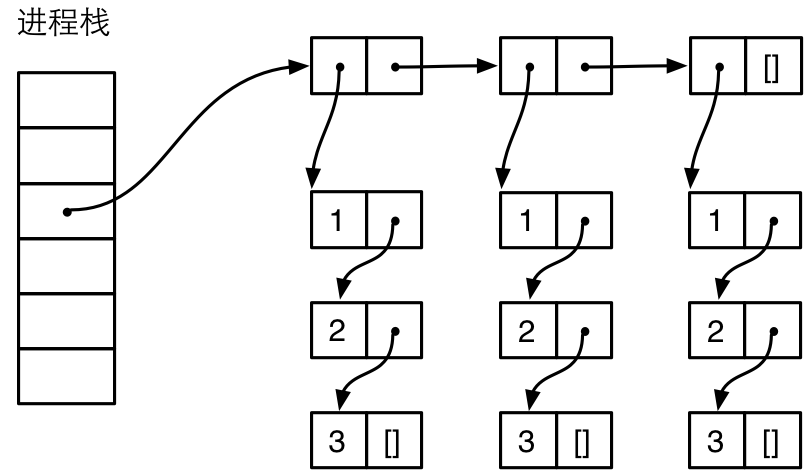
看看 L2 被发送到其他进程之后 erts_debug:size() 得到的值:
112> P1 = spawn(fun() -> receive L -> io:format("~w~n", [erts_debug:size(L)]) end end).
<0.198.0>
113> P1 ! L2.
24
[[1,2,3],[1,2,3],[1,2,3]]
shell 进程将 L2 发送到 P1 之后,P1 请求 io 服务器打印出收到的 L 大小为 24,也就是 L2 平坦化之后的大小。由于 Eterm 跨进程传输的时候会被平坦化,所以在某些情况下如果被发送的列表中引用了好几次某个特别大的对象,那么平坦化之后会占用大量内存,甚至把 Erlang 虚拟机搞挂掉。2012 年 Erlang Workshop 上有一篇论文 [1] 就记录了这么一个案例,并且提出了一种跨进程也能保持共享对象树形结构的优化方案。这个方案也属于 D2.3,可能会引入未来版本的 Erlang 虚拟机。
了解了列表的结构和实现方式之后,我们就可以更高效地使用列表这种数据结构。Erlang 标准库中 lists 模块下提供了很多针对列表的操作。在选择 api 完成我们的需求的时候,应该在了解数据结构内部实现的基础上考虑,如果我自己实现这个 api,怎么样才是最高效的(比如说复制的次数最少),一般情况下,库中选择的实现方案就是自己能想到的最高效的方案。比如说两个列表拼接的操作:append(L1, L2),最简单的实现方法就是直接 L1 ++ L2 了。那么这种做法是否高效呢?很高效!因为 ++ 操作是一个 BIF,在 Erlang 内部是通过 C 语言实现的:复制 L1,然后将 L1 最后一个 cons 单元格的 CDR 修改为指向 L2。这种实现方式是最高效的,因为将复制的必要性降到最低。L1 是必须复制的,因为不复制的话最后一个 cons 单元格应该指向 L2 还是 NIL 呢?由于 ++ 操作要复制 L1,所以要注意如果 L1 很长,那么复制的开销也是很大的。
由于列表的操作是 Erlang 中非常频繁的操作,所以有很多不方便用纯 Erlang 实现或实现效率低的操作都被做成 BIF 了,在虚拟机的层面直接操作列表的效率很高,避免了大量虚拟机指令的分发和解释执行。比如 length/1、++、--、member/2 和 reverse/2 等。不过涉及到列表的时候依然要注意,尽管有些操作效率很高,但这只是针对实现上不需要经过 Erlang 虚拟机的多重解释执行而言的,时间复杂度依然和列表长度呈线性关系,而函数式语言的程序写起来可能算法复杂度不如几个 for 循环嵌套那么直观,所以不要一不小心就写出 n 的好几次方的糟糕算法。
以上就是列表的实现,下面我们来看 Boxed 对象的表示和实现。
[注3] erts_debug:size() BIF 调用并不会陷入 Erlang 虚拟机从虚拟机中直接获得对象大小,而是根据 Erlang 虚拟机对数据结构的表示形式推算出来的。
[1] N. Papaspyrou and K. Sagonas. On preserving term sharing in the erlang virtual machine. In Proceedings of the eleventh ACM SIGPLAN workshop on Erlang workshop, Erlang ’12, pages 11–20, New York, NY, USA, 2012. ACM.
Erlang数据类型的表示和实现(3)——列表的更多相关文章
- Erlang数据类型的表示和实现(2)——Eterm 和立即数
Erlang 数据类型的内部表示和实现 Erlang 中的变量在绑定之前是自由的,非绑定变量可以绑定一次任意类型的数据.为了支持这种类型系统,Erlang 虚拟机采用的实现方法是用一个带有标签的机器字 ...
- Erlang数据类型的表示和实现(1)——数据类型回顾
本文介绍 Erlang 语言中使用的各种数据类型以及这些数据类型在 Erlang 虚拟机内部的表示和实现.了解数据类型的实现可以帮助大家在实际开发过程中正确选择数据类型,并且可以更好更高效地操作这些数 ...
- 总结day6 ---- set集合,基本类型的相互转化,编码,数据类型总结,循环时候不要动列表或者字典,深浅copy
python小数据池,代码块的最详细.深入剖析 一. id is == 二. 代码块 三. 小数据池 四. 总结 一,id,is,== 在Python中,id是什么?id是内存地址,比如你利用id ...
- Erlang数据类型的表示和实现(5)——binary
binary 是 Erlang 中一个具有特色的数据结构,用于处理大块的“原始的”字节块.如果没有 binary 这种数据类型,在 Erlang 中处理字节流的话可能还需要像列表或元组这样的数据结构. ...
- Erlang数据类型的表示和实现(4)——boxed 对象
Boxed 对象 Boxed 对象是比较复杂的对象,在 Erlang 中主标签为 10 的 Eterm 表示一个对 boxed 对象的引用.这个 Eterm 除去标签之后剩下的实际上是一个指针,指向具 ...
- python学习道路(day2note)(数据类型,运算符,字符串,列表)
一,数据类型 1.1数字 数字分为int(整型),long(长整型),float(浮点型) 1.1.1 int整型的取值范围为 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31- ...
- 【笔记】Python基础一 :变量,控制结构,运算符及数据类型之数字,字符串,列表,元组,字典
一,开发语言介绍 高级语言:Java,C#,Python ==>产生字节码 低级语言:C,汇编 ==>产生机器码 高级语言开发效率高,低级语言运行效率 ...
- python数据类型内置方法 字符串和列表
1.字符串 内置方法操作# a = 'qqssf'#1. print(a[-1:]) #按索引取,正向从0开始,反向从-1开始# print(len(a)) #取长度# a = 'qqssf'# 2. ...
- python_04 基本数据类型、数字、字符串、列表、元组、字典
基本数据类型 所有的方法(函数)都带括号,且括号内没带等号的参数需传给它一个值,带等号的参数相当于有默认值 1.数字 int 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1 ...
随机推荐
- DevOps 解读
本文为 转载文章, 非原创 DevOps DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化.运 ...
- bat批处理文件自动判断系统版本信息(转载)
@echo offver|find "Version 5.0" >nulif not errorlevel 1 goto Windows2Kver|find "版本 ...
- Spring Cloud和Dubbo整合开发笔记(1)
一.需求背景: 公司内部老项目微服务技术栈使用Dubbo, 新项目技术栈使用主流的Spring Cloud相关组件开发,新旧项目涉及交互调用,无法直接通信数据传递. 老项目基于Dubbo,重构代码升级 ...
- django之models学习总结
from django.db import models # Create your models here. class Classes(models.Model): ''' 班级表 ''' tit ...
- Java中队列
定义 队的操作是在两端进行,一端只能进行插入操作(入队),称为队尾,一端只能进行删除操作(出队),称为队尾. 队列的运算规则是FIFO(first in first out). 队列的入队.出队操作分 ...
- Tarjan算法初探 (1):Tarjan如何求有向图的强连通分量
在此大概讲一下初学Tarjan算法的领悟( QwQ) Tarjan算法 是图论的非常经典的算法 可以用来寻找有向图中的强连通分量 与此同时也可以通过寻找图中的强连通分量来进行缩点 首先给出强连通分量的 ...
- Redis之Redis安装(Mac OS版本)
各版本下载地址:http://download.redis.io/releases,本教程使用版本为redis-5.0.4. ##进入应用安装目录 cd /usr/local ##下载安装包 wget ...
- centos下安装myrocksdb
承接上一篇,https://www.cnblogs.com/lunyu/p/10190364.html .编译安装myrocks的整个过程,特别是第2步和第7步,让人冗长难耐.因此编译安装成功后省去这 ...
- c#操作注册表的意外
因为要在C/S程序中使用WebBrowser控件,因为默认的IE版本很低,无法使用Html5功能,故需通过把程序名写入注册表的方法指定IE版本. 但操作的过程中出现一个问题: 1.使用代码找到相关项, ...
- 20155222卢梓杰 课堂测试ch06补做
20155222卢梓杰 课堂测试ch06补做 1.下面代码中,对数组x填充后,采用直接映射高速缓存,所有对x和y引用的命中率为() A . 1 B . 1/4 C . 1/2 D . 3/4 正确答案 ...