如何快速分析出现性能问题的Linux服务器
Brendan Gregg曾经分享过当遇到一个系统性能问题时,如何利用登录的前60秒对系统的性能情况做一个快速浏览和分析,主要包括如下10个工具,这是一个非常有用且有效的工具列表。本文将详细介绍这些命令及其扩展选项的意义,及其在实践中的作用。并利用一个实际出现问题的例子,来验证这些套路是不是可行,下面工具的屏幕输出结果都来自这个出现问题的系统。
# 系统负载概览
uptime# 系统日志
dmesg | tail# CPU
vmstat 1
mpstat -P ALL 1
pidstat 1# Disk
iostat -xz 1# 内存
free -m# 网络
sar -n DEV 1
sar -n TCP,ETCP 1# 系统概览
top
上面的工具都基于内核提供给用户态的统计,并以计数器形式展示,是快速排查时的利器。对于应用和系统的进一步跟踪(tracing),则需要利用strace和systemtap等工具,不在本文的范畴。
注意:
- 如上基于CPU, 内存,I/O,网络等的分类只是基于工具默认选项的分类,比如pidstat,默认展示进程的CPU统计,但是利用-d参数可以展示进程的I/O统计。又比如vmstat,虽然名称是查看虚拟内存的工具,但默认展示了负载,内存,I/O,系统,CPU等多方面的信息。
- 部分工具需要安装sysstat包。
1. uptime
[root@nginx1 ~]# uptime
:: up days, :, user, load average: 1.13, 0.41, 0.18
uptime是快速查看load average的方法,在Linux中load average包括处于runnable和uninterruptable状态的进程总数,runnable状态包括在CPU上运行的进程和在run queue里waiting for run time等待CPU的进程;uninterruptable状态的进程是在等待一些I/O访问,比如等待disk的返回。Load average没有根据系统的CPU数量做格式化,所以load average 1表示单CPU系统在对应时间段内(1分钟, 5分钟, 15分钟)一直负载饱和,而在4 CPU的系统中,load average 1表示有75%的时间在idle。
Load average体现了一个high level的负载概览,但是可能需要和别的工具一起来使用以了解更多信息,比如处于runable和uninterruptable的实时进程数量分别是多少,可以用下面将介绍到的vmstat来查看。1分钟,5分钟,15分钟的负载平均值同时能体现系统负载的变化情况。例如,如果你要检查一个问题服务器,当你看到1分钟的平均负载值已经远小于15分钟的平均负载值,则意味这也许你登录晚了点,错过了现场。用top或者w命令,也可以看到load average信息。
上面示例中最近1分钟内的负载比15分钟内的负载高了不少 (因为是个测试的例子,1.13可以看作明显大于0.18,但是在生产系统上这不能说明什么)。
2. dmesg | tail
[root@nginx1 ~]# dmesg | tail
[3128052.929139] device eth0 left promiscuous mode
[3128104.794514] device eth0 entered promiscuous mode
[3128526.750271] device eth0 left promiscuous mode
[3537292.096991] device eth0 entered promiscuous mode
[3537295.941952] device eth0 left promiscuous mode
[3537306.450497] device eth0 entered promiscuous mode
[3537307.884028] device eth0 left promiscuous mode
[3668025.020351] bash (): drop_caches:
[3674191.126305] bash (): drop_caches:
[3675304.139734] bash (): drop_caches:
dmesg用于查看内核缓冲区存放的系统信息。另外查看/var/log/messages也可能查看出服务器系统方面的某些问题。
上面示例中的dmesg没有特别的值得注意的错误。
3. vmstat 1

vmstat简介:
- vmstat是virtual memory stat的简写,能够打印processes, memory, paging, block IO, traps, disks and cpu的相关信息。
- vmstat的格式:vmstat [options] [delay [count]]。在输入中的1是延迟。第一行打印的是机器启动到现在的平均值,后面打印的则是根据deley间隔的取样结果,也就是实时的结果。
结果中列的含义:
Procs(进程)
r: The number of runnable processes (running or waiting for run time).
b: The number of processes in uninterruptible sleep.
注释:r表示在CPU上运行的进程和ready等待运行的进程总数,相比load average, 这个值更能判断CPU是否饱和(saturation),因为它没有包括I/O。如果r的值大于CPU数目,即达到饱和。
Memory
swpd: the amount of virtual memory used.
free: the amount of idle memory.
buff: the amount of memory used as buffers.
cache: the amount of memory used as cache.
Swap
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
注释:swap-in和swap-out的内存。如果是非零,说明主存中的内存耗尽。
IO
bi: Blocks received from a block device (blocks/s).
bo: Blocks sent to a block device (blocks/s).
System (中断和进程上下文切换)
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
CPU
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
根据user+system时间,可以判断CPUs是否繁忙。如果wait I/O一直维持一定程度,说明disk有瓶颈,这时CPUs是"idle"的,因为任务都被block在等待disk I/O中。wait I/O可以被视为另一种形式的CPU idle,并且说明idle的原因就是在等待disk I/O的完成。
处理I/O需要花费system time,在将I/O提交到disk driver之前可能要经过remap, split和merge等操作,并被I/O scheduler调度到request queue。如果处理I/O时平均system time比较高,超过20%,则要进一步分析下,是不是内核处理I/O时的效率有问题。
如果用户空间的CPU使用率接近100%,不一定就代表有问题,可以结合r列的进程总数量看下CPU的饱和程度。
上面示例可以看到在CPU方面有一个明显的问题。user+system的CPU一直维持在50%左右,并且system消耗了大部分的CPU。
4. mpstat -P ALL 1
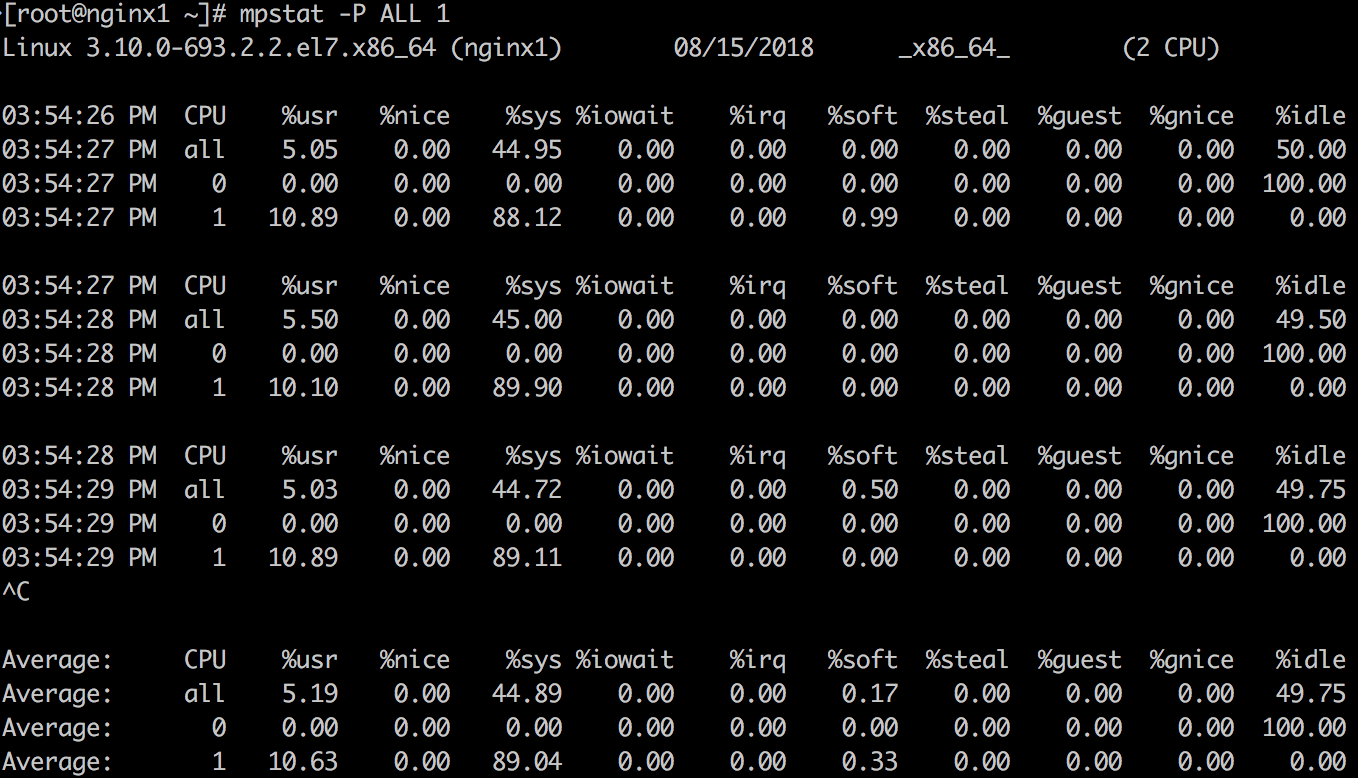
mpstat可以打印按照CPU的分解,可以用来检查不不均衡的情况。
上面示例结果可以印证vmstat中观察到的结论,并且可以看到服务器有2个CPU,其中CPU 1的使用率一直维持在100%,而CPU 0并没有什么负载。CPU 1的消耗主要在内核空间,而非用户空间。
5. pidstat 1
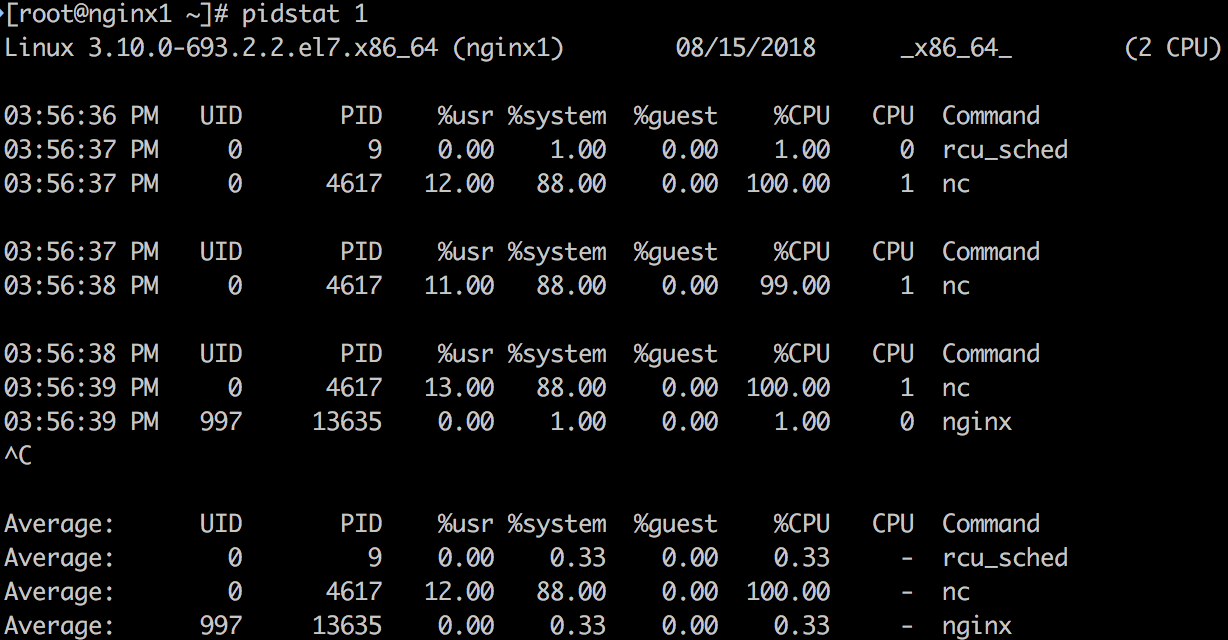
默认pidstat类似于top按照进程的打印方式,不过是以滚动打印的方式,和top的清屏方式不同。利用-p可以打出指定进程的信息,-p ALL可以打出所有进程的信息。如果没有指定任何进程默认相当于-p ALL,但是只打印活动进程的信息(统计非0的数据)。
pidstat不只可以打印进程的CPU信息,还可以打印内存,I/O等方面的信息,如下是比较有用的信息:
- pidstat -d 1:看哪些进程有读写。
- pidstat -r 1:看进程的page fault和内存使用。没有发生page fault的进程默认不会被打印出来,可以指定-p和进程号来打印查看内存。
- pidstat -t: 利用-t查看线程信息,可以快速查看线程和期相关线程的关系。
- pidstat -w:利用-w查看进程的context switch情况。输出:
- cswch/s: 每秒发生的voluntary context switch数目 (voluntary cs:当进程被block在获取不到的资源时,主动发生的context switch)
- nvcswch/s: 每秒发生的non voluntary context switch数目 (non vloluntary cs:进程执行一段时间用完了CPU分配的time slice,被强制从CPU上调度下来,这时发生的context switch)
上面示例中可以明确得看到是nc这个进程在消耗CPU 1 100%的CPU。因为测试系统里消耗CPU的进程比较少,所以一目了然,在生产系统中pidstat应该能输出更多正在消耗CPU的进程情况。
6. iostat -zx 1
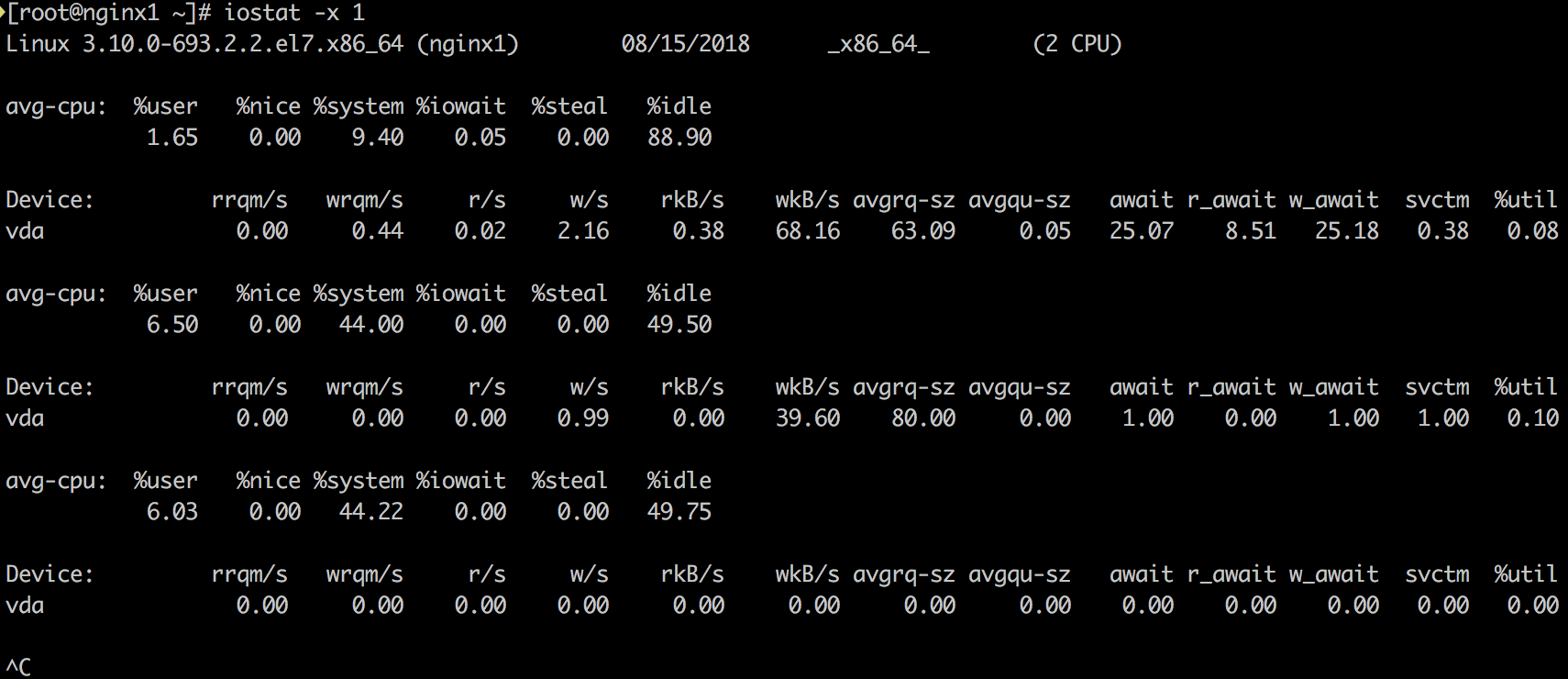
了解块设备(block device, 这里是disk)负载和性能的工具。主要看如下指标:
- r/s, w/s, rkB/s, wkB/s:每秒完成的读请求次数(read requests, after merges),每秒完成的写请求次数(write requests completed, after merges),每秒读取的千字节数,每秒写入的千字节数。这些指标可以看出disk的负载情况。一个性能问题可能仅仅是因为disk的负载过大。
- await:每个I/O平均所需的时间,单位为毫秒。await不仅包括硬盘设备处理I/O的时间,还包括了在kernel队列中等待的时间。要精确地知道块设备service一个I/O请求地时间,可供iostat读取地内核统计并没有体现,需要用如blktrace这样地跟踪工具来跟踪。对于blktrace来说,D2C的时间间隔代表硬件块设备地service time,Q2C代表整个I/O请求所消耗的时间,即iostat的await。
- avgqu-sz:队列里的平均I/O请求数量 (更恰当的理解应该是平均未完成的I/O请求数量)。如果该值大于1,则有饱和的趋势 (当然设备可以并发地处理请求,特别是一个front对多个backend disk的虚拟设备)。
- %util:设备在处理I/O的时间占总时间的百分比。表示该设备有I/O(即非空闲)的时间比率,不考虑I/O有多少,只考虑有没有。通常该指标达到60%即可能引起性能问题 (可以根据await指标进一步求证)。如果指标接近100%,通常就说明出现了饱和。
如果存储设备是一个对应多个后端磁盘的逻辑磁盘,那么100%使用率可能仅仅表示一些I/O在处理时间占比达到100%,其他后端磁盘不一定也到达了饱和。请注意磁盘I/O的性能问题并不一定会造成应用的问题,很多技术都是使用异步I/O操作,所以应用不一定会被block或者直接受到延迟的影响。
7. free -m
# free -m
total used free shared buff/cache available
Mem:
Swap:
查看内存使用情况。倒数第二列:
- buffers: buffer cache,用于block device I/O。
- cached: page cache, 用于文件系统。
Linux用free memory来做cache, 当应用需要时,这些cache可以被回收。比如kswapd内核进程做页面回收时可能回收cache;另外手动写/proc/sys/vm/drop_caches也会导致cache回收。
上面示例中free的内存只有129M,大部分memory被cache占用。但是系统并没有问题。
8. sar -n DEV 1
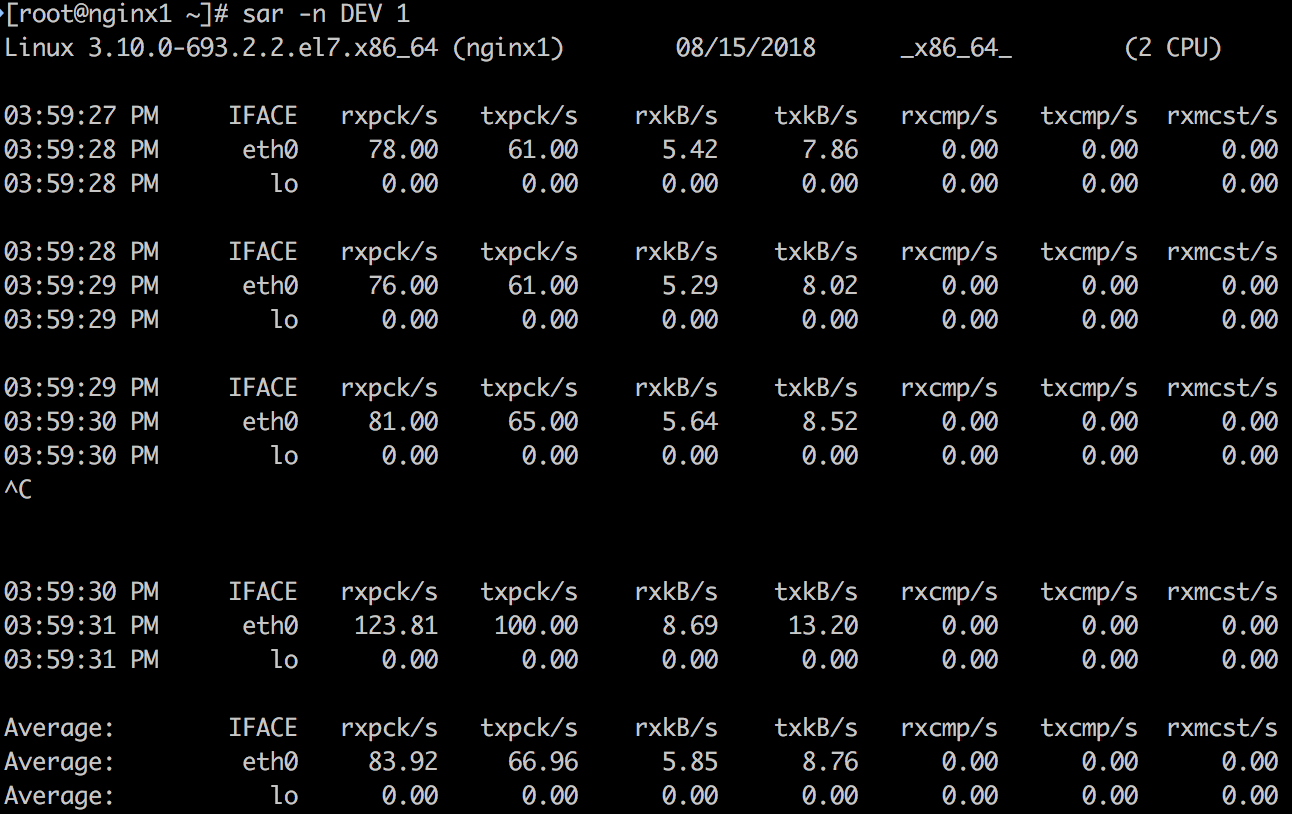
输出指标的含义如下:
- rxpck/s: Total number of packets received per second.
- txpck/s: Total number of packets transmitted per second.
- rxkB/s: Total number of kilobytes received per second.
- txkB/s: Total number of kilobytes transmitted per second.
- rxcmp/s: Number of compressed packets received per second (for cslip etc.).
- txcmp/s: Number of compressed packets transmitted per second.
- rxmcst/s: Number of multicast packets received per second.
- %ifutil: Utilization percentage of the network interface. For half-duplex interfaces, utilization is calculated using the sum of rxkB/s and txkB/s as a percentage of the interface speed.
- For full-duplex, this is the greater of rxkB/S or txkB/s.
这个工具可以查看网络接口的吞吐量,特别是上面蓝色高亮的rxkB/s和txkB/s,这是网络负载,也可以看是否达到了limit。
9. sar -n TCP,ETCP 1
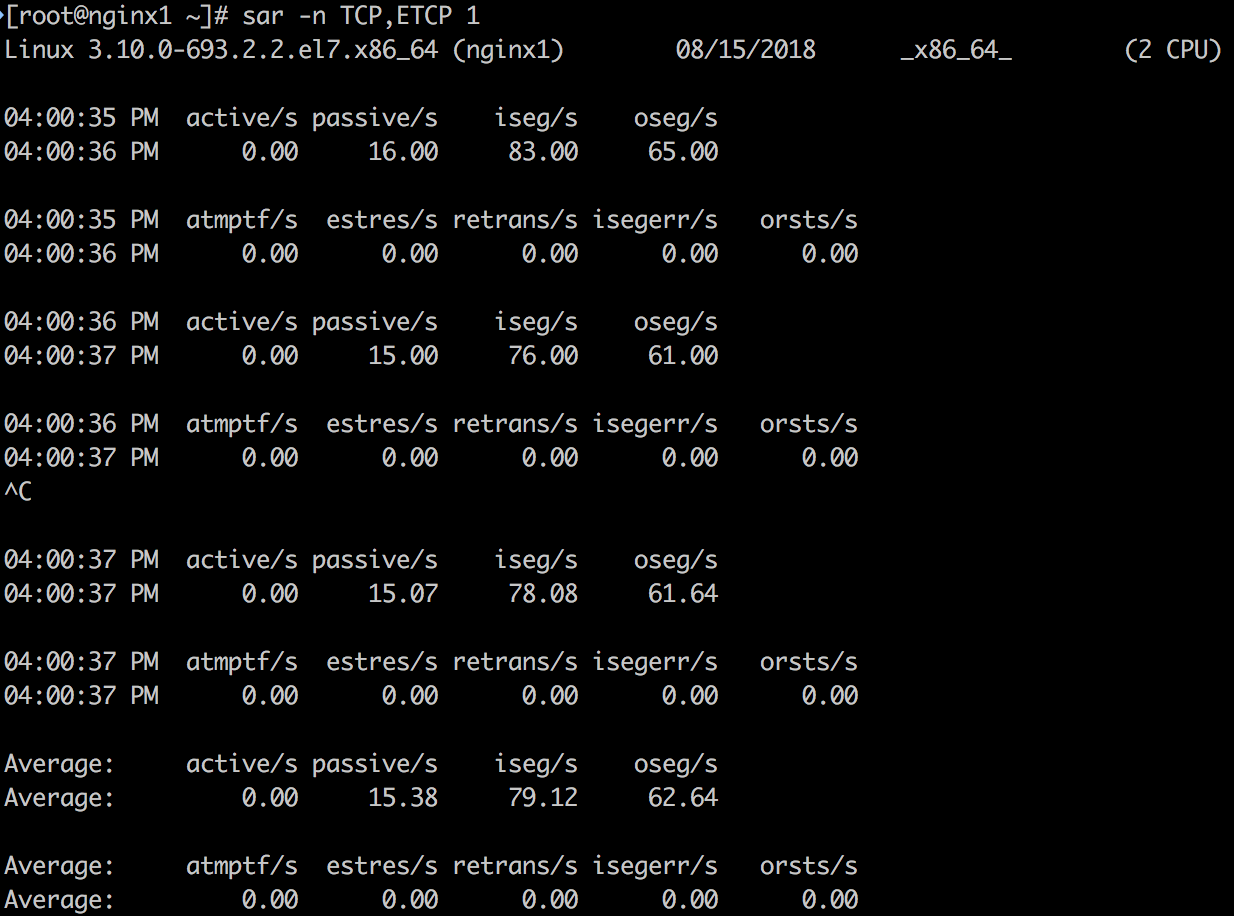
输出指标的含义如下:
- active/s: The number of times TCP connections have made a direct transition to the SYN-SENT state from the CLOSED state per second [tcpActiveOpens].
- passive/s: The number of times TCP connections have made a direct transition to the SYN-RCVD state from the LISTEN state per second [tcpPassiveOpens].
- iseg/s: The total number of segments received per second, including those received in error [tcpInSegs]. This count includes segments received on currently established connections.
- oseg/s: The total number of segments sent per second, including those on current connections but excluding those containing only retransmitted octets [tcpOutSegs].
- atmptf/s: The number of times per second TCP connections have made a direct transition to the CLOSED state from either the SYN-SENT state or the SYN-RCVD state, plus the number of times per second TCP connections have made a direct transition to the LISTEN state from the SYN-RCVD state [tcpAttemptFails].
- estres/s: The number of times per second TCP connections have made a direct transition to the CLOSED state from either the ESTABLISHED state or the CLOSE-WAIT state [tcpEstabResets].
- retrans/s: The total number of segments retransmitted per second - that is, the number of TCP segments transmitted containing one or more previously transmitted octets [tcpRetransSegs].
- isegerr/s: The total number of segments received in error (e.g., bad TCP checksums) per second [tcpInErrs].
- orsts/s: The number of TCP segments sent per second containing the RST flag [tcpOutRsts].
上述蓝色高亮的3个指标:active/s, passive/s和retrans/s是比较有代表性的指标。
- active/s和passive/s分别是本地发起的每秒新建TCP连接数和远程发起的TCP新建连接数。这两个指标可以粗略地判断服务器的负载。可以用active衡量出站发向,用passive衡量入站方向,但也不是完全准确(比如,考虑localhost到localhost的连接)。
- retrans是网络或者服务器发生问题的象征。有可能问题是网络不稳定,比如Internet网络问题,或者服务器过载丢包。
10. top
# top
Tasks: total, running, sleeping, stopped, zombie
%Cpu(s): 6.0 us, 44.1 sy, 0.0 ni, 49.6 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : total, free, used, buff/cache
KiB Swap: total, free, used. avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
root R 100.0 0.0 :27.23 nc
nginx S 0.3 0.0 :59.85 nginx
root S 0.0 0.0 :11.53 systemd
root S 0.0 0.0 :00.60 kthreadd
root S 0.0 0.0 :17.92 ksoftirqd/
root - S 0.0 0.0 :00.00 kworker/:0H
root rt S 0.0 0.0 :03.21 migration/
root S 0.0 0.0 :00.00 rcu_bh
root S 0.0 0.0 :47.62 rcu_sched
root rt S 0.0 0.0 :10.00 watchdog/
top是一个常用的命令,包括了多方面的指标。缺点是没有滚动输出(rolling output),不可复现问题发生时不容易保留信息。对于信息保留,用vmstat或者pidstat等能够提供滚动输出的工具会更好。
示例的问题?
在上面利用工具排查的过程中,我们可以在非常短的时间内快速得到如下结论:
- 2个CPU,nc这个进程消耗了CPU 1 100%的时间,并且时间消耗在system内核态。其他进程基本没有在消耗CPU。
- 内存free比较少,大部分在cache中 (并不是问题)。
- Disk I/O非常低,平均读写请求小于1个。
- 收到报文在个位数KB/s级别,每秒有15个被动建立的TCP连接,没有明显异常。
整个排查过程把系统的问题定位到了进程级别,并且排除一些可能性 (Disk I/O和内存)。接下来就是进一步到进程级别的排查,不属于本文的覆盖范围,有时间再进一步演示。
参考
如何快速分析出现性能问题的Linux服务器的更多相关文章
- Linux服务器性能问题
如何快速分析出现性能问题的Linux服务器 https://www.cnblogs.com/leixiaobai/category/1246164.html Brendan Gregg曾经分享过当遇到 ...
- 检查 Linux 服务器性能
如何用十条命令在一分钟内检查 Linux 服务器性能 如果你的Linux服务器突然负载暴增,报警短信快发爆你的手机,如何在最短时间内找出Linux性能问题所在?来看Netflix性能工程团队的这篇博文 ...
- 如何为企业选择最理想的Linux服务器系统?
[2013年10月12日 51CTO外电头条]什么样的Linux服务器最合适您的企业?简言之,它需要为员工带来工作所需的理想支持效果. 相对于成百上千种Linux桌面系统,Linux服务器系统的数量其 ...
- Linux服务器的16个监控命令
想不想知道你的服务器到底在干什么?那么你要知道本文介绍的这些基本命令.一旦你熟悉掌握了这些命令,就为成为专业的 Linux系统管理员打下了基础. 你可以通过图形化用户界面(GUI)程序来获取这些外壳命 ...
- linux服务器性能分析只需1分钟
背景: 现在的互联网公司,大多数时候应用服务都是部署在linux服务器上,那么当你的服务运行过程中出现了一些响应慢,资源瓶颈等疑似性能问题时,给你60秒,如何快速完成初步检测? 肯定有人会说用工具,公 ...
- 检查Linux服务器性能
如果你的Linux服务器突然负载暴增,告警短信快发爆你的手机,如何在最短时间内找出Linux性能问题所在? 概述通过执行以下命令,可以在1分钟内对系统资源使用情况有个大致的了解. • uptime• ...
- 用十条命令在一分钟内检查Linux服务器性能
转自:http://www.infoq.com/cn/news/2015/12/linux-performance 如果你的Linux服务器突然负载暴增,告警短信快发爆你的手机,如何在最短时间内找出L ...
- Linux服务器的那些性能参数指标
Linux服务器的那些性能参数指标 一个基于Linux操作系统的服务器运行的同时,也会表征出各种各样参数信息.通常来说运维人员.系统管理员会对这些数据会极为敏感,但是这些参数对于开发者来说也十分重要, ...
- 1.linux服务器的性能分析与优化
[教程主题]:1.linux服务器的性能分析与优化 [课程录制]: 创E [主要内容] [1]影响Linux服务器性能的因素 操作系统级 CPU 目前大部分CPU在同一时间只能运行一个线程,超线程的处 ...
随机推荐
- Chrome截长屏
本文地址:https://www.cnblogs.com/veinyin/p/9257833.html Chrome截取长屏一直是一个痛点,之前尝试过第三方截图工具,但是不是收费就是不怎么好用,今 ...
- 基本控件文档-UIKit结构图
CHENYILONG Blog 基本控件文档-UIKit结构图 Fullscreen UIKit结构图 技术博客http://www.cnblogs.com/ChenYilong/ 新浪微博htt ...
- python Linux flask uwsgi nginx 在centos7.3部署
0.直接上uwsgi和nginx安装命令 linux 安装uwsgi yum groupinstall "Development tools" yum install zlib-d ...
- Velocity VelocityEngine 支持多种loader 乱码问题
最近升级团队的代码生成工具,此工具是velocity实现的. 之前习惯使用UTF-8编码,现在团队使用GBK. 所以遇到一种场景,模板文件使用UTF-8(习惯了所有任性),输出文件使用GBK(项目需要 ...
- Ubuntu使用apt-get upgrade升级时出错
今天在按照常规的sudo apt-get update更新软件列表后,再使用sudo apt-get upgrade升级软件时,出现了以下的错误: 正在设置 linux-image-extra-4.4 ...
- redis安装(linux)
一.redis安装步骤 1.yum install gcc 如果你机器已经安装了编译环境请忽略,否则在使用make编译源码时会报错. 报错信息:make: *** [adlist.o] 2.使用w ...
- Linux下C程序的反汇编【转】
转自:http://blog.csdn.net/u011192270/article/details/50224267 前言:本文主要介绍几种反汇编的方法. gcc gcc的完整编译过程大致为:预处理 ...
- 2015 Dhaka
2015 Dhaka A - Automatic Cheater Detection solution 模拟计数. B - Counting Weekend Days solution 模拟计数. C ...
- Linux 获取网关地址
route命令的用法:操作或者显示IP路由表route:DESCRIPTION Route manipulates the kernel's IP routing tables. Its primar ...
- Nginx - Header详解
1. 前言 通过 HttpHeadersModule 模块可以设置HTTP头,但是不能重写已经存在的头,比如可能相对server头进行重写,可以添加其他的头,例如:Cache-Control,设置生存 ...