【scrapy】使用方法概要(二)(转)
【请初学者作为参考,不建议高手看这个浪费时间】
上一篇文章里介绍了scrapy的主要优点及linux下的安装方式,此篇文章将简要介绍scrapy的爬取过程,本文大部分内容源于scrapy文档,翻译并加上了笔者自己的理解。
忘记scrapy,一般所说的爬虫工作分为两个部分,downoader 和 parser:
downloader输入是url列表,输出抓取到的rawdata,可能时候是html源代码,也可能是json,xml格式的数据。
parser输入是第一部分输出的rawdata,根据已知的规则提取所需的info

图1. 简单爬虫
图1所示的是最简单的爬虫,不考虑解析url,并把rawdata中的url提取做进一步提取,并假设预先知道抓取的所有的url,而且抓到的网页的parser(提取规则)是相同的。
---------------------------------------------------------------------------------------------------------------------------
重新回到主角scrapy
下面是摘取的scrapy文档中的抓取流程图
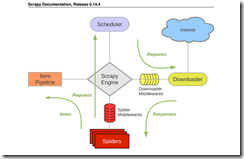
官方文档中对图中的每个components如下:
scrapy engine 【scrapy引擎】
引擎控制系统中的数据流,当某些情况发生时,触发事件。
scheduler 【调度器】
调度器接受引擎发送过来的request对象【可简单理解成抓取任务】并把他们入队列,等待的引擎在适当时刻提取出这些request并把它们通过下载中间件交给downloader去做下载。
Downloader【下载器】
Downloader根据request对象中的地址获取网页内容告知引擎下载结果,并把网页内容传送给spider组件
Spiders【解析器】
Spiders是开发人员主要接触的组件,开发人员通过在这里coding,从raw网页中提取出所需的数据并存入item【数据原单元,一个item代表一项数据对象,使用者自己定义item包含的数据项】或者提取出新的抓取request对象【新的抓取任务】 一个爬虫负责一个指定domain列表下的网页
ItemPipeline【item管道】
item管道负责处理爬虫吐出的item,包括数据清理,验证,保存
DownloaderMiddleware【下载中间件】
【工作原理很像一般mvc框架中的拦截器或者behavior,开发者可以在某些步骤之间插入自己的处理逻辑】有了中间件,开发这可以在engine向downloader传request任务之间,或者,在downloader下载完毕,向engine吐回response对象的时候对request,或者resonse插入custom code
Spider milldleware【解析器中间件】
spider middleware是引擎和spider之间的hook程序【拦截器】,用来处理spider的输入【response】和输出【item and requests】
【这两类中间件为开发者提供了非常便利的扩展scrapy的方式】

scrapy的数据流有engine【类似于mvc框架中的controller】指挥,如下:
1. engine打开一个domain,定位spider代码的位置,获取最初的urls【start_urls,暂叫‘种子’】,拿到Request对象
2. 拿到这些最初的Request对象,并把他们交给scheduler,enqueue到scheduler负责的任务队列中
3. engine向scheduler索取下一个要下载的request【url】
4. scheduler收到请求后,从任务队列中pop出一个request,并feed给engine,engine收到后,将抓取任务发送给downloader,这些request将通过downloader middlewares【scrapy默认会开启很多内置的downloader】
5. 当downloader下载完毕后,downloader生成一个Response对象并通过downloader middlerware传递给engine
6. engine拿到reponse后,通过spidermiddleware将response交给spider做解析工作
7. spider解析response,将解析出来的item和新的Request【新的抓取任务】交给engine
8. engine将拿到的item交给pipeline处理,将新的Request按照第2步骤发送给scheduler
9. 程序会在2-8之间循环直至scheduler中的任务队列为空
【scrapy】使用方法概要(二)(转)的更多相关文章
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy基本使用(二)
scrapy基本使用(二) 参考链接: http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html#id5 scrapy基本使用(一 ...
- .NET 扩展方法 (二)
上一篇随笔 .NET 扩展方法 (一) 已经对 扩展方法有了大致的介绍,这篇算是一个补充,让我们来看一下扩展方法的几个细节: 一.扩展方法具有继承性 当使用扩展方法扩展一个类型的时候,其也扩展了派生类 ...
- 编写高质量JS代码的68个有效方法(二)
[20141011]编写高质量JS代码的68个有效方法(二) *:first-child { margin-top: 0 !important; } body>*:last-child { ma ...
- Python3 Scrapy 安装方法
Python3 Scrapy 安装方法 (一脸辛酸泪) 写在前面 最近在学习爬虫,在熟悉了Python语言和BeautifulSoup4后打算下个爬虫框架试试. 没想到啊,这坑太深了... 看了看相关 ...
- Eclipse中如何开启断言(Assert),方法有二
Eclipse中如何开启断言(Assert),方法有二:1.Run -> Run Configurations -> Arguments页签 -> VM arguments文本框中加 ...
- WPF文字描边的解决方法(二)——支持文字竖排和字符间距调整
原文:WPF文字描边的解决方法(二)--支持文字竖排和字符间距调整 自前天格式化文本效果出来后,今天又添加文本竖排和调整字符间距的功能.另外,由于上次仓促,没来得及做有些功能的设计时支持,这次也调整好 ...
- selenium定位方法(二)
selenium定位方法(二) 1.xpath定位:xpath是在XML中查找节点所在的路径的表达式 1)绝对路径的Xpath表达式 例:/html/body/div/div[1]/ul//li[3 ...
- Python 数据类型常用的内置方法(二)
目录 Python 数据类型常用的内置方法(二) 1.字符串类型常用内置方法 1.upper.lower.isupper.islower 2.startswith.endswith 3.format ...
- 《手把手教你》系列基础篇(九十七)-java+ selenium自动化测试-框架设计篇-Selenium方法的二次封装和页面基类(详解教程)
1.简介 上一篇宏哥介绍了如何设计支持不同浏览器测试,宏哥的方法就是通过来切换配置文件设置的浏览器名称的值,来确定启动什么浏览器进行脚本测试.宏哥将这个叫做浏览器引擎类.这个类负责获取浏览器类型和启动 ...
随机推荐
- local class incompatible: stream classdesc serialVersionUID = -2897844985684768944, local class serialVersionUID = 7350468743759137184
local class incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 2427 ...
- python dict交换key value值
方法一: 使用dict.items()方式 dict_ori = {'A':1, 'B':2, 'C':3} dict_new = {value:key for key,value in dict_o ...
- 规范命名CSS
作者:词晖链接:https://www.zhihu.com/question/19586885/answer/48933504来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出 ...
- Codeforces 981D Bookshelves(按位贪心+二维DP)
题目链接:http://codeforces.com/contest/981/problem/D 题目大意:给你n本书以及每本书的价值,现在让你把n本书放到k个书架上(只有连续的几本书可以放到一个书架 ...
- JAVA复习笔记之GC部分
前言:垃圾回收机制,大家都知道JAVA的垃圾回收都是JVM自动回收的,不需要程序员去管理.但是我们还是得知道原理才能在适当时机进行JVM调优 原理:当我们new 一个对象时JVM堆区就会分配一块 ...
- Linux学习笔记:crontab定时任务
通过crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell script脚本.时间间隔的单位可以是分钟.小时.日.月.周及以上的任意组合.这个命令非常适合周期性的日志分析或数据 ...
- 10月15日 | 云栖大会“淘宝移动技术实践&开放论坛”来了!
参会报名链接:http://baichuan.taobao.com/marketing/yunqi#?baichuan_channel=cnblogs 顺应移动互联网消费升级趋势, 淘宝作为移动领域的 ...
- ZCTF2015 pwn试题分析
ZCTF的pwn赛题分析, PWN100 这道题与SCTF的pwn100玩法是一样的,区别在于这个要过前面的几个限制条件.不能触发exit(0).否则就不能实现溢出了. 依然是触发canary来lea ...
- 毕设demo写好
2015年1月20日 14:41:47 阶段性暂停!! 把运行结果截图给了老师,老师说先整理下文档,然后下学期来了再部署到服务器上. 那么,下学期来了,估计也要把Epm和CR1000什么的搞好了. 先 ...
- 使用mybatis-generator-core自动生成代码
SSM框架可以使用mybatis-generator-core-1.3.2.jar来自动生成代码,以下是配置和使用的代码. generatorConfig.xml <?xml version=& ...