hashlib模块&日志模块
内容概要
- hashlib模块
- logging模块
- 第三方模块下载
内容详细
hashlib模块
hashlib 是一个提供了一些流行的hash(摘要)算法的Python标准库.其中所包括的算法有 md5, sha1, sha224, sha256, sha384
加密:将明文数据通过一系列算法变成密文数据(目的就是为了数据的安全)
加密算法:md系列 sha系列 base系列 hmac系列
# 涉及到用户密码存储 其实都是密文 只要用户自己知道明文是什么
"""
1.内部程序员无法得知明文数据
2.数据泄露也无法得知明文数据
"""
1、基本使用
import hashlib
# 定义一个md5对象
md5 = hashlib.md5()
# 用update方法把数据以二进制的格式传入对象 注意:传入的数据一定是二进制类型
md5.update('123456'.encode('utf8'))
# 用hexdigest方法把密文传出
password = md5.hexdigest()
print(password) # e10adc3949ba59abbe56e057f20f883e
"""
1.加密之后的密文数据是没有办法反解密成明文数据的
市面上所谓的破解 其实就是提前算出一系列明文对应的密文
之后比对密文再获取明文
"""
2、明文数据只要是相同的,那么无论如何传递加密结果一定是一样的
md5 = hashlib.md5()
md5.update('123456789'.encode('utf8'))
print(md5.hexdigest())
# 25f9e794323b453885f5181f1b624d0b
md5 = hashlib.md5()
md5.update('123'.encode('utf8'))
md5.update('456'.encode('utf8'))
md5.update('789'.encode('utf8'))
print(md5.hexdigest())
# 25f9e794323b453885f5181f1b624d0b
3、密文数据越长表示内部对应的算法越复杂 越难被正向破解
# 使用sha256算法
md5 = hashlib.sha256()
md5.update('123456'.encode('utf8'))
password = md5.hexdigest()
print(password)
# 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
密文越长表示算法越复杂 对应的破解算法的难度越高
但是越复杂的算法所需要消耗的资源也就越多 密文越长基于网络发送需要占据的数据也就越大
具体使用什么算法取决于项目的要求 一般情况下md5足够了
4、加盐处理
"""
在对明文数据做加密处理过程前添加一些干扰项,增加破解难度
"""
# 定义一个md5对象
md5 = hashlib.md5()
# 定义一个‘盐’字符串并添加
salt = '12345,egon上山打老虎'
md5.update(salt.encode('utf8')) # 记得要把字符转为二进制才能传入
# 用update方法把数据以二进制的格式传入对象 注意:传入的数据一定是二进制类型
md5.update('123456'.encode('utf8'))
# 用hexdigest方法把密文传出
password = md5.hexdigest()
print(password)
# d775d16db55eb9619f92b0ddd9ffe121
5、动态加盐
加盐的操作变为动态,也就是每次额外添加进去的字符串都不一样,增加破解密文的难度
在对明文数据做加密处理过程前添加一些变化的干扰项
方式:当前时间 用户名的部分 uuid(随机字符串(永远不会重复))
import time
md5 = hashlib.md5()
# 把添加时间当作干扰向项
salt = time.time()
salt = str(salt)
md5.update(salt.encode('utf8'))
md5.update('123456'.encode('utf8'))
password = md5.hexdigest()
print(password)
# 46152da37b6d8096cdb144c3ccb6468a
有些所谓的破解密码网站,其实就是把尽可能多的可能输入的明文全部加密一遍,把密文保存起来,用户输入他的密文后,从数据库中找出相同的密文配对,从而判断明文是什么...
"""
在IT互联网领域 没有绝对的安全可言 只有更安全
原因在于互联网的本质 就是通过网线(网卡)连接计算机
"""
6、校验文件一致性
文件不是很大的情况下 可以将所有文件内部全部加密处理
但是如果文件特别大 全部加密处理相当的耗时好资源 如何解决???
针对大文件可以使用切片读取的方式
md5 = hashlib.md5()
with open(r'a.txt', 'rb') as f:
for line in f:
md5.update(line)
real_data = md5.hexdigest()
print(real_data) # 29d8ea41c610ee5d1e76dd0a42c7e60a
with open(r'a.txt', 'rb') as f:
for line in f:
md5.update(line)
error_data = md5.hexdigest()
print(error_data) # 738a56b49f24884ba758d1e4ab6ceb74
import os
# 读取文件总大小
res = os.path.getsize(r'a.txt')
# 指定分片读取策略(读几段 每段几个字节) 10 f.seek()
read_method = [0, res // 4, res // 2, res]
# 用f.read(10)读取十个字符
# 读取到最后的位置时需要把光标往前移动
logging模块
1、日志五个等级
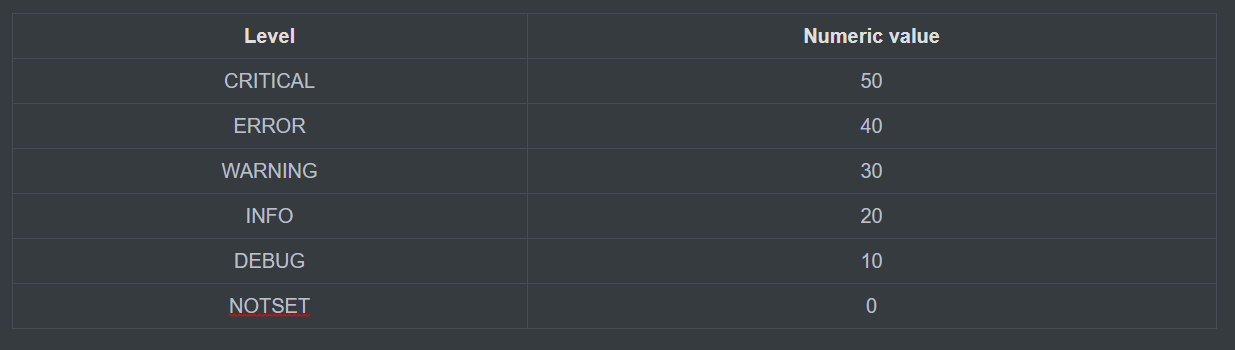
注意:默认记录的级别在30以上
常用处理
logging.debug(‘debug级别’)
logging.info(‘info级别’)
logging.warning(‘warning级别’)
logging.error(‘error级别’)
logging.critical(‘critical级别’)
2、四大金刚
logger对象: 负责产生日志
filter对象:负责过滤日志(直接忽略)
handler对象:负责日志产生的位置
formater对象:负责日志产生的格式
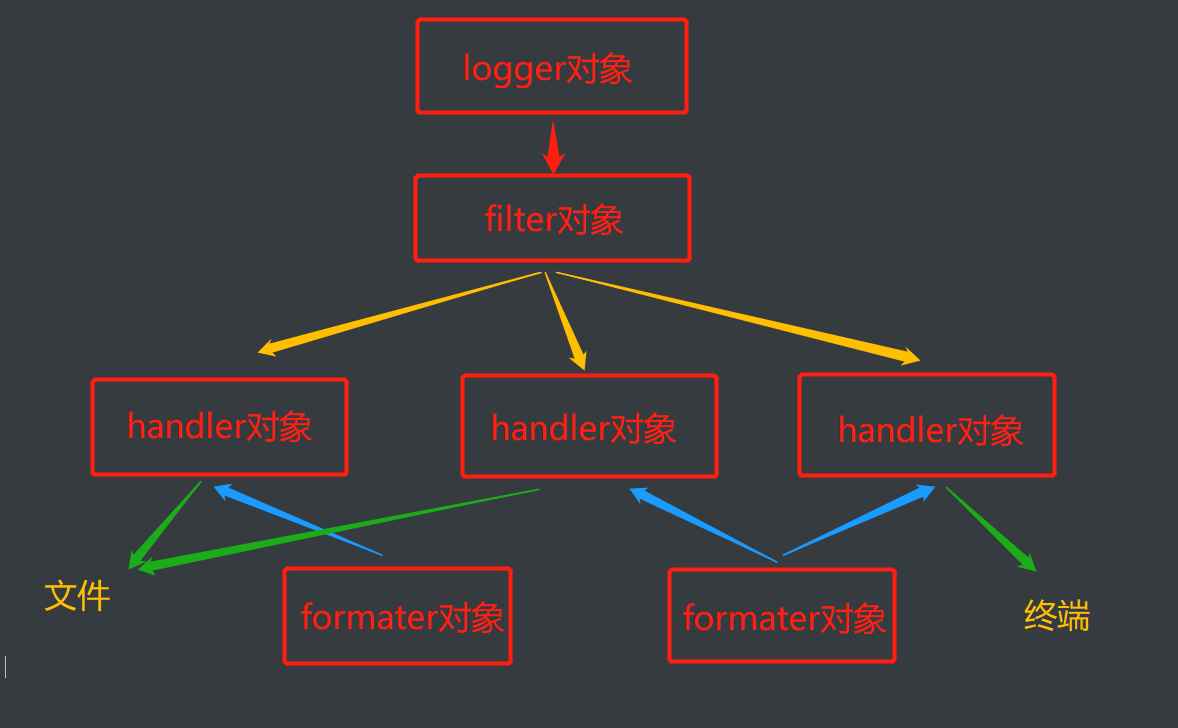
3、简单使用
import logging
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('日志模块很好学 不要自己吓自己')
"""
1.如何控制日志输入的位置
想在文件和终端中同时打印
2.不同位置如何做到不同的日志格式
文件详细一些 终端简单一些
"""
4、日志模块详细介绍
import logging
# 1.logger对象:负责产生日志
logger = logging.getLogger('转账记录')
# 2.filter对象:负责过滤日志(直接忽略)
# 3.handler对象:负责日志产生的位置
hd1 = logging.FileHandler('a1.log',encoding='utf8') # 产生到文件的
hd2 = logging.FileHandler('a2.log',encoding='utf8') # 产生到文件的
hd3 = logging.StreamHandler() # 产生在终端的
# 4.formatter对象:负责日志的格式
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s %(message)s',
datefmt='%Y-%m-%d',
)
# 5.绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.绑定formatter对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(30)
# 8.记录日志
logger.debug('写了半天 好累啊 好热啊')
5、配置字典
# 核心就在于CV
import logging
import logging.config
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
logfile_path = 'a3.log'
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置 空字符串作为键 能够兼容所有的日志
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
# 使用配置字典
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger('xxx')
logger1.debug('加油啊铁子们')
配置参数
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
第三方模块
# 并不是python自带的 需要基于网络下载!!!
'''pip所在的路径添加环境变量'''
下载第三方模块的方式
方式1:命令行借助于pip工具
pip3 install 模块名 # 不知道版本默认是最新版
pip3 install 模块名==版本号 # 指定版本下载
pip3 install 模块名 -i 仓库地址 # 临时切换
'''命令行形式永久修改需要修改python解释器源文件'''
方式2:pycharm快捷方式
settings
project
project interprter
双击或者加号
点击右下方manage管理添加源地址即可
# 下载完第三方模块之后 还是使用import或from import句式导入使用
"""
pip命令默认下载的渠道是国外的python官网(有时候会非常的慢)
我们可以切换下载的源(仓库)
(1)阿里云 http://mirrors.aliyun.com/pypi/simple/
(2)豆瓣 http://pypi.douban.com/simple/
(3)清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
(4)中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
(5)华中科技大学http://pypi.hustunique.com/
pip3 install openpyxl -i http://mirrors.aliyun.com/pypi/simple/
"""
"""
下载第三方模块可能报错的情况及解决措施
1.报错的提示信息中含有关键字timeout
原因:网络不稳定
措施:再次尝试 或者切换更加稳定的网络
2.找不到pip命令
环境变量问题
3.没有任何的关键字 不同的模块报不同的错
原因:模块需要特定的计算机环境
措施:拷贝报错信息 打开浏览器 百度搜索即可
pip下载某个模块报错错误信息
"""
hashlib模块&日志模块的更多相关文章
- Python--day29--logging模块(日志模块)
重要程度六颗星,比如一个小窗口的广告如果因为你没有日志的问题导致点击量没有记录下来,几十分钟那就会损失几十万了,这责任谁负得起. 希望离开一个公司是因为有了更好的去处而不是因为各种各样的原因被开掉,那 ...
- hashlib加密模块、logging日志模块
hashlib模块 加密:将明文数据通过一系列算法变成密文数据 目的: 就是为了数据的安全 基本使用 基本使用 import hashlib # 1.先确定算法类型(md5普遍使用) md5 = ha ...
- logging日志模块,hashlib hash算法相关的库,
logging: 功能完善的日志模块 import logging #日志的级别 logging.debug("这是个调试信息")#级别10 #常规信息 logging.info( ...
- 约束、自定义异常、hashlib模块、logging日志模块
一.约束(重要***) 1.首先我们来说一下java和c#中的一些知识,学过java的人应该知道,java中除了有类和对象之外,还有接口类型,java规定,接口中不允许在方法内部写代码,只能约束继承它 ...
- 日志模块详细介绍 hashlib模块 动态加盐
目录 一:hashlib模块 二:logging 一:hashlib模块 加密: 将明文数据通过一系列算法变成密文数据(目的就是为了数据的安全) 能够做文件一系列校验 python的hashlib提供 ...
- 加密模块hashlib+日志模块logging
目录 1.hashlib 加密模块 1.hashlib模块基本使用 1.2 详细操作 ①md5加密模式 ②sha256复杂加密模式 ③加盐操作(普通加盐) ④加盐操作(动态加盐) 2.logging ...
- Python(文件、文件夹压缩处理模块,shelve持久化模块,xml处理模块、ConfigParser文档配置模块、hashlib加密模块,subprocess系统交互模块 log模块)
OS模块 提供对操作系统进行调用的接口 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目 ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- hashlib,configparser,logging模块
一.常用模块二 hashlib模块 hashlib提供了常见的摘要算法,如md5和sha1等等. 那么什么是摘要算法呢?摘要算法又称为哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度 ...
随机推荐
- 解决spring boot 无法访问静态文件夹的附件或图片
1.需要在配置文件重新执行静态文件夹位置即可 # 指定静态文件位置 resources: static-locations: classpath:/static/,classpath:/static/ ...
- 深入谈谈 Java IOC 和 DI
1.前言 不得不说, IOC和DI 在写代码时经常用到.还有个就是在面试时 ,面试官老喜欢问 IOC 和DI是什么的问题,都快被问吐了, 可是,仍然会让许多人说的支支吾吾. 为什么? 第一,因为这个知 ...
- react中自定义antd主题与支持less(第二部)
自定义主题 首先自定义主题需要修改antd,antd本身也是less写的之后编译成css的,所以当我们需要使用less. 1.yarn add react-app-rewire-less --dev ...
- Zabbix漏洞利用 CVE-2016-10134
最近也是遇见了Zabbix,所以这里以CVE-2016-10134为例复现一下该漏洞 什么是Zabbix? zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案. ...
- Solon Web 开发,一、开始
Solon Web 开发 一.开始 二.开发知识准备 三.打包与运行 四.请求上下文 五.数据访问.事务与缓存应用 六.过滤器.处理.拦截器 七.视图模板与Mvc注解 八.校验.及定制与扩展 九.跨域 ...
- 1013day-人口普查系统
1.shuchu.jsp <%@ page language="java" contentType="text/html; charset=UTF-8" ...
- 【刷题-LeetCode】204. Count Primes
Count Primes Count the number of prime numbers less than a non-negative number, *n*. Example: Input: ...
- gin中绑定查询字符串或表单数据
package main import ( "github.com/gin-gonic/gin" "log" "time" ) type P ...
- Go 指针,标识符命名规范及关键字
#### Go 指针,标识符命名规范,关键字,运算符回顾了一下之前写的文章,以及考虑到后期的内容较多, 从这篇开始逐渐增加文章内容; 这篇我们主要学习一Go 中的指针,标识符关键字以及运算符##### ...
- 负载均衡的比例(权重,ip_hash,轮询)
目录 一:负载均衡的比例 1.轮询 2.权重 3.ip_hash 二:测试轮询 1.测试 2.重启 3.网址测试 三:测试ip_hash 一:负载均衡的比例 1.轮询 # 默认情况下,Nginx负载均 ...