Kafka万亿级消息实战
一、Kafka应用
本文主要总结当Kafka集群流量达到 万亿级记录/天或者十万亿级记录/天 甚至更高后,我们需要具备哪些能力才能保障集群高可用、高可靠、高性能、高吞吐、安全的运行。
这里总结内容主要针对Kafka2.1.1版本,包括集群版本升级、数据迁移、流量限制、监控告警、负载均衡、集群扩/缩容、资源隔离、集群容灾、集群安全、性能优化、平台化、开源版本缺陷、社区动态等方面。本文主要是介绍核心脉络,不做过多细节讲解。下面我们先来看看Kafka作为数据中枢的一些核心应用场景。
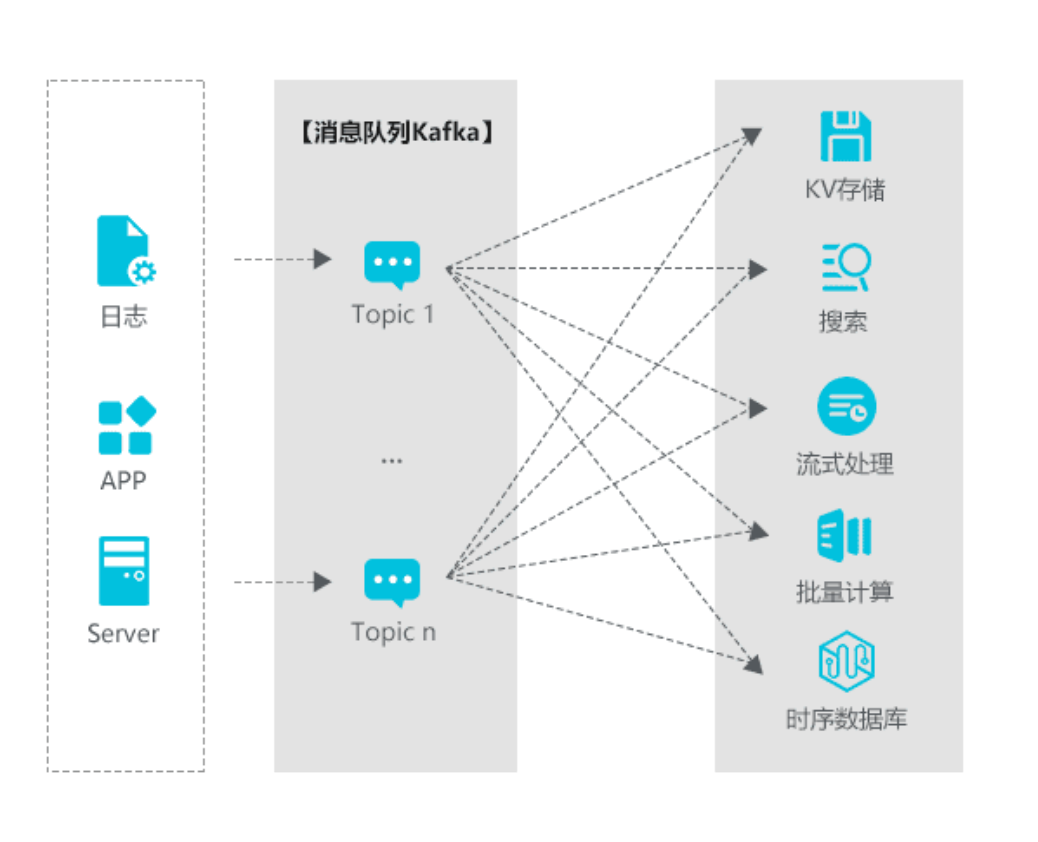
下图展示了一些主流的数据处理流程,Kafka起到一个数据中枢的作用。
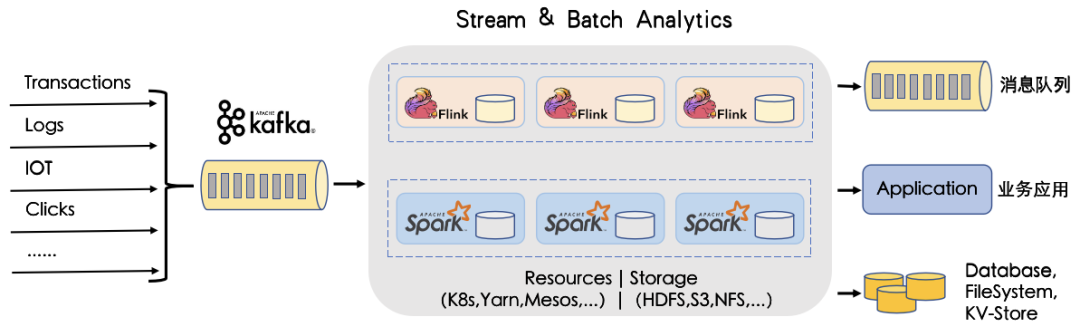
接下来看看我们Kafka平台整体架构;
1.1 版本升级
1.1.1 开源版本如何进行版本滚动升级与回退
1.1.1.2 源码改造如何升级与回退
由于在升级过程中,必然出现新旧代码逻辑交替的情况。集群内部部分节点是开源版本,另外一部分节点是改造后的版本。所以,需要考虑在升级过程中,新旧代码混合的情况,如何兼容以及出现故障时如何回退。
1.2 数据迁移
由于Kafka集群的架构特点,这必然导致集群内流量负载不均衡的情况,所以我们需要做一些数据迁移来实现集群不同节点间的流量均衡。Kafka开源版本为数据迁移提供了一个脚本工具“bin/kafka-reassign-partitions.sh”,如果自己没有实现自动负载均衡,可以使用此脚本。
开源版本提供的这个脚本生成迁移计划完全是人工干预的,当集群规模非常大时,迁移效率变得非常低下,一般以天为单位进行计算。当然,我们可以实现一套自动化的均衡程序,当负载均衡实现自动化以后,基本使用调用内部提供的API,由程序去帮我们生成迁移计划及执行迁移任务。需要注意的是,迁移计划有指定数据目录和不指定数据目录两种,指定数据目录的需要配置ACL安全认证。
1.2.1 broker间数据迁移
不指定数据目录
//未指定迁移目录的迁移计划
{
"version":1,
"partitions":[
{"topic":"yyj4","partition":0,"replicas":[1000003,1000004]},
{"topic":"yyj4","partition":1,"replicas":[1000003,1000004]},
{"topic":"yyj4","partition":2,"replicas":[1000003,1000004]}
]
}
指定数据目录
//指定迁移目录的迁移计划
{
"version":1,
"partitions":[
{"topic":"yyj1","partition":0,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]},
{"topic":"yyj1","partition":1,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]},
{"topic":"yyj1","partition":2,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]}
]
}
1.2.2 broker内部磁盘间数据迁移
生产环境的服务器一般都是挂载多块硬盘,比如4块/12块等;那么可能出现在Kafka集群内部,各broker间流量比较均衡,但是在broker内部,各磁盘间流量不均衡,导致部分磁盘过载,从而影响集群性能和稳定,也没有较好的利用硬件资源。在这种情况下,我们就需要对broker内部多块磁盘的流量做负载均衡,让流量更均匀的分布到各磁盘上。
1.2.3 并发数据迁移
当前Kafka开源版本(2.1.1版本)提供的副本迁移工具“bin/kafka-reassign-partitions.sh”在同一个集群内只能实现迁移任务的串行。对于集群内已经实现多个资源组物理隔离的情况,由于各资源组不会相互影响,但是却不能友好的进行并行的提交迁移任务,迁移效率有点低下,这种不足直到2.6.0版本才得以解决。如果需要实现并发数据迁移,可以选择升级Kafka版本或者修改Kafka源码。
1.2.4 终止数据迁移
当前Kafka开源版本(2.1.1版本)提供的副本迁移工具“bin/kafka-reassign-partitions.sh”在启动迁移任务后,无法终止迁移。当迁移任务对集群的稳定性或者性能有影响时,将变得束手无策,只能等待迁移任务执行完毕(成功或者失败),这种不足直到2.6.0版本才得以解决。如果需要实现终止数据迁移,可以选择升级Kafka版本或者修改Kafka源码。
1.3 流量限制
1.3.1 生产消费流量限制
经常会出现一些突发的,不可预测的异常生产或者消费流量会对集群的IO等资源产生巨大压力,最终影响整个集群的稳定与性能。那么我们可以对用户的生产、消费、副本间数据同步进行流量限制,这个限流机制并不是为了限制用户,而是避免突发的流量影响集群的稳定和性能,给用户可以更好的服务。
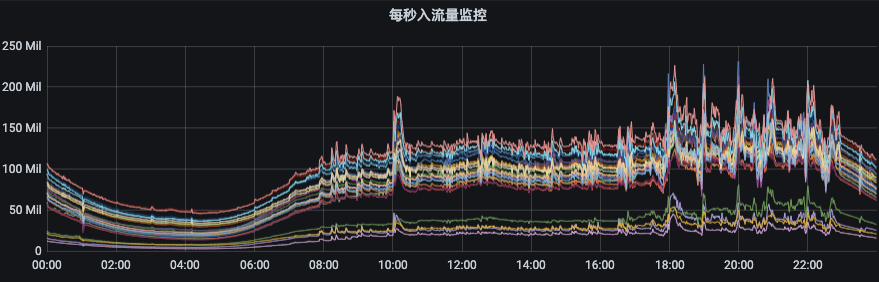
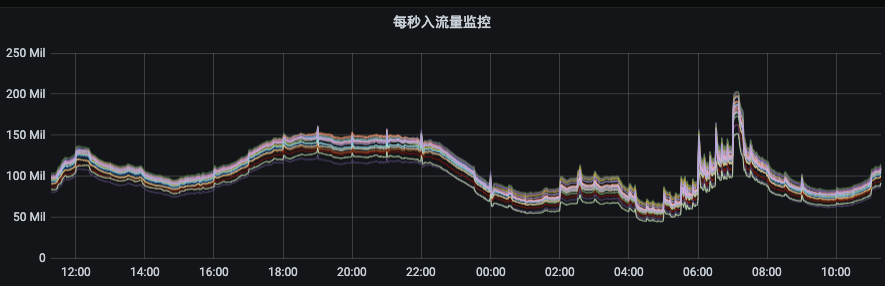
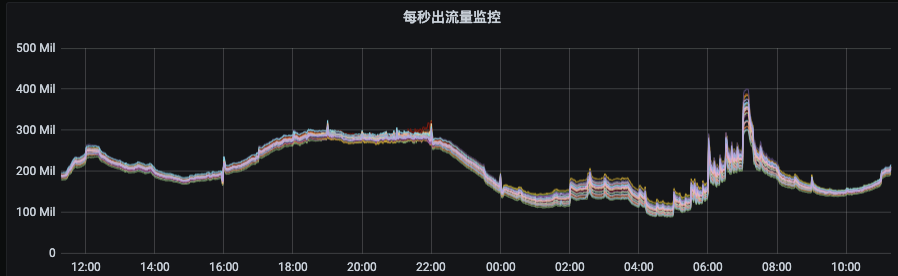
如下图所示,节点入流量由140MB/s左右突增到250MB/s,而出流量则从400MB/s左右突增至800MB/s。如果没有限流机制,那么集群的多个节点将有被这些异常流量打挂的风险,甚至造成集群雪崩。
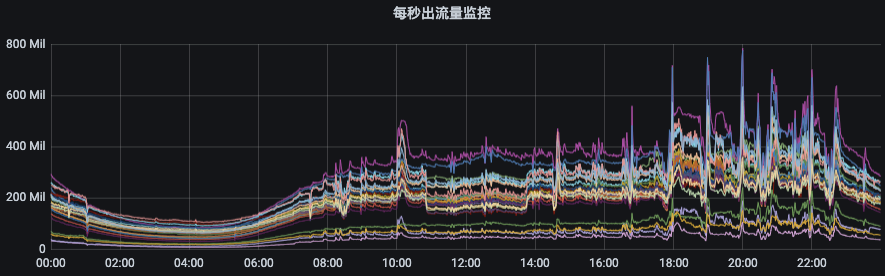
图片生产/消费流量限制官网地址:点击链接
对于生产者和消费者的流量限制,官网提供了以下几种维度组合进行限制(当然,下面限流机制存在一定缺陷,后面在“Kafka开源版本功能缺陷”我们将提到):
/config/users/<user>/clients/<client-id> //根据用户和客户端ID组合限流
/config/users/<user>/clients/<default>
/config/users/<user>//根据用户限流 这种限流方式是我们最常用的方式
/config/users/<default>/clients/<client-id>
/config/users/<default>/clients/<default>
/config/users/<default>
/config/clients/<client-id>
/config/clients/<default>
在启动Kafka的broker服务时需要开启JMX参数配置,方便通过其他应用程序采集Kafka的各项JMX指标进行服务监控。当用户需要调整限流阈值时,根据单个broker所能承受的流量进行智能评估,无需人工干预判断是否可以调整;对于用户流量限制,主要需要参考的指标包括以下两个:
(1)消费流量指标:ObjectName:kafka.server:type=Fetch,user=acl认证用户名称 属性:byte-rate(用户在当前broker的出流量)、throttle-time(用户在当前broker的出流量被限制时间)
(2)生产流量指标:ObjectName:kafka.server:type=Produce,user=acl认证用户名称 属性:byte-rate(用户在当前broker的入流量)、throttle-time(用户在当前broker的入流量被限制时间)
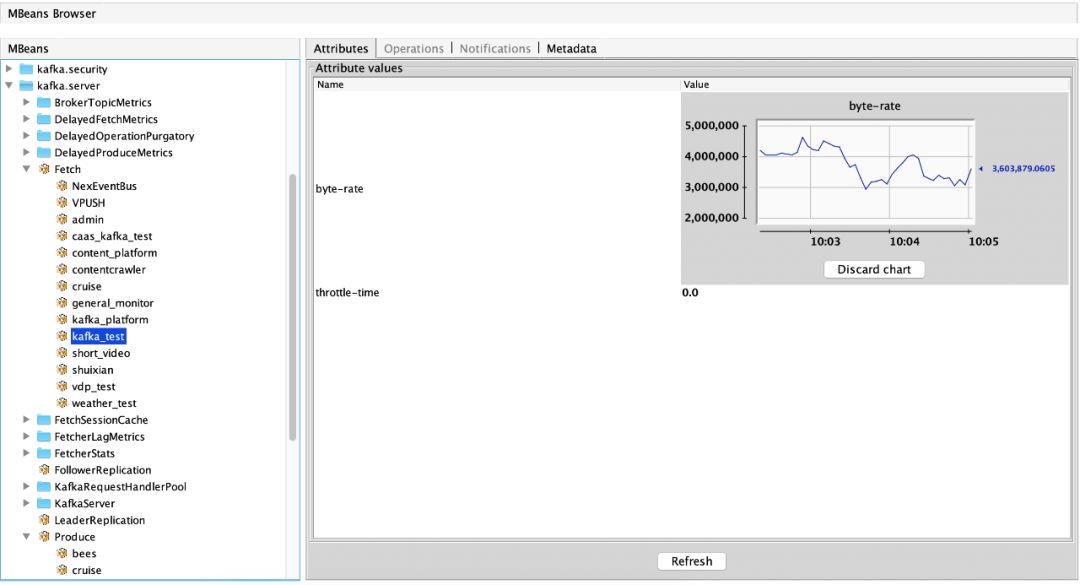
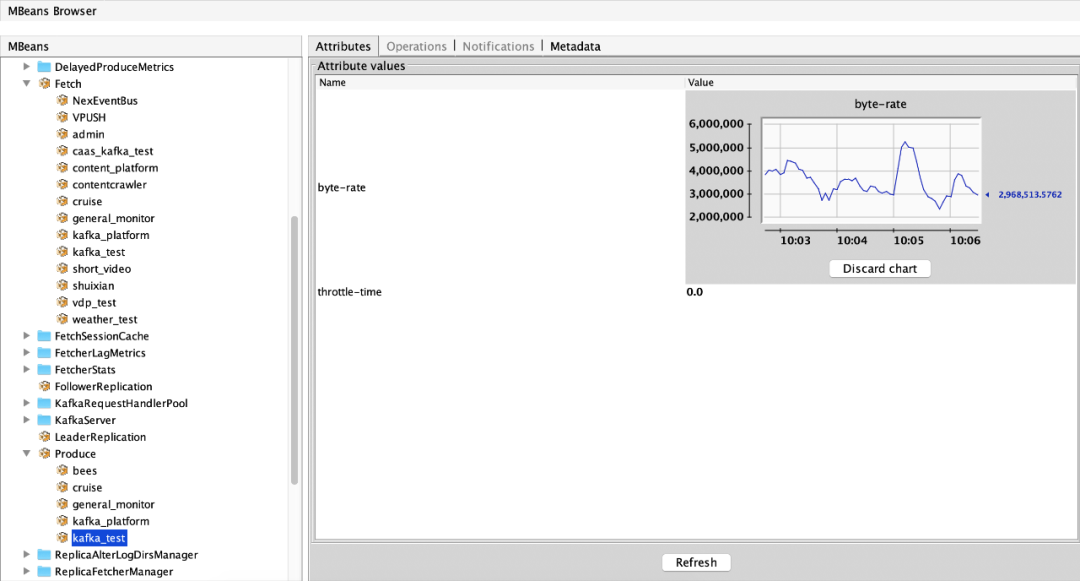
1.3.2 follower同步leader/数据迁移流量限制
副本迁移/数据同步流量限制官网地址:链接
涉及参数如下:
//副本同步限流配置共涉及以下4个参数
leader.replication.throttled.rate
follower.replication.throttled.rate
leader.replication.throttled.replicas
follower.replication.throttled.replicas
辅助指标如下:
(1)副本同步出流量指标:ObjectName:kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesOutPerSec
(2)副本同步入流量指标:ObjectName:kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesInPerSec
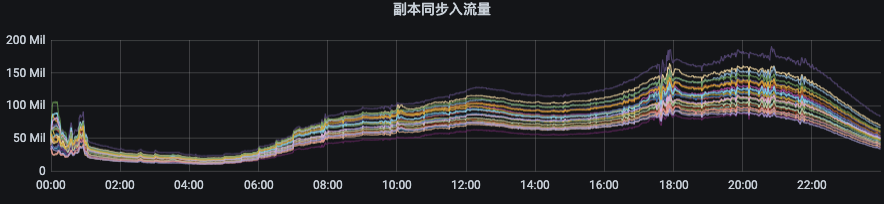
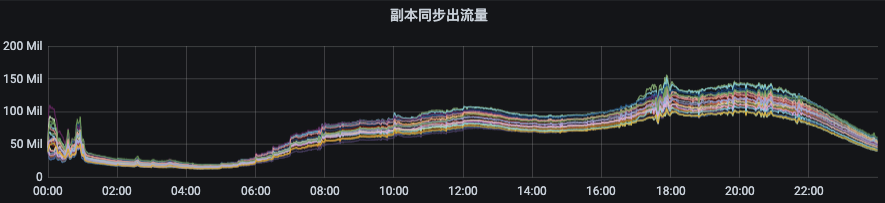
1.4 监控告警
关于Kafka的监控有一些开源的工具可用使用,比如下面这几种:
KafkaOffsetMonitor;
我们已经把Kafka Manager作为我们查看一些基本指标的工具嵌入平台,然而这些开源工具不能很好的融入到我们自己的业务系统或者平台上。所以,我们需要自己去实现一套粒度更细、监控更智能、告警更精准的系统。其监控覆盖范围应该包括基础硬件、操作系统(操作系统偶尔出现系统进程hang住情况,导致broker假死,无法正常提供服务)、Kafka的broker服务、Kafka客户端应用程序、zookeeper集群、上下游全链路监控。
1.4.1 硬件监控
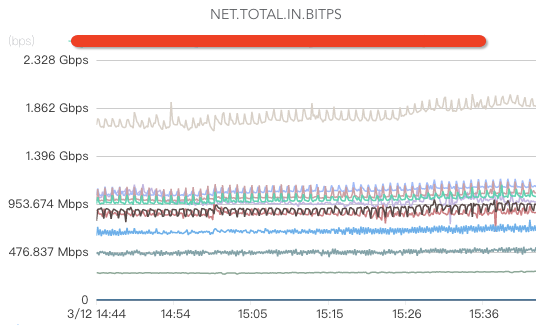
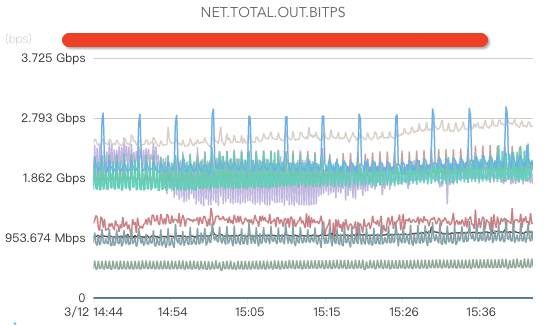
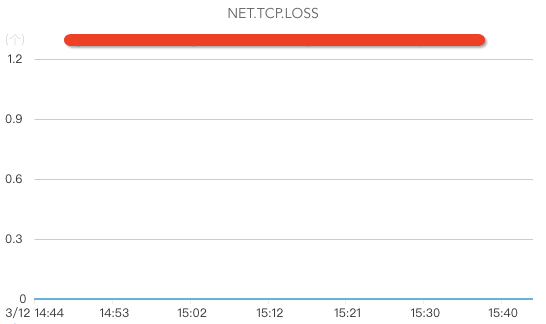
网络监控:
核心指标包括网络入流量、网络出流量、网络丢包、网络重传、处于TIME.WAIT的TCP连接数、交换机、机房带宽、DNS服务器监控(如果DNS服务器异常,可能出现流量黑洞,引起大面积业务故障)等。
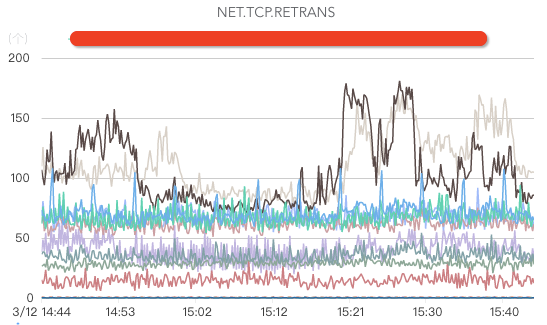
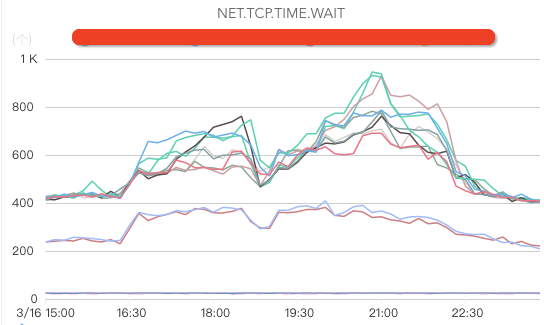
磁盘监控:
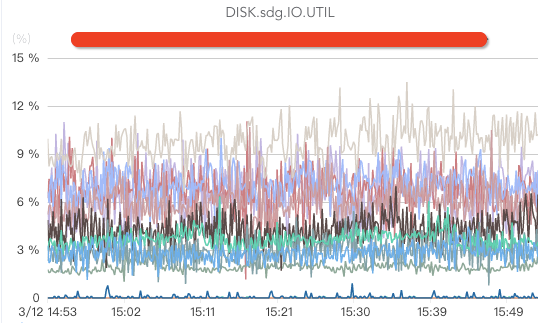
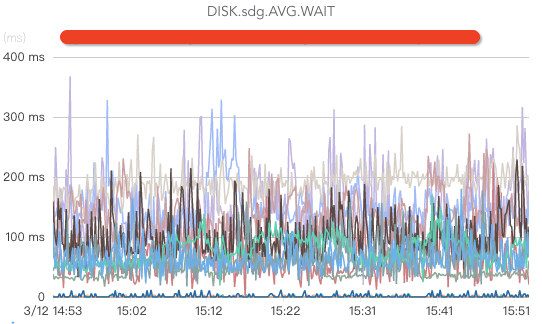
核心指标包括监控磁盘write、磁盘read(如果消费时没有延时,或者只有少量延时,一般都没有磁盘read操作)、磁盘ioutil、磁盘iowait(这个指标如果过高说明磁盘负载较大)、磁盘存储空间、磁盘坏盘、磁盘坏块/坏道(坏道或者坏块将导致broker处于半死不活状态,由于有crc校验,消费者将被卡住)等。
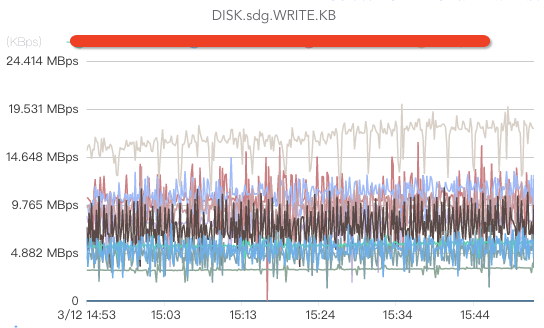
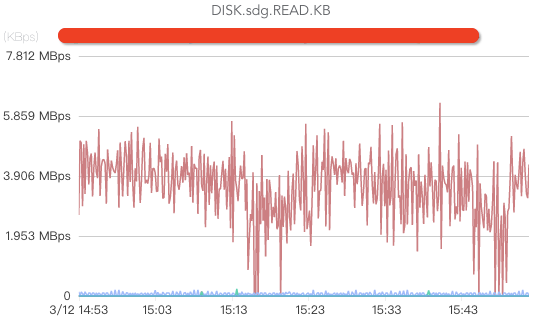
CPU监控:
监控CPU空闲率/负载,主板故障等,通常CPU使用率比较低不是Kafka的瓶颈。
内存/交换区监控:
内存使用率,内存故障。一般情况下,服务器上除了启动Kafka的broker时分配的堆内存以外,其他内存基本全部被用来做PageCache。
缓存命中率监控:
由于是否读磁盘对Kafka的性能影响很大,所以我们需要监控Linux的PageCache缓存命中率,如果缓存命中率高,则说明消费者基本命中缓存。
详细内容请阅读文章:《Linux Page Cache调优在Kafka中的应用》。
系统日志:
我们需要对操作系统的错误日志进行监控告警,及时发现一些硬件故障。
1.4.2 broker服务监控
broker服务的监控,主要是通过在broker服务启动时指定JMX端口,然后通过实现一套指标采集程序去采集JMX指标。(服务端指标官网地址)
broker级监控:broker进程、broker入流量字节大小/记录数、broker出流量字节大小/记录数、副本同步入流量、副本同步出流量、broker间流量偏差、broker连接数、broker请求队列数、broker网络空闲率、broker生产延时、broker消费延时、broker生产请求数、broker消费请求数、broker上分布leader个数、broker上分布副本个数、broker上各磁盘流量、broker GC等。
topic级监控:topic入流量字节大小/记录数、topic出流量字节大小/记录数、无流量topic、topic流量突变(突增/突降)、topic消费延时。
partition级监控:分区入流量字节大小/记录数、分区出流量字节大小/记录数、topic分区副本缺失、分区消费延迟记录、分区leader切换、分区数据倾斜(生产消息时,如果指定了消息的key容易造成数据倾斜,这严重影响Kafka的服务性能)、分区存储大小(可以治理单分区过大的topic)。
用户级监控:用户出/入流量字节大小、用户出/入流量被限制时间、用户流量突变(突增/突降)。
broker服务日志监控:对server端打印的错误日志进行监控告警,及时发现服务异常。
1.4.3.客户端监控
客户端监控主要是自己实现一套指标上报程序,这个程序需要实现
org.apache.kafka.common.metrics.MetricsReporter 接口。然后在生产者或者消费者的配置中加入配置项 metric.reporters,如下所示:
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//ClientMetricsReporter类实现org.apache.kafka.common.metrics.MetricsReporter接口
props.put(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG, ClientMetricsReporter.class.getName());
...
客户端指标官网地址:
http://kafka.apache.org/21/documentation.html#selector_monitoring
http://kafka.apache.org/21/documentation.html#common_node_monitoring
http://kafka.apache.org/21/documentation.html#producer_monitoring
http://kafka.apache.org/21/documentation.html#producer_sender_monitoring
http://kafka.apache.org/21/documentation.html#consumer_monitoring
http://kafka.apache.org/21/documentation.html#consumer_fetch_monitoring
客户端监控流程架构如下图所示:
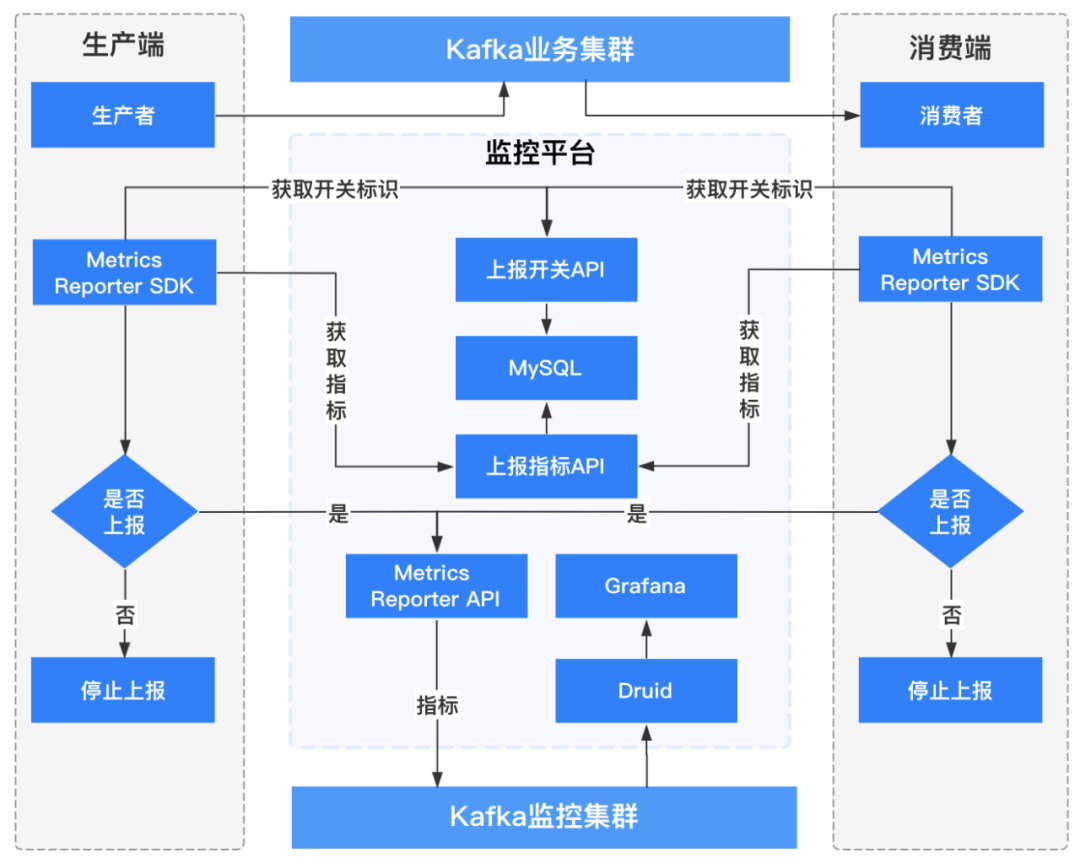
1.4.3.1 生产者客户端监控
维度:用户名称、客户端ID、客户端IP、topic名称、集群名称、brokerIP;
指标:连接数、IO等待时间、生产流量大小、生产记录数、请求次数、请求延时、发送错误/重试次数等。
1.4.3.2 消费者客户端监控
维度:用户名称、客户端ID、客户端IP、topic名称、集群名称、消费组、brokerIP、topic分区;
指标:连接数、io等待时间、消费流量大小、消费记录数、消费延时、topic分区消费延迟记录等。
1.4.4 Zookeeper监控
Zookeeper进程监控;
Zookeeper的leader切换监控;
Zookeeper服务的错误日志监控;
1.4.5 全链路监控
当数据链路非常长的时候(比如:业务应用->埋点SDk->数据采集->Kafka->实时计算->业务应用),我们定位问题通常需要经过多个团队反复沟通与排查才能发现问题到底出现在哪个环节,这样排查问题效率比较低下。在这种情况下,我们就需要与上下游一起梳理整个链路的监控。出现问题时,第一时间定位问题出现在哪个环节,缩短问题定位与故障恢复时间。
1.5 资源隔离
1.5.1 相同集群不同业务资源物理隔离
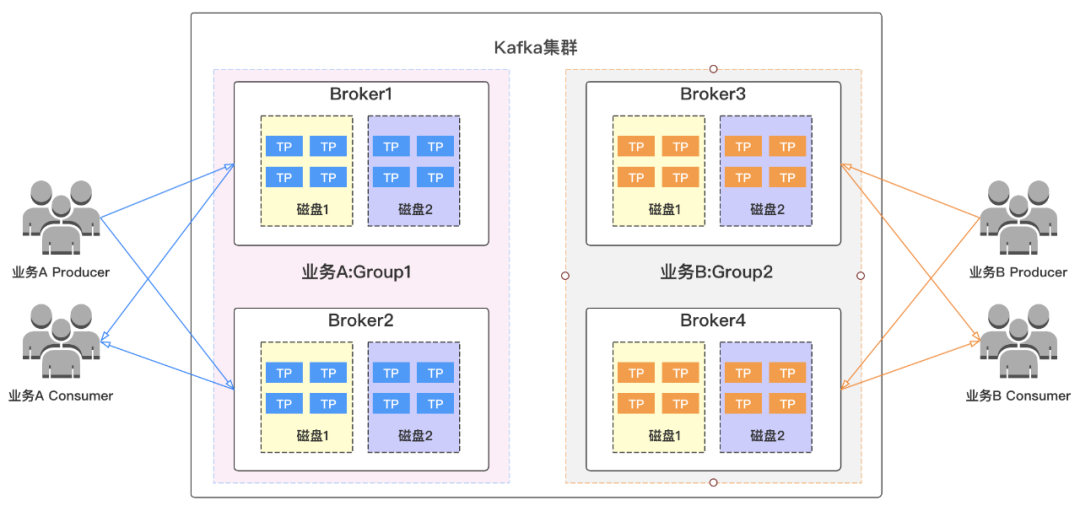
我们对所有集群中不同对业务进行资源组物理隔离,避免各业务之间相互影响。在这里,我们假设集群有4个broker节点(Broker1/Broker2/Broker3/Broker4),2个业务(业务A/业务B),他们分别拥有topic分区分布如下图所示,两个业务topic都分散在集群的各个broker上,并且在磁盘层面也存在交叉。
试想一下,如果我们其中一个业务异常,比如流量突增,导致broker节点异常或者被打挂。那么这时候另外一个业务也将受到影响,这样将大大的影响了我们服务的可用性,造成故障,扩大了故障影响范围。
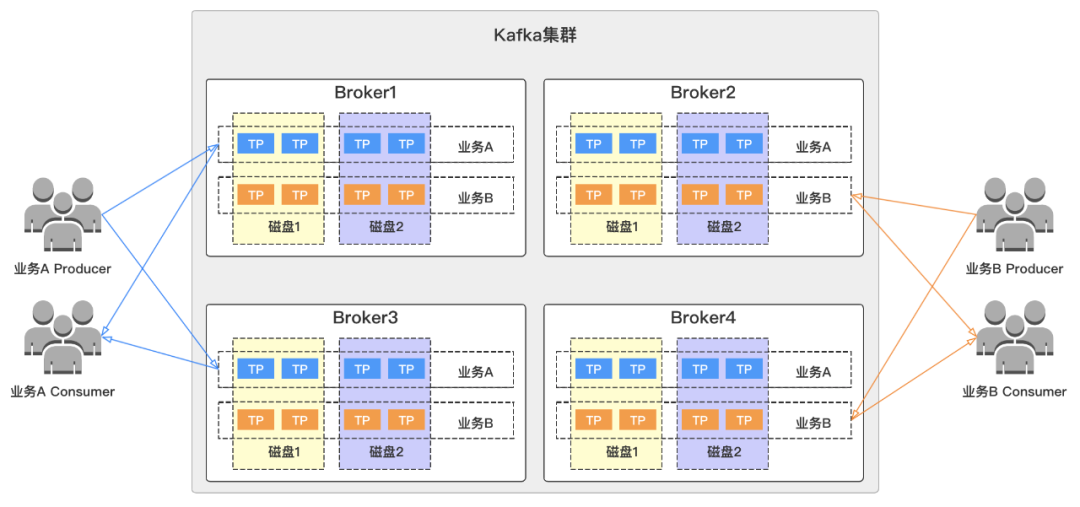
针对这些痛点,我们可以对集群中的业务进行物理资源隔离,各业务独享资源,进行资源组划分(这里把4各broker划分为Group1和Group2两个资源组)如下图所示,不同业务的topic分布在自己的资源组内,当其中一个业务异常时,不会波及另外一个业务,这样就可以有效的缩小我们的故障范围,提高服务可用性。
1.6 集群归类
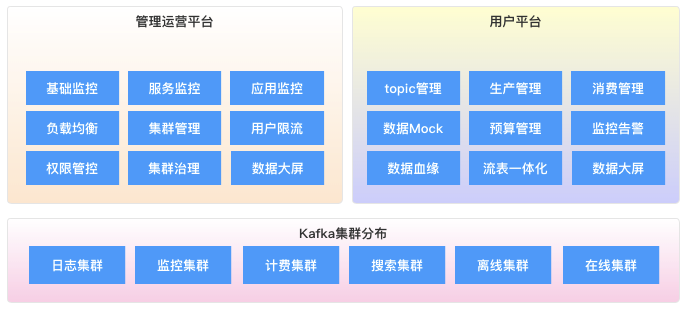
我们把集群根据业务特点进行拆分为日志集群、监控集群、计费集群、搜索集群、离线集群、在线集群等,不同场景业务放在不同集群,避免不同业务相互影响。
1.7 扩容/缩容
1.7.1 topic扩容分区
随着topic数据量增长,我们最初创建的topic指定的分区个数可能已经无法满足数量流量要求,所以我们需要对topic的分区进行扩展。扩容分区时需要考虑一下几点:
必须保证topic分区leader与follower轮询的分布在资源组内所有broker上,让流量分布更加均衡,同时需要考虑相同分区不同副本跨机架分布以提高容灾能力;
当topic分区leader个数除以资源组节点个数有余数时,需要把余数分区leader优先考虑放入流量较低的broker。
1.7.2 broker上线
随着业务量增多,数据量不断增大,我们的集群也需要进行broker节点扩容。关于扩容,我们需要实现以下几点:
扩容智能评估:根据集群负载,把是否需要扩容评估程序化、智能化;
智能扩容:当评估需要扩容后,把扩容流程以及流量均衡平台化。
1.7.3 broker下线
某些场景下,我们需要下线我们的broker,主要包括以下几个场景:
一些老化的服务器需要下线,实现节点下线平台化;
服务器故障,broker故障无法恢复,我们需要下线故障服务器,实现节点下线平台化;
有更优配置的服务器替换已有broker节点,实现下线节点平台化。
1.8 负载均衡
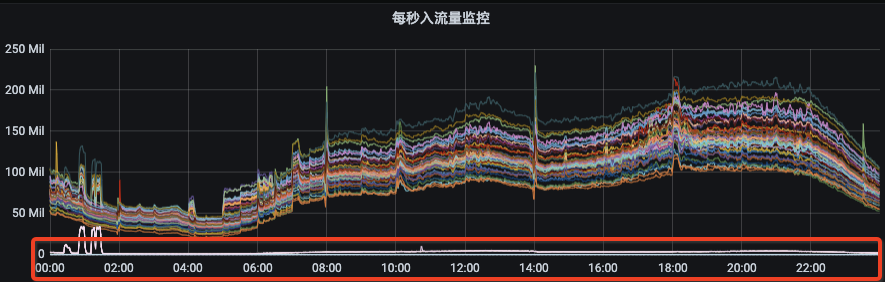
我们为什么需要负载均衡呢?首先,我们来看第一张图,下图是我们集群某个资源组刚扩容后的流量分布情况,流量无法自动的分摊到我们新扩容后的节点上。那么这个时候需要我们手动去触发数据迁移,把部分副本迁移至新节点上才能实现流量均衡。
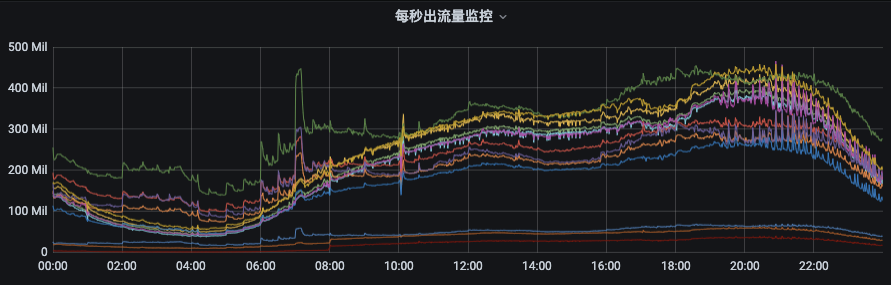
下面,我们来看一下第二张图。这张图我们可以看出流量分布非常不均衡,最低和最高流量偏差数倍以上。这和Kafka的架构特点有关,当集群规模与数据量达到一定量后,必然出现当问题。这种情况下,我们也需要进行负载均衡。
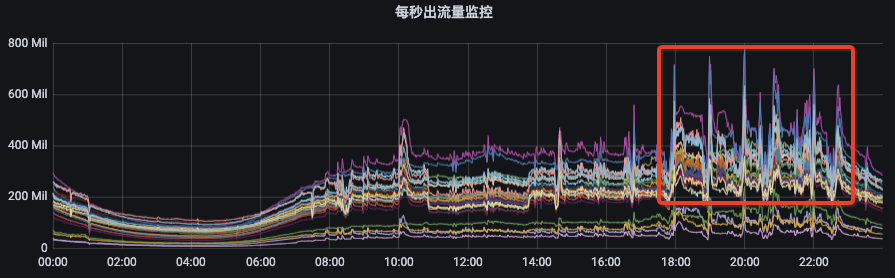
我们再来看看第三张图。这里我们可以看出出流量只有部分节点突增,这就是topic分区在集群内部不够分散,集中分布到了某几个broker导致,这种情况我们也需要进行扩容分区和均衡。
我们比较理想的流量分布应该如下图所示,各节点间流量偏差非常小,这种情况下,既可以增强集群扛住流量异常突增的能力又可以提升集群整体资源利用率和服务稳定性,降低成本。
负载均衡我们需要实现以下效果:
1)生成副本迁移计划以及执行迁移任务平台化、自动化、智能化;
2)执行均衡后broker间流量比较均匀,且单个topic分区均匀分布在所有broker节点上;
3)执行均衡后broker内部多块磁盘间流量比较均衡;
要实现这个效果,我们需要开发一套自己的负载均衡工具,如对开源的 cruise control进行二次开发;此工具的核心主要在生成迁移计划的策略,迁移计划的生成方案直接影响到最后集群负载均衡的效果。参考内容:
2. Introduction to Kafka Cruise Control
3. Cloudera Cruise Control REST API Reference
cruise control架构图如下:
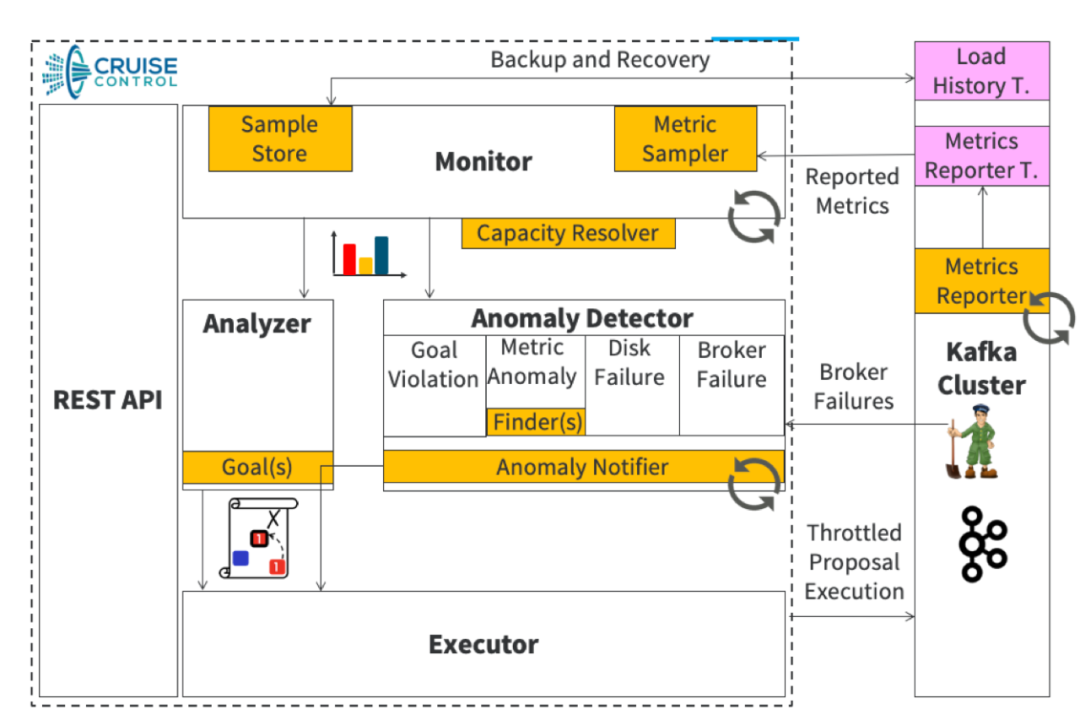
在生成迁移计划时,我们需要考虑以下几点:
1)选择核心指标作为生成迁移计划的依据,比如出流量、入流量、机架、单topic分区分散性等;
2)优化用来生成迁移计划的指标样本,比如过滤流量突增/突降/掉零等异常样本;
3)各资源组的迁移计划需要使用的样本全部为资源组内部样本,不涉及其他资源组,无交叉;
4)治理单分区过大topic,让topic分区分布更分散,流量不集中在部分broker,让topic单分区数据量更小,这样可以减少迁移的数据量,提升迁移速度;
5)已经均匀分散在资源组内的topic,加入迁移黑名单,不做迁移,这样可以减少迁移的数据量,提升迁移速度;
6)做topic治理,排除长期无流量topic对均衡的干扰;
7)新建topic或者topic分区扩容时,应让所有分区轮询分布在所有broker节点,轮询后余数分区优先分布流量较低的broker;
8)扩容broker节点后开启负载均衡时,优先把同一broker分配了同一大流量(流量大而不是存储空间大,这里可以认为是每秒的吞吐量)topic多个分区leader的,迁移一部分到新broker节点;
9)提交迁移任务时,同一批迁移计划中的分区数据大小偏差应该尽可能小,这样可以避免迁移任务中小分区迁移完成后长时间等待大分区的迁移,造成任务倾斜;
1.9 安全认证
是不是我们的集群所有人都可以随意访问呢?当然不是,为了集群的安全,我们需要进行权限认证,屏蔽非法操作。主要包括以下几个方面需要做安全认证:
(1)生产者权限认证;
(2)消费者权限认证;
(3)指定数据目录迁移安全认证;
1.10 集群容灾
跨机架容灾:
跨集群/机房容灾:如果有异地双活等业务场景时,可以参考Kafka2.7版本的MirrorMaker 2.0。
GitHub地址:https://github.com
精确KIP地址 :https://cwiki.apache.org
ZooKeeper集群上Kafka元数据恢复:我们会定期对ZooKeeper上的权限信息数据做备份处理,当集群元数据异常时用于恢复。
1.11 参数/配置优化
broker服务参数优化:这里我只列举部分影响性能的核心参数。
num.network.threads
#创建Processor处理网络请求线程个数,建议设置为broker当CPU核心数*2,这个值太低经常出现网络空闲太低而缺失副本。
num.io.threads
#创建KafkaRequestHandler处理具体请求线程个数,建议设置为broker磁盘个数*2
num.replica.fetchers
#建议设置为CPU核心数/4,适当提高可以提升CPU利用率及follower同步leader数据当并行度。
compression.type
#建议采用lz4压缩类型,压缩可以提升CPU利用率同时可以减少网络传输数据量。
queued.max.requests
#如果是生产环境,建议配置最少500以上,默认为500。
log.flush.scheduler.interval.ms
log.flush.interval.ms
log.flush.interval.messages
#这几个参数表示日志数据刷新到磁盘的策略,应该保持默认配置,刷盘策略让操作系统去完成,由操作系统来决定什么时候把数据刷盘;
#如果设置来这个参数,可能对吞吐量影响非常大;
auto.leader.rebalance.enable
#表示是否开启leader自动负载均衡,默认true;我们应该把这个参数设置为false,因为自动负载均衡不可控,可能影响集群性能和稳定;
生产优化:这里我只列举部分影响性能的核心参数。
linger.ms
#客户端生产消息等待多久时间才发送到服务端,单位:毫秒。和batch.size参数配合使用;适当调大可以提升吞吐量,但是如果客户端如果down机有丢失数据风险;
batch.size
#客户端发送到服务端消息批次大小,和linger.ms参数配合使用;适当调大可以提升吞吐量,但是如果客户端如果down机有丢失数据风险;
compression.type
#建议采用lz4压缩类型,具备较高的压缩比及吞吐量;由于Kafka对CPU的要求并不高,所以,可以通过压缩,充分利用CPU资源以提升网络吞吐量;
buffer.memory
#客户端缓冲区大小,如果topic比较大,且内存比较充足,可以适当调高这个参数,默认只为33554432(32MB)
retries
#生产失败后的重试次数,默认0,可以适当增加。当重试超过一定次数后,如果业务要求数据准确性较高,建议做容错处理。
retry.backoff.ms
#生产失败后,重试时间间隔,默认100ms,建议不要设置太大或者太小。
除了一些核心参数优化外,我们还需要考虑比如topic的分区个数和topic保留时间;如果分区个数太少,保留时间太长,但是写入数据量非常大的话,可能造成以下问题:
1)topic分区集中落在某几个broker节点上,导致流量副本失衡;
2)导致broker节点内部某几块磁盘读写超负载,存储被写爆;
1.11.1 消费优化
消费最大的问题,并且经常出现的问题就是消费延时,拉历史数据。当大量拉取历史数据时将出现大量读盘操作,污染pagecache,这个将加重磁盘的负载,影响集群性能和稳定;
可以怎样减少或者避免大量消费延时呢?
1)当topic数据量非常大时,建议一个分区开启一个线程去消费;
2)对topic消费延时添加监控告警,及时发现处理;
3)当topic数据可以丢弃时,遇到超大延时,比如单个分区延迟记录超过千万甚至数亿,那么可以重置topic的消费点位进行紧急处理;【此方案一般在极端场景才使用】
4)避免重置topic的分区offset到很早的位置,这可能造成拉取大量历史数据;
1.11.2 Linux服务器参数优化
我们需要对Linux的文件句柄、pagecache等参数进行优化。可参考《Linux Page Cache调优在Kafka中的应用》。
1.12.硬件优化
磁盘优化
在条件允许的情况下,可以采用SSD固态硬盘替换HDD机械硬盘,解决机械盘IO性能较低的问题;如果没有SSD固态硬盘,则可以对服务器上的多块硬盘做硬RAID(一般采用RAID10),让broker节点的IO负载更加均衡。如果是HDD机械硬盘,一个broker可以挂载多块硬盘,比如 12块*4TB。
内存
由于Kafka属于高频读写型服务,而Linux的读写请求基本走的都是Page Cache,所以单节点内存大一些对性能会有比较明显的提升。一般选择256GB或者更高。
网络
提升网络带宽:在条件允许的情况下,网络带宽越大越好。因为这样网络带宽才不会成为性能瓶颈,最少也要达到万兆网络( 10Gb,网卡为全双工)才能具备相对较高的吞吐量。如果是单通道,网络出流量与入流量之和的上限理论值是1.25GB/s;如果是双工双通道,网络出入流量理论值都可以达到1.25GB/s。
网络隔离打标:由于一个机房可能既部署有离线集群(比如HBase、Spark、Hadoop等)又部署有实时集群(如Kafka)。那么实时集群和离线集群挂载到同一个交换机下的服务器将出现竞争网络带宽的问题,离线集群可能对实时集群造成影响。所以我们需要进行交换机层面的隔离,让离线机器和实时集群不要挂载到相同的交换机下。即使有挂载到相同交换机下面的,我们也将进行网络通行优先级(金、银、铜、铁)标记,当网络带宽紧张的时候,让实时业务优先通行。
CPU
Kafka的瓶颈不在CPU,单节点一般有32核的CPU都足够使用。
1.13.平台化
现在问题来了,前面我们提到很多监控、优化等手段;难道我们管理员或者业务用户对集群所有的操作都需要登录集群服务器吗?答案当然是否定的,我们需要丰富的平台化功能来支持。一方面是为了提升我们操作的效率,另外一方面也是为了提升集群的稳定和降低出错的可能。
配置管理
黑屏操作,每次修改broker的server.properties配置文件都没有变更记录可追溯,有时可能因为有人修改了集群配置导致一些故障,却找不到相关记录。如果我们把配置管理做到平台上,每次变更都有迹可循,同时降低了变更出错的风险。
滚动重启
当我们需要做线上变更时,有时候需要对集群对多个节点做滚动重启,如果到命令行去操作,那效率将变得很低,而且需要人工去干预,浪费人力。这个时候我们就需要把这种重复性的工作进行平台化,提升我们的操作效率。
集群管理
集群管理主要是把原来在命令行的一系列操作做到平台上,用户和管理员不再需要黑屏操作Kafka集群;这样做主要有以下优点:
提升操作效率;
操作出错概率更小,集群更安全;
所有操作有迹可循,可以追溯;
集群管理主要包括:broker管理、topic管理、生产/消费权限管理、用户管理等
1.13.1 mock功能
在平台上为用户的topic提供生产样例数据与消费抽样的功能,用户可以不用自己写代码也可以测试topic是否可以使用,权限是否正常;
在平台上为用户的topic提供生产/消费权限验证功能,让用户可以明确自己的账号对某个topic有没有读写权限;
1.13.2 权限管理
把用户读/写权限管理等相关操作进行平台化。
1.13.3 扩容/缩容
把broker节点上下线做到平台上,所有的上线和下线节点不再需要操作命令行。
1.13.4 集群治理
1)无流量topic的治理,对集群中无流量topic进行清理,减少过多无用元数据对集群造成的压力;
2)topic分区数据大小治理,把topic分区数据量过大的topic(如单分区数据量超过100GB/天)进行梳理,看看是否需要扩容,避免数据集中在集群部分节点上;
3)topic分区数据倾斜治理,避免客户端在生产消息的时候,指定消息的key,但是key过于集中,消息只集中分布在部分分区,导致数据倾斜;
4)topic分区分散性治理,让topic分区分布在集群尽可能多的broker上,这样可以避免因topic流量突增,流量只集中到少数节点上的风险,也可以避免某个broker异常对topic影响非常大;
5)topic分区消费延时治理;一般有延时消费较多的时候有两种情况,一种是集群性能下降,另外一种是业务方的消费并发度不够,如果是消费者并发不够的化应该与业务联系增加消费并发。
1.13.5 监控告警
1)把所有指标采集做成平台可配置,提供统一的指标采集和指标展示及告警平台,实现一体化监控;
2)把上下游业务进行关联,做成全链路监控;
3)用户可以配置topic或者分区流量延时、突变等监控告警;
1.13.6 业务大屏
业务大屏主要指标:集群个数、节点个数、日入流量大小、日入流量记录、日出流量大小、日出流量记录、每秒入流量大小、每秒入流量记录、每秒出流量大小、每秒出流量记录、用户个数、生产延时、消费延时、数据可靠性、服务可用性、数据存储大小、资源组个数、topic个数、分区个数、副本个数、消费组个数等指标。
1.13.7 流量限制
把用户流量现在做到平台,在平台进行智能限流处理。
1.13.8 负载均衡
把自动负载均衡功能做到平台,通过平台进行调度和管理。
1.13.9 资源预算
当集群达到一定规模,流量不断增长,那么集群扩容机器从哪里来呢?业务的资源预算,让集群里面的多个业务根据自己在集群中当流量去分摊整个集群的硬件成本;当然,独立集群与独立隔离的资源组,预算方式可以单独计算。
1.14.性能评估
1.14.1 单broker性能评估
我们做单broker性能评估的目的包括以下几方面:
1)为我们进行资源申请评估提供依据;
2)让我们更了解集群的读写能力及瓶颈在哪里,针对瓶颈进行优化;
3)为我们限流阈值设置提供依据;
4)为我们评估什么时候应该扩容提供依据;
1.14.2 topic分区性能评估
1)为我们创建topic时,评估应该指定多少分区合理提供依据;
2)为我们topic的分区扩容评估提供依据;
1.14.3 单磁盘性能评估
1)为我们了解磁盘的真正读写能力,为我们选择更合适Kafka的磁盘类型提供依据;
2)为我们做磁盘流量告警阈值设置提供依据;
1.14.4 集群规模限制摸底
1)我们需要了解单个集群规模的上限或者是元数据规模的上限,探索相关信息对集群性能和稳定性的影响;
2)根据摸底情况,评估集群节点规模的合理范围,及时预测风险,进行超大集群的拆分等工作;
1.15 DNS+LVS的网络架构
当我们的集群节点达到一定规模,比如单集群数百个broker节点,那么此时我们生产消费客户端指定bootstrap.servers配置时,如果指定呢?是随便选择其中几个broker配置还是全部都配上呢?
其实以上做法都不合适,如果只配置几个IP,当我们配置当几个broker节点下线后,我们当应用将无法连接到Kafka集群;如果配置所有IP,那更不现实啦,几百个IP,那么我们应该怎么做呢?
方案:采用DNS+LVS网络架构,最终生产者和消费者客户端只需要配置域名就可以啦。需要注意的是,有新节点加入集群时,需要添加映射;有节点下线时,需要从映射中踢掉,否则这批机器如果拿到其他的地方去使用,如果端口和Kafka的一样的话,原来集群部分请求将发送到这个已经下线的服务器上来,造成生产环境重点故障。
二、开源版本功能缺陷
RTMP协议主要的特点有:多路复用,分包和应用层协议。以下将对这些特点进行详细的描述。
2.1 副本迁移
无法实现增量迁移;【我们已经基于2.1.1版本源码改造,实现了增量迁移】
无法实现并发迁移;【开源版本直到2.6.0才实现了并发迁移】
无法实现终止迁移;【我们已经基于2.1.1版本源码改造,实现了终止副本迁移】【开源版本直到2.6.0才实现了暂停迁移,和终止迁移有些不一样,不会回滚元数据】
当指定迁移数据目录时,迁移过程中,如果把topic保留时间改短,topic保留时间针对正在迁移topic分区不生效,topic分区过期数据无法删除;【开源版本bug,目前还没有修复】
当指定迁移数据目录时,当迁移计划为以下场景时,整个迁移任务无法完成迁移,一直处于卡死状态;【开源版本bug,目前还没有修复】
迁移过程中,如果有重启broker节点,那个broker节点上的所有leader分区无法切换回来,导致节点流量全部转移到其他节点,直到所有副本被迁移完毕后leader才会切换回来;【开源版本bug,目前还没有修复】。
在原生的Kafka版本中存在以下指定数据目录场景无法迁移完毕的情况,此版本我们也不决定修复次bug:
1.针对同一个topic分区,如果部分目标副本相比原副本是所属broker发生变化,部分目标副本相比原副本是broker内部所属数据目录发生变化;
那么副本所属broker发生变化的那个目标副本可以正常迁移完毕,目标副本是在broker内部数据目录发生变化的无法正常完成迁移;
但是旧副本依然可以正常提供生产、消费服务,并且不影响下一次迁移任务的提交,下一次迁移任务只需要把此topic分区的副本列表所属broker列表变更后提交依然可以正常完成迁移,并且可以清理掉之前未完成的目标副本;
这里假设topic yyj1的初始化副本分布情况如下:
{
"version":1,
"partitions":[
{"topic":"yyj","partition":0,"replicas":[1000003,1000001],"log_dirs":["/kfk211data/data31","/kfk211data/data13"]}
]
}
//迁移场景1:
{
"version":1,
"partitions":[
{"topic":"yyj","partition":0,"replicas":[1000003,1000002],"log_dirs":["/kfk211data/data32","/kfk211data/data23"]}
]
}
//迁移场景2:
{
"version":1,
"partitions":[
{"topic":"yyj","partition":0,"replicas":[1000002,1000001],"log_dirs":["/kfk211data/data22","/kfk211data/data13"]}
]
}
针对上述的topic yyj1的分布分布情况,此时如果我们的迁移计划为“迁移场景1”或迁移场景2“,那么都将出现有副本无法迁移完毕的情况。
但是这并不影响旧副本处理生产、消费请求,并且我们可以正常提交其他的迁移任务。
为了清理旧的未迁移完成的副本,我们只需要修改一次迁移计划【新的目标副本列表和当前分区已分配副本列表完全不同即可】,再次提交迁移即可。
这里,我们依然以上述的例子做迁移计划修改如下:
{
"version":1,
"partitions":[
{"topic":"yyj","partition":0,"replicas":[1000004,1000005],"log_dirs":["/kfk211data/data42","/kfk211data/data53"]}
]
}
这样我们就可以正常完成迁移。
2.2 流量协议
限流粒度较粗,不够灵活精准,不够智能。
当前限流维度组合
/config/users/<user>/clients/<client-id>
/config/users/<user>/clients/<default>
/config/users/<user>
/config/users/<default>/clients/<client-id>
/config/users/<default>/clients/<default>
/config/users/<default>
/config/clients/<client-id>
/config/clients/<default>
存在问题
当同一个broker上有多个用户同时进行大量的生产和消费时,想要让broker可以正常运行,那必须在做限流时让所有的用户流量阈值之和不超过broker的吞吐上限;如果超过broker上限,那么broker就存在被打挂的风险;然而,即使用户流量没有达到broker的流量上限,但是,如果所有用户流量集中到了某几块盘上,超过了磁盘的读写负载,也会导致所有生产、消费请求将被阻塞,broker可能处于假死状态。
解决方案
(1)改造源码,实现单个broker流量上限限制,只要流量达到broker上限立即进行限流处理,所有往这个broker写的用户都可以被限制住;或者对用户进行优先级处理,放过高优先级的,限制低优先级的;
(2)改造源码,实现broker上单块磁盘流量上限限制(很多时候都是流量集中到某几块磁盘上,导致没有达到broker流量上限却超过了单磁盘读写能力上限),只要磁盘流量达到上限,立即进行限流处理,所有往这个磁盘写的用户都可以被限制住;或者对用户进行优先级处理,放过高优先级的,限制低优先级的;
(3)改造源码,实现topic维度限流以及对topic分区的禁写功能;
(4)改造源码,实现用户、broker、磁盘、topic等维度组合精准限流;
三、kafka发展趋势
3.1 Kafka社区迭代计划
3.3 controller与broker分离,引入raft协议作为controller的仲裁机制(KIP-630)
3.4 分层存储(KIP-405)
3.7 下载与各版本特性说明
3.8 Kafka所有KIP地址
四、如何贡献社区
4.1 哪些点可以贡献
http://kafka.apache.org/contributing
4.2 wiki贡献地址
https://cwiki.apache.org/confluence/dashboard.action#all-updates
4.3 issues地址
1)https://issues.apache.org/jira/projects/KAFKA/issues/KAFKA-10444?filter=allopenissues
2)https://issues.apache.org/jira/secure/BrowseProjects.jspa?selectedCategory=all
4.4 主要committers
http://kafka.apache.org/committers
作者:vivo互联网服务器团队-Yang Yijun
Kafka万亿级消息实战的更多相关文章
- Kafka 万亿级消息实践之资源组流量掉零故障排查分析
作者:vivo 互联网服务器团队-Luo Mingbo 一.Kafka 集群部署架构 为了让读者能与小编在后续的问题分析中有更好的共鸣,小编先与各位读者朋友对齐一下我们 Kafka 集群的部署架构及服 ...
- 腾讯自研万亿级消息中间件TubeMQ为什么要捐赠给Apache?
导语 | 近日,云+社区技术沙龙“腾讯开源技术”圆满落幕.本次沙龙邀请了多位腾讯技术专家围绕腾讯开源与各位开发者进行探讨,深度揭秘了腾讯开源项目TencentOS tiny.TubeMQ.Kona J ...
- 杂文笔记《Redis在万亿级日访问量下的中断优化》
杂文笔记<Redis在万亿级日访问量下的中断优化> Redis在万亿级日访问量下的中断优化 https://mp.weixin.qq.com/s?__biz=MjM5ODI5Njc2MA= ...
- 如何基于MindSpore实现万亿级参数模型算法?
摘要:近来,增大模型规模成为了提升模型性能的主要手段.特别是NLP领域的自监督预训练语言模型,规模越来越大,从GPT3的1750亿参数,到Switch Transformer的16000亿参数,又是一 ...
- 腾讯万亿级分布式消息中间件TubeMQ正式开源
TubeMQ是腾讯在2013年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条.较之于众多明星的开源MQ组件,T ...
- 手机QQ公众号亿级消息实时群发架构
编者按:高可用架构分享及传播在架构领域具有典型意义的文章,本文由孙子荀分享.转载请注明来自高可用架构公众号 ArchNotes. 孙子荀,2009 年在华为从事内核和分布式系统的开发工作:2011 ...
- 万亿级KV存储架构与实践
一.KV 存储发展历程 我们第一代的分布式 KV 存储如下图左侧的架构所示,相信很多公司都经历过这个阶段.在客户端内做一致性哈希,在后端部署很多的 Memcached 实例,这样就实现了最基本的 KV ...
- 万亿级日志与行为数据存储查询技术剖析(续)——Tindex是改造的lucene和druid
五.Tindex 数果智能根据开源的方案自研了一套数据存储的解决方案,该方案的索引层通过改造Lucene实现,数据查询和索引写入框架通过扩展Druid实现.既保证了数据的实时性和指标自由定义的问题,又 ...
- 【HBase调优】Hbase万亿级存储性能优化总结
背景:HBase主集群在生产环境已稳定运行有1年半时间,最大的单表region数已达7200多个,每天新增入库量就有百亿条,对HBase的认识经历了懵懂到熟的过程.为了应对业务数据的压力,HBase入 ...
随机推荐
- 通过unity Distribution Portal发布华为渠道的游戏
背景说明 前面几个帖子详细介绍了: Unity Editor安装和Apk打包 手把手教您快速运行Unity提供的华为游戏demo 使用unity完成华为游戏的初始化和华为帐号登录 快速开发Unity游 ...
- 3.DataFrame的增删改查
以此为例 一.DataFrame的初步认知 在pandas中完成数据读取后数据以DataFrame保存.在操作时要以DataFrame函数进行了解 函数 含义 示例 values 元素 index 索 ...
- RichText实现动态输入关键字高亮颜色显示
int a = 0; string[] kc = new string[40] { "private","protected","public&quo ...
- 【Linux学习笔记1】-centos6.9部署django
一,centos6.9部署django 部署套件:centos6.9+nginx+mysql+uwsgi+python3+django 首先还是要明白这几个部分之间的关系(自己也是初学者,希望 ...
- Android学习之Broadcast初体验
•何为 Broadcast ? Broadcast 直译广播,接下来举个形象的例子来理解下 Broadcast: 上学的时候,每个班级都会有一个挂在墙上的大喇叭,用来广播一些通知,比如,开学要去搬书, ...
- [BFS]最优乘车
最优乘车 题目描述 HH 城是一个旅游胜地,每年都有成千上万的人前来观光.为方便游客,巴士公司在各个旅游景点及宾馆,饭店等地都设置了巴士站并开通了一些单程巴上线路.每条单程巴士线路从某个巴士站出发,依 ...
- HTML前世今生
HTML贯穿了整个互联网的发展史,就目前来看,它还会继续下去,因为HTTP和HTTPS协议在互联网中传输的主要内容,也是用户浏览的最终页面管理内容,接下来就来扒一扒HTML的前世今生. 历史舞台已交给 ...
- Leedcode算法专题训练(字符串)
4. 两个字符串包含的字符是否完全相同 242. Valid Anagram (Easy) Leetcode / 力扣 可以用 HashMap 来映射字符与出现次数,然后比较两个字符串出现的字符数量是 ...
- 数据库MySQL五
测试题复习 子查询案例 DML语句(很重要) 自增长列 为某一个字段设置自增长 修改语句 truncate实际上是DDL语句删除表再新建一个表 DCL事务 ACID 回滚:没发生 提交才更新数据 /* ...
- 第一个 vue-cli项目
第一个 vue-cli项目 什么是vue-cli vue-cli官方提供的一个脚手架,用于快速生成一个vue的项目模板: 预先定义好的目录结构及基础代码,就好比咱们在创建Maven项目时可以选择创建一 ...