企业级BI是自研还是采购?
企业级BI是自研还是采购?
上一篇《企业级BI为什么这么难做?》,谈到了企业级BI项目所具有的特殊背景,以及在“破局”方面的一点思考,其中谈论的焦点主要是在IT开发项目组外部。本篇会再谈一谈在开发项目组内部,应该如何选择企业级BI的实施方案:是自主研发还是采购商业BI产品?
(写在前面的话:如果你所在的企业预算非常充足,并且处于BI项目的初创期,那么这个问题不存在,后文可以直接略过,以节省大家宝贵的时间。)
接下来会分别从商业BI产品的系统架构和自研技术方案进行介绍与对比。
/请尊重作者劳动成果,转载请标明原文链接:/
/* https://www.cnblogs.com/jpcflyer/p/15685268.html * /
一、主流商业BI产品方案介绍
近几年国内BI发展如火如荼,已经有不少相对成熟BI产品,这里仅举例介绍几个,供参考。
FineBI
帆软的FineBI的核心功能架构如下图所示,主要包括Spider引擎和上层自助分析功能两部分。

其中Spider引擎是核心,也应该是FineBI的核心竞争所在吧,所以这里要重点研究一下。Spider能够支持抽取模式,也能支持直连模式,这也是目前成熟BI都应具备的基础功能。对于抽取模式,Spider的技术架构如下图所示。
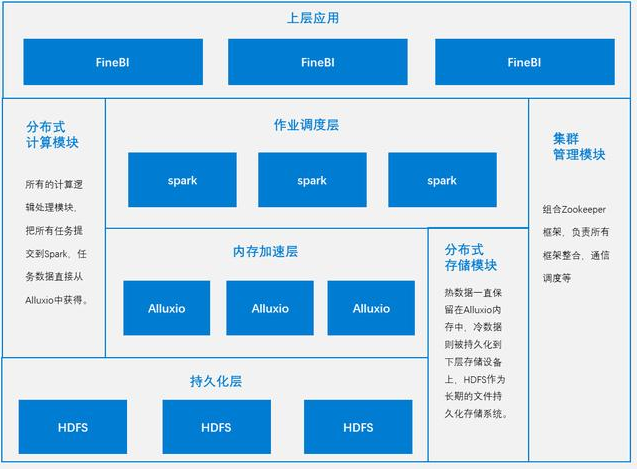
可以看出帆软的抽取模式中,底层使用了大数据的相关技术:持久化存储用HDFS,计算引擎使用spark,缓存加速使用了Alluxio......细节描述本篇不再展开。除了FineBI,帆软公司还有FineReport产品支持传统固定报表及复杂报表的制作、简道云产品支持轻应用等。
永洪BI
关于永洪BI的技术资料不多,更多的是联合企业共创的解决方案,正面消息居多,说明永洪BI的公关与宣传工作做的十分到位。下面是能找到的官方认可的最偏技术的架构图了。
当然这个图描述的都是各BI产品共性的东西,看不出来有什么亮点(保密工作做的挺好),大家就将就着看一下吧。
Smartbi
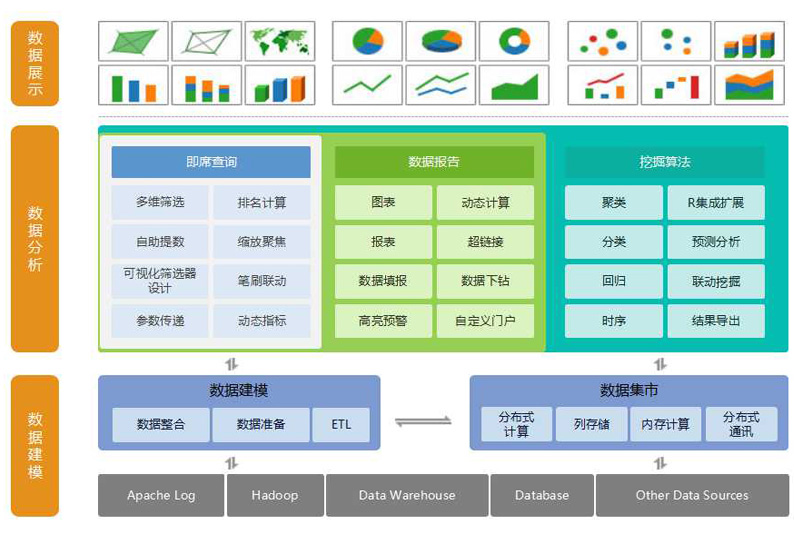
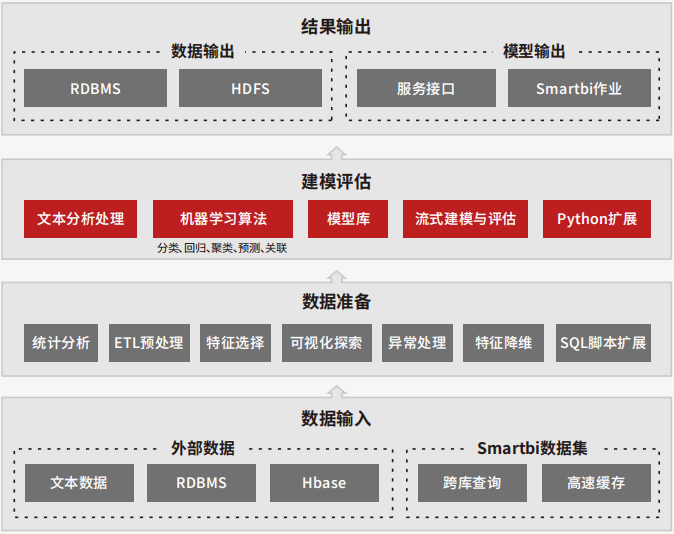
主要包含三个产品:Smartbi Insight(中国式传统报表)、Smartbi Eagle(自助分析平台)、Smartbi Mining(数据挖掘平台)。
Insight和Eagle产品主要是借助excel实现报表计算与自助分析,Mining的架构图如下:
观远guandata
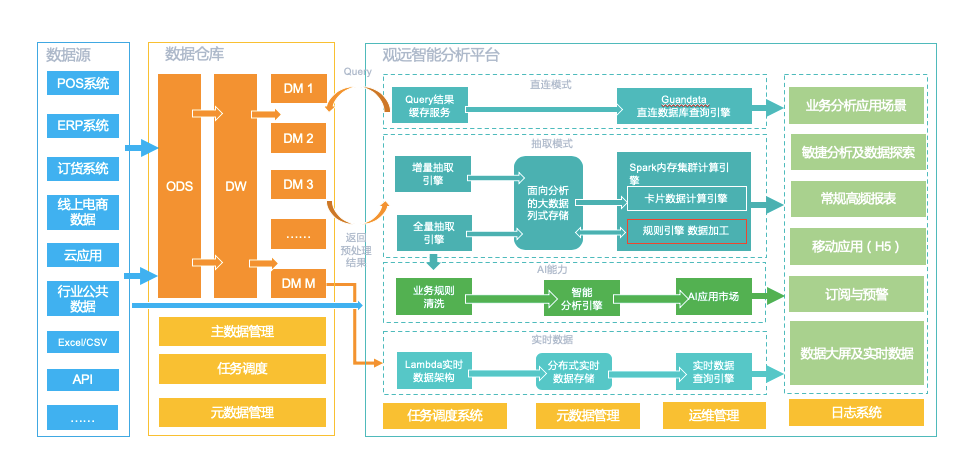
观远也是最近比较火的商业BI工具,其技术架构如下图所示。和帆软差不多,也具有直连和抽取两种模式,均基于spark计算,缓存用的是Cassandra。和帆软不同的是,为加速查询,观远尝试引入了Clickhouse,并且增加了AI方面的功能。
5、BI商业产品对比
从附录1文章中引一张对比图如下所示,综合来看,帆软和观远处于行业第一梯队(该图仅代表源文作者观点,供学习交流使用)。

二、自研技术方案介绍
一般企业级BI从系统架构角度可分为数据存储层、计算加工层、BI展现层等。企业内部基本都会有数据仓库、数据湖等企业级数据存储归档库,也有spark、clickhouse等计算引擎,所以本篇假设企业的数据底座能力已比较完善,已经具备BI工具所需要的存储与计算能力。后面重点说下BI展现层的实现方案。
建议选择在开源BI框架的基础上,按企业需求进行定制化开发。目前开源BI框架有Superset、Redash、Metabase,以及最近越来越红火的Davinci等。
Superset
Superset采用技术栈为 Python + Flask + React + Redux + SQLAlchemy ,支持多种数据源和图表类型,在Davinci出现之前,Superset的评价最高,stars数量也是最多的。
Redash
Redash采用技术栈为 Python + Flask + AngularJS + SQLAlchemy ,需要手写SQL,对业务人员不太友好,支持数据源较Superset略少。
Metabase
Metabase采用技术栈为 Clojure + React + Redux ,是页面布局和体验最好的,适合业务人员使用,但支持数据源少。
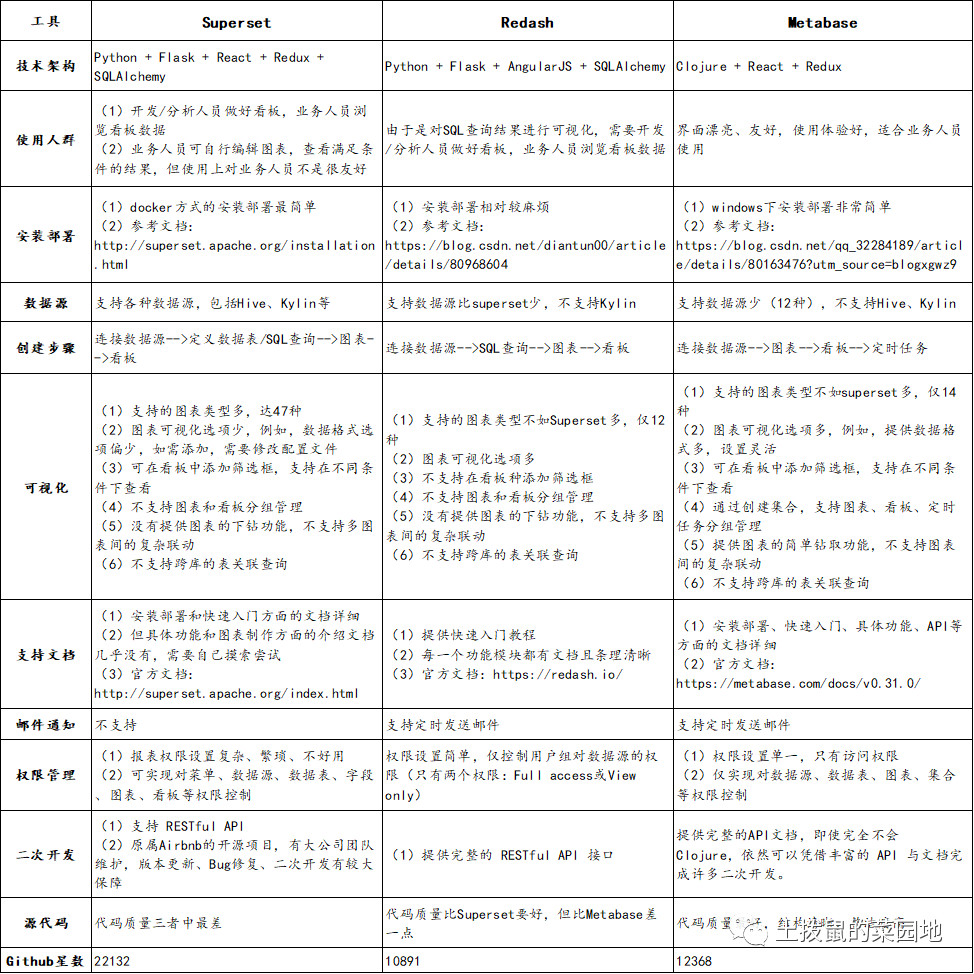
下图为Superset、Redash和Metabase的详细对比图(图片来源参考附录2)。
Davince
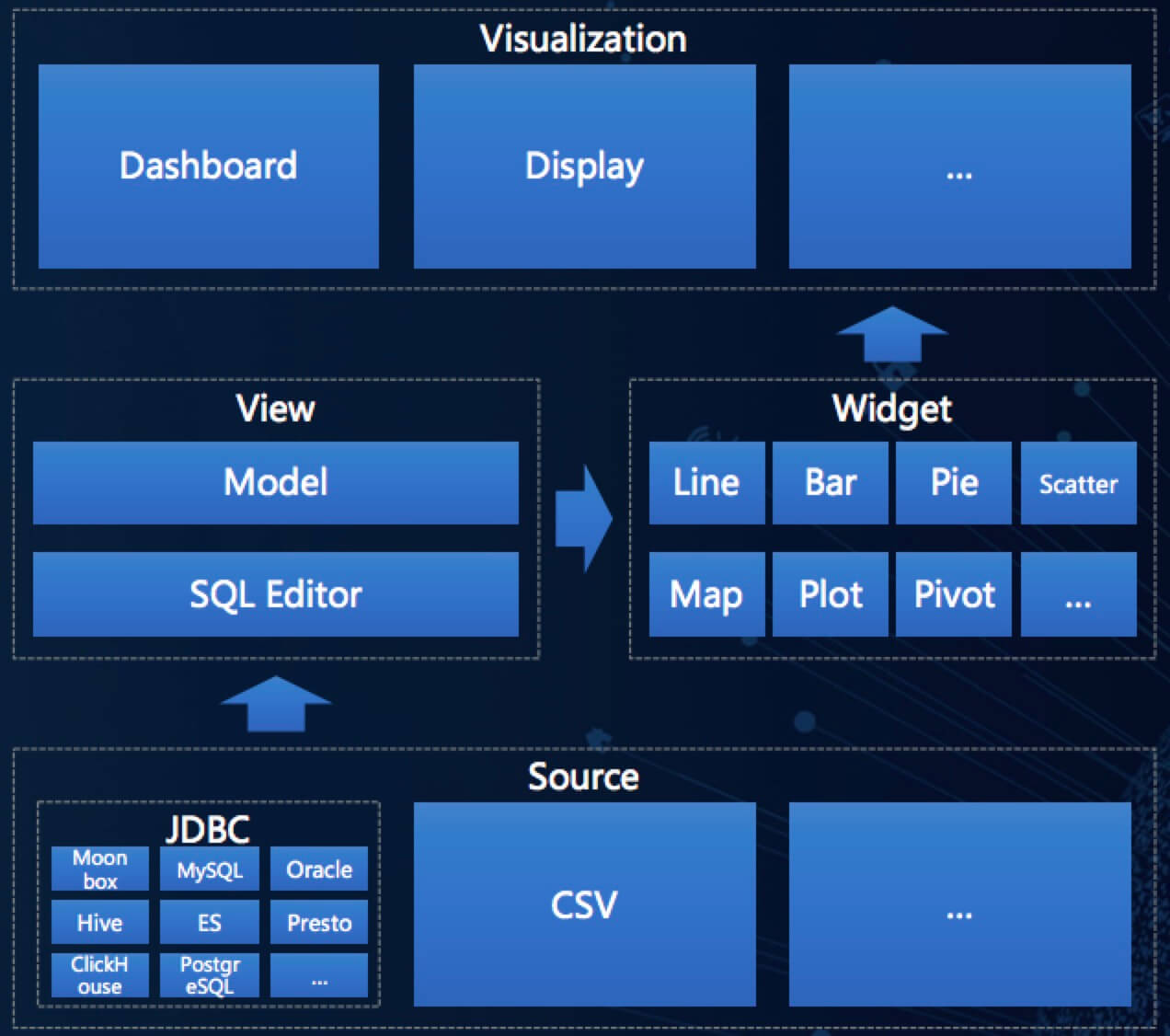
Davinci是宜信在2017年开源的可视化分析工具,面向业务人员/数据工程师/数据分析师/数据科学家,致力于提供一站式数据可视化解决方案 。其架构如下图所示。
相关概念及设计理念可以参考官网https://edp963.github.io/davinci/。对于金融行业来说,选择基于宜信的Davinci进行定制化开发还是比较合适的。(最近有核心成员离开成立了datart项目,对datart感兴趣的可以自行github)。
以上均为敏捷BI开源框架,可能需要做大量的定制化开发工作才能满足企业内部BI用户的需求,需要提前做好开发资源方面的准备。
三、采购商业BI产品与自研方案对比
1、自研
自研的优势在于可以自主进行定制化开发,能够更好的满足用户的需求。
缺点在于对产品经理、技术团队的能力要求比较高,需要非常专业的产品+开发团队,同时由于开发过程中的细节比较多、坑也多,所以在时间、人力资源有限的情况下,项目可能存在实施方面的风险。
另外从0开始建设企业级BI,在产品功能和用户体验方面可能永远追不上专业BI公司的脚步,永远在步别人的后尘,因为商业BI公司都是在市场上摸爬滚打多年、经过时间检验的,所以时间久了,业务满意度可能会持续降低,转而偏向于引入商业BI公司的产品。
2、采购
采购的优势在于能够快速引入产品部署,及时响应业务在BI方面的共性需求,用户体验也会不错。
缺点在于产品的定制化成本比较高,需要有足够的预算支持,在商务方面,也要考虑产品升级、运维等的合作模式。
四、总结
| 方案 | 优势 | 不足 |
|---|---|---|
| 自主研发,基于开源敏捷BI框架或从0开始搭建企业级BI | 1、可按需满足企业内部数据分析场景2、成本相对偏低 | 1、实施周期长,难以快速释放业务价值2、需要一只非常专业的开发团队3、用户需求场景多,产品设计和功能实现存在难度,对产品经理和开发团队有较高的专业要求 |
| 采购产品,采购新的BI产品作为企业级BI体系 | 1、快速部署,能够快速释放价值2、业务能够一起参与选型,引入外部先进经验3、功能细节比较完善,项目实施风险小 | 1、定制化开发成本高,难以满足企业内部特殊业务分析场景2、产品与厂商绑定,运维升级需要商务谈判 |
各企业的情况不同,需结合预算、开发资源、上线时间等方面综合考虑决策,部分企业还会涉及到存量BI系统的数据迁移、与企业内部系统进行定制化对接等等内容,所以需要企业因地制宜,自行设计企业级BI方案。当然如果在设计过程中有什么问题,也可以随时与我沟通交流,希望本篇对您所在企业的BI建设能有帮助,也祝各位的企业级BI越来越好。
参考资料:
企业级BI是自研还是采购?的更多相关文章
- BI系统要自研还是采购?这篇文章告诉你
首先说一下目前市面上的BI工具都有哪些吧.总体上,其实分为免费和付费两大阵营.免费阵营里,为首的当然是GA(也就是谷歌分析).PowerBI,但是由于有墙的限制,很多公司没法使用前者.付费阵营里,近两 ...
- 企业级BI为什么这么难做?
本人长期在银行内从事数据线相关工作,亲眼目睹过多个企业级BI(非部门级BI)产品从上线试用.全行推广.然后衰败没落,再替换到下一个BI产品重复此过程.企业内没有任何一个BI产品即能长期运行,又能赢得非 ...
- Airbnb开源 快速搭建企业级BI数据平台
最近在公司做一个数据可视化相关的项目,使用了Airbnb开源维护的企业级BI数据平台superset,相较于tableau这种收费的商业软件,Superset是开源维护的,同时图表的种类和颜值普遍偏高 ...
- 杂记- 3W互联网的圈子,大数据敏捷BI与微软BI的前端痛点
开篇介绍 上周末参加了一次永洪科技在中关村 3W 咖啡举行的一次线下沙龙活动 - 关于它们的产品大数据敏捷 BI 工具的介绍.由此活动,我想到了三个话题 - 3W 互联网的圈子,永洪科技的大数据敏捷 ...
- 国内BI工具/报表工具厂商简介
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- 拥有自助式BI要摒弃传统BI?
简单来说BI就是从data中提取知识和信息的一套软件解决方案.商业智能 (BI,Business Intelligence) 也就是BI,是为企业把数据转换为信息.知识 ,相应蕴育而出的IT技术.企业 ...
- 零售BI:为什么说零售行业非上一套企业BI系统不可?
如果你要问为什么现在越来越多的零售企业都会在公司上一套企业BI系统,这边文章就能解答你的疑惑. 2016年10月,马云在云栖大会上提出了"新零售"概念.在新零售时代,数字化转型打通 ...
- 2021年国内BI厂商推荐_大数据分析工具
随着互联网大数据时代的不断发展,BI让企业的工作效率变得更高效.BI的功能也随着需求的增长不断地丰富,例如,数据可视化大屏.可视化表格.商业化数据分析.数据地图等.国外的厂商在很多场景下无法满足国内的 ...
- 数据分析侠A的成长故事
数据分析侠A的成长故事 面包君 同学A:22岁,男,大四准备实习,计算机专业,迷茫期 作为一个很普通的即将迈入职场的他来说,看到周边的同学都找了技术开发的岗位,顿觉自己很迷茫,因为自己不是那么喜欢钻 ...
随机推荐
- Jquery的常用使用方法
1.获取单个checkbox选中项(三种写法)$("input:checkbox:checked").val()或者$("input:[type='checkbox']: ...
- 在Vs code中使用sftp插件以及连接windows远程sftp协议部署指导(解决vscode的sftp插件中文目录乱码问题)
一.启动SFtp 二.上手vs code SFTP插件 2.1 初始配置 2.2解决乱码问题 三.SFTP配置 3.1常用配置 3.2示例配置 四.SFTP使用 五.扩展阅读 一.启动SFtp 话说小 ...
- [loj3301]魔法商店
令$A=\{a_{1},a_{2},...,a_{s}\}$,若$k\not\in A$,那么恰存在一个$A'\subseteq A$使得$c_{k}=\bigoplus_{x\in A'}c_{x} ...
- [bzoj1483]梦幻布丁
对于每一个颜色用一个链表存储,并记录下:1.当前某种颜色的真实颜色:2.这种颜色的数量(用于启发式合并的判断):3.当前答案(即有几段),然后对于每一个操作简单处理一下就行了. 1 #include& ...
- [luogu5616]恶魔之树
记录$lcm$的质因子状态(包括大于$\sqrt 300$的质因子),设$f[s]$表示质因子状态为$s$的$lcm$之和,转移枚举当前的数$k$,转移到$lcm(s,k)$即可,时间复杂度为$o(n ...
- [loj3367]装饼干
先考虑如何判定一个$y$是否可行--从高位开始,记录这一位所需要的$2^{i}$数量$t$,若$y$的这一位为1,则$t+=x$,之后分两类讨论:1.$t\le a_{i}$,令$t=0$:2.$b& ...
- Spring Cloud Gateway限流实战
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Linux终端使用aplay播放wav
Linux终端使用aplay播放wav aplay是一个ALSA的声卡命令行soundfile录音机的驱动程序. 在linux下可以使用下面命令来查看用法: man aplay 所以可以使用来播放.w ...
- [NOI2020] 超现实树
我们定义链树为:在该树上的任意节点,左右子树大小的最小值小于2. 举个例子: 那么我们思考,链树显然可以在叶子节点任意替换成其他子树. 那么在主链上,我们可以做到生成任意深度大于主链长度的树. 反过来 ...
- UOJ #129 / BZOJ 4197 / 洛谷 P2150 - [NOI2015]寿司晚宴 (状压dp+数论+容斥)
题面传送门 题意: 你有一个集合 \(S={2,3,\dots,n}\) 你要选择两个集合 \(A\) 和 \(B\),满足: \(A \subseteq S\),\(B \subseteq S\), ...