「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言
资源是影响 Spark 应用执行效率的一个重要因素。Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark 应用的 Executor 的数量。在运行过程中,无论 Executor上是否有 task 在执行,都会被一直占有直到此 Spark 应用结束。
上篇我们从动态优化的角度讲述了 Spark 3.0 版本中的自适应查询特性,它主要是在一条 SQL 执行过程中不断优化执行逻辑,选择更好的执行策略,从而达到提升性能的目的。本篇我们将从整个 Spark 集群资源的角度讨论一个常见痛点:资源不足。
在 Spark 集群中的一个常见场景是,随着业务的不断发展,需要运行的 Spark 应用数和数据量越来越大,靠资源堆砌的优化方式也越来越显得捉襟见肘。当一个长期运行的 Spark 应用,若分配给它多个 Executor,可是却没有任何 task 分配到这些 Executor 上,而此时有其他的 Spark 应用却资源紧张,这就造成了资源浪费和调度不合理。

要是每个 Spark 应用的 Executor 数也能动态调整那就太好了。
动态资源分配(Dynamic Resource Allocation)就是为了解决这种场景而产生。Spark 2.4 版本中 on Kubernetes 的动态资源并不完善,在 Spark 3.0 版本完善了 Spark on Kubernetes 的功能,其中就包括更灵敏的动态分配。我们 Erda 的 FDP 平台(Fast Data Platform)从 Spark 2.4 升级到 Spark 3.0,也尝试了动态资源分配的相关优化。本文将针对介绍 Spark 3.0 中 Spark on Kubernetes 的动态资源使用。
原理
一个 Spark 应用中如果有些 Stage 稍微数据倾斜,那就有大量的 Executor 是空闲状态,造成集群资源的极大浪费。通过动态资源分配策略,已经空闲的 Executor 如果超过了一定时间,就会被集群回收,并在之后的 Stage 需要时可再次请求 Executor。
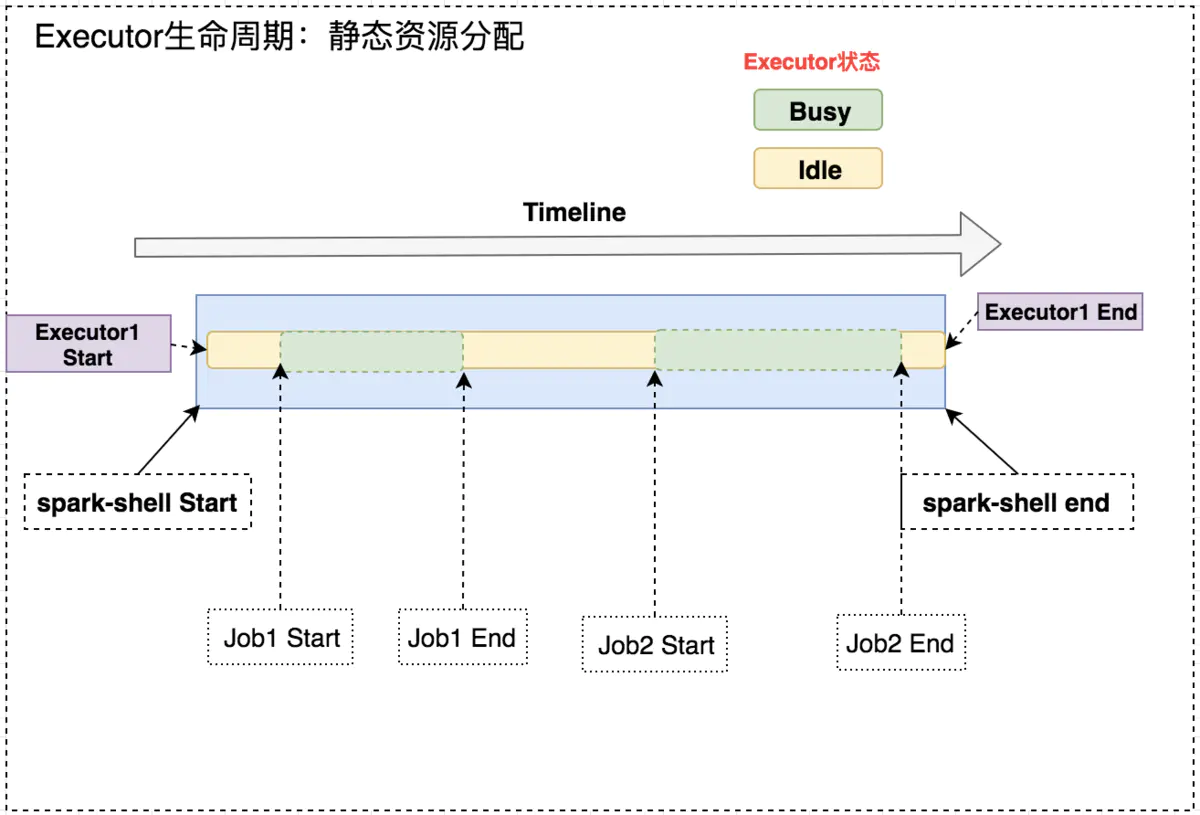
如下图所示,固定 Executor 个数情况,Job1 End 和 Job2 Start 之间,Executor 处于空闲状态,此时就造成集群资源的浪费。
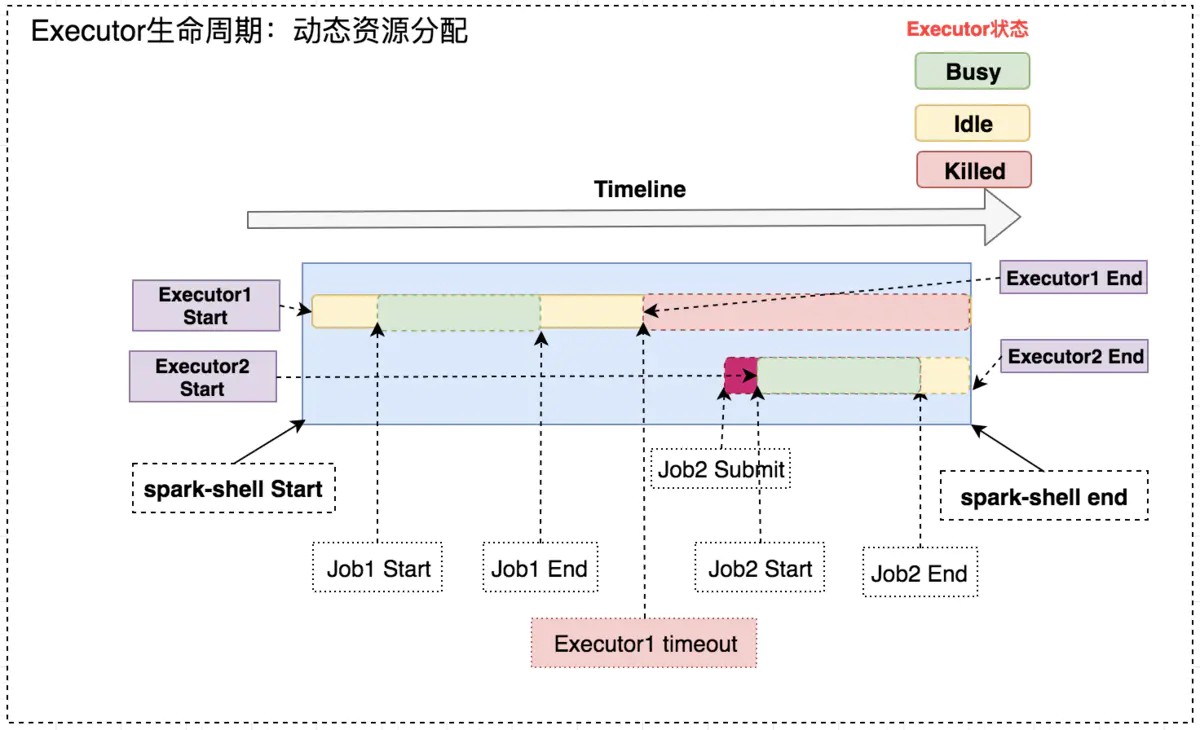
开启动态资源分配后,在 Job1 结束后,Executor1 空闲一段时间便被回收;在 Job2 需要资源时再申Executor2,实现集群资源的动态管理。
动态分配的原理很容易理解:“按需使用”。当然,一些细节还是需要考虑到:
- 何时新增/移除 Executor
- Executor 数量的动态调整范围
- Executor 的增减频率
- Spark on Kubernetes 场景下,Executor 的 Pod 销毁后,它存储的中间计算数据如何访问
这些注意点在下面的参数列表中都有相应的说明。
参数一览
spark.dynamicAllocation.enabled=true #总开关,是否开启动态资源配置,根据工作负载来衡量是否应该增加或减少executor,默认false
spark.dynamicAllocation.shuffleTracking.enabled=true #spark3新增,之前没有官方支持的on k8s的Dynamic Resouce Allocation。启用shuffle文件跟踪,此配置不会回收保存了shuffle数据的executor
spark.dynamicAllocation.shuffleTracking.timeout #启用shuffleTracking时控制保存shuffle数据的executor超时时间,默认使用GC垃圾回收控制释放。如果有时候GC不及时,配置此参数后,即使executor上存在shuffle数据,也会被回收。暂未配置
spark.dynamicAllocation.minExecutors=1 #动态分配最小executor个数,在启动时就申请好的,默认0
spark.dynamicAllocation.maxExecutors=10 #动态分配最大executor个数,默认infinity
spark.dynamicAllocation.initialExecutors=2 #动态分配初始executor个数默认值=spark.dynamicAllocation.minExecutors
spark.dynamicAllocation.executorIdleTimeout=60s #当某个executor空闲超过这个设定值,就会被kill,默认60s
spark.dynamicAllocation.cachedExecutorIdleTimeout=240s #当某个缓存数据的executor空闲时间超过这个设定值,就会被kill,默认infinity
spark.dynamicAllocation.schedulerBacklogTimeout=3s #任务队列非空,资源不够,申请executor的时间间隔,默认1s(第一次申请)
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout #同schedulerBacklogTimeout,是申请了新executor之后继续申请的间隔,默认=schedulerBacklogTimeout(第二次及之后)
spark.specution=true #开启推测执行,对长尾task,会在其他executor上启动相同task,先运行结束的作为结果
实战演示
无图无真相,下面我们将动态资源分配进行简单演示。
1.配置参数
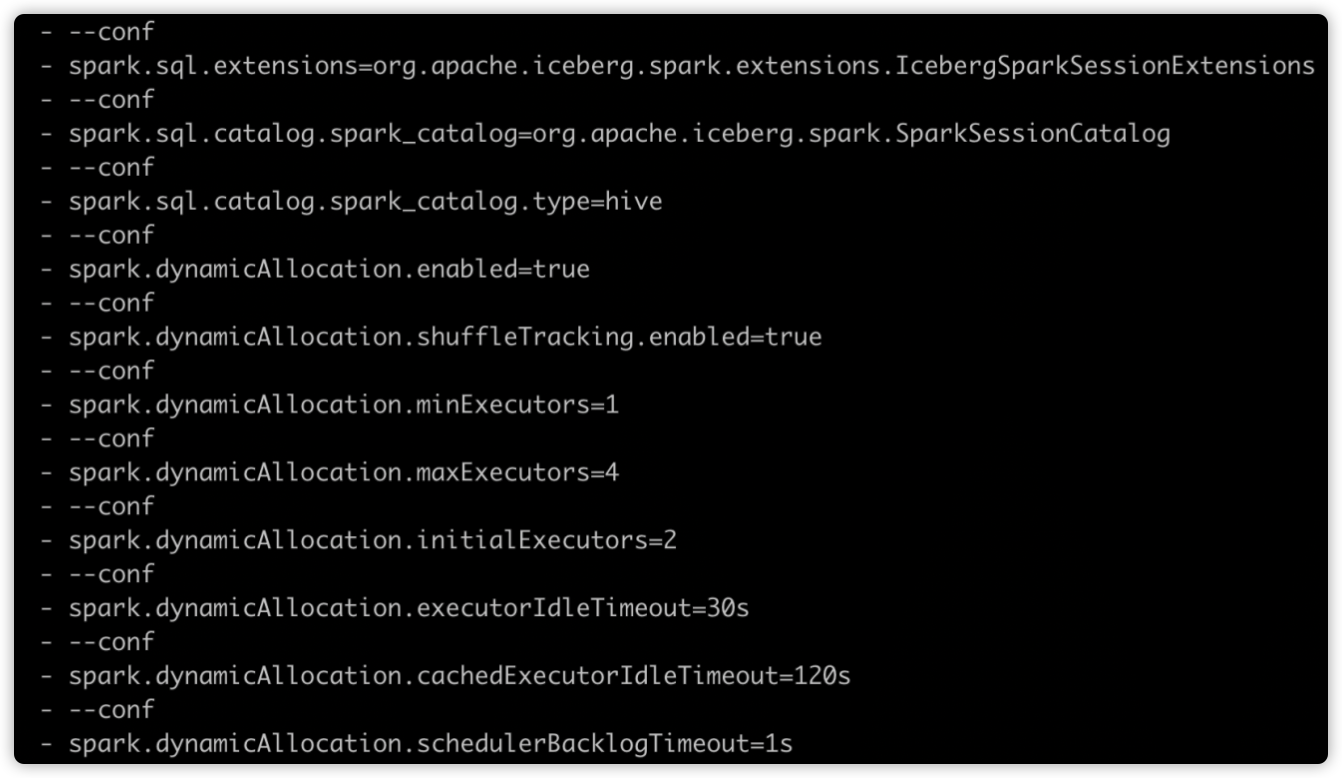
动态资源分配相关参数配置如下图所示:
如下图所示,Spark 应用启动时的 Executor 个数为 2。因为配置了
spark.dynamicAllocation.initialExecutors=2
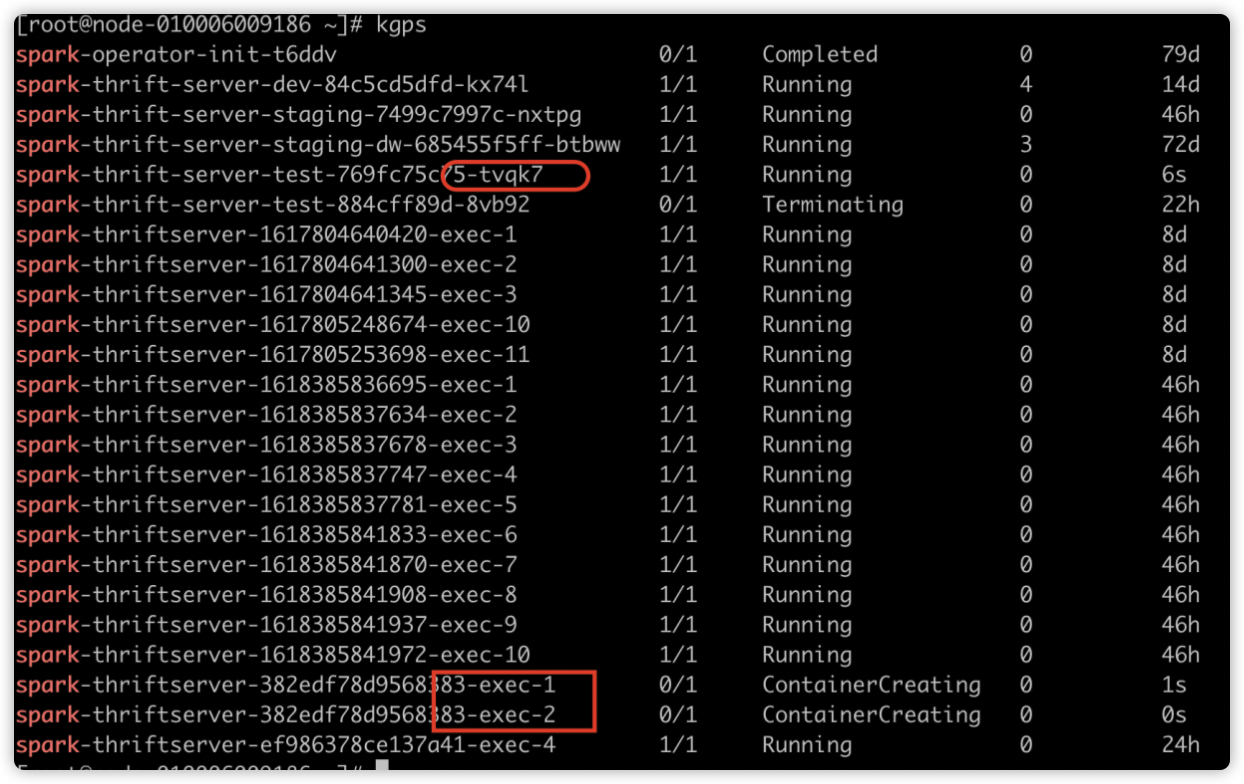
运行一段时间后效果如下,executorNum 会递增,因为空闲的 Executor 被不断回收,新的 Executor 不断申请。

2. 验证快慢 SQL 执行
使用 SparkThrfitServer 会遇到的问题是一个数据量很大的 SQL 把所有的资源全占了,导致后面的 SQL 都等待,即使后面的 SQL 只需要几秒就能完成。我们开启动态分配策略,再来看 SQL 执行顺序。
先提交慢 SQL:
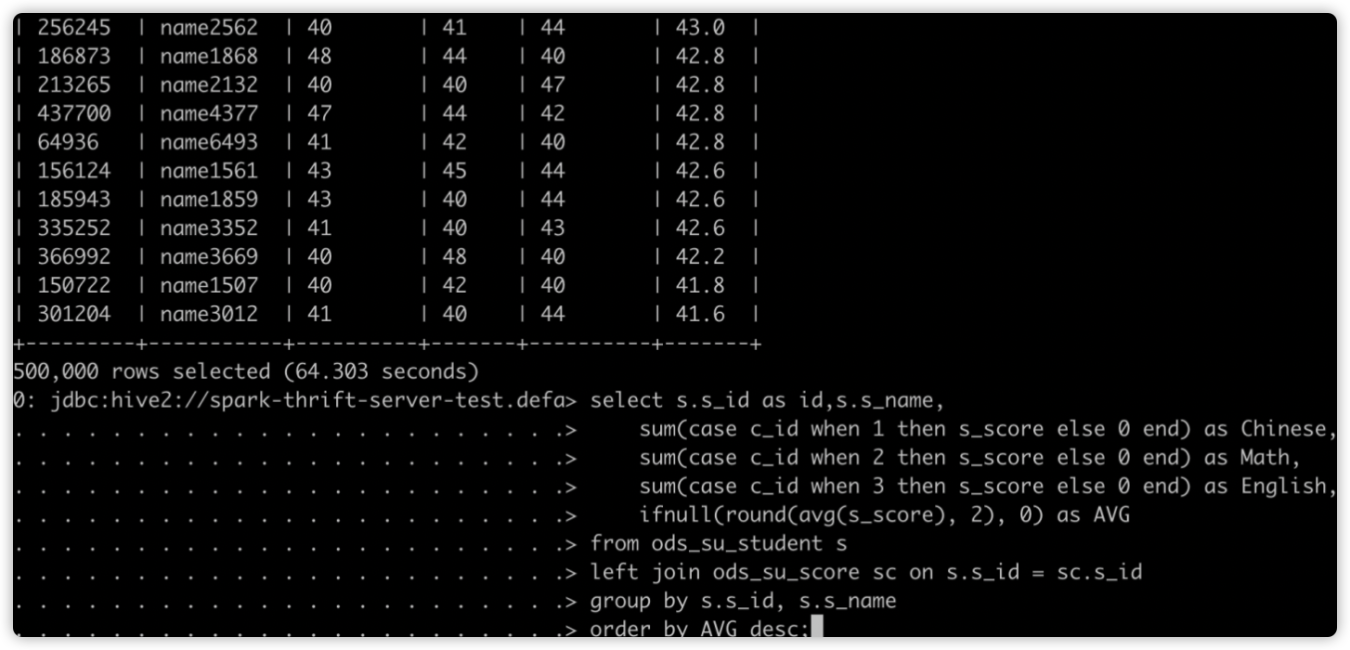
再提交快 SQL:
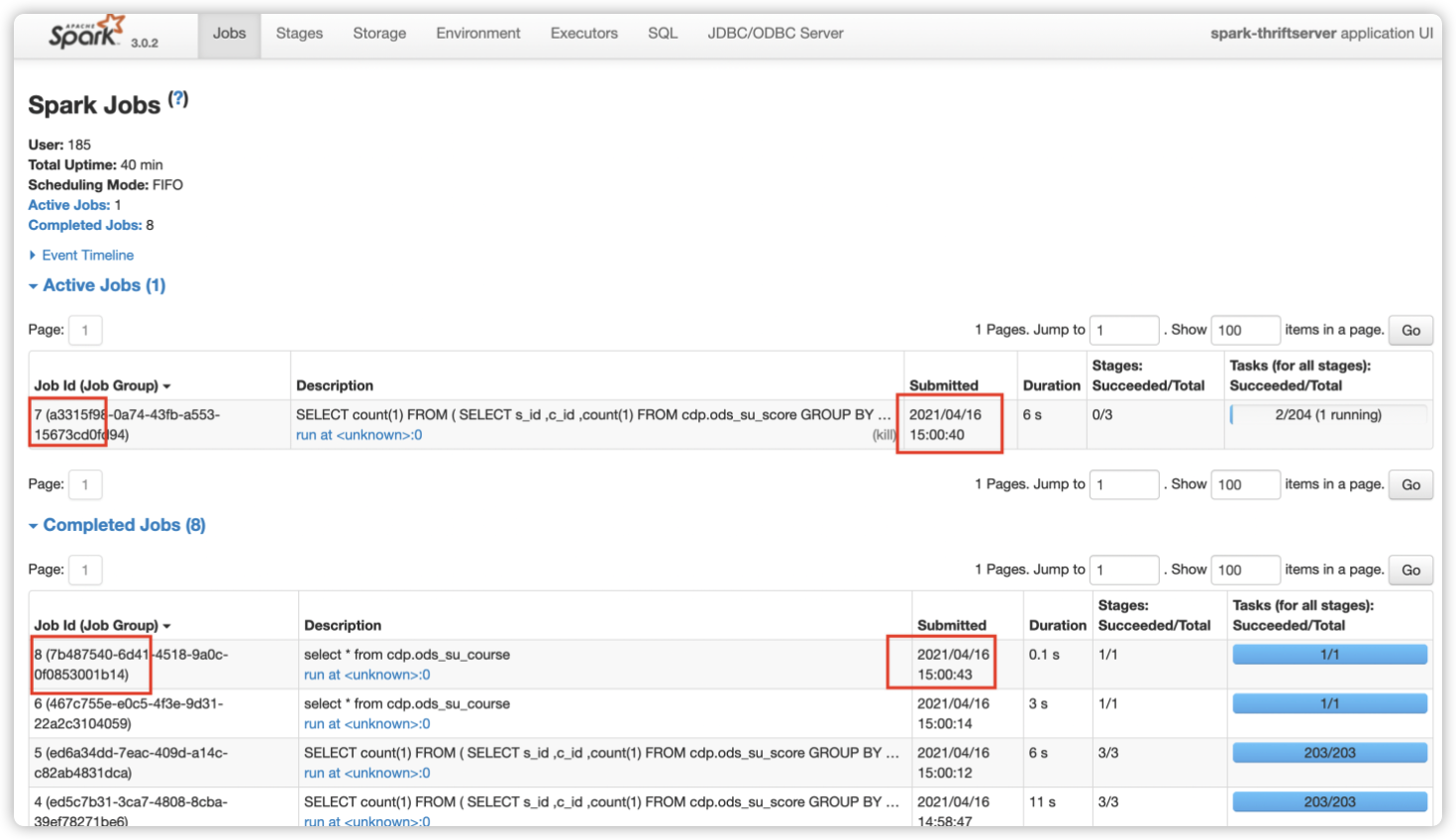
如下图所示,开启动态资源分配后,因为 SparkThrfitServer 可以申请新的 Executor,后面的 SQL 无需等待便可执行。Job7(慢 SQL)还在运行中,后提交的 Job8(快 SQL)已完成。这在一定程度上缓解了资源分配不合理的情况。
3. 详情查看
我们在 SparkWebUI 上可以看到动态分配的整个流程。
登陆 SparkWebUI 页面,Jobs -> Event Timeline,可以看到 Driver 对整个应用的 Executor 调度。如下图所示,显示了每个 Executor 的创建和回收。

同时也能看到此 Executor 的具体创建和回收时间。

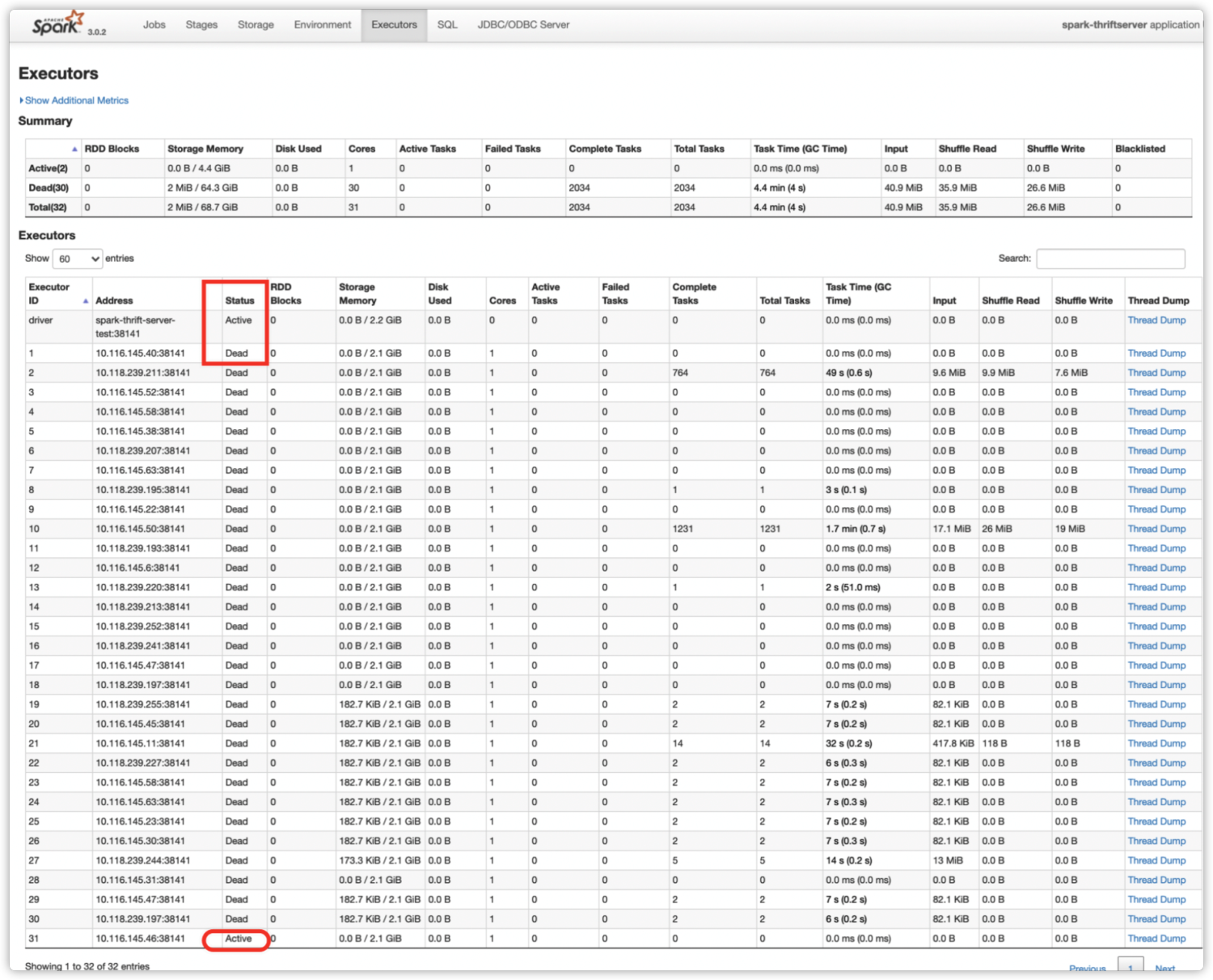
在 Executors 标签页,我们可以看到所有历史 Executor 的当前状态。如下图所示,之前的 Executor 都已被回收,只有 Executor-31 状态为 Active。
总结
动态资源分配策略在空闲时释放 Executor,繁忙时申请 Executor,虽然逻辑比较简单,但是和任务调度密切相关。它可以防止小数据申请大资源,Executor 空转的情况。在集群资源紧张,有多个 Spark 应用的场景下,可以开启动态分配达到资源按需使用的效果。
以上是我们在 Spark 相关优化的一点经验,希望能够对大家有所帮助。
注:文中部分图片源自于网络,侵删。
更多技术干货请关注【尔达 Erda】公众号,与众多开源爱好者共同成长~
「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配的更多相关文章
- 「Spark从精通到重新入门(一)」Spark 中不可不知的动态优化
前言 Apache Spark 自 2010 年面世,到现在已经发展为大数据批计算的首选引擎.而在 2020 年 6 月份发布的Spark 3.0 版本也是 Spark 有史以来最大的 Release ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- Spark学习之路(十二)—— Spark SQL JOIN操作
一. 数据准备 本文主要介绍Spark SQL的多表连接,需要预先准备测试数据.分别创建员工和部门的Datafame,并注册为临时视图,代码如下: val spark = SparkSession.b ...
- [Maven实战-许晓斌]-[第三章] Mave使用入门二(在IDE中的使用) [第四章] 案例的背景介绍
创建maven项目
- 利用动态资源分配优化Spark应用资源利用率
背景 在某地市开展项目的时候,发现数据采集,数据探索,预处理,数据统计,训练预测都需要很多资源,现场资源不够用. 目前该项目的资源3台旧的服务器,每台的资源 内存为128G,cores 为24 (co ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- Spark RDD/Core 编程 API入门系列之简单移动互联网数据(五)
通过对移动互联网数据的分析,了解移动终端在互联网上的行为以及各个应用在互联网上的发展情况等信息. 具体包括对不同的应用使用情况的统计.移动互联网上的日常活跃用户(DAU)和月活跃用户(MAU)的统计, ...
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- 【原创】NIO框架入门(二):服务端基于MINA2的UDP双向通信Demo演示
前言 NIO框架的流行,使得开发大并发.高性能的互联网服务端成为可能.这其中最流行的无非就是MINA和Netty了,MINA目前的主要版本是MINA2.而Netty的主要版本是Netty3和Netty ...
随机推荐
- [bzoj1068]压缩
用f[i][j][0/1]表示区间[i,j],i之前有没有M的最少需要多少个字符,然后分两种情况:1.可以分为两个,转移到dp[l][mid][0]+1:2.枚举断点,但当前面有M时,后面的这个不能重 ...
- [bzoj1415]聪聪与可可
直接求出任意两点的距离后记忆化搜索,用f[i][j]表示聪聪在i,可可在j的期望步数,由于i和j的最短路单调递减,所以搜不到环 1 #include<bits/stdc++.h> 2 us ...
- [cf1421E]Swedish Heroes
令$p_{i}$为最终$a_{i}$之前的系数($p_{i}\in \{-1,1\}$),则有$n+\sum_{i=1}^{n}[p_{i}=-1]\equiv 1(mod\ 3)$ 证明:对于两个满 ...
- NLP 开源形近字算法补完计划(完结篇)
前言 所有的故事都有开始,也终将结束. 本文将作为 NLP 汉字相似度的完结篇,为该系列画上一个句号. 起-NLP 中文形近字相似度计算思路 承-中文形近字相似度算法实现,为汉字 NLP 尽一点绵薄之 ...
- 【Redis】(1)-- 关系型数据库与非关系型数据库
关系型数据库与非关系型数据库 2019-07-02 16:34:48 by冲冲 1. 关系型数据库 1.1 概念 关系型数据库,是指采用了关系模型来组织数据的数据库.关系模型指的就是二维表格模型, ...
- Linux远程软件
Xhell6:Linux的终端模拟软件 1>安装并破解:解压.破解(运行两个.bat文件).启动(点击Xshell.exe文件) 2>连接远端Linux系统: 创建会话:点击连接,在常规框 ...
- CF1493E Enormous XOR
题目传送门. 题意简述:给出长度为 \(n\) 的二进制数 \(l,r\),求 \(\max_{l\leq x\leq y\leq r}\oplus_{i=x}^yi\). 非常搞笑的题目,感觉难度远 ...
- 【Pathview web】通路映射可视化
前言 pathview是一个通路可视化友好的R包,最主要的是它支持多组学数据映射(基因/蛋白-代谢).自己用过它的R包,后来发现有网页版的,果断介绍给学员.因为不常用,记录要点,以后温习备用. 目前w ...
- 【NCBI教程】资源汇总整理 (转载)
主题 网址 备注 [NCBI教程]资源汇总整理 http://www.omicshare.com/forum/thread-200-1-1.html (出处: OmicShare Forum)
- memset初始化值的效率秒杀for循环
<span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255) ...