第46篇-signature_handler与result_handler
在之前介绍为native方法设置解释执行的入口时介绍过,当Method::native_function为空时会调用InterpreterRuntime::prepare_native_call()函数,这个函数不但会查找本地函数,而且还会确保Method::signature_handler也完成了设置。这一篇将详细介绍signature_handler的查找设置过程。
1、signature_handler
Method实例的第2个附加slot的signature_handler指向的例程用来消除Java解释器栈和C/C++栈调用约定的不同,将位于解析器栈中的参数适配到本地函数使用的C栈。
在调用本地函数时,要确保signature handler被安装,之前介绍过,如果signature_handler没有安装,那么InterpreterRuntime::prepare_native_call()函数通过调用SignatureHandlerLibrary::add()函数来安装。add()函数的实现如下:
源代码位置:openjdk/hotspot/src/share/vm/interpreter/interpreterRuntime.cpp
// 根据方法签名解析方法参数的解析器,当方法参数大小小于Fingerprinter::max_size_of_parameters
// 时可以生成并使用根据方法签名定制的快速的解析器,否则使用通用的相对较慢的解析器。
void SignatureHandlerLibrary::add(methodHandle method) {
// 只有在signature_handler的值为NULL时才会执行如下逻辑,否则不做任何操作
if (method->signature_handler() == NULL) {
int handler_index = -1;
// UseFastSignatureHandlers的值默认为true
// Fingerprinter::max_size_of_parameters的值为13,也就是13个slot
if (UseFastSignatureHandlers && method->size_of_parameters() <= Fingerprinter::max_size_of_parameters) {
MutexLocker mu(SignatureHandlerLibrary_lock);
// 确保使用到的相关变量都已经初始化完成
initialize();
// lookup method signature's fingerprint
// 读出Method::_constMethod::_fingerprinter的值,也就是
// 根据方法签名得到对应的指纹值,然后在_fingerprints数组中查找到
// 句柄下标索引,由于句柄存储在_handlers数组中,所以可以根据这个下标
// 索引从_handlers数组中获取
uint64_t fingerprint = Fingerprinter(method).fingerprint();
handler_index = _fingerprints->find(fingerprint);
// 如果handler_index小于0,则说明没有这个方法签名对应的signature_handler,需要创建一个新的
// signature_handler
if (handler_index < 0) {
ResourceMark rm;
ptrdiff_t align_offset = (address)round_to((intptr_t)_buffer, CodeEntryAlignment) - (address)_buffer; CodeBuffer buffer(
(address)(_buffer + align_offset),
SignatureHandlerLibrary::buffer_size - align_offset
);
// 生成signature_handler,其实就是生成一段例程,这段例程可消除Java解释器栈
// 和C/C++栈调用约定的不同,将位于解析器栈中的参数适配到本地函数使用的C栈
InterpreterRuntime::SignatureHandlerGenerator tmp = InterpreterRuntime::SignatureHandlerGenerator(method, &buffer);
tmp.generate(fingerprint);
// signature_handler对应的例程临时保存在了CodeBuffer中,调用set_handler保存到BufferBlob中,
// 这个BufferBlob中的内存是从CodeCache中分配出来的,解释执行所需要的所有例程基本都保存在CodeCache中
address handler = set_handler(&buffer);
if (handler == NULL) {
// 使用普通的、相对较慢的解释器
} else {
// 向_fingerprints和_handlers数组中添加方法签名和signature_handler,这样下次就可以
// 根据方法签名快速定位对应的signature_handler
_fingerprints->append(fingerprint);
_handlers->append(handler);
handler_index = _fingerprints->length() - 1;
}
} // 结束 if (handler_index < 0) if (handler_index < 0) {
// 使用通用的相对较慢的解析器
address tmp = Interpreter::slow_signature_handler();
method->set_signature_handler(tmp);
} else {
// 使用快速的解析器
address tmp = _handlers->at(handler_index);
method->set_signature_handler(tmp);
}
} else {
// 没有快速的解释器,只能使用相对较慢的普通解释器
method->set_signature_handler(Interpreter::slow_signature_handler());
}
} }
对于参数不超过13个slot大小(int、byte、对象地址等占用一个slot,而double和long占用2个slot)的native方法来说,signature_handler会走快速路径。就是根据方法签名字符串得到一个64位的整数方法指纹(Method Fingerprint)值,后续signature_handler将不需要每次都解析native方法签名字符串得到参数个数和参数类型,而是直接用方法指纹值。这个方法指纹值的格式如下图所示。

每个方法指纹值都会存储在元素类型为uint64_t的数组中,所以方法指纹值不能超过64位大小,另外加上还需要存储结果类型、是否为静态方法等信息,所以能表示方法参数类型的参数存储区只有52位大小,所以才会要求方法参数大小不超过13个slot的大小(每个参数的类型存储需要占用4位)。
在SignatureHandlerLibrary::add()函数中使用了_fingerprints和_handlers来保存方法指纹值,这两个变量是静态的,所以说,如果两个方法的指纹值相同,则可以重用快速解释器。
在之前介绍过为native方法生成解释执行的入口时,会在Method::native_funciton执行之前调用Method::signature_handler,而在调用Method::signature_handler之前会根据方法要求的参数大小从native栈帧中开辟对应的存储空间,栈的状态如下图所示。
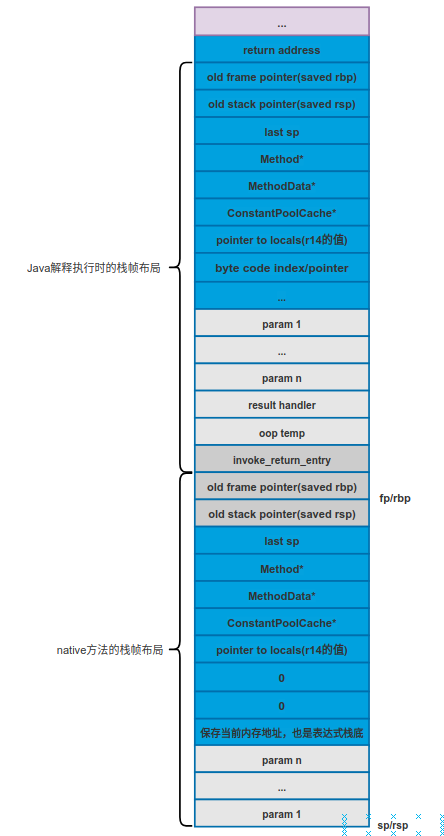
其中最下面的param n ... param 1中会压入调用C/C++实现的本地函数需要的参数,不过Java方法的解释执行需要将参数从左向右入栈,所以我们能够看到上图中方法的局部变量表中实参的顺序为param 1... param n,但是本地函数根据调用约定,其参数需要从右到左入栈,这就要求最后一个参数最先入栈(注意,C/C++函数只有在参数过多的情况下才会借助栈来传递参数)。
(1)快速解释器
调用InterpreterRuntime::SignatureHandlerGenerator::generate()函数生成快速解释器,函数的实现如下:
void InterpreterRuntime::SignatureHandlerGenerator::generate(uint64_t fingerprint) {
// 处理参数
iterate(fingerprint);
// 查找并返回result_handler
BasicType bt = method()->result_type();
address adr = Interpreter::result_handler(bt);
__ lea(rax, ExternalAddress(adr));
__ ret(0);
__ flush();
}
这个函数在生成signature_handler时还会生成result_handler,这个result_handler会处理本地函数调用后的返回值,之前在介绍为native方法设置解释执行的入口时介绍过,result_handler对native_function执行的结果进行处理的具体逻辑。
处理参数iterate()函数的实现如下:
void iterate( uint64_t fingerprint ) {
if (!is_static()) {
// 当为实例方法时,需要传递receiver,也就是this参数
pass_object();
_jni_offset++;
_offset++;
}
// fingerprint中包含有函数调用参数及返回类型等相关信息
SignatureIterator::iterate_parameters( fingerprint );
}
调用pass_object()函数为本地函数传递this参数。调用SignatureIterator::iterate_parameters()函数根据Java方法签名向C/C++函数传递参数。调用的SignatureIterator::iterate_parameters()函数的实现如下:
void SignatureIterator::iterate_parameters( uint64_t fingerprint ) {
uint64_t saved_fingerprint = fingerprint;
// 当传递的参数太多时就无法使用方法指纹值来快速处理,只能通过遍历Java方法签名来处理
if ( fingerprint == UCONST64(-1) ) { // 检查处理参数太多的情况
SignatureIterator::iterate_parameters();
return;
}
_parameter_index = 0;
// static_feature_size + result_feature_size的值为5
fingerprint = fingerprint >> (static_feature_size + result_feature_size);
while ( 1 ) {
switch ( fingerprint & parameter_feature_mask ) {
case bool_parm:
do_bool();
_parameter_index += T_BOOLEAN_size;
break;
case byte_parm:
do_byte();
_parameter_index += T_BYTE_size;
break;
case char_parm:
do_char();
_parameter_index += T_CHAR_size;
break;
case short_parm:
do_short();
_parameter_index += T_SHORT_size;
break;
case int_parm:
do_int();
_parameter_index += T_INT_size;
break;
case obj_parm:
do_object(0, 0);
_parameter_index += T_OBJECT_size;
break;
case long_parm:
do_long();
_parameter_index += T_LONG_size;
break;
case float_parm:
do_float();
_parameter_index += T_FLOAT_size;
break;
case double_parm:
do_double();
_parameter_index += T_DOUBLE_size;
break;
case done_parm:
return;
break;
default:
ShouldNotReachHere();
break;
}
// parameter_feature_size的值为4
fingerprint >>= parameter_feature_size;
}
_parameter_index = 0;
}
调用的do_float()、do_object()等函数的实现如下:
void do_bool () { pass_int(); _jni_offset++; _offset++; }
void do_char () { pass_int(); _jni_offset++; _offset++; }
void do_float () { pass_float(); _jni_offset++; _offset++; }
void do_double() { pass_double(); _jni_offset++; _offset += 2; }
void do_byte () { pass_int(); _jni_offset++; _offset++; }
void do_short () { pass_int(); _jni_offset++; _offset++; }
void do_int () { pass_int(); _jni_offset++; _offset++; }
void do_long () { pass_long(); _jni_offset++; _offset += 2; }
void do_object(int begin, int end) { pass_object(); _jni_offset++; _offset++; }
void do_array (int begin, int end) { pass_object(); _jni_offset++; _offset++; }
其中的_jni_offset表示参数对于本地函数的偏移量,而_offset表示参数对于Java方法的偏移量。对于Java方法来说,一个long或double会占用2个slot,而在64位下,本地函数只需要一个slot即可。另外,如果是静态方法,由于有JNIEnv*和jclass,对于实例方法有JNIEnv*,所以_jni_offset还需要加上2或1。
调用的pass_int()、pass_double()和pass_object()等函数的实现如下:
void InterpreterRuntime::SignatureHandlerGenerator::pass_int() {
const Address src(from(), Interpreter::local_offset_in_bytes(offset()));
switch (_num_int_args) { // 当为静态方法时,_num_int_args的值为1,否则为0
case 0:
__ movl(c_rarg1, src);
_num_int_args++;
break;
case 1:
__ movl(c_rarg2, src);
_num_int_args++;
break;
case 2:
__ movl(c_rarg3, src);
_num_int_args++;
break;
case 3:
__ movl(c_rarg4, src);
_num_int_args++;
break;
case 4:
__ movl(c_rarg5, src);
_num_int_args++;
break;
default: // 当传递的整数类型参数多于5个时,多出来的只能通过栈来传递
__ movl(rax, src);
__ movl(Address(to(), _stack_offset), rax); // 调用to()函数返回rsp
_stack_offset += wordSize;
break;
}
}
void InterpreterRuntime::SignatureHandlerGenerator::pass_double() {
const Address src(from(), Interpreter::local_offset_in_bytes(offset() + 1));
if (_num_fp_args < Argument::n_float_register_parameters_c) {
__ movdbl(as_XMMRegister(_num_fp_args++), src);
} else {
__ movptr(rax, src);
__ movptr(Address(to(), _stack_offset), rax);
_stack_offset += wordSize;
}
}
// 在传递对象地址时,只需要使用整数类型的slot存储地址即可
void InterpreterRuntime::SignatureHandlerGenerator::pass_object() {
const Address src(from(), Interpreter::local_offset_in_bytes(offset()));
switch (_num_int_args) {
case 0:
assert(offset() == 0, "argument register 1 can only be (non-null) receiver");
__ lea(c_rarg1, src);
_num_int_args++;
break;
case 1:
__ lea(rax, src);
__ xorl(c_rarg2, c_rarg2);
__ cmpptr(src, 0);
__ cmov(Assembler::notEqual, c_rarg2, rax);
_num_int_args++;
break;
case 2:
__ lea(rax, src);
__ xorl(c_rarg3, c_rarg3);
__ cmpptr(src, 0);
__ cmov(Assembler::notEqual, c_rarg3, rax);
_num_int_args++;
break;
case 3:
__ lea(rax, src);
__ xorl(c_rarg4, c_rarg4);
__ cmpptr(src, 0);
__ cmov(Assembler::notEqual, c_rarg4, rax);
_num_int_args++;
break;
case 4:
__ lea(rax, src);
__ xorl(c_rarg5, c_rarg5);
__ cmpptr(src, 0);
__ cmov(Assembler::notEqual, c_rarg5, rax);
_num_int_args++;
break;
default:
__ lea(rax, src);
__ xorl(temp(), temp());
__ cmpptr(src, 0);
// 如果传递的对象地址不为0,则将rax中的值存储到temp()中
__ cmov(Assembler::notEqual, temp(), rax);
// 将temp()中的值存储到栈帧中
__ movptr(Address(to(), _stack_offset), temp());
_stack_offset += wordSize;
break;
}
}
我们需要注意,因为要调用的本地函数是C/C++函数,所以需要遵守C/C++函数的调用约定,如果是整数或对象地址,则可以放到6个整数类型的寄存器中。静态方法的JNI*和jclass参数需要通过c_rarg0和c_rarg1来传递,所以native方法的参数中的非浮点数类型只能使用c_rarg2、c_rarg3、c_rarg4和c_rarg5这几个寄存器;如果是实例方法,则c_rarg0需要传递JNI*,然后就是c_rarg1传递receiver。当整数或对象多于6个时,要将剩下的参数从右向左压入栈内。
下面看2个具体的小实例。
为java.lang.Object.registerNatives()方法生成的signature_handler与result_handler的汇编代码如下:(为HotSpot VM添加选项 -XX:+PrintSignatureHandlers)
argument handler #0 for: static java.lang.Object.registerNatives()V (fingerprint = 349, 11 bytes generated)
// 根据方法的返回类型获取到对应的result_handler例程的地址并保存到%rax中
// movabs的源操作数只能是立即数或标号(本质还是立即数),目的操作数是寄存器
0x00007f386911c420: movabs $0x7f386900ecd8,%rax
0x00007f386911c42a: retq --- associated result handler ---
// 由于registerNatives()方法不需要任何返回值,所以没有任何执行逻辑
// ret指令用于从子函数中返回。X86架构的Linux中是将函数的返回值设置到eax寄
// 存器并返回的,设置的工作不是由ret来做,要自己做
0x00007f386900ecd8: retq
由于registerNatives()方法没有任何参数,所以不需要对参数进行处理。至于JNIEnv*和jclass参数,在之前介绍为native方法设置解释执行入口时详细介绍过。
再举个例子,如下:
private native void writeBytes(byte b[], int off, int len, boolean append) throws IOException;
生成的汇编如下:
argument handler #56 for: receiver java.io.FileOutputStream.writeBytes([BIIZ)V (fingerprint = 21146428, 44 bytes generated)
// Java方法的第1个参数this是本地方法的第2个参数,所以要根据调用约定存储在%rsi中
0x00007fbfe4067a5a: lea (%r14),%rsi
// 将Java方法的第2个参数b存储到%rax中
0x00007fbfe4067a5d: lea -0x8(%r14),%rax
0x00007fbfe4067a61: xor %edx,%edx // 清空%edx
// cmp是比较指令,cmp的功能相当于减法指令,只是不保存结果
0x00007fbfe4067a63: cmpq $0x0,-0x8(%r14)
// cmovne不相等时(也就是-0x8(%r14)中的值不为0时),将%rax中的值移动到%rdx中,
// 也就是Java方法的第2个参数b是本地方法的第3个参数,根据调用约定存储在%rdx中
0x00007fbfe4067a6b: cmovne %rax,%rdx // 传递Java方法的off参数
0x00007fbfe4067a6f: mov -0x10(%r14),%ecx
// 传递Java方法的len参数
0x00007fbfe4067a73: mov -0x18(%r14),%r8d
// 传递Java访求的append参数
0x00007fbfe4067a77: mov -0x20(%r14),%r9d 0x00007fbfe4067a7b: movabs $0x7fbfe3f59cd8,%rax
0x00007fbfe4067a85: retq --- associated result handler ---
// 当类型为int、long、void、float与double时,只执行retq
// 即可,详见下面的result handler
0x00007fbfe3f59cd8: retq
如上函数的参数不多于6个,所以正好能使用6个整数寄存器来传参。
C/C++中的参数放入的顺序如下:
- 第一个参数:%rdi c_rarg0
- 第二个参数:%rsi c_rarg1
- 第三个参数:%rdx c_rarg2
- 第四个参数:%rcx c_rarg3
- 第五个参数:%r8 c_rarg4
- 第六个参数:%r9 c_rarg5
第1个参数为JNIEnv*,这在之前介绍为native方法设置解释执行的入口时介绍过,从JavaThread::jni_environment中获取JNIEnv实例的地址并保存到%rdi中。
(2)普通的解释器
将普通的解释器生成的例程保存到AbstractInterpreter::_slow_signature_handler中,所以在SignatureHandlerLibrary::add()函数中可直接能这个字段中获取例程地址。在HotSpot VM启动时会调用如下函数:
void AbstractInterpreterGenerator::generate_all() {
{
CodeletMark cm(_masm, "slow signature handler");
Interpreter::_slow_signature_handler = generate_slow_signature_handler();
}
}
调用AbstractInterpreterGenerator::generate_slow_signature_handler()函数生成的汇编代码如下:
// rbx: method
// r14: pointer to locals // %rcx指向了栈顶,其中的栈顶值是第1个需要通过栈来给本地函数传递的参数
0x00007fffe1005400: mov %rsp,%rcx // 为调用准备c_rarg3
// 0x70=14*wordSize,其中wordSize=8,这里又从native栈帧上开辟了
// 14个slot,其中8个用来存储浮点数,5个用来存储整数,1个用来指示8个slot
// 中,哪些存储了需要传递的方法参数,也就是需要传递给本地函数的浮点数
0x00007fffe1005403: sub $0x70,%rsp // 调用call_VM()函数生成的例程,这个例程调用InterpreterRuntime::slow_signature_handler()函数
0x00007fffe1005407: callq 0x00007fffe1005411
0x00007fffe100540c: jmpq 0x00007fffe1005492
0x00007fffe1005411: mov %r14,%rdx // 为调用准备参数c_rarg2
0x00007fffe1005414: mov %rbx,%rsi // 为调用准备参数c_rarg1
0x00007fffe1005417: lea 0x8(%rsp),%rax
0x00007fffe100541c: mov %r13,-0x38(%rbp)
0x00007fffe1005420: mov %r15,%rdi // 为调用准备参数c_rarg0 // 相关信息保存到线程中
0x00007fffe1005423: mov %rbp,0x200(%r15)
0x00007fffe100542a: mov %rax,0x1f0(%r15) // 如下汇编对函数进行调用,如果内存没有对齐,则需要对齐处理后调用
0x00007fffe1005431: test $0xf,%esp
0x00007fffe1005437: je 0x00007fffe100544f
0x00007fffe100543d: sub $0x8,%rsp
0x00007fffe1005441: callq 0x00007ffff66aeed2
0x00007fffe1005446: add $0x8,%rsp
0x00007fffe100544a: jmpq 0x00007fffe1005454 0x00007fffe100544f: callq 0x00007ffff66aeed2 // 将线程中保存的相关信息重置
0x00007fffe1005454: movabs $0x0,%r10
0x00007fffe100545e: mov %r10,0x1f0(%r15)
0x00007fffe1005465: movabs $0x0,%r10
0x00007fffe100546f: mov %r10,0x200(%r15) 0x00007fffe1005476: cmpq $0x0,0x8(%r15)
0x00007fffe100547e: je 0x00007fffe1005489
0x00007fffe1005484: jmpq 0x00007fffe1000420
0x00007fffe1005489: mov -0x38(%rbp),%r13
0x00007fffe100548d: mov -0x30(%rbp),%r14
0x00007fffe1005491: retq
// 结束call_VM()函数的调用 // rax: result handler // Do FP first so we can use c_rarg3 as temp
// 0x28等于5*wordSize
0x00007fffe1005492: mov 0x28(%rsp),%ecx // float/double identifiers
在执行InterpreterRuntime::slow_signature_handler()函数之前的栈状态如下图所示。
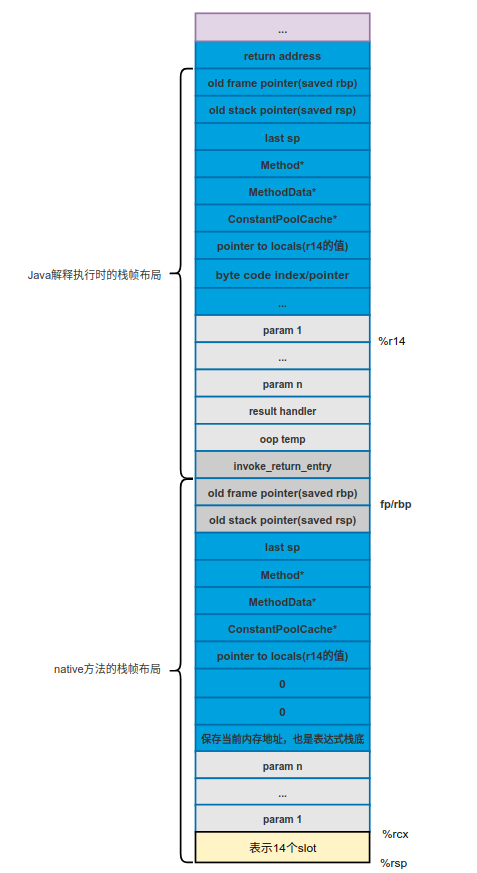
调用的InterpreterRuntime::slow_signature_handler()函数的实现如下:
IRT_ENTRY(address,InterpreterRuntime::slow_signature_handler(
JavaThread* thread,
Method* method,
intptr_t* from,
intptr_t* to
))
methodHandle m(thread, (Method*)method); // 处理方法参数
SlowSignatureHandler(m, (address)from, to + 1).iterate(UCONST64(-1)); // 返回result_handler
return Interpreter::result_handler(m->result_type());
IRT_END
其中from与to分别为
r14: pointer to locals
%rcx/c_rarg3: first stack arg - wordSize
调用的SlowSignatureHandler的构造函数如下:
SlowSignatureHandler(methodHandle method, address from, intptr_t* to) : NativeSignatureIterator(method) {
_from = from;
_to = to;
_int_args = to - (method->is_static() ? 14 : 15);
_fp_args = to - 9;
_fp_identifiers = to - 10;
*(int*) _fp_identifiers = 0;
_num_int_args = (method->is_static() ? 1 : 0);
_num_fp_args = 0;
}
NativeSignatureIterator(methodHandle method) : SignatureIterator(method->signature()) {
_method = method;
_offset = 0;
_jni_offset = 0;
const int JNIEnv_words = 1;
const int mirror_words = 1;
// 如果为静态方法,则_prepended的值为2(JNI和mirror),否则值为1(JNI)
_prepended = !is_static() ? JNIEnv_words : JNIEnv_words + mirror_words;
}
SignatureIterator::SignatureIterator(Symbol* signature) {
_signature = signature;
_parameter_index = 0;
}
SignatureIterator类的继承体系如下:
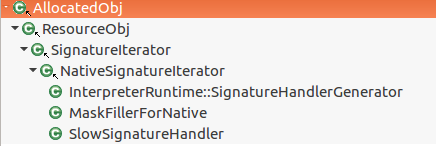
之前在介绍快速解释器时使用的是InterpreterRuntime::SignatureHandlerGenerator,而慢速解释器使用的是SlowSignatureHandler。
初始化好各个变量后就能在InterpreterRuntime::slow_signature_handler()函数中调用iterate()函数,然后在iterate()函数中调用SignatureIterator::iterate_parameters()函数,调用的pass_int()、pass_double()和pass_object()等函数是SlowSignatureHandler类中定义的系列函数,实现如下:
virtual void pass_int(){
jint from_obj = *(jint *)(_from+Interpreter::local_offset_in_bytes(0));
_from -= Interpreter::stackElementSize;
if (_num_int_args < Argument::n_int_register_parameters_c-1) {
*_int_args++ = from_obj;
_num_int_args++;
} else {
*_to++ = from_obj;
}
}
virtual void pass_long(){
intptr_t from_obj = *(intptr_t*)(_from+Interpreter::local_offset_in_bytes(1));
_from -= 2*Interpreter::stackElementSize;
// n_int_register_parameters_c的值为6
if (_num_int_args < Argument::n_int_register_parameters_c-1) {
*_int_args++ = from_obj;
_num_int_args++;
} else {
*_to++ = from_obj;
}
}
virtual void pass_object(){
intptr_t *from_addr = (intptr_t*)(_from + Interpreter::local_offset_in_bytes(0));
_from -= Interpreter::stackElementSize;
// n_int_register_parameters_c的值为6
if (_num_int_args < Argument::n_int_register_parameters_c-1) {
*_int_args++ = (*from_addr == 0) ? NULL : (intptr_t)from_addr;
_num_int_args++;
} else {
*_to++ = (*from_addr == 0) ? NULL : (intptr_t) from_addr;
}
}
通过如上函数的实现我们能看到,将需要通过寄存器传递的参数暂时存储到native方法的栈中,过多的参数也会存储到栈中。如下图所示。
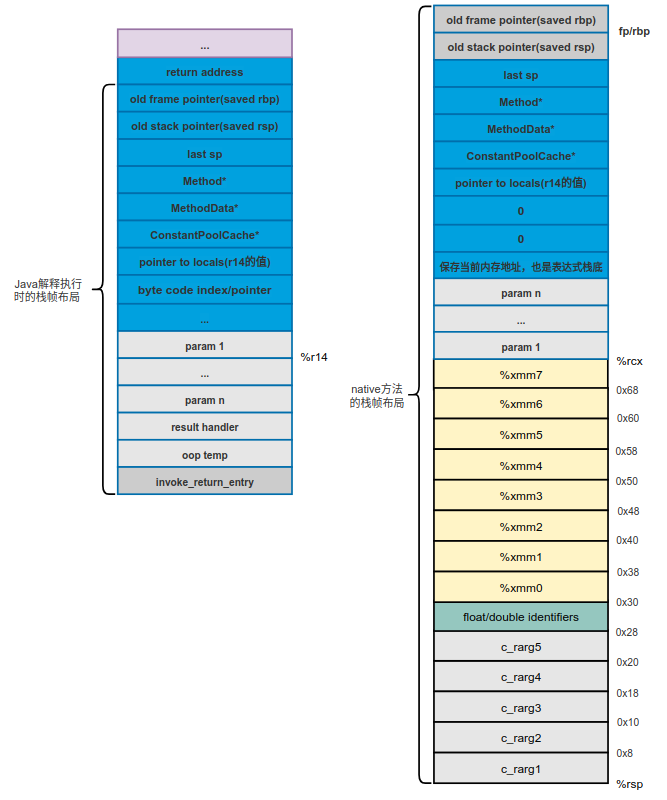
我们暂时将需要通过寄存器传递的参数保存到新开辟过的14个slot中,而需要通过栈传递的参数放到param n ... param 1区域中即可。然后我们接着看AbstractInterpreterGenerator::generate_slow_signature_handler()函数中生成的汇编代码的逻辑,如下:
// (6 + 0) * wordSize
0x00007fffe1005496: test $0x1,%ecx
0x00007fffe100549c: jne 0x00007fffe10054ad // 如果不相等,则跳转到-- d --
0x00007fffe10054a2: vmovss 0x30(%rsp),%xmm0 // 针对32位的移动
0x00007fffe10054a8: jmpq 0x00007fffe10054b3 // 跳转到-- done --
// **** d ****
0x00007fffe10054ad: vmovsd 0x30(%rsp),%xmm0 // 针对64位的移动
// **** done **** // (6 + 1) * wordSize
0x00007fffe10054b3: test $0x2,%ecx
0x00007fffe10054b9: jne 0x00007fffe10054ca
0x00007fffe10054bf: vmovss 0x38(%rsp),%xmm1
0x00007fffe10054c5: jmpq 0x00007fffe10054d0
0x00007fffe10054ca: vmovsd 0x38(%rsp),%xmm1 // (6 + 2) * wordSize
0x00007fffe10054d0: test $0x4,%ecx
0x00007fffe10054d6: jne 0x00007fffe10054e7
0x00007fffe10054dc: vmovss 0x40(%rsp),%xmm2
0x00007fffe10054e2: jmpq 0x00007fffe10054ed
0x00007fffe10054e7: vmovsd 0x40(%rsp),%xmm2 // (6 + 3) * wordSize
0x00007fffe10054ed: test $0x8,%ecx
0x00007fffe10054f3: jne 0x00007fffe1005504
0x00007fffe10054f9: vmovss 0x48(%rsp),%xmm3
0x00007fffe10054ff: jmpq 0x00007fffe100550a
0x00007fffe1005504: vmovsd 0x48(%rsp),%xmm3 // (6 + 4) * wordSize
0x00007fffe100550a: test $0x10,%ecx
0x00007fffe1005510: jne 0x00007fffe1005521
0x00007fffe1005516: vmovss 0x50(%rsp),%xmm4
0x00007fffe100551c: jmpq 0x00007fffe1005527
0x00007fffe1005521: vmovsd 0x50(%rsp),%xmm4 // (6 + 5) * wordSize
0x00007fffe1005527: test $0x20,%ecx
0x00007fffe100552d: jne 0x00007fffe100553e
0x00007fffe1005533: vmovss 0x58(%rsp),%xmm5
0x00007fffe1005539: jmpq 0x00007fffe1005544
0x00007fffe100553e: vmovsd 0x58(%rsp),%xmm5 // (6 + 6) * wordSize
0x00007fffe1005544: test $0x40,%ecx
0x00007fffe100554a: jne 0x00007fffe100555b
0x00007fffe1005550: vmovss 0x60(%rsp),%xmm6
0x00007fffe1005556: jmpq 0x00007fffe1005561
0x00007fffe100555b: vmovsd 0x60(%rsp),%xmm6 // (6 + 7) * wordSize
0x00007fffe1005561: test $0x80,%ecx
0x00007fffe1005567: jne 0x00007fffe1005578
0x00007fffe100556d: vmovss 0x68(%rsp),%xmm7
0x00007fffe1005573: jmpq 0x00007fffe100557e
0x00007fffe1005578: vmovsd 0x68(%rsp),%xmm7
其中的%ecx中存储的是float/double identifiers,这是一个组合数字,也就是能够指明8个浮点数slot中,哪些存储了float值,哪些存储了double值,然后分别使用vmovss和vmovsd移动到对应的寄存器中。
下面接着看AbstractInterpreterGenerator::generate_slow_signature_handler()函数中生成的汇编代码的逻辑,如下:
// 将Method::access_flags存储到%ecx中
0x00007fffe100557e: mov 0x28(%rbx),%ecx
// 是否含有JVM_ACC_STATIC标识
0x00007fffe1005581: test $0x8,%ecx
// 如果不含有,表示为实例方法,则将栈顶值存储到c_rarg1,即%rsi中
0x00007fffe1005587: cmove (%rsp),%rsi // 将栈顶值存储到c_rarg2、c_rarg3、c_rarg4及c_rarg5中
0x00007fffe100558c: mov 0x8(%rsp),%rdx
0x00007fffe1005591: mov 0x10(%rsp),%rcx
0x00007fffe1005596: mov 0x18(%rsp),%r8
0x00007fffe100559b: mov 0x20(%rsp),%r9 // 恢复%rsp
0x00007fffe10055a0: add $0x70,%rsp
0x00007fffe10055a4: retq
之前已经将栈中保存的浮点数存储到了对应的寄存器中,现在需要将整数也保存到对应的寄存器中。
当将相关的值移动到寄存器后,新开始的14个slot就没有用处了,直接更改%rsp的指向弹出这14个slot,这样慢速解释器为调用本地函数准备好了调用相关的参数。
对于慢速解释器来说,其对于所有的本地方法,生成的例程都是同一个,所以在这个例程中就必须检查目标方法是否为静态的、是否需要同步,然后根据不同的情况进入不同的路径。还需要检查参数数量和参数类型,然后准备栈参数。如果每个native方法的调用都涉及到这些逻辑,那么执行的速度就会相对较慢一些。
对于快速解释器来说,只是执行了必要的逻辑,所以执行的速度会相对快一些。
2、result_handler
无论是快速解释器还是慢速解释器,都会根据native方法的结果类型返回对应的result_handler(快速解释器返回result_handler的逻辑在InterpreterRuntime::SignatureHandlerGenerator::generate()函数中,慢速解释器在InterpreterRuntime::slow_signature_handler()函数中)。下面我们就来看一下result_handler,生成result_handler的代码如下:
static const BasicType types[Interpreter::number_of_result_handlers] = {
T_BOOLEAN,
T_CHAR ,
T_BYTE ,
T_SHORT ,
T_INT ,
T_LONG ,
T_VOID ,
T_FLOAT ,
T_DOUBLE ,
T_OBJECT
};
{
CodeletMark cm(_masm, "result handlers for native calls");
int is_generated[Interpreter::number_of_result_handlers]; // 10
memset(is_generated, 0, sizeof(is_generated));
for (int i = 0; i < Interpreter::number_of_result_handlers; i++) {
BasicType type = types[i];
if (!is_generated[Interpreter::BasicType_as_index(type)]++) {
int x = Interpreter::BasicType_as_index(type);
Interpreter::_native_abi_to_tosca[x] = generate_result_handler_for(type);
}
}
}
会根据不同的方法返回类型生成不同的例程,这些例程都会保存到对应的_native_abi_to_tosca数组中,这个数组的定义如下:
static address _native_abi_to_tosca[number_of_result_handlers];
调用的generate_result_handler_for()函数的实现如下:
address TemplateInterpreterGenerator::generate_result_handler_for(BasicType type) {
switch (type) {
case T_BOOLEAN: __ c2bool(rax); break;
case T_CHAR : __ movzwl(rax, rax); break;
case T_BYTE : __ sign_extend_byte(rax); break;
case T_SHORT : __ sign_extend_short(rax); break;
case T_INT : /* nothing to do */ break;
case T_LONG : /* nothing to do */ break;
case T_VOID : /* nothing to do */ break;
case T_FLOAT : /* nothing to do */ break;
case T_DOUBLE : /* nothing to do */ break;
case T_OBJECT :
// 对于返回类型为Object来说,会将结果存储到栈上特定的位置
__ movptr(rax, Address(rbp, frame::interpreter_frame_oop_temp_offset*wordSize));
break;
default : ShouldNotReachHere();
}
__ ret(0);
return entry;
}
可以看到,向Interpreter::_native_abi_to_tosca数组中存储了不同类型的入口。
(1)T_BOOLEAN
调用如下函数生成处理方法返回类型为boolean的例程:
void MacroAssembler::c2bool(Register x) {
// implements x == 0 ? 0 : 1
// note: must only look at least-significant byte of x
// since C-style booleans are stored in one byte
// only! (was bug)
andl(x, 0xFF);
setb(Assembler::notZero, x);
}
生成的汇编如下:
0x00007fffe100ecc0: and $0xff,%eax
0x00007fffe100ecc6: setne %al // 获取ZF值后,取反,然后再放入%al中
0x00007fffe100ecc9: retq
setxx系列指令根据标志寄存器eflags的值,将操作数设置为0或1,如setne表示ZF=0时,也就是不相等时设置%al为1,否则设置为0。
(2)T_CHAR
生成的汇编如下:
0x00007fffe100ecca: movzwl %ax,%eax
0x00007fffe100eccd: retq
(3)T_BYTE
生成的汇编如下:
0x00007fffe100ecce: movsbl %al,%eax
0x00007fffe100ecd1: retq
(4)T_SHORT
生成的汇编如下:
0x00007fffe100ecd2: movswl %ax,%eax
0x00007fffe100ecd5: retq
(5)T_INT、T_LONG、T_VOID、T_FLOAT与T_DOUBLE
只会生成一个retq指令,因为相关的值都根据调用约定缓存到了特定的寄存器中。
(6)T_OBJECT
生成的汇编如下:
0x00007fffe100ecdb: mov 0x10(%rbp),%rax
0x00007fffe100ecdf: retq
0x10(%rbp)在之前介绍为native方法设置解释器入口时介绍过,这个slot处为oop temp,当native方法返回对象时,将结果存储到这个slot中。
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流
第46篇-signature_handler与result_handler的更多相关文章
- 《Entity Framework 6 Recipes》中文翻译系列 (46) ------ 第八章 POCO之领域对象测试和仓储测试
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 8-8 测试领域对象 问题 你想为领域对象创建单元测试. 这主要用于,测试特定的数 ...
- 第47篇-解释执行的Java方法调用native方法小实例
举个小实例,如下: public class TestJNI { static { // 程序在加载时,自动加载libdiaoyong.so库 System.loadLibrary("dia ...
- Qt, 我回来了。。。
说起qt,大学时就有接触,但一直没有深入,这个周六周天利用两于时间重新温习了一下,跟之前用过的vs上的MFC.C++ builder比起来,Qt封装很人性化,库也比较全,写个 一般的小工具很轻松. 参 ...
- 从壹开始 [ Nuxt.js ] 之一 || 为开源收录Bug之 TiBug项目 开篇讲
缘起 哈喽大家周二好呀,刚刚经历过了几天火车抢票,整个人都不好了,不知道小伙伴对今年的春节是否还一如既往的期待呢,眼看都要春节了,本来也想写篇2018总结篇,但是怕不免会出现鸡汤文的窠臼嫌疑,想想还是 ...
- 零基础入门微信小程序开发
注:本文来源于:<零基础入门微信小程序开发> 课程介绍 本达人课是一个系列入门教程,目标是从 0 开始带领读者上手实战,课程以微信小程序的核心概念作为主线,介绍配置文件.页面样式文件.Ja ...
- LeetCode算法题-House Robber(Java实现)
这是悦乐书的第187次更新,第189篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第46题(顺位题号是198).你是一个专业的强盗,计划在街上抢劫房屋. 每个房子都藏着一 ...
- maven dependendency
登录|注册 zhengsj的专栏 目录视图 摘要视图 订阅 [公告]博客系统优化升级 [收藏]Html5 精品资源汇集 博乐招募开始啦 Maven De ...
- 自己动手写CPU之第九阶段(7)——MIPS32中的LL、SC指令说明
将陆续上传新书<自己动手写CPU>,今天是第46篇. 在MIPS32指令集中有两条特殊的存储载入指令:链接载入指令LL.条件存储指令SC,本次将介绍这两条指令.在兴许将实现这两条指令. 9 ...
- LeetCode 77,组合挑战,你能想出不用递归的解法吗?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode第46篇文章,我们一起来LeetCode中的77题,Combinations(组合). 这个题目可以说是很精辟了,仅仅 ...
随机推荐
- [atAGC048F]01 Record
先将这个序列翻转,贪心找到最长的'101010--'的形式的子序列并删除,重复此过程并记这些字符串长度依次为$l_{1},l_{2},...,l_{n}$,若最终还有字符剩余则一定无解 假设$S$中元 ...
- 在spring启动后执行代码
如果spring的项目直接监听tomcat启动对于 操作来说有很大难度,bean没有初始化,接口不能直接调用等等,所以我们代码执行要在spring启动之后执行项目 package com.java71 ...
- 最小生成树(MST)详解+题目
原因 回顾一下旧知识 概况 在一给定的无向图G = (V, E) 中,(u, v) 代表连接顶点 u 与顶点 v 的边(即),而 w(u, v) 代表此边的权重,若存在 T 为 E 的子集(即)且为无 ...
- DirectX12 3D 游戏开发与实战第七章内容(上)
利用Direct3D绘制几何体(续) 学习目标 学会一种无须每帧都要刷新命令队列的渲染流程,以此来优化性能 了解另外两种根签名参数类型:根常量和根描述符 探索如何在程序中生成和绘制常见的几何体:如栅格 ...
- 深入理解 OpenFOAM 环境变量与编译
操作系统选择 由于 OpenFOAM 在 Linux 平台开发和测试,在非 Linux 平台无法直接对软件进行编译和安装,所以在非 Linux 平台上最简便方法是使用 docker 容器运行 Open ...
- 根据VCF构建进化树
VCF2Dis,是一款计算根据vcf文件计算距离矩阵的小工具 1 安装 下载后 tar -zxvf VCF2DisXXX.tar.gz cd VCF2DisXXX make # 添加环境变量即可 2 ...
- Perl语言入门14-17
---------第十四章 字符串与排序------------------- index查找子字符串 my $stuff = "howdy world!"; my $where ...
- 如何鉴定全基因组加倍事件(WGD)
目前鉴定全基因组加倍(whole-genome duplication events)有3种 通过染色体共线性(synteny) 方法是比较两个基因组的序列,并将同源序列的位置绘制成点状图,如果能在点 ...
- C++常用的字符串处理函数-全
这是自己用stl实现的一些字符串处理函数和常用的字符串处理技巧,经验正基本无误,可直接使用,若有问题,可相应列出 包括:split string to int int to string join # ...
- tcp可靠传输的机制有哪些(面试必看
一.综述 1.确认和重传:接收方收到报文就会确认,发送方发送一段时间后没有收到确认就重传. 2.数据校验 3.数据合理分片和排序: UDP:IP数据报大于1500字节,大于MTU.这个时候发送方IP层 ...