etcd学习(6)-etcd实现raft源码解读
etcd中raft实现源码解读
前言
关于raft的原来可参考etcd学习(5)-etcd的Raft一致性算法原理
本文次阅读的etcd代码版本v3.5.0
Etcd将raft协议实现为一个library,然后本身作为一个应用使用它。这个库仅仅实现了对应的raft算法,对于网络传输,磁盘存储,raft库没有做具体的实现,需要用户自己去实现。
raft实现
先来看几个源码中定义的一些变量概念
Node: 对etcd-raft模块具体实现的一层封装,方便上层模块使用etcd-raft模块;
上层模块: etcd-raft的调用者,上层模块通过Node提供的API与底层的etcd-raft模块进行交互;
Cluster: 表示一个集群,其中记录了该集群的基础信息;
Member: 组层Cluster的元素之一,其中封装了一个节点的基本信息;
Peer: 集群中某个节点对集群中另一个节点的称呼;
Entry记录: 节点之间的传递是通过message进行的,每条消息中可以携带多条Entry记录,每条Entry对应一条一个独立的操作
type Entry struct {
// Term:表示该Entry所在的任期。
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
// Index:当前这个entry在整个raft日志中的位置索引,有了Term和Index之后,一个`log entry`就能被唯一标识。
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
// 当前entry的类型
// 目前etcd支持两种类型:EntryNormal和EntryConfChange
// EntryNormaln表示普通的数据操作
// EntryConfChange表示集群的变更操作
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"`
// 具体操作使用的数据
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}
- Message: 是所有消息的抽象,包括各种消息所需要的字段,raft集群中各个节点之前的通讯都是通过这个message进行的。
type Message struct {
// 该字段定义了不同的消息类型,etcd-raft就是通过不同的消息类型来进行处理的,etcd中一共定义了19种类型
Type MessageType `protobuf:"varint,1,opt,name=type,enum=raftpb.MessageType" json:"type"`
// 消息的目标节点 ID,在急群中每个节点都有一个唯一的id作为标识
To uint64 `protobuf:"varint,2,opt,name=to" json:"to"`
// 发送消息的节点ID
From uint64 `protobuf:"varint,3,opt,name=from" json:"from"`
// 整个消息发出去时,所处的任期
Term uint64 `protobuf:"varint,4,opt,name=term" json:"term"`
// 该消息携带的第一条Entry记录的的Term值
LogTerm uint64 `protobuf:"varint,5,opt,name=logTerm" json:"logTerm"`
// 索引值,该索引值和消息的类型有关,不同的消息类型代表的含义不同
Index uint64 `protobuf:"varint,6,opt,name=index" json:"index"`
// 需要存储的日志信息
Entries []Entry `protobuf:"bytes,7,rep,name=entries" json:"entries"`
// 已经提交的日志的索引值,用来向别人同步日志的提交信息。
Commit uint64 `protobuf:"varint,8,opt,name=commit" json:"commit"`
// 在传输快照时,该字段保存了快照数据
Snapshot Snapshot `protobuf:"bytes,9,opt,name=snapshot" json:"snapshot"`
// 主要用于响应类型的消息,表示是否拒绝收到的消息。
Reject bool `protobuf:"varint,10,opt,name=reject" json:"reject"`
// Follower 节点拒绝 eader 节点的消息之后,会在该字段记录 一个Entry索引值供Leader节点。
RejectHint uint64 `protobuf:"varint,11,opt,name=rejectHint" json:"rejectHint"`
// 携带的一些上下文的信息
Context []byte `protobuf:"bytes,12,opt,name=context" json:"context,omitempty"`
}
- raftLog: Raft中日志同步的核心就是集群中leader如何同步日志到各个follower。日志的管理是在raftLog结构上完成的。
type raftLog struct {
// 用于保存自从最后一次snapshot之后提交的数据
storage Storage
// 用于保存还没有持久化的数据和快照,这些数据最终都会保存到storage中
unstable unstable
// 当天提交的日志数据索引
committed uint64
// committed保存是写入持久化存储中的最高index,而applied保存的是传入状态机中的最高index
// 即一条日志首先要提交成功(即committed),才能被applied到状态机中
// 因此以下不等式一直成立:applied <= committed
applied uint64
logger Logger
// 调用 nextEnts 时,返回的日志项集合的最大的大小
// nextEnts 函数返回应用程序已经可以应用到状态机的日志项集合
maxNextEntsSize uint64
}
看下etcd中的raftexample
这里先看下etcd中提供的raftexample来简单连接下etcd中raft的使用
这里放一张raftexample总体的架构图
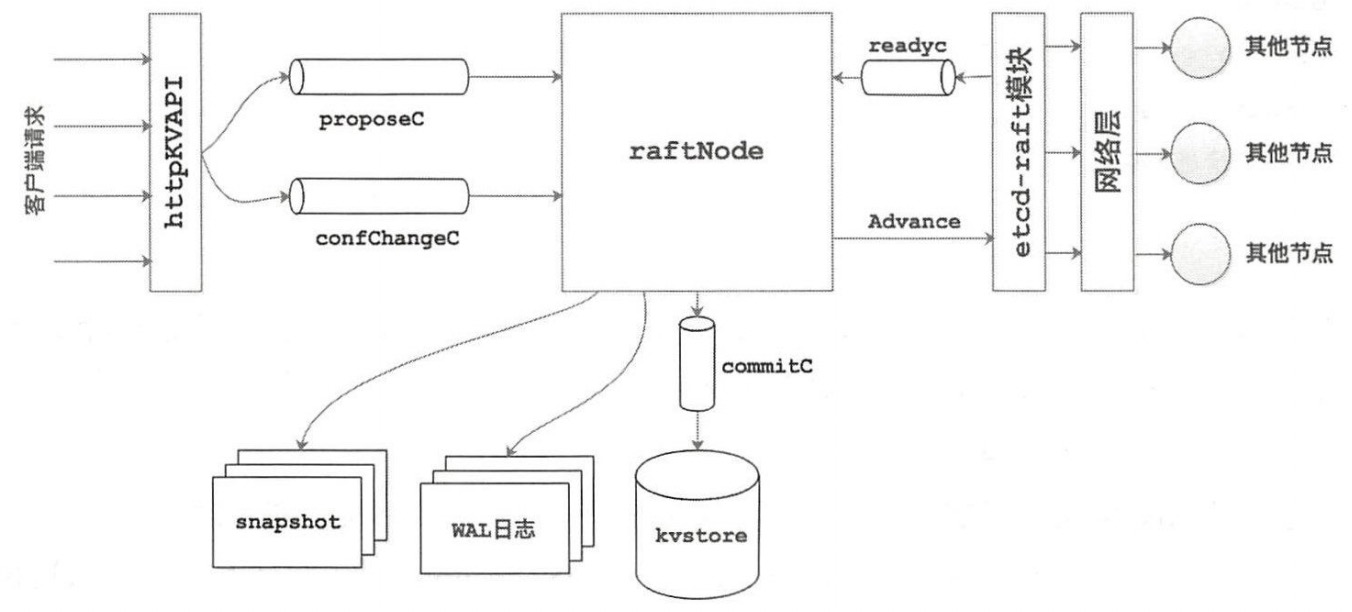
raftexample 是一个etcd raft library的使用示例。它为Raft一致性算法的键值对集群存储提供了一个简单的REST API。
该包提供了goreman启动集群的方式,使用goreman start启动,可以很清楚的看到raft在启动过程中的选举过程,能够很好的帮助我们理解raft的选举过程
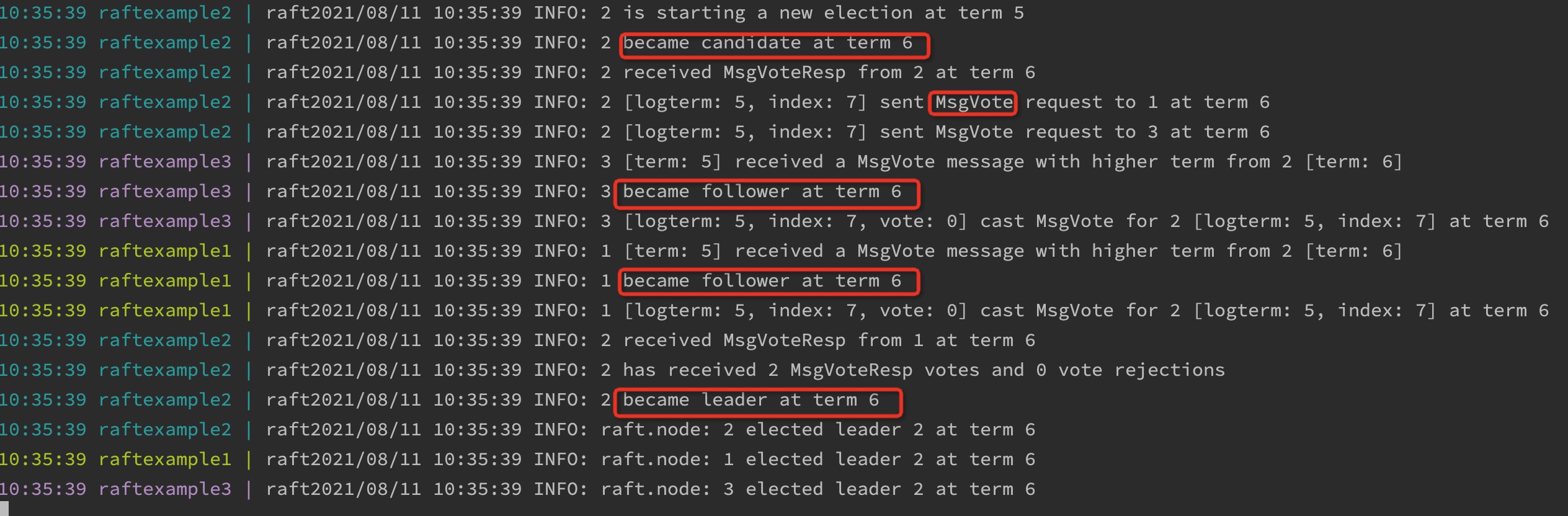
来看下几个主要的函数实现
newRaftNode
在该函数中主要完成了raftNode的初始化 。在该方法中会使用上层模块传入的配置信息(其中包括proposeC通道和confChangeC通道)来创建raftNode实例,同时会创建commitC通道和errorC通道返回给上层模块使用 。这样,上层模块就可以通过这几个通道与rafeNode实例进行 交互了。另外,newRaftNode()函数中还会启动一个独立的后台goroutine来完成回放WAL日志、 启动网络组件等初始化操作。
// 主要完成了raftNode的初始化
// 使用上层模块传入的配置信息来创建raftNode实例,同时创建commitC 通道和errorC通道返回给上层模块使用
// 上层的应用通过这几个channel就能和raftNode进行交互
func newRaftNode(id int, peers []string, join bool, getSnapshot func() ([]byte, error), proposeC <-chan string,
confChangeC <-chan raftpb.ConfChange) (<-chan *commit, <-chan error, <-chan *snap.Snapshotter) {
// channel,主要传输Entry记录
// raftNode会将etcd-raft模块返回的待应用Entry记
// 录(封装在 Ready实例中〉写入commitC通道,另一方面,kvstore会从commitC通
// 道中读取这些待应用的 Entry 记录井保存其中的键值对信息。
commitC := make(chan *commit)
errorC := make(chan error)
rc := &raftNode{
proposeC: proposeC,
confChangeC: confChangeC,
commitC: commitC,
errorC: errorC,
id: id,
peers: peers,
join: join,
// 初始化存放 WAL 日志和 Snapshot 文件的的目录
waldir: fmt.Sprintf("raftexample-%d", id),
snapdir: fmt.Sprintf("raftexample-%d-snap", id),
getSnapshot: getSnapshot,
snapCount: defaultSnapshotCount,
stopc: make(chan struct{}),
httpstopc: make(chan struct{}),
httpdonec: make(chan struct{}),
logger: zap.NewExample(),
snapshotterReady: make(chan *snap.Snapshotter, 1),
// rest of structure populated after WAL replay
}
// 启动一个goroutine,完成剩余的初始化工作
go rc.startRaft()
return commitC, errorC, rc.snapshotterReady
}
startRaft
1、创建 Snapshotter,并将该 Snapshotter 实例返回给上层模块;
2、创建 WAL 实例,然后加载快照并回放 WAL 日志;
3、创建 raft.Config 实例,其中包含了启动 etcd-raft 模块的所有配置;
4、初始化底层 etcd-raft 模块,得到 node 实例;
5、创建 Transport 实例,该实例负责集群中各个节点之间的网络通信,其具体实现在 raft-http 包中;
6、建立与集群中其他节点的网络连接;
7、启动网络组件,其中会监听当前节点与集群中其他节点之间的网络连接,并进行节点之间的消息读写;
8、启动两个后台的 goroutine,它们主要工作是处理上层模块与底层 etcd-raft 模块的交互,但处理的具体内容不同,后面会详细介绍这两个 goroutine 的处理流程。
func (rc *raftNode) startRaft() {
if !fileutil.Exist(rc.snapdir) {
if err := os.Mkdir(rc.snapdir, 0750); err != nil {
log.Fatalf("raftexample: cannot create dir for snapshot (%v)", err)
}
}
rc.snapshotter = snap.New(zap.NewExample(), rc.snapdir)
// 创建 WAL 实例,然后加载快照并回放 WAL 日志
oldwal := wal.Exist(rc.waldir)
// raftNode.replayWAL() 方法首先会读取快照数据,
//在快照数据中记录了该快照包含的最后一条 Entry 记录的 Term 值 和 索引值。
//然后根据 Term 值 和 索引值确定读取 WAL 日志文件的位置, 并进行日志记录的读取。
rc.wal = rc.replayWAL()
// signal replay has finished
rc.snapshotterReady <- rc.snapshotter
rpeers := make([]raft.Peer, len(rc.peers))
for i := range rpeers {
rpeers[i] = raft.Peer{ID: uint64(i + 1)}
}
// 创建 raft.Config 实例
c := &raft.Config{
ID: uint64(rc.id),
// 选举超时
ElectionTick: 10,
// 心跳超时
HeartbeatTick: 1,
Storage: rc.raftStorage,
MaxSizePerMsg: 1024 * 1024,
MaxInflightMsgs: 256,
MaxUncommittedEntriesSize: 1 << 30,
}
// 初始化底层的 etcd-raft 模块,这里会根据 WAL 日志的回放情况,
// 判断当前节点是首次启动还是重新启动
if oldwal || rc.join {
rc.node = raft.RestartNode(c)
} else {
// 初次启动
rc.node = raft.StartNode(c, rpeers)
}
// 创建 Transport 实例并启动,他负责 raft 节点之间的网络通信服务
rc.transport = &rafthttp.Transport{
Logger: rc.logger,
ID: types.ID(rc.id),
ClusterID: 0x1000,
Raft: rc,
ServerStats: stats.NewServerStats("", ""),
LeaderStats: stats.NewLeaderStats(zap.NewExample(), strconv.Itoa(rc.id)),
ErrorC: make(chan error),
}
// 启动网络服务相关组件
rc.transport.Start()
// 建立与集群中其他各个节点的连接
for i := range rc.peers {
if i+1 != rc.id {
rc.transport.AddPeer(types.ID(i+1), []string{rc.peers[i]})
}
}
// 启动一个goroutine,其中会监听当前节点与集群中其他节点之间的网络连接
go rc.serveRaft()
// 启动后台 goroutine 处理上层应用与底层 etcd-raft 模块的交互
go rc.serveChannels()
}
serveChannels
处理上层应用与底层etcd-raft模块的交互
// 会单独启动一个后台 goroutine来负责上层模块 传递给 etcd-ra企 模块的数据,
// 主要 处理前面介绍的 proposeC、 confChangeC 两个通道
func (rc *raftNode) serveChannels() {
// 这里是获取快照数据和快照的元数据
snap, err := rc.raftStorage.Snapshot()
if err != nil {
panic(err)
}
rc.confState = snap.Metadata.ConfState
rc.snapshotIndex = snap.Metadata.Index
rc.appliedIndex = snap.Metadata.Index
defer rc.wal.Close()
// 创建一个每隔 lOOms 触发一次的定时器,那么在逻辑上,lOOms 即是 etcd-raft 组件的最小时间单位 ,
// 该定时器每触发一次,则逻辑时钟推进一次
ticker := time.NewTicker(100 * time.Millisecond)
defer ticker.Stop()
// 单独启 动一个 goroutine 负责将 proposeC、 confChangeC 远远上接收到
// 的数据传递给 etcd-raft 组件进行处理
go func() {
confChangeCount := uint64(0)
for rc.proposeC != nil && rc.confChangeC != nil {
select {
case prop, ok := <-rc.proposeC:
if !ok {
// 发生异常将proposeC置空
rc.proposeC = nil
} else {
// 阻塞直到消息被处理
rc.node.Propose(context.TODO(), []byte(prop))
}
// 收到上层应用通过 confChangeC远远传递过来的数据
case cc, ok := <-rc.confChangeC:
if !ok {
// 如果发生异常将confChangeC置空
rc.confChangeC = nil
} else {
confChangeCount++
cc.ID = confChangeCount
rc.node.ProposeConfChange(context.TODO(), cc)
}
}
}
// 关闭 stopc 通道,触发 rafeNode.stop() 方法的调用
close(rc.stopc)
}()
// 处理 etcd-raft 模块返回给上层模块的数据及其他相关的操作
for {
select {
case <-ticker.C:
// 上述 ticker 定时器触发一次
rc.node.Tick()
// 读取 node.readyc 通道
// 该通道是 etcd-raft 组件与上层应用交互的主要channel之一
// 其中传递的 Ready 实例也封装了很多信息
case rd := <-rc.node.Ready():
// 将当前 etcd raft 组件的状态信息,以及待持久化的 Entry 记录先记录到 WAL 日志文件中,
// 即使之后宕机,这些信息也可以在节点下次启动时,通过前面回放 WAL 日志的方式进行恢复
rc.wal.Save(rd.HardState, rd.Entries)
// 检测到 etcd-raft 组件生成了新的快照数据
if !raft.IsEmptySnap(rd.Snapshot) {
// 将新的快照数据写入快照文件中
rc.saveSnap(rd.Snapshot)
// 将新快照持久化到 raftStorage
rc.raftStorage.ApplySnapshot(rd.Snapshot)
// 通知上层应用加载新快照
rc.publishSnapshot(rd.Snapshot)
}
// 将待持久化的 Entry 记录追加到 raftStorage 中完成持久化
rc.raftStorage.Append(rd.Entries)
// 将待发送的消息发送到指定节点
rc.transport.Send(rd.Messages)
// 将已提交、待应用的 Entry 记录应用到上层应用的状态机中
applyDoneC, ok := rc.publishEntries(rc.entriesToApply(rd.CommittedEntries))
if !ok {
rc.stop()
return
}
// 随着节点的运行, WAL 日志量和 raftLog.storage 中的 Entry 记录会不断增加 ,
// 所以节点每处理 10000 条(默认值) Entry 记录,就会触发一次创建快照的过程,
// 同时 WAL 会释放一些日志文件的句柄,raftLog.storage 也会压缩其保存的 Entry 记录
rc.maybeTriggerSnapshot(applyDoneC)
// 上层应用处理完该 Ready 实例,通知 etcd-raft 纽件准备返回下一个 Ready 实例
rc.node.Advance()
case err := <-rc.transport.ErrorC:
rc.writeError(err)
return
case <-rc.stopc:
rc.stop()
return
}
}
}
领导者选举
启动并初始化node节点
对于node来讲,刚被出初始化的时候就是follower状态,当集群中的节点初次启动时会通过StartNode()函数启动创建对应的node实例和底层的raft实例。在StartNode()方法中,主要是根据传入的config配置创建raft实例并初始raft负使用的相关组件。
// etcd/raft/node.go
// Peer封装了节点的ID, peers记录了当前集群中全部节点的ID
func StartNode(c *Config, peers []Peer) Node {
if len(peers) == 0 {
panic("no peers given; use RestartNode instead")
}
// 根据config信息初始化RawNode
// 同时也会初始化一个raft
rn, err := NewRawNode(c)
if err != nil {
panic(err)
}
// 第一次使用初始化RawNode
err = rn.Bootstrap(peers)
if err != nil {
c.Logger.Warningf("error occurred during starting a new node: %v", err)
}
// 初始化node实例
n := newNode(rn)
go n.run()
return &n
}
func NewRawNode(config *Config) (*RawNode, error) {
// 这里调用初始化newRaft
r := newRaft(config)
rn := &RawNode{
raft: r,
}
rn.prevSoftSt = r.softState()
rn.prevHardSt = r.hardState()
return rn, nil
}
func newRaft(c *Config) *raft {
...
r := &raft{
id: c.ID,
lead: None,
isLearner: false,
raftLog: raftlog,
maxMsgSize: c.MaxSizePerMsg,
maxUncommittedSize: c.MaxUncommittedEntriesSize,
prs: tracker.MakeProgressTracker(c.MaxInflightMsgs),
electionTimeout: c.ElectionTick,
heartbeatTimeout: c.HeartbeatTick,
logger: c.Logger,
checkQuorum: c.CheckQuorum,
preVote: c.PreVote,
readOnly: newReadOnly(c.ReadOnlyOption),
disableProposalForwarding: c.DisableProposalForwarding,
}
...
// 启动都是follower状态
r.becomeFollower(r.Term, None)
var nodesStrs []string
for _, n := range r.prs.VoterNodes() {
nodesStrs = append(nodesStrs, fmt.Sprintf("%x", n))
}
r.logger.Infof("newRaft %x [peers: [%s], term: %d, commit: %d, applied: %d, lastindex: %d, lastterm: %d]",
r.id, strings.Join(nodesStrs, ","), r.Term, r.raftLog.committed, r.raftLog.applied, r.raftLog.lastIndex(), r.raftLog.lastTerm())
return r
}
总结:
进行node节点初始化工作,所有的Node开始都被初始化为Follower状态
重点来看下run
func (n *node) run() {
...
for {
...
select {
case pm := <-propc:
...
r.Step(m)
case m := <-n.recvc:
...
r.Step(m)
case cc := <-n.confc:
...
case <-n.tickc:
n.rn.Tick()
case readyc <- rd:
n.rn.acceptReady(rd)
advancec = n.advancec
case <-advancec:
n.rn.Advance(rd)
rd = Ready{}
advancec = nil
case c := <-n.status:
c <- getStatus(r)
case <-n.stop:
close(n.done)
return
}
}
}
总结:
主要是通过for-select-channel监听channel信息,来处理不同的请求
来看下几个主要的channel信息
propc和recvc中拿到的是从上层应用传进来的消息,这个消息会被交给raft层的Step函数处理。
func (r *raft) Step(m pb.Message) error {
//...
switch m.Type {
case pb.MsgHup:
//...
case pb.MsgVote, pb.MsgPreVote:
//...
default:
r.step(r, m)
}
}
总结:
Step是etcd-raft模块负责各类信息的入口
default后面的step,被实现为一个状态机,它的step属性是一个函数指针,根据当前节点的不同角色,指向不同的消息处理函数:stepLeader/stepFollower/stepCandidate。与它类似的还有一个tick函数指针,根据角色的不同,也会在tickHeartbeat和tickElection之间来回切换,分别用来触发定时心跳和选举检测。
发送心跳包
作为leader
当一个节点成为leader的时候,会将节点的定时器设置为tickHeartbeat,然后周期性的调用,维持leader的地位
func (r *raft) becomeLeader() {
// 检测当 前节点的状态,禁止从 follower 状态切换成 leader 状态
if r.state == StateFollower {
panic("invalid transition [follower -> leader]")
}
// 将step 字段设置成 stepLeader
r.step = stepLeader
r.reset(r.Term)
// 设置心跳的函数
r.tick = r.tickHeartbeat
// 设置lead的id值
r.lead = r.id
// 更新当前的角色
r.state = StateLeader
...
}
func (r *raft) tickHeartbeat() {
// 递增心跳计数器
r.heartbeatElapsed++
// 递增选举计数器
r.electionElapsed++
...
if r.electionElapsed >= r.electionTimeout {
r.electionElapsed = 0
// 检测当前节点时候大多数节点保持连通
if r.checkQuorum {
r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum})
}
// If current leader cannot transfer leadership in electionTimeout, it becomes leader again.
if r.state == StateLeader && r.leadTransferee != None {
r.abortLeaderTransfer()
}
}
if r.heartbeatElapsed >= r.heartbeatTimeout {
r.heartbeatElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgBeat})
}
}
becomeLeader中的step被设置成stepLeader,所以将会调用stepLeader来处理leader中对应的消息
通过调用bcastHeartbeat向所有的节点发送心跳
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
case pb.MsgBeat:
// 向所有节点发送心跳
r.bcastHeartbeat()
return nil
case pb.MsgCheckQuorum:
// 检测是否和大部分节点保持连通
// 如果不连通切换到follower状态
if !r.prs.QuorumActive() {
r.logger.Warningf("%x stepped down to follower since quorum is not active", r.id)
r.becomeFollower(r.Term, None)
}
return nil
...
}
}
// bcastHeartbeat sends RPC, without entries to all the peers.
func (r *raft) bcastHeartbeat() {
lastCtx := r.readOnly.lastPendingRequestCtx()
// 这两个函数最终都将调用sendHeartbeat
if len(lastCtx) == 0 {
r.bcastHeartbeatWithCtx(nil)
} else {
r.bcastHeartbeatWithCtx([]byte(lastCtx))
}
}
// 向指定的节点发送信息
func (r *raft) sendHeartbeat(to uint64, ctx []byte) {
commit := min(r.prs.Progress[to].Match, r.raftLog.committed)
m := pb.Message{
To: to,
// 发送MsgHeartbeat类型的数据
Type: pb.MsgHeartbeat,
Commit: commit,
Context: ctx,
}
r.send(m)
}
最终的心跳通过MsgHeartbeat的消息类型进行发送,通知它们目前Leader的存活状态,重置所有Follower持有的超时计时器
作为follower
1、接收到来自leader的RPC消息MsgHeartbeat;
2、然后重置当前节点的选举超时时间;
3、回复leader自己的存活。
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgProp:
...
case pb.MsgHeartbeat:
r.electionElapsed = 0
r.lead = m.From
r.handleHeartbeat(m)
...
}
return nil
}
func (r *raft) handleHeartbeat(m pb.Message) {
r.raftLog.commitTo(m.Commit)
r.send(pb.Message{To: m.From, Type: pb.MsgHeartbeatResp, Context: m.Context})
}
作为candidate
candidate来处理MsgHeartbeat的信息,是先把自己变成follower,然后和上面的follower一样,回复leader自己的存活。
func stepCandidate(r *raft, m pb.Message) error {
...
switch m.Type {
...
case pb.MsgHeartbeat:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleHeartbeat(m)
}
...
return nil
}
func (r *raft) handleHeartbeat(m pb.Message) {
r.raftLog.commitTo(m.Commit)
r.send(pb.Message{To: m.From, Type: pb.MsgHeartbeatResp, Context: m.Context})
}
当leader收到返回的信息的时候,会将对应的节点设置为RecentActive,表示该节点目前存活
func stepLeader(r *raft, m pb.Message) error {
...
// 根据from,取出当前的follower的Progress
pr := r.prs.Progress[m.From]
if pr == nil {
r.logger.Debugf("%x no progress available for %x", r.id, m.From)
return nil
}
switch m.Type {
case pb.MsgHeartbeatResp:
pr.RecentActive = true
...
}
return nil
}
如果follower在一定的时间内,没有收到leader节点的消息,就会发起新一轮的选举,重新选一个leader节点
leader选举
1、接收leader的心跳
func (r *raft) becomeFollower(term uint64, lead uint64) {
r.step = stepFollower
r.reset(term)
r.tick = r.tickElection
r.lead = lead
r.state = StateFollower
r.logger.Infof("%x became follower at term %d", r.id, r.Term)
}
// follower以及candidate的tick函数,在r.electionTimeout之后被调用
func (r *raft) tickElection() {
r.electionElapsed++
// promotable返回是否可以被提升为leader
// pastElectionTimeout检测当前的候选超时间是否过期
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
// 发起选举
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
总结:
1、如果可以成为leader;
2、没有收到leader的心跳,候选超时时间过期了;
3、重新发起新的选举请求。
2、发起竞选
Step函数看到MsgHup这个消息后会调用campaign函数,进入竞选状态
func (r *raft) Step(m pb.Message) error {
//...
switch m.Type {
case pb.MsgHup:
if r.preVote {
r.hup(campaignPreElection)
} else {
r.hup(campaignElection)
}
}
}
func (r *raft) hup(t CampaignType) {
...
r.campaign(t)
}
func (r *raft) campaign(t CampaignType) {
...
if t == campaignPreElection {
r.becomePreCandidate()
voteMsg = pb.MsgPreVote
// PreVote RPCs are sent for the next term before we've incremented r.Term.
term = r.Term + 1
} else {
// 切换到Candidate状态
r.becomeCandidate()
voteMsg = pb.MsgVote
term = r.Term
}
// 统计当前节点收到的选票 并统计其得票数是否超过半数,这次检测主要是为单节点设置的
// 判断是否是单节点
if _, _, res := r.poll(r.id, voteRespMsgType(voteMsg), true); res == quorum.VoteWon {
if t == campaignPreElection {
r.campaign(campaignElection)
} else {
// 是单节点直接,变成leader
r.becomeLeader()
}
return
}
...
// 向集群中的所有节点发送信息,请求投票
for _, id := range ids {
// 跳过自身的节点
if id == r.id {
continue
}
r.logger.Infof("%x [logterm: %d, index: %d] sent %s request to %x at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), voteMsg, id, r.Term)
var ctx []byte
if t == campaignTransfer {
ctx = []byte(t)
}
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
}
总结:
主要是切换到campaign状态,然后将自己的term信息发送出去,请求投票。
这里我们能看到对于Candidate会有一个PreCandidate,PreCandidate这个状态的作用的是什么呢?
当系统曾出现分区,分区消失后恢复的时候,可能会造成某个被split的Follower的Term数值很大。
对服务器进行分区时,它将不会收到heartbeat包,每次electionTimeout后成为Candidate都会递增Term。
当服务器在一段时间后恢复连接时,Term的值将会变得很大,然后引入的重新选举会导致导致临时的延迟与可用性问题。
PreElection阶段并不会真正增加当前节点的Term,它的主要作用是得到当前集群能否成功选举出一个Leader的答案,避免上面这种情况的发生。
接着Candidate的状态来分析
3、其他节点收到信息,进行投票
能够投票需要满足下面条件:
1、当前节点没有给任何节点投票 或 投票的节点term大于本节点的 或者 是之前已经投票的节点;
2、该节点的消息是最新的;
func (r *raft) Step(m pb.Message) error {
...
switch m.Type {
case pb.MsgVote, pb.MsgPreVote:
// We can vote if this is a repeat of a vote we've already cast...
canVote := r.Vote == m.From ||
// ...we haven't voted and we don't think there's a leader yet in this term...
(r.Vote == None && r.lead == None) ||
// ...or this is a PreVote for a future term...
(m.Type == pb.MsgPreVote && m.Term > r.Term)
// ...and we believe the candidate is up to date.
if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) {
// 如果当前没有给任何节点投票(r.Vote == None)或者投票的节点term大于本节点的(m.Term > r.Term)
// 或者是之前已经投票的节点(r.Vote == m.From)
// 同时还满足该节点的消息是最新的(r.raftLog.isUpToDate(m.Index, m.LogTerm)),那么就接收这个节点的投票
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] cast %s for %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.Message{To: m.From, Term: m.Term, Type: voteRespMsgType(m.Type)})
if m.Type == pb.MsgVote {
// 保存下来给哪个节点投票了
r.electionElapsed = 0
r.Vote = m.From
}
} else {
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] rejected %s from %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.Message{To: m.From, Term: r.Term, Type: voteRespMsgType(m.Type), Reject: true})
}
...
}
return nil
}
4、candidate节点统计投票的结果
candidate节点接收到投票的信息,然后统计投票的数量
1、如果投票数大于节点数的一半,成为leader;
2、如果达不到,变成follower;
func stepCandidate(r *raft, m pb.Message) error {
// Only handle vote responses corresponding to our candidacy (while in
// StateCandidate, we may get stale MsgPreVoteResp messages in this term from
// our pre-candidate state).
var myVoteRespType pb.MessageType
if r.state == StatePreCandidate {
myVoteRespType = pb.MsgPreVoteResp
} else {
myVoteRespType = pb.MsgVoteResp
}
switch m.Type {
case myVoteRespType:
// 计算当前集群中有多少节点给自己投了票
gr, rj, res := r.poll(m.From, m.Type, !m.Reject)
r.logger.Infof("%x has received %d %s votes and %d vote rejections", r.id, gr, m.Type, rj)
switch res {
// 大多数投票了
case quorum.VoteWon:
if r.state == StatePreCandidate {
r.campaign(campaignElection)
} else {
// 如果进行投票的节点数量正好是半数以上节点数量
r.becomeLeader()
// 向集群中其他节点广 MsgApp 消息
r.bcastAppend()
}
// 票数不够
case quorum.VoteLost:
// pb.MsgPreVoteResp contains future term of pre-candidate
// m.Term > r.Term; reuse r.Term
// 切换到follower
r.becomeFollower(r.Term, None)
}
...
}
return nil
}
每当收到一个MsgVoteResp类型的消息时,就会设置当前节点持有的votes数组,更新其中存储的节点投票状态,如果收到大多数的节点票数,切换成leader,向其他的节点发送当前节点当选的消息,通知其余节点更新Raft结构体中的Term等信息。
上面涉及到几种状态的切换
正常情况只有3种状态
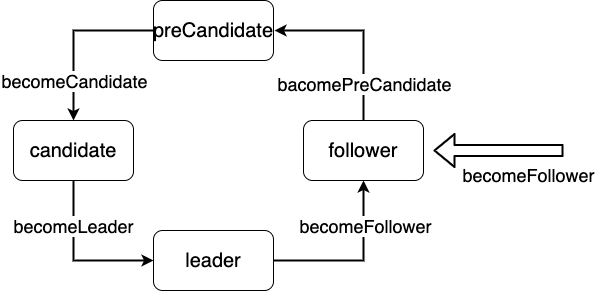
为了防止在分区的情况下,某个split的Follower的Term数值变得很大的场景,引入了PreCandidate
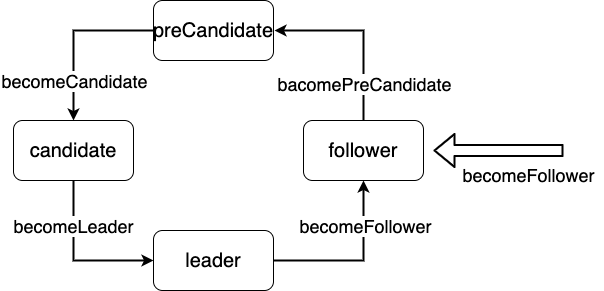
对于不同节点之间的切换,调用的对应的bacome*方法就可以了
这里需要注意的就是对应的每个bacome*中的step和tick
func (r *raft) becomeFollower(term uint64, lead uint64) {
r.step = stepFollower
r.reset(term)
r.tick = r.tickElection
r.lead = lead
r.state = StateFollower
r.logger.Infof("%x became follower at term %d", r.id, r.Term)
}
func (r *raft) becomeCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> candidate]")
}
r.step = stepCandidate
r.reset(r.Term + 1)
r.tick = r.tickElection
r.Vote = r.id
r.state = StateCandidate
r.logger.Infof("%x became candidate at term %d", r.id, r.Term)
}
它的step属性是一个函数指针,根据当前节点的不同角色,指向不同的消息处理函数:stepLeader/stepFollower/stepCandidate。
tick也是一个函数指针,根据角色的不同,也会在tickHeartbeat和tickElection之间来回切换,分别用来触发定时心跳和选举检测。
日志同步
WAL日志
WAL(Write Ahead Log)最大的作用是记录了整个数据变化的全部历程。在etcd中,所有数据的修改在提交前,都要先写入到WAL中。使用WAL进行数据的存储使得etcd拥有两个重要功能。
故障快速恢复: 当你的数据遭到破坏时,就可以通过执行所有WAL中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。
数据回滚(undo)/重做(redo):因为所有的修改操作都被记录在WAL中,需要回滚或重做,只需要反向或正向执行日志中的操作即可。
这里发放一张关于etcd中处理Entry记录的流程图(图片摘自【etcd技术内幕】)

具体的流程:
1、客户端向etcd集群发起一次请求,请求中封装的Entry首先会交给etcd-raft处理,etcd-raft会将Entry记录保存到raftLog.unstable中;
2、etcd-raft将Entry记录封装到Ready实例中,返回给上层模块进行持久化;
3、上层模块收到持久化的Ready记录之后,会记录到WAL文件中,然后进行持久化,最后通知etcd-raft模块进行处理;
4、etcd-raft将该Entry记录从unstable中移到storage中保存;
5、当该Entry记录被复制到集区中的半数以上节点的时候,该Entry记录会被Lader节点认为是已经提交了,封装到Ready实例中通知上层模块;
6、此时上层模块将该Ready实例封装的Entry记录应用到状态机中。
leader同步follower日志
这里放一张etcd中leader节点同步数据到follower的流程图
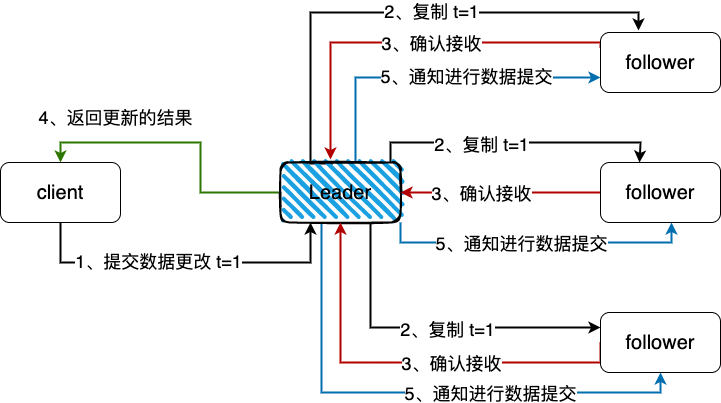
etcd日志的保存总体流程如下:
1、集群某个节点收到client的put请求要求修改数据。节点会生成一个Type为MsgProp的Message,发送给leader。
// 生成MsgProp消息
func (n *node) Propose(ctx context.Context, data []byte) error {
return n.stepWait(ctx, pb.Message{Type: pb.MsgProp, Entries: []pb.Entry{{Data: data}}})
}
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgProp:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term)
return ErrProposalDropped
} else if r.disableProposalForwarding {
r.logger.Infof("%x not forwarding to leader %x at term %d; dropping proposal", r.id, r.lead, r.Term)
return ErrProposalDropped
}
// 设置发送的目标为leader
// 将信息发送给leader
m.To = r.lead
r.send(m)
}
return nil
}
2、leader收到Message以后,会处理Message中的日志条目,将其append到raftLog的unstable的日志中,并且调用bcastAppend()广播append日志的消息。
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
...
case pb.MsgProp:
...
// 将Entry记录追加到当前节点的raftlog中
if !r.appendEntry(m.Entries...) {
return ErrProposalDropped
}
// 向其他节点复制Entry记录
r.bcastAppend()
return nil
...
}
return nil
}
func (r *raft) maybeSendAppend(to uint64, sendIfEmpty bool) bool {
pr := r.prs.Progress[to]
if pr.IsPaused() {
return false
}
m := pb.Message{}
m.To = to
...
m.Type = pb.MsgApp
m.Index = pr.Next - 1
m.LogTerm = term
m.Entries = ents
m.Commit = r.raftLog.committed
if n := len(m.Entries); n != 0 {
switch pr.State {
// optimistically increase the next when in StateReplicate
case tracker.StateReplicate:
last := m.Entries[n-1].Index
pr.OptimisticUpdate(last)
pr.Inflights.Add(last)
case tracker.StateProbe:
pr.ProbeSent = true
default:
r.logger.Panicf("%x is sending append in unhandled state %s", r.id, pr.State)
}
}
r.send(m)
return true
}
3、leader中的消息最终会以MsgApp类型的消息通知follower,follower收到这些信息之后,同leader一样,先将缓存中的日志条目持久化到磁盘中并将当前已经持久化的最新日志index返回给leader。
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgApp:
r.electionElapsed = 0
r.lead = m.From
r.handleAppendEntries(m)
}
return nil
}
func (r *raft) handleAppendEntries(m pb.Message) {
....
if mlastIndex, ok := r.raftLog.maybeAppend(m.Index, m.LogTerm, m.Commit, m.Entries...); ok {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: mlastIndex})
}
...
}
// maybeAppend returns (0, false) if the entries cannot be appended. Otherwise,
// it returns (last index of new entries, true).
func (l *raftLog) maybeAppend(index, logTerm, committed uint64, ents ...pb.Entry) (lastnewi uint64, ok bool) {
...
l.commitTo(min(committed, lastnewi))
...
return 0, false
}
func (l *raftLog) commitTo(tocommit uint64) {
// never decrease commit
if l.committed < tocommit {
if l.lastIndex() < tocommit {
l.logger.Panicf("tocommit(%d) is out of range [lastIndex(%d)]. Was the raft log corrupted, truncated, or lost?", tocommit, l.lastIndex())
}
l.committed = tocommit
}
}
4、最后leader收到大多数的follower的确认,commit自己的log,同时再次广播通知follower自己已经提交了。
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
...
case pb.MsgAppResp:
pr.RecentActive = true
if r.maybeCommit() {
releasePendingReadIndexMessages(r)
// 如果可以commit日志,那么广播append消息
r.bcastAppend()
} else if oldPaused {
// 如果该节点之前状态是暂停,继续发送append消息给它
r.sendAppend(m.From)
}
...
}
return nil
}
// 尝试提交索引,如果已经提交返回true
// 然后应该调用bcastAppend通知所有的follower
func (r *raft) maybeCommit() bool {
mci := r.prs.Committed()
return r.raftLog.maybeCommit(mci, r.Term)
}
// 提交修改committed就可以了
func (l *raftLog) commitTo(tocommit uint64) {
// never decrease commit
if l.committed < tocommit {
if l.lastIndex() < tocommit {
l.logger.Panicf("tocommit(%d) is out of range [lastIndex(%d)]. Was the raft log corrupted, truncated, or lost?", tocommit, l.lastIndex())
}
l.committed = tocommit
}
}
总结
1、etcd中的raft是作为一个library,然后本身作为一个应用使用它。这个库仅仅实现了对应的raft算法;
2、etcd-raft这种实现的过程,其中的step和tick被设计成了函数指针,根据不同的角色来防止不同的函数;
3、为了防止出现网络分区Term数值变得很大的场景,引入了PreCandidate;
4、etcd中所有的数据都是通过leader分发到follower,通过日志的复制确认机制,保证绝大多数的follower都能同步到消息。
参考
【etcd技术内幕】一本关于etcd不错的书籍
【高可用分布式存储 etcd 的实现原理】https://draveness.me/etcd-introduction/
【Raft 在 etcd 中的实现】https://blog.betacat.io/post/raft-implementation-in-etcd/
【etcd Raft库解析】https://www.codedump.info/post/20180922-etcd-raft/
【etcd raft 设计与实现《一》】https://zhuanlan.zhihu.com/p/51063866
【raftexample 源码解读】https://zhuanlan.zhihu.com/p/91314329
【etcd实现-全流程分析】https://zhuanlan.zhihu.com/p/135891186
【线性一致性和Raft】https://pingcap.com/zh/blog/linearizability-and-raft
【etcd raft 设计与实现《二》】https://zhuanlan.zhihu.com/p/51065416
【《深入浅出etcd》part 3 – 解析etcd的日志同步机制】https://mp.weixin.qq.com/s/o_g5z77VZbImgTqjNBSktA
etcd学习(6)-etcd实现raft源码解读的更多相关文章
- etcd学习(10)-etcd对比Consul和zooKeeper如何选型
etcd选型对比 前言 基本架构和原理 etcd Consul ZooKeeper 选型对比 总结 参考 etcd选型对比 前言 对比 Consul, ZooKeeper.选型etcd有那些好处呢? ...
- 很值得学习的java 画图板源码
很值得学习的java 画图板源码下载地址:http://download.csdn.net/source/2371150 package minidrawpad; import java.awt.*; ...
- iOS学习——布局利器Masonry框架源码深度剖析
iOS开发过程中很大一部分内容就是界面布局和跳转,iOS的布局方式也经历了 显式坐标定位方式 --> autoresizingMask --> iOS 6.0推出的自动布局(Auto La ...
- Spring学习之——手写Spring源码V2.0(实现IOC、D、MVC、AOP)
前言 在上一篇<Spring学习之——手写Spring源码(V1.0)>中,我实现了一个Mini版本的Spring框架,在这几天,博主又看了不少关于Spring源码解析的视频,受益匪浅,也 ...
- Spark学习之路 (十六)SparkCore的源码解读(二)spark-submit提交脚本
一.概述 上一篇主要是介绍了spark启动的一些脚本,这篇主要分析一下Spark源码中提交任务脚本的处理逻辑,从spark-submit一步步深入进去看看任务提交的整体流程,首先看一下整体的流程概要图 ...
- SDWebImage源码解读 之 NSData+ImageContentType
第一篇 前言 从今天开始,我将开启一段源码解读的旅途了.在这里先暂时不透露具体解读的源码到底是哪些?因为也可能随着解读的进行会更改计划.但能够肯定的是,这一系列之中肯定会有Swift版本的代码. 说说 ...
- SDWebImage源码解读之SDWebImageCache(下)
第六篇 前言 我们在SDWebImageCache(上)中了解了这个缓存类大概的功能是什么?那么接下来就要看看这些功能是如何实现的? 再次强调,不管是图片的缓存还是其他各种不同形式的缓存,在原理上都极 ...
- AFNetworking 3.0 源码解读 总结(干货)(上)
养成记笔记的习惯,对于一个软件工程师来说,我觉得很重要.记得在知乎上看到过一个问题,说是人类最大的缺点是什么?我个人觉得记忆算是一个缺点.它就像时间一样,会自己消散. 前言 终于写完了 AFNetwo ...
- AFNetworking 3.0 源码解读(十)之 UIActivityIndicatorView/UIRefreshControl/UIImageView + AFNetworking
我们应该看到过很多类似这样的例子:某个控件拥有加载网络图片的能力.但这究竟是怎么做到的呢?看完这篇文章就明白了. 前言 这篇我们会介绍 AFNetworking 中的3个UIKit中的分类.UIAct ...
随机推荐
- linux 生成密钥
p.p1 { margin: 0; font: 16px "Helvetica Neue" } span.s1 { font: 16px ".PingFang SC&qu ...
- Java中的四种引用和引用队列
目录 强引用 软引用 弱引用 幻象引用 Reachability Fence 参考 强引用 正常的引用,生命周期最长,例如 Object obj = new Object(); 当JVM内存不足时,宁 ...
- 访问其他人的vue项目
本地git拉取项目 git clone git@git路径 项目clone到本地后 1.工具命令行切换到此项目路径下 cd 路径名称 2.首先要下载项目所需要的资源包 npm install 这里会 ...
- YsoSerial 工具常用Payload分析之URLDNS
本文假设你对Java基本数据结构.Java反序列化.高级特性(反射.动态代理)等有一定的了解. 背景 YsoSerial是一款反序列化利用的便捷工具,可以很方便的生成基于多种环境的反序列化EXP.ja ...
- Requests方法 -- 关联用例执行
1.参照此篇流程 :Requsts方法 -- Blog流程类进行关联 2.用例接口目录如下: 3.用例代码如下: import requestsimport unittestfrom Request. ...
- maven解析依赖报错:Cannot resolve com.baomidou:mybatis-plus-generator:3.4.2
不能解析依赖: <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plu ...
- my.ini修改后启动失败
修改之后ini文件后不要直接关闭在记事本里点击另存为,编码选择为ANSI编码格式,再保存就行了
- npm WARN checkPermissions Missing write access to ......解决方法
npm安装出错 npm WARN checkPermissions Missing write access to ...... 解决方法: 删除本地node_modules文件夹,之后再次 npm ...
- kali操作系统添加中文输入法
今天一通操作真心累啊.想安装搜狗输入法,百度搜索了好多 三步走:https://blog.csdn.net/qq_44110340/article/details/101382732 一顿操作猛如虎, ...
- 第十三篇 -- QMainWindow与QAction(新建-打开-保存)
效果图: 添加了三个Action,分别是新建,打开,和保存,没有具体写相应的功能,只是提供了一个接口,可以自己写相应的功能.这次不仅将这些Action放在了工具栏,还将其添加到了菜单栏.方法同样是直接 ...