noip模拟4[随·单·题·大佬]
woc woc woc难斩了人都傻了
害上来先看T1,发现这不就是一个小期望嘛(有啥的)真是!!打算半个小时秒掉
可是吧,读着读着题面,发现这题面有大问题,后来去找老师,还是我nb给题挑错,可是错是挑出来了,看完了题开始苦思冥想,我明白了,我不会啊!!!
随随便便打了个暴力,走人了
直接看T2,头都不带回的,看完T2,这不就是两个过程嘛,O(n2)直接搞掉,可惜我就没算这复杂度,TLE快乐30pts,这是我这整场比赛里拿的唯一的分数
然后就去看T3了,此时距离考试结束仍有2h
hhhhh,两个小时还不是拿了0分
T3相对来说还比较简单,我开始推那几种情况,有两种几乎是推出来了,可是我。。。。
卡特兰数就没学!!!!!然后改题的时候就去恶补了一下,现在还是有些了解的(看来比赛还是可以查漏补缺的hhh)
看到T4只剩下半个小时了,推T3推累了,就连想都没想就输出了个样例!!!
后来发现XIN-team算法还是很厉害的!!!(还有45pts呢。。。。)
还是时间分配有问题,下次考试一定要注意

下面是正解时间
当当当当~~~~~~有请fengwu同学为我们讲解这一套题他的思路
(据说这套题是学长出的哦)
T1 随
上来一看还是挺简单的,一个循环,暴力乘一下,也就O(nlogm)的复杂度,没想到是错的。。。
考完之后去看题解,原来是转移概率,知道了这个以后,我就开开心心的去写方程式了
写出来f[i][j]表示第 i 次乘法得到 j 的概率,然后写完了之后,我就去转移
可是考虑到m的范围过大,复杂度里要是加个m,那就必炸,,然后我就不会,就又去颓题解
题解说可以用矩阵乘
矩阵乘!!!好东西,观察式子,先不考虑操作次数,那么每次转移,都是f[ j ]转移到f[ j *a[k] ](a就是题目中的输入的数)(建议这里自己手玩一下,我弄了好长时间)
这样的话把他们两个放到一起,我们得到了一个矩阵,设他为mul[ i ][ j ]由刚才的转移我们知道mul[ j ][ j*a[k] ]+=1/n;
如果你稍微对矩阵乘法有一点点了解的话,那这里一定很好理解
循环每一个a,这样我们就可以得到一mod*mod的矩阵(因为所有的结果都要%mod,所以只可能有mod种结果,其实0转移不转移都没意思,反正全是零)
题解说这样可以拿80pts,可是我交上去只有20pts
没事继续干正解
考试的时候看到原根,就感觉这玩意没啥用,估计是一不小心放在这里的,就掠过了(就算略不过,也不会用)
接着上面的思路,利用矩阵乘,我们得到了一个O(mod*mod*mod*logm)的算法,还是不够,搬原根
对质数p的原根来说,rt的0~n-2(1~n-1也一样)次方可以取遍所有的1~n-1个数
那么原来的j就可以表示成原根形式,j*a[k]也可以,然后指数就变成了相加
j=rtw[j] ; a[k]=rtw[a[k]] ; j*a[k]=rtw[j*a[k]] ; j*a[k]=j * a[k]=rtw[j]*rtw[a[k]]=rtw[j]+w[a[k]]
这样原来的矩阵就变成了加法,然后加法就变成了二维,时间复杂度降到了O(mod*mod*logm)可以过掉本题
矩阵的时候一定得清零啊要不然会一直WA
关于原根怎么求
对于1~p中非原根的数,他的1~p-2次方中必定有1,然后就会出现循环节,而此循环节的长度又一定是p-1的因数;
那么我们可以枚举对于p-1的每一个质因数,然后p-1除以这个质因数得到一个p-1的因数
然后外层循环枚举1-p的所有数,判断有没有1的出现就ok了
最后乘起来就好了
(注意代码中num->a , h->mod , mod->1e9+7 )


#include<bits/stdc++.h>
using namespace std;
#define re register int
#define ll long long
const int mod=1e9+7;
const int N=100005;
int n,m,h;
int num[N];
int sum[N];
int prt,pos[N];
struct ac{
int a[1005];
friend ac operator*(ac x,ac y){
ac z;memset(z.a,0,sizeof(z.a));
//cout<<"sb"<<endl;
for(re i=0;i<h;i++)
for(re j=0;j<h;j++)
z.a[(i+j)%(h-1)]=(1ll*z.a[(i+j)%(h-1)]+1ll*x.a[i]*y.a[j]%mod)%mod;
return z;
}
}mul;
int ksm(int x,int y,int p){
int ret=1;
while(y){
if(y&1)ret=1ll*ret*x%p;
x=1ll*x*x%p;
y>>=1;
}
return ret;
}
ac ksn(ac x,int y){
ac ret;
memset(ret.a,0,sizeof(ret.a));
ret.a[0]=1;
while(y){
if(y&1)ret=ret*x;
x=x*x;
y>>=1;
}
return ret;
}
void get_prt(){
int sdk[N],tp=0;
int tmp=h-1;
for(re i=2;i*i<h;i++){
if(tmp%i==0){
sdk[++tp]=i;
while(tmp%i==0)tmp/=i;
}
}
if(tmp>1)sdk[++tp]=tmp;
for(re i=2;i<=h;i++){
int pd=0;
for(re j=1;j<=tp;j++){
if(ksm(i,(h-1)/sdk[j],h)==1){
pd=1;break;
}
}
if(pd==0){
prt=i;break;
}
}
for(re i=1;i<h-1;i++)pos[ksm(prt,i,h)]=i;
}
signed main(){
scanf("%lld%lld%lld",&n,&m,&h);
for(re i=1;i<=n;i++){
scanf("%lld",&num[i]);
sum[num[i]]++;
}
get_prt();
int mi=ksm(n,mod-2,mod);
for(re i=1;i<h;i++)mul.a[pos[i]]=1ll*sum[i]*mi%mod;
mul=ksn(mul,m);
ll ans=0;
for(re i=1;i<h;i++){
ans=(ans+1ll*i*mul.a[pos[i]]%mod)%mod;
}
printf("%lld",ans);
}
T1
然后就干完了T1
T2 单

刚看到这题我就觉得简单,嘿嘿,第一步不就n2直接上嘛
第二步不就是高斯消元吗,just-so-so,打完就跑,考完一看30pts
以为搞到了正解结果是个连暴力都算不上的暴力
我们先看第一问,给a求b
这个好说,就先不要求那个dis了,听说有人连dijstra都用上了
这样,考虑由一个点的b转移到与他相连的另一个点的b
我们设siz[i]为i的子树的权值和
那么转移时,改变的值就是这条边的两边的所有点的权值和
咱们脑子里想一想,其中一端一定是子树和,那么另一端就是siz[1]-siz[i];
现在第一种几乎已经解决了,b[son]-b[fa]=siz[1]-2*siz[son];
有这个式子,我们还需要b[1],因为他没有爹啊
但b[1]恰恰是最好求的,b[1]=siz[2]+siz[3]+siz[4]+...+siz[n];
这个式子很好想,每一个点要乘上他的距离,而这个距离在加的过程中变成了它的个数
然后我们就成功的把第一问解决掉了
-------------------------------------------------------------------------------------------------------------------------------------------
接下来是第二问,给你b求a
这个稍稍有一些难度,现在我们已经有了一个式子b[son]-b[fa]=siz[1]-2*siz[son];
我们可以根据b求出这些来,那么只要知道siz[1]就一切都解决了
siz[1]怎么求呢??
刚才还有一个式子b[1]=siz[2]+siz[3]+siz[4]+...+siz[n];
有没有恍然大悟的感觉?!直接吧上面b[son]-b[fa]=siz[1]-2*siz[son]这个式子求个和,就是把n-1对父子的b相减得到的值再相加
就得到了(n-1)*siz[1]-2*(siz[2]+siz[3]+siz[4]+...+siz[n])=tot(tot=上面的式子加和)
换一下(n-1)*siz[1]-2*b[1]=tot;
问题就迎刃而解了吧
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define re register int
const int N=1e5+10;
int T,n;
int to[N*2],nxt[N*2],head[N*2],rp;
int typ,a[N],b[N];
int dep[N],siz[N],tot;
void clear(){
rp=0;
memset(head,0,sizeof(head));
}
void add_edg(int x,int y){
to[++rp]=y;
nxt[rp]=head[x];
head[x]=rp;
}
void dfs0(int x,int f){
siz[x]=0;
siz[x]+=a[x];
for(re i=head[x];i;i=nxt[i]){
if(to[i]==f)continue;
dep[to[i]]=dep[x]+1;
dfs0(to[i],x);
siz[x]+=siz[to[i]];
}
}
void dfs1(int x,int f){
for(re i=head[x];i;i=nxt[i]){
if(to[i]==f)continue;
b[to[i]]=b[x]+siz[1]-2*siz[to[i]];
dfs1(to[i],x);
}
}
void dfs2(int x,int f){
for(re i=head[x];i;i=nxt[i]){
if(to[i]==f)continue;
tot+=b[to[i]]-b[x];
dfs2(to[i],x);
}
}
void dfs3(int x,int f){
for(re i=head[x];i;i=nxt[i]){
if(to[i]==f)continue;
siz[to[i]]=(siz[1]+b[x]-b[to[i]])/2;
if(x!=1)siz[x]-=siz[to[i]];
dfs3(to[i],x);
}
}
signed main(){
scanf("%lld",&T);
while(T--){
clear();
scanf("%lld",&n);
for(re i=1;i<n;i++){
int x,y;
scanf("%lld%lld",&x,&y);
add_edg(x,y);
add_edg(y,x);
}
scanf("%lld",&typ);
if(typ==0){
memset(b,0,sizeof(b));
for(re i=1;i<=n;i++)scanf("%lld",&a[i]);
dep[1]=0;dfs0(1,1);
for(re i=1;i<=n;i++)b[1]+=a[i]*dep[i];
dfs1(1,1);
for(re i=1;i<=n;i++)printf("%lld ",b[i]);
printf("\n");
}
else{
tot=0;
memset(siz,0,sizeof(siz));
for(re i=1;i<=n;i++)scanf("%lld",&b[i]);
dfs2(1,1);
siz[1]=(tot+2*b[1])/(n-1);
dfs3(1,1);
for(re i=2;i<=n;i++)siz[1]-=siz[i];
for(re i=1;i<=n;i++)printf("%lld ",siz[i]);
printf("\n");
}
}
}
T2
那么我们就去看T3题
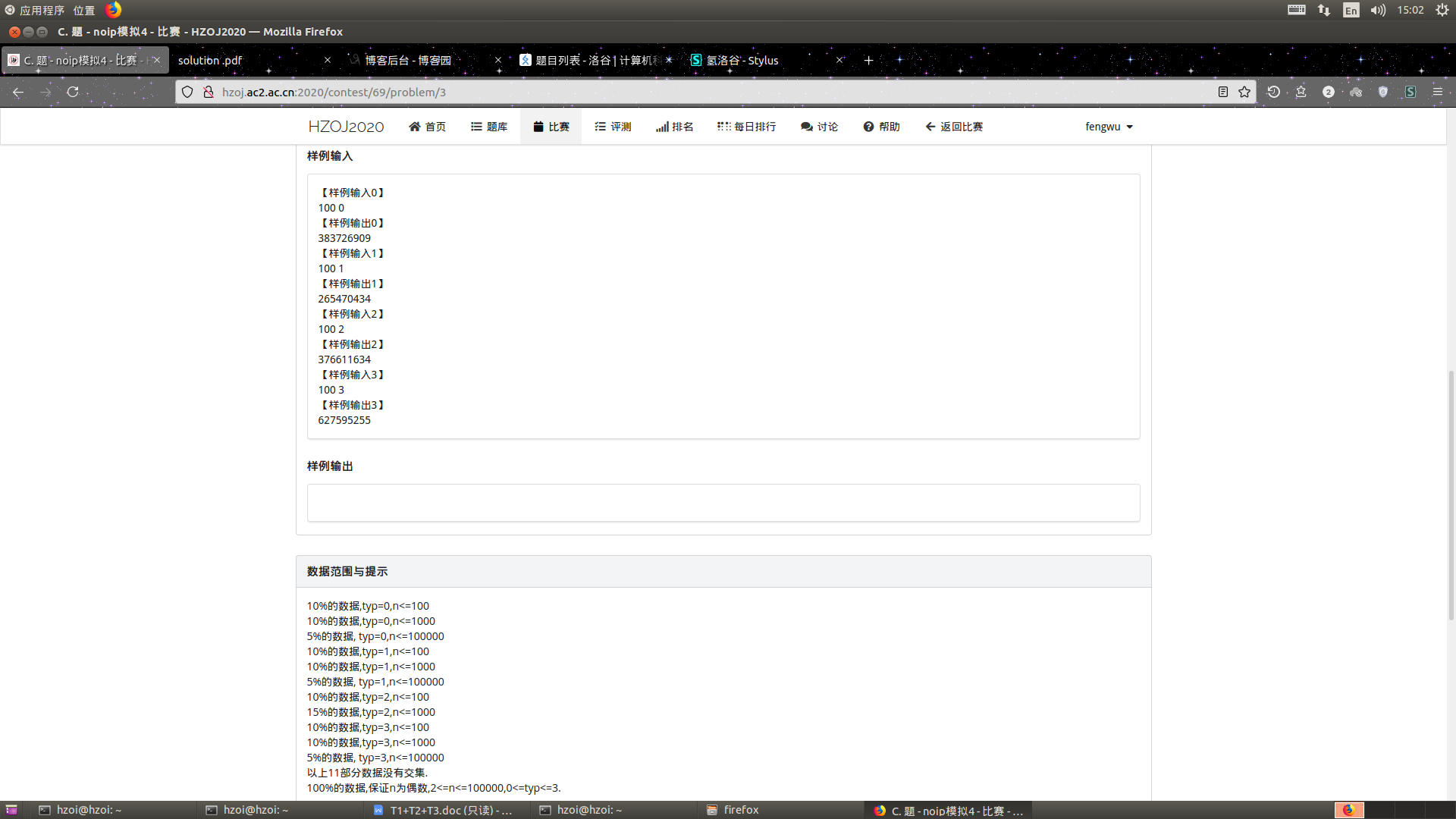
这应该是四个题里面最简单的一个啦
我们直接分情况讨论
typ=0,因为我们不知道出去之后要去哪,因为没有限制,但是吧他肯定得回来
所以向上和向下一定是相同的,向左和向右一定是相同的(这也是为什么n严格保证是偶数)
我那知道他是竖着走还是横着走,---那就枚举呗
我们枚举竖着走了i步,那么在竖着的方向上走的方案有C(i,i/2),横着就有C(n-i,(n-i)/2)
最后乘上组合数C(n,i)因为你不知道是啥时候竖着啥时候横着
typ=1,这直接就是一个卡特兰数,就不说了吧
就肯定得回来,就是进栈出栈的问题,前缀和肯定大于等于0,卡特兰数嘛!!!
typ=2,这个有点难度哦,不对不对你发现这没法直接用卡特兰数,那我们就设计dp呗
设dp[i]表示走了i步,然后第i步回到了原点,因为我们不知道啥时候还回来过,所以要乘一个特殊的卡特兰数
我们要从上一次回来的时候转移,所以这中间不能再回来,所以我们就先走出去一步,然后走卡特兰数,再走回来,所以这时候的卡特兰数参数要-1
转移就好了
对对对还有×4,毕竟有四个方向可以走啊
typ=3,这个和第一个比较类似但是他不能去负的地方,所以就是卡特兰数相乘
然后再乘上C(n,i)
完美解决
#include<bits/stdc++.h>
using namespace std;
#define re register int
#define ll long long
const int N=100005;
const int mod=1e9+7;
int n,typ;
ll jc[N];
ll dp[N];
ll ksm(ll x,ll y){
ll ret=1;
while(y){
if(y&1)ret=ret*x%mod;
x=x*x%mod;
y>>=1;
}
return ret;
}
ll C(int x,int y){
if(x==0||y==0)return 1;
return 1ll*jc[x]*ksm(jc[y],mod-2)%mod*ksm(jc[x-y],mod-2)%mod;
}
ll cat(int x){
return 1ll*C(x<<1,x)*ksm(x+1,mod-2)%mod;
}
signed main(){
scanf("%d%d",&n,&typ);
jc[0]=jc[1]=1;
for(re i=2;i<=2*n+2;i++)jc[i]=1ll*jc[i-1]%mod*i%mod;
ll ans=0;
if(typ==0){
for(re i=0;i<=n;i+=2){
ans=(ans+C(n,i)*C(i,i>>1)%mod*C(n-i,n-i>>1)%mod)%mod;
}
}
if(typ==1){
ans=cat(n>>1);
}
if(typ==2){
dp[0]=1;
for(re i=2;i<=n;i+=2){
for(re j=2;j<=i;j+=2){
dp[i]=(1ll*dp[i]+dp[i-j]*4%mod*cat(j/2-1)%mod)%mod;
}
}
ans=dp[n];
}
if(typ==3){
for(re i=0;i<=n;i+=2){
ans=(ans+C(n,i)*cat(i>>1)%mod*cat(n-i>>1)%mod)%mod;
}
}
printf("%lld",ans);
}
T3
T4大佬
我是脑残吗我最后一题连暴力都不打就走,输出样例就走了



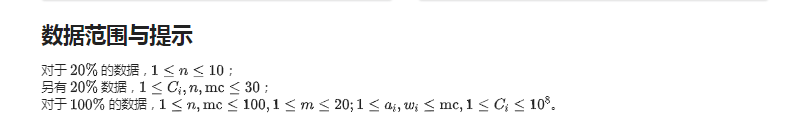
说实话看到题解的时候我蒙了一会
但是还是想明白了
你死不死只跟大佬嘲讽你和刷题有关
所以我们可以去dp了
找到可以利用的最多的天数D
然后暴搜,找到所有的二元组,打出的攻击+所需的天数
这里用到了一个hash其实没啥用就是快点
然后就完了
我们可以一下把大佬搞死,也可以两下,然后要打到他的血比我剩余的时间少,但是比打出的伤害多
然后看代码吧
#include<bits/stdc++.h>
using namespace std;
#define re register int
const int N=105;
const int mod=1e6+9;
int n,m,mc;
int a[N],w[N],c[N],mx;
int f[N][N];
int D,cnt;
pair<int,int> zt[N*N*N];
struct node{
int day,fi,li;
};
struct hash{
struct link{
int x,y,nxt;
}e[N*N*N];
int head[N*N*N],rp;
void ins(int x,int y){
int tmp=(1ll*x*131+y)%mod;
e[++rp]=(link){x,y,head[tmp]};
head[tmp]=rp;
}
bool query(int x,int y){
int tmp=(1ll*x*131+y)%mod;
for(re i=head[tmp];i;i=e[i].nxt){
if(e[i].x==x&&e[i].y==y)return false;
}
return true;
}
}ma;
void bfs(){
queue<node> q;
q.push((node){1,1,0});
while(!q.empty()){
node x=q.front();
q.pop();
if(x.day==D)continue;
q.push((node){x.day+1,x.fi,x.li+1});
if(x.li>1&&1ll*x.fi*x.li<=1ll*mx&&ma.query(x.fi*x.li,x.day+1)){
q.push((node){x.day+1,x.fi*x.li,x.li});
zt[++cnt]=(pair<int,int>){x.fi*x.li,x.day+1};
ma.ins(x.fi*x.li,x.day+1);
}
}
}
signed main(){
scanf("%d%d%d",&n,&m,&mc);
for(re i=1;i<=n;i++)scanf("%d",&a[i]);
for(re i=1;i<=n;i++)scanf("%d",&w[i]);
for(re i=1;i<=m;i++){
scanf("%d",&c[i]);
mx=max(mx,c[i]);
}
for(re i=1;i<=n;i++){
for(re j=a[i];j<=mc;j++){
f[i][j-a[i]]=max(f[i][j-a[i]],f[i-1][j]+1);
f[i][min(j-a[i]+w[i],mc)]=max(f[i][min(j-a[i]+w[i],mc)],f[i-1][j]);
}
}
for(re i=1;i<=n;i++){
for(re j=0;j<=mc;j++){
D=max(D,f[i][j]);
}
}
bfs();
sort(zt+1,zt+cnt+1);
for(re i=1;i<=m;i++){
if(c[i]<=D){
puts("1");
continue;
}
int pd=0,mi=0x3f3f3f3f;
for(re j=cnt,k=1;j>=1;j--){
while(k<cnt&&zt[k].first+zt[j].first<=c[i])
mi=min(mi,zt[k].second-zt[k].first),k++;
if(mi+zt[j].second-zt[j].first+c[i]<=D){pd=1;break;}
if(zt[j].first<=c[i]&&c[i]-zt[j].first+zt[j].second<=D){pd=1;break;}
}
printf("%d\n",pd);
}
}
T4
完结啦
在一次次考试中提升

noip模拟4[随·单·题·大佬]的更多相关文章
- noip模拟23[联·赛·题]
\(noip模拟23\;solutions\) 怎么说呢??这个考试考得是非常的惨烈,一共拿了70分,为啥呢 因为我第一题和第三题爆零了,然后第二题拿到了70分,还是贪心的分数 第一题和第二题我调了好 ...
- noip模拟35[第一次4题·裂了]
noip模拟35 solutions 这是我第一次这么正式的考四个题,因为这四个题都出自同一个出题人,并不是拼盘拼出来的. 但是考得非常的不好,因为题非常难而且一直想睡觉.. 有好多我根本就不会的算法 ...
- noip模拟6[辣鸡·模板·大佬·宝藏]
这怕不是学长出的题吧 这题就很迷 这第一题吧,正解竟然是O(n2)的,我这是快气死了,考场上一直觉得aaaaa n2过不了过不了, 我就去枚举边了,然后调了两个小时,愣是没调出来,然后交了个暴力,就走 ...
- Noip模拟考第三题——饥饿游戏
饥饿游戏 (hungry.pas/c/cpp) [问题描述] Chanxer饿了,但是囊中羞涩,于是他去参加号称免费吃到饱的“饥饿游戏”. 这个游戏的规则是这样的,举办者会摆出一排 个食物,希望你能够 ...
- NOIP 模拟 $13\; \text{玄学题}$
题解 题如其名,是挺玄学的. 我们发现每个值是 \(-1\) 还是 \(1\) 只与它的次数是奇是偶有关,而 \(\sum_j^{j\le m}d(i×j)\) 又只与其中有多少个奇数有关 对于 \( ...
- NOIP 模拟 $13\; \text{工业题}$
题解 本题不用什么推式子,找规律(而且也找不出来) 可以将整个式子看成一个 \(n×m\) 矩阵 考虑 \(f_{i,j}\),它向右走一步给出 \(f_{i,j}×a\) 的贡献,向下走一步给出 \ ...
- NOIP模拟13「工业题·卡常题·玄学题」
T1:工业题 基本思路 这题有一个重要的小转化: 我们将原来的函数看作一个矩阵,\(f(i,j-1)*a\)相当于从\(j-1\)向右走一步并贡献a,\(f(i-1,j)*b\)相当于从\(i-1 ...
- 5.23考试总结(NOIP模拟2)
5.23考试总结(NOIP模拟2) 洛谷题单 看第一题第一眼,不好打呀;看第一题样例又一眼,诶,我直接一手小阶乘走人 然后就急忙去干T2T3了 后来考完一看,只有\(T1\)骗到了\(15pts\)[ ...
- noip模拟26[肾炎黄·酱累黄·换莫黄]
\(noip模拟26\;solutions\) 这个题我做的确实是得心应手,为啥呢,因为前两次考试太难了 T1非常的简单,只不过我忘记了一个定理, T2就是一个小小的线段树,虽然吧我曾经说过我再也不写 ...
随机推荐
- 1079 Total Sales of Supply Chain
A supply chain is a network of retailers(零售商), distributors(经销商), and suppliers(供应商)-- everyone invo ...
- Tomcat容器、JSP和Servlet
目录 JSP Tomcat.JSP和Servlet JSP JSP全名为Java Server Pages,其根本是一个简化的Servlet设计.JSP技术有点类似ASP技术,它是在传统的HTML网页 ...
- Run-Time Check Failure #0,The value of ESP was not properly saved 错误解决
调用DLL函数,出现错误 Run-Time Check Failure #0 - The value of ESP was not properly saved across a function c ...
- 【Github搬砖】Python入门网络爬虫之精华版
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scrapy,这里最后也详细介绍一下. 首先列举一下本人总结的相关文章,这些覆盖了入门网络爬虫需要的基本概念和技巧 ...
- Root mapping definition has unsupported parameters
使用ElasticSearch创建映射报错 Root mapping definition has unsupported parameters 原因 使用的ES版本为7.2.0,不再支持创建指定类型 ...
- Ubuntu20.04连接WiFi
电脑安装了Ubuntu20.04后发现没办法连接WiFi,也找不到WiFi图标,一般来说是因为Ubuntu系统没有网卡驱动,安装一下即可 解决办法如下: 先用网线或者手机开热点连接到到电脑,让电脑有网 ...
- 源码简析XXL-JOB的注册和执行过程
一,前言 XXL-JOB是一个优秀的国产开源分布式任务调度平台,他有着自己的一套调度注册中心,提供了丰富的调度和阻塞策略等,这些都是可视化的操作,使用起来十分方便. 由于是国产的,所以上手还是比较快的 ...
- mysql.data.entityframeworkcore 已弃用
转官网有方案: https://dev.mysql.com/doc/connector-net/en/connector-net-entityframework-core.html General R ...
- .NET Core 对象( Transient、Scope、Singleton )生命周期详解 (对象创建以及释放)
首先我们在VS2019中创建一个.NET Core的控制台程序,方便演示: 需要安装两个依赖包 Microsoft.Extensions.DependencyInjection 依赖注入对象的具体实现 ...
- CVPR2021| TimeSformer-视频理解的时空注意模型
前言: transformer在视频理解方向的应用主要有如下几种实现方式:Joint Space-Time Attention,Sparse Local Global Attention 和Axial ...