Calcite(一):javacc语法框架及使用
是一个动态数据管理框架。 它包含许多组成典型数据库管理系统的部分,但省略了存储原语。它提供了行业标准的SQL解析器和验证器,具有可插入规则和成本函数的可自定义优化器,逻辑和物理代数运算符,从SQL到代数(以及相反)的各种转换。
以上是官方描述,用大白话描述就是,calcite实现了一套标准的sql解析功能,比如实现了标准hive sql的解析,可以避免繁杂且易出错的语法问题。并暴露了相关的扩展接口供用户自定义使用。其提供了逻辑计划修改功能,用户可以实现自己的优化。(害,好像还是很绕!不管了)
1. calcite的两大方向
从核心功能上讲,或者某种程度上讲,我们可以将calicite分为两大块,一块是对sql语法的解析,另一块是对语义的转化与实现;
为什么要将其分为几块呢?我们知道,基本上所有的分层,都是为了简化各层的逻辑。如果我们将所有的逻辑全放在一个层上,必然存在大量的耦合,互相嵌套,很难实现专业的人做专业的事。语法解析,本身是一件比较难的事情,但是因为有很多成熟的编译原理理论支持,所以,这方面有许多现成的实现可以利用,或者即使是自己单独实现这一块,也不会有太大麻烦。所以,这一层是一定要分出来的。
而对语义的转化与实现,则是用户更关注的一层,如果说前面的语法是标准规范的话,那么语义才是实现者最关心的东西。规范是为了减轻使用者的使用难度,而其背后的逻辑则可能有天壤之别。当有了前面的语法解析树之后,再来进一步处理语义的东西,必然方便了许多。但也必定是个复杂的工作,因为上下文关联语义,并不好处理。
而我们本篇只关注语法解析这一块功能,而calcite使用javacc作为其语法解析器,所以我们自然主关注向javacc了。与javacc类似的,还有antlr,这个留到我们后面再说。
calcite中,javacc应该属于一阶段的编译,而java中引入javacc编译后的样板代码,再执行自己的逻辑,可以算作是二阶段编译。我们可以简单的参考下下面这个图,说明其意义。
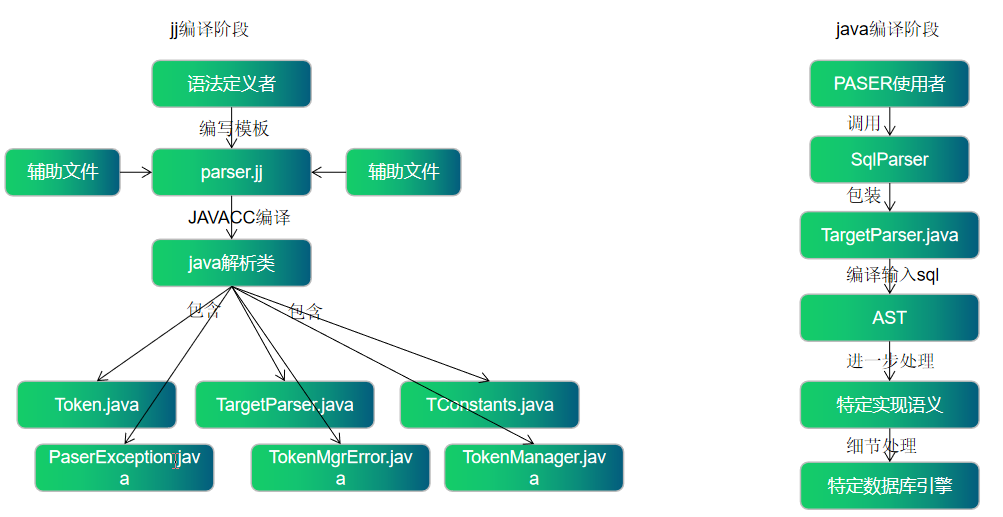
2. javacc的语法框架
本文仅站在一个使用者的角度来讲解javacc, 因为javacc本身必然是复杂的难以讲清的, 而且如果想要细致了解javacc则肯定是需要借助官网的。
首先,来看下javacc的编码框架:
javacc_options /* javacc 的各种配置选项设置,需了解具体配置含义后以kv形式配置 */
"PARSER_BEGIN" "(" <IDENTIFIER> ")" /* parser代码开始定义,标识下面的代码是纯粹使用java编写的 */
java_compilation_unit /* parser的入口代码编写,纯java, 此处将决定外部如何调用parser */
"PARSER_END" "(" <IDENTIFIER> ")" /* parser代码结束标识,javacc将会把以上代码纯粹当作原文copy到parser中 */
( production )* /* 各种语法产生式,按照编译原理的类似样子定义语法产生式,由javacc去分析具体代码逻辑,嵌入到parser中,该部分产生式代码将被编译到上面的parser中,所以方法可以完全供parser调用 */
<EOF> /* 文件结束标识 */
以上就是javacc的语法定义的框架了,它是一个整个的parser.jj文件。即这个文件只要按照这种框架写了,然后调用javacc进行编译后,可以得到一系列的编译器样板代码了。
但是,如何去编写去编写这些语法呢?啥都不知道,好尴尬。不着急,且看下一节。
3. javacc中的关键词及使用
之所以我们无从下手写javacc的jj文件,是因为我们不知道有些什么关键词,以及没有给出一些样例。主要熟能生巧嘛。
javacc中的关键词非常的少,一个是因为这种词法解析器的方法论是非常成熟的,它可以按照任意的语法作出解析。二一个是它不负责太多的业务实现相关的东西,它只管理解语义,翻译即可。而它其中仅有的几个关键词,也还有一些属于辅助类的功能。真正必须的关键词就更少了。列举如下:
TOKEN /* 定义一些确定的普通词或关键词,主要用于被引用 */
SPECIAL_TOKEN /* 定义一些确定的特殊用途的普通词或关键词,主要用于被引用或抛弃 */
SKIP /* 定义一些需要跳过或者忽略的单词或短语,主要用于分词或者注释 */
MORE /* token的辅助定义工具,用于确定连续的多个token */
EOF /* 文件结束标识或者语句结束标识 */
IGNORE_CASE /* 辅助选项,忽略大小写 */
JAVACODE /* 辅助选项,用于标识本段代码是java */
LOOKAHEAD /* 语法二义性处理工具,用于预读多个token,以便明确语义 */
PARSER_BEGIN /* 样板代码,固定开头 */
PARSER_END /* 样板代码,固定结尾 */
TOKEN_MGR_DECLS /* 辅助选项 */
有了这些关键词的定义,我们就可以来写个hello world 了。其主要作用就是验证语法是否是 hello world.
options {
STATIC = false;
ERROR_REPORTING = true;
JAVA_UNICODE_ESCAPE = true;
UNICODE_INPUT = false;
IGNORE_CASE = true;
DEBUG_PARSER = false;
DEBUG_LOOKAHEAD = false;
DEBUG_TOKEN_MANAGER = false;
}
PARSER_BEGIN(HelloWorldParser)
package my;
import java.io.FileInputStream;
/**
* hello world parser
*/
@SuppressWarnings({"nls", "unused"})
public class HelloWorldParser {
/**
* 测试入口
*/
public static void main( String args[] ) throws Throwable {
// 编译器会默认生成构造方法
String sqlFilePath = args[0];
final HelloWorldParser parser = new HelloWorldParser(new FileInputStream(sqlFilePath));
try {
parser.hello();
} catch(Throwable t) {
System.err.println(":1: not parsed");
t.printStackTrace();
return;
}
System.out.println("ok");
}
public void hello () throws ParseException {
helloEof();
}
} // end class
PARSER_END(HelloWorldParser)
void helloEof() :
{}
{
// 匹配到hello world 后,打印文字,否则抛出异常
(
<HELLO>
|
"HELLO2"
)
<WORLD>
{ System.out.println("ok to match hello world."); }
}
TOKEN :
{
<HELLO: "hello">
| <WORLD: "world">
}
SKIP:
{
" "
| "\t"
| "\r"
| "\n"
}
命名为 hello.jj, 运行 javacc 编译该jj文件。
> javacc hello.jj
> javac my/*.java
> java my.HelloWorldParser
4. javacc中的编译原理
javacc作为一个词法解析器,其主要作用是提供词法解析功能。当然,只有它自己知道词是不够的,它还有一个非常重要的功能,能够翻译成java语言(不止java)的解析器,这样用户就可以调用这些解析器进行业务逻辑实现了。所以,从某种角度上说,它相当于是一个脚手架,帮我们生成一些模板代码。
词法解析作为一个非常通用的话题,各种大牛科学家们,早就总结出非常多的方法论的东西了。即编译原理。但要想深入理解其理论,还是非常难的,只能各自随缘了。随便列举几个名词,供大家参考:
产生式
终结符与非终结符,运算分量
预测分析法,左递归,回溯,上下文无关
DFA, NFA, 正则匹配,模式,kmp算法,trie树
附加操作,声明
LL, LR, 二义性
词法
语法
可以说,整个javacc就是编译原理的其中一小部分实现。当然了,我们平时遇到编译的地方非常多,因为我们所使用的语言,都需要被编译成汇编或机器语言,才能被执行,比如javacc, gcc...。所以,编译原理无处不在。
这里,我们单说jj文件如何被编译成java文件?总体上,大的原理就按照编译原理来就好了。我们只说一些映射关系。
"a" "b" -> 代表多个连续token
| -> 对应if或者switch语义
(..)* -> 对应while语义
["a"] -> 对应if语句,可匹配0-1次
(): {} -> 对应语法的产生式
{} -> 附加操作,在匹配后嵌入执行
<id> 对应常量词或容易描述的token描述
javacc 默认会生成几个辅助类:
XXConstants: 定义一些常量值,比如将TOKEN定义的值转换为一个个的数字;
HelloWorldParserTokenManager: token管理器, 用于读取token, 可以自定义处理;
JavaCharStream: CharStream的实现,会根据配置选项生成不同的类;
ParseException: 解析错误时抛出的类;
Token: 读取到的单词描述类;
TokenMgrError: 读取token错误时抛出的错误;
具体看下javacc中有些什么选项配置,请查看官网。https://javacc.github.io/javacc/documentation/grammar.html#javacc-options
从编写代码的角度来说,我们基本上只要掌握基本的样板格式和正则表达式就可以写出javacc的语法了。如果想要在具体的java代码中应用,则需要自己组织需要的语法树结构或其他了。
5. javacc 编译实现源码解析
javacc本身也是用java写的,可读性还是比较强的。我们就略微扫一下吧。它的仓库地址: https://github.com/javacc/javacc
其入口在: src/main/java/org/javacc/parser/Main.java
/**
* A main program that exercises the parser.
*/
public static void main(String args[]) throws Exception {
int errorcode = mainProgram(args);
System.exit(errorcode);
} /**
* The method to call to exercise the parser from other Java programs.
* It returns an error code. See how the main program above uses
* this method.
*/
public static int mainProgram(String args[]) throws Exception { if (args.length == 1 && args[args.length -1].equalsIgnoreCase("-version")) {
System.out.println(Version.versionNumber);
return 0;
} // Initialize all static state
reInitAll(); JavaCCGlobals.bannerLine("Parser Generator", ""); JavaCCParser parser = null;
if (args.length == 0) {
System.out.println("");
help_message();
return 1;
} else {
System.out.println("(type \"javacc\" with no arguments for help)");
} if (Options.isOption(args[args.length-1])) {
System.out.println("Last argument \"" + args[args.length-1] + "\" is not a filename.");
return 1;
}
for (int arg = 0; arg < args.length-1; arg++) {
if (!Options.isOption(args[arg])) {
System.out.println("Argument \"" + args[arg] + "\" must be an option setting.");
return 1;
}
Options.setCmdLineOption(args[arg]);
} try {
java.io.File fp = new java.io.File(args[args.length-1]);
if (!fp.exists()) {
System.out.println("File " + args[args.length-1] + " not found.");
return 1;
}
if (fp.isDirectory()) {
System.out.println(args[args.length-1] + " is a directory. Please use a valid file name.");
return 1;
}
// javacc 本身也使用的语法解析器生成 JavaCCParser, 即相当于自依赖咯
parser = new JavaCCParser(new java.io.BufferedReader(new java.io.InputStreamReader(new java.io.FileInputStream(args[args.length-1]), Options.getGrammarEncoding())));
} catch (SecurityException se) {
System.out.println("Security violation while trying to open " + args[args.length-1]);
return 1;
} catch (java.io.FileNotFoundException e) {
System.out.println("File " + args[args.length-1] + " not found.");
return 1;
} try {
System.out.println("Reading from file " + args[args.length-1] + " . . .");
// 使用静态变量来实现全局数据共享
JavaCCGlobals.fileName = JavaCCGlobals.origFileName = args[args.length-1];
JavaCCGlobals.jjtreeGenerated = JavaCCGlobals.isGeneratedBy("JJTree", args[args.length-1]);
JavaCCGlobals.toolNames = JavaCCGlobals.getToolNames(args[args.length-1]);
// javacc 语法解析入口
// 经过解析后,它会将各种解析数据放入到全局变量中
parser.javacc_input(); // 2012/05/02 - Moved this here as cannot evaluate output language
// until the cc file has been processed. Was previously setting the 'lg' variable
// to a lexer before the configuration override in the cc file had been read.
String outputLanguage = Options.getOutputLanguage();
// TODO :: CBA -- Require Unification of output language specific processing into a single Enum class
boolean isJavaOutput = Options.isOutputLanguageJava();
boolean isCPPOutput = outputLanguage.equals(Options.OUTPUT_LANGUAGE__CPP); // 2013/07/22 Java Modern is a
boolean isJavaModern = isJavaOutput && Options.getJavaTemplateType().equals(Options.JAVA_TEMPLATE_TYPE_MODERN); if (isJavaOutput) {
lg = new LexGen();
} else if (isCPPOutput) {
lg = new LexGenCPP();
} else {
return unhandledLanguageExit(outputLanguage);
} JavaCCGlobals.createOutputDir(Options.getOutputDirectory()); if (Options.getUnicodeInput())
{
NfaState.unicodeWarningGiven = true;
System.out.println("Note: UNICODE_INPUT option is specified. " +
"Please make sure you create the parser/lexer using a Reader with the correct character encoding.");
}
// 将词法解析得到的信息,重新语义加强,构造出更连贯的上下文信息,供后续使用
Semanticize.start();
boolean isBuildParser = Options.getBuildParser(); // 2012/05/02 -- This is not the best way to add-in GWT support, really the code needs to turn supported languages into enumerations
// and have the enumerations describe the deltas between the outputs. The current approach means that per-langauge configuration is distributed
// and small changes between targets does not benefit from inheritance.
if (isJavaOutput) {
if (isBuildParser) {
// 1. 生成parser框架信息
new ParseGen().start(isJavaModern);
} // Must always create the lexer object even if not building a parser.
// 2. 生成语法解析信息
new LexGen().start();
// 3. 生成其他辅助类
Options.setStringOption(Options.NONUSER_OPTION__PARSER_NAME, JavaCCGlobals.cu_name);
OtherFilesGen.start(isJavaModern);
} else if (isCPPOutput) { // C++ for now
if (isBuildParser) {
new ParseGenCPP().start();
}
if (isBuildParser) {
new LexGenCPP().start();
}
Options.setStringOption(Options.NONUSER_OPTION__PARSER_NAME, JavaCCGlobals.cu_name);
OtherFilesGenCPP.start();
} else {
unhandledLanguageExit(outputLanguage);
} // 编译结果状态判定,输出
if ((JavaCCErrors.get_error_count() == 0) && (isBuildParser || Options.getBuildTokenManager())) {
if (JavaCCErrors.get_warning_count() == 0) {
if (isBuildParser) {
System.out.println("Parser generated successfully.");
}
} else {
System.out.println("Parser generated with 0 errors and "
+ JavaCCErrors.get_warning_count() + " warnings.");
}
return 0;
} else {
System.out.println("Detected " + JavaCCErrors.get_error_count() + " errors and "
+ JavaCCErrors.get_warning_count() + " warnings.");
return (JavaCCErrors.get_error_count()==0)?0:1;
}
} catch (MetaParseException e) {
System.out.println("Detected " + JavaCCErrors.get_error_count() + " errors and "
+ JavaCCErrors.get_warning_count() + " warnings.");
return 1;
} catch (ParseException e) {
System.out.println(e.toString());
System.out.println("Detected " + (JavaCCErrors.get_error_count()+1) + " errors and "
+ JavaCCErrors.get_warning_count() + " warnings.");
return 1;
}
}
以上,就是javacc的编译运行框架,其词法解析仍然靠着自身的jj文件,生成的 JavaCCParser 进行解析:
1. 生成的 JavaCCParser, 然后调用 javacc_input() 解析出词法信息;
2. 将解析出的语法信息放入到全局变量中;
3. 使用Semanticize 将词法语义加强,转换为javacc可处理的结构;
4. 使用ParseGen 生成parser框架信息;
5. 使用LexGen 生成语法描述方法;
6. 使用OtherFilesGen 生成同级辅助类;
下面我们就前面几个重点类,展开看看其实现就差不多了。
5.1. javacc语法定义
前面说了,javacc在编译其他语言时,它自己又定义了一个语法文件,用于第一步的词法分析。可见这功能的普启遍性。我们大致看下入口即可,更多完整源码可查看: src/main/javacc/JavaCC.jj
void javacc_input() :
{
String id1, id2;
initialize();
}
{
javacc_options()
{
}
"PARSER_BEGIN" "(" id1=identifier()
{
addcuname(id1);
}
")"
{
processing_cu = true;
parser_class_name = id1; if (!isJavaLanguage()) {
JavaCCGlobals.otherLanguageDeclTokenBeg = getToken(1);
while(getToken(1).kind != _PARSER_END) {
getNextToken();
}
JavaCCGlobals.otherLanguageDeclTokenEnd = getToken(1);
}
}
CompilationUnit()
{
processing_cu = false;
}
"PARSER_END" "(" id2=identifier()
{
compare(getToken(0), id1, id2);
}
")"
( production() )+
<EOF>
}
...
可以看出,这种语法定义,与说明文档相差不太多,可以说是一种比较接近自然语言的实现了。
5.2. Semanticize 语义处理
Semanticize 将前面词法解析得到数据,进一步转换成容易被理解的语法树或者其他信息。
// org.javacc.parser.Semanticize#start
static public void start() throws MetaParseException { if (JavaCCErrors.get_error_count() != 0) throw new MetaParseException(); if (Options.getLookahead() > 1 && !Options.getForceLaCheck() && Options.getSanityCheck()) {
JavaCCErrors.warning("Lookahead adequacy checking not being performed since option LOOKAHEAD " +
"is more than 1. Set option FORCE_LA_CHECK to true to force checking.");
} /*
* The following walks the entire parse tree to convert all LOOKAHEAD's
* that are not at choice points (but at beginning of sequences) and converts
* them to trivial choices. This way, their semantic lookahead specification
* can be evaluated during other lookahead evaluations.
*/
for (Iterator<NormalProduction> it = bnfproductions.iterator(); it.hasNext();) {
ExpansionTreeWalker.postOrderWalk(((NormalProduction)it.next()).getExpansion(),
new LookaheadFixer());
} /*
* The following loop populates "production_table"
*/
for (Iterator<NormalProduction> it = bnfproductions.iterator(); it.hasNext();) {
NormalProduction p = it.next();
if (production_table.put(p.getLhs(), p) != null) {
JavaCCErrors.semantic_error(p, p.getLhs() + " occurs on the left hand side of more than one production.");
}
} /*
* The following walks the entire parse tree to make sure that all
* non-terminals on RHS's are defined on the LHS.
*/
for (Iterator<NormalProduction> it = bnfproductions.iterator(); it.hasNext();) {
ExpansionTreeWalker.preOrderWalk((it.next()).getExpansion(), new ProductionDefinedChecker());
} /*
* The following loop ensures that all target lexical states are
* defined. Also piggybacking on this loop is the detection of
* <EOF> and <name> in token productions. After reporting an
* error, these entries are removed. Also checked are definitions
* on inline private regular expressions.
* This loop works slightly differently when USER_TOKEN_MANAGER
* is set to true. In this case, <name> occurrences are OK, while
* regular expression specs generate a warning.
*/
for (Iterator<TokenProduction> it = rexprlist.iterator(); it.hasNext();) {
TokenProduction tp = (TokenProduction)(it.next());
List<RegExprSpec> respecs = tp.respecs;
for (Iterator<RegExprSpec> it1 = respecs.iterator(); it1.hasNext();) {
RegExprSpec res = (RegExprSpec)(it1.next());
if (res.nextState != null) {
if (lexstate_S2I.get(res.nextState) == null) {
JavaCCErrors.semantic_error(res.nsTok, "Lexical state \"" + res.nextState +
"\" has not been defined.");
}
}
if (res.rexp instanceof REndOfFile) {
//JavaCCErrors.semantic_error(res.rexp, "Badly placed <EOF>.");
if (tp.lexStates != null)
JavaCCErrors.semantic_error(res.rexp, "EOF action/state change must be specified for all states, " +
"i.e., <*>TOKEN:.");
if (tp.kind != TokenProduction.TOKEN)
JavaCCErrors.semantic_error(res.rexp, "EOF action/state change can be specified only in a " +
"TOKEN specification.");
if (nextStateForEof != null || actForEof != null)
JavaCCErrors.semantic_error(res.rexp, "Duplicate action/state change specification for <EOF>.");
actForEof = res.act;
nextStateForEof = res.nextState;
prepareToRemove(respecs, res);
} else if (tp.isExplicit && Options.getUserTokenManager()) {
JavaCCErrors.warning(res.rexp, "Ignoring regular expression specification since " +
"option USER_TOKEN_MANAGER has been set to true.");
} else if (tp.isExplicit && !Options.getUserTokenManager() && res.rexp instanceof RJustName) {
JavaCCErrors.warning(res.rexp, "Ignoring free-standing regular expression reference. " +
"If you really want this, you must give it a different label as <NEWLABEL:<"
+ res.rexp.label + ">>.");
prepareToRemove(respecs, res);
} else if (!tp.isExplicit && res.rexp.private_rexp) {
JavaCCErrors.semantic_error(res.rexp, "Private (#) regular expression cannot be defined within " +
"grammar productions.");
}
}
} removePreparedItems(); /*
* The following loop inserts all names of regular expressions into
* "named_tokens_table" and "ordered_named_tokens".
* Duplications are flagged as errors.
*/
for (Iterator<TokenProduction> it = rexprlist.iterator(); it.hasNext();) {
TokenProduction tp = (TokenProduction)(it.next());
List<RegExprSpec> respecs = tp.respecs;
for (Iterator<RegExprSpec> it1 = respecs.iterator(); it1.hasNext();) {
RegExprSpec res = (RegExprSpec)(it1.next());
if (!(res.rexp instanceof RJustName) && !res.rexp.label.equals("")) {
String s = res.rexp.label;
Object obj = named_tokens_table.put(s, res.rexp);
if (obj != null) {
JavaCCErrors.semantic_error(res.rexp, "Multiply defined lexical token name \"" + s + "\".");
} else {
ordered_named_tokens.add(res.rexp);
}
if (lexstate_S2I.get(s) != null) {
JavaCCErrors.semantic_error(res.rexp, "Lexical token name \"" + s + "\" is the same as " +
"that of a lexical state.");
}
}
}
} /*
* The following code merges multiple uses of the same string in the same
* lexical state and produces error messages when there are multiple
* explicit occurrences (outside the BNF) of the string in the same
* lexical state, or when within BNF occurrences of a string are duplicates
* of those that occur as non-TOKEN's (SKIP, MORE, SPECIAL_TOKEN) or private
* regular expressions. While doing this, this code also numbers all
* regular expressions (by setting their ordinal values), and populates the
* table "names_of_tokens".
*/ tokenCount = 1;
for (Iterator<TokenProduction> it = rexprlist.iterator(); it.hasNext();) {
TokenProduction tp = (TokenProduction)(it.next());
List<RegExprSpec> respecs = tp.respecs;
if (tp.lexStates == null) {
tp.lexStates = new String[lexstate_I2S.size()];
int i = 0;
for (Enumeration<String> enum1 = lexstate_I2S.elements(); enum1.hasMoreElements();) {
tp.lexStates[i++] = (String)(enum1.nextElement());
}
}
Hashtable table[] = new Hashtable[tp.lexStates.length];
for (int i = 0; i < tp.lexStates.length; i++) {
table[i] = (Hashtable)simple_tokens_table.get(tp.lexStates[i]);
}
for (Iterator<RegExprSpec> it1 = respecs.iterator(); it1.hasNext();) {
RegExprSpec res = (RegExprSpec)(it1.next());
if (res.rexp instanceof RStringLiteral) {
RStringLiteral sl = (RStringLiteral)res.rexp;
// This loop performs the checks and actions with respect to each lexical state.
for (int i = 0; i < table.length; i++) {
// Get table of all case variants of "sl.image" into table2.
Hashtable table2 = (Hashtable)(table[i].get(sl.image.toUpperCase()));
if (table2 == null) {
// There are no case variants of "sl.image" earlier than the current one.
// So go ahead and insert this item.
if (sl.ordinal == 0) {
sl.ordinal = tokenCount++;
}
table2 = new Hashtable();
table2.put(sl.image, sl);
table[i].put(sl.image.toUpperCase(), table2);
} else if (hasIgnoreCase(table2, sl.image)) { // hasIgnoreCase sets "other" if it is found.
// Since IGNORE_CASE version exists, current one is useless and bad.
if (!sl.tpContext.isExplicit) {
// inline BNF string is used earlier with an IGNORE_CASE.
JavaCCErrors.semantic_error(sl, "String \"" + sl.image + "\" can never be matched " +
"due to presence of more general (IGNORE_CASE) regular expression " +
"at line " + other.getLine() + ", column " + other.getColumn() + ".");
} else {
// give the standard error message.
JavaCCErrors.semantic_error(sl, "Duplicate definition of string token \"" + sl.image + "\" " +
"can never be matched.");
}
} else if (sl.tpContext.ignoreCase) {
// This has to be explicit. A warning needs to be given with respect
// to all previous strings.
String pos = ""; int count = 0;
for (Enumeration<RegularExpression> enum2 = table2.elements(); enum2.hasMoreElements();) {
RegularExpression rexp = (RegularExpression)(enum2.nextElement());
if (count != 0) pos += ",";
pos += " line " + rexp.getLine();
count++;
}
if (count == 1) {
JavaCCErrors.warning(sl, "String with IGNORE_CASE is partially superseded by string at" + pos + ".");
} else {
JavaCCErrors.warning(sl, "String with IGNORE_CASE is partially superseded by strings at" + pos + ".");
}
// This entry is legitimate. So insert it.
if (sl.ordinal == 0) {
sl.ordinal = tokenCount++;
}
table2.put(sl.image, sl);
// The above "put" may override an existing entry (that is not IGNORE_CASE) and that's
// the desired behavior.
} else {
// The rest of the cases do not involve IGNORE_CASE.
RegularExpression re = (RegularExpression)table2.get(sl.image);
if (re == null) {
if (sl.ordinal == 0) {
sl.ordinal = tokenCount++;
}
table2.put(sl.image, sl);
} else if (tp.isExplicit) {
// This is an error even if the first occurrence was implicit.
if (tp.lexStates[i].equals("DEFAULT")) {
JavaCCErrors.semantic_error(sl, "Duplicate definition of string token \"" + sl.image + "\".");
} else {
JavaCCErrors.semantic_error(sl, "Duplicate definition of string token \"" + sl.image +
"\" in lexical state \"" + tp.lexStates[i] + "\".");
}
} else if (re.tpContext.kind != TokenProduction.TOKEN) {
JavaCCErrors.semantic_error(sl, "String token \"" + sl.image + "\" has been defined as a \"" +
TokenProduction.kindImage[re.tpContext.kind] + "\" token.");
} else if (re.private_rexp) {
JavaCCErrors.semantic_error(sl, "String token \"" + sl.image +
"\" has been defined as a private regular expression.");
} else {
// This is now a legitimate reference to an existing RStringLiteral.
// So we assign it a number and take it out of "rexprlist".
// Therefore, if all is OK (no errors), then there will be only unequal
// string literals in each lexical state. Note that the only way
// this can be legal is if this is a string declared inline within the
// BNF. Hence, it belongs to only one lexical state - namely "DEFAULT".
sl.ordinal = re.ordinal;
prepareToRemove(respecs, res);
}
}
}
} else if (!(res.rexp instanceof RJustName)) {
res.rexp.ordinal = tokenCount++;
}
if (!(res.rexp instanceof RJustName) && !res.rexp.label.equals("")) {
names_of_tokens.put(new Integer(res.rexp.ordinal), res.rexp.label);
}
if (!(res.rexp instanceof RJustName)) {
rexps_of_tokens.put(new Integer(res.rexp.ordinal), res.rexp);
}
}
} removePreparedItems(); /*
* The following code performs a tree walk on all regular expressions
* attaching links to "RJustName"s. Error messages are given if
* undeclared names are used, or if "RJustNames" refer to private
* regular expressions or to regular expressions of any kind other
* than TOKEN. In addition, this loop also removes top level
* "RJustName"s from "rexprlist".
* This code is not executed if Options.getUserTokenManager() is set to
* true. Instead the following block of code is executed.
*/ if (!Options.getUserTokenManager()) {
FixRJustNames frjn = new FixRJustNames();
for (Iterator<TokenProduction> it = rexprlist.iterator(); it.hasNext();) {
TokenProduction tp = (TokenProduction)(it.next());
List<RegExprSpec> respecs = tp.respecs;
for (Iterator<RegExprSpec> it1 = respecs.iterator(); it1.hasNext();) {
RegExprSpec res = (RegExprSpec)(it1.next());
frjn.root = res.rexp;
ExpansionTreeWalker.preOrderWalk(res.rexp, frjn);
if (res.rexp instanceof RJustName) {
prepareToRemove(respecs, res);
}
}
}
} removePreparedItems(); /*
* The following code is executed only if Options.getUserTokenManager() is
* set to true. This code visits all top-level "RJustName"s (ignores
* "RJustName"s nested within regular expressions). Since regular expressions
* are optional in this case, "RJustName"s without corresponding regular
* expressions are given ordinal values here. If "RJustName"s refer to
* a named regular expression, their ordinal values are set to reflect this.
* All but one "RJustName" node is removed from the lists by the end of
* execution of this code.
*/ if (Options.getUserTokenManager()) {
for (Iterator<TokenProduction> it = rexprlist.iterator(); it.hasNext();) {
TokenProduction tp = (TokenProduction)(it.next());
List<RegExprSpec> respecs = tp.respecs;
for (Iterator<RegExprSpec> it1 = respecs.iterator(); it1.hasNext();) {
RegExprSpec res = (RegExprSpec)(it1.next());
if (res.rexp instanceof RJustName) { RJustName jn = (RJustName)res.rexp;
RegularExpression rexp = (RegularExpression)named_tokens_table.get(jn.label);
if (rexp == null) {
jn.ordinal = tokenCount++;
named_tokens_table.put(jn.label, jn);
ordered_named_tokens.add(jn);
names_of_tokens.put(new Integer(jn.ordinal), jn.label);
} else {
jn.ordinal = rexp.ordinal;
prepareToRemove(respecs, res);
}
}
}
}
} removePreparedItems(); /*
* The following code is executed only if Options.getUserTokenManager() is
* set to true. This loop labels any unlabeled regular expression and
* prints a warning that it is doing so. These labels are added to
* "ordered_named_tokens" so that they may be generated into the ...Constants
* file.
*/
if (Options.getUserTokenManager()) {
for (Iterator<TokenProduction> it = rexprlist.iterator(); it.hasNext();) {
TokenProduction tp = (TokenProduction)(it.next());
List<RegExprSpec> respecs = tp.respecs;
for (Iterator<RegExprSpec> it1 = respecs.iterator(); it1.hasNext();) {
RegExprSpec res = (RegExprSpec)(it1.next());
Integer ii = new Integer(res.rexp.ordinal);
if (names_of_tokens.get(ii) == null) {
JavaCCErrors.warning(res.rexp, "Unlabeled regular expression cannot be referred to by " +
"user generated token manager.");
}
}
}
} if (JavaCCErrors.get_error_count() != 0) throw new MetaParseException(); // The following code sets the value of the "emptyPossible" field of NormalProduction
// nodes. This field is initialized to false, and then the entire list of
// productions is processed. This is repeated as long as at least one item
// got updated from false to true in the pass.
boolean emptyUpdate = true;
while (emptyUpdate) {
emptyUpdate = false;
for (Iterator<NormalProduction> it = bnfproductions.iterator(); it.hasNext();) {
NormalProduction prod = (NormalProduction)it.next();
if (emptyExpansionExists(prod.getExpansion())) {
if (!prod.isEmptyPossible()) {
emptyUpdate = prod.setEmptyPossible(true);
}
}
}
} if (Options.getSanityCheck() && JavaCCErrors.get_error_count() == 0) { // The following code checks that all ZeroOrMore, ZeroOrOne, and OneOrMore nodes
// do not contain expansions that can expand to the empty token list.
for (Iterator<NormalProduction> it = bnfproductions.iterator(); it.hasNext();) {
ExpansionTreeWalker.preOrderWalk(((NormalProduction)it.next()).getExpansion(), new EmptyChecker());
} // The following code goes through the productions and adds pointers to other
// productions that it can expand to without consuming any tokens. Once this is
// done, a left-recursion check can be performed.
for (Iterator<NormalProduction> it = bnfproductions.iterator(); it.hasNext();) {
NormalProduction prod = it.next();
addLeftMost(prod, prod.getExpansion());
} // Now the following loop calls a recursive walk routine that searches for
// actual left recursions. The way the algorithm is coded, once a node has
// been determined to participate in a left recursive loop, it is not tried
// in any other loop.
for (Iterator<NormalProduction> it = bnfproductions.iterator(); it.hasNext();) {
NormalProduction prod = it.next();
if (prod.getWalkStatus() == 0) {
prodWalk(prod);
}
} // Now we do a similar, but much simpler walk for the regular expression part of
// the grammar. Here we are looking for any kind of loop, not just left recursions,
// so we only need to do the equivalent of the above walk.
// This is not done if option USER_TOKEN_MANAGER is set to true.
if (!Options.getUserTokenManager()) {
for (Iterator<TokenProduction> it = rexprlist.iterator(); it.hasNext();) {
TokenProduction tp = (TokenProduction)(it.next());
List<RegExprSpec> respecs = tp.respecs;
for (Iterator<RegExprSpec> it1 = respecs.iterator(); it1.hasNext();) {
RegExprSpec res = (RegExprSpec)(it1.next());
RegularExpression rexp = res.rexp;
if (rexp.walkStatus == 0) {
rexp.walkStatus = -1;
if (rexpWalk(rexp)) {
loopString = "..." + rexp.label + "... --> " + loopString;
JavaCCErrors.semantic_error(rexp, "Loop in regular expression detected: \"" + loopString + "\"");
}
rexp.walkStatus = 1;
}
}
}
} /*
* The following code performs the lookahead ambiguity checking.
*/
if (JavaCCErrors.get_error_count() == 0) {
for (Iterator<NormalProduction> it = bnfproductions.iterator(); it.hasNext();) {
ExpansionTreeWalker.preOrderWalk((it.next()).getExpansion(), new LookaheadChecker());
}
} } // matches "if (Options.getSanityCheck()) {" if (JavaCCErrors.get_error_count() != 0) throw new MetaParseException(); } // org.javacc.parser.ExpansionTreeWalker#postOrderWalk
// 后续遍历节点,与前序遍历类似
/**
* Visits the nodes of the tree rooted at "node" in post-order.
* i.e., it visits the children first and then executes
* opObj.action.
*/
static void postOrderWalk(Expansion node, TreeWalkerOp opObj) {
if (opObj.goDeeper(node)) {
if (node instanceof Choice) {
for (Iterator it = ((Choice)node).getChoices().iterator(); it.hasNext();) {
postOrderWalk((Expansion)it.next(), opObj);
}
} else if (node instanceof Sequence) {
for (Iterator it = ((Sequence)node).units.iterator(); it.hasNext();) {
postOrderWalk((Expansion)it.next(), opObj);
}
} else if (node instanceof OneOrMore) {
postOrderWalk(((OneOrMore)node).expansion, opObj);
} else if (node instanceof ZeroOrMore) {
postOrderWalk(((ZeroOrMore)node).expansion, opObj);
} else if (node instanceof ZeroOrOne) {
postOrderWalk(((ZeroOrOne)node).expansion, opObj);
} else if (node instanceof Lookahead) {
Expansion nested_e = ((Lookahead)node).getLaExpansion();
if (!(nested_e instanceof Sequence && (Expansion)(((Sequence)nested_e).units.get(0)) == node)) {
postOrderWalk(nested_e, opObj);
}
} else if (node instanceof TryBlock) {
postOrderWalk(((TryBlock)node).exp, opObj);
} else if (node instanceof RChoice) {
for (Iterator it = ((RChoice)node).getChoices().iterator(); it.hasNext();) {
postOrderWalk((Expansion)it.next(), opObj);
}
} else if (node instanceof RSequence) {
for (Iterator it = ((RSequence)node).units.iterator(); it.hasNext();) {
postOrderWalk((Expansion)it.next(), opObj);
}
} else if (node instanceof ROneOrMore) {
postOrderWalk(((ROneOrMore)node).regexpr, opObj);
} else if (node instanceof RZeroOrMore) {
postOrderWalk(((RZeroOrMore)node).regexpr, opObj);
} else if (node instanceof RZeroOrOne) {
postOrderWalk(((RZeroOrOne)node).regexpr, opObj);
} else if (node instanceof RRepetitionRange) {
postOrderWalk(((RRepetitionRange)node).regexpr, opObj);
}
}
opObj.action(node);
}
5.3. ParseGen 生成parser框架
ParseGen 生成一些header, 将java_compilation 写进去等。
// org.javacc.parser.ParseGen#start
public void start(boolean isJavaModernMode) throws MetaParseException { Token t = null; if (JavaCCErrors.get_error_count() != 0) {
throw new MetaParseException();
} if (Options.getBuildParser()) {
final List<String> tn = new ArrayList<String>(toolNames);
tn.add(toolName); // This is the first line generated -- the the comment line at the top of the generated parser
genCodeLine("/* " + getIdString(tn, cu_name + ".java") + " */"); boolean implementsExists = false;
final boolean extendsExists = false; if (cu_to_insertion_point_1.size() != 0) {
Object firstToken = cu_to_insertion_point_1.get(0);
printTokenSetup((Token) firstToken);
ccol = 1;
for (final Iterator<Token> it = cu_to_insertion_point_1.iterator(); it.hasNext();) {
t = it.next();
if (t.kind == IMPLEMENTS) {
implementsExists = true;
} else if (t.kind == CLASS) {
implementsExists = false;
} printToken(t);
}
} if (implementsExists) {
genCode(", ");
} else {
genCode(" implements ");
}
genCode(cu_name + "Constants ");
if (cu_to_insertion_point_2.size() != 0) {
printTokenSetup((Token) (cu_to_insertion_point_2.get(0)));
for (final Iterator<Token> it = cu_to_insertion_point_2.iterator(); it.hasNext();) {
printToken(it.next());
}
} genCodeLine("");
genCodeLine(""); new ParseEngine().build(this); if (Options.getStatic()) {
genCodeLine(" static private " + Options.getBooleanType()
+ " jj_initialized_once = false;");
}
if (Options.getUserTokenManager()) {
genCodeLine(" /** User defined Token Manager. */");
genCodeLine(" " + staticOpt() + "public TokenManager token_source;");
} else {
genCodeLine(" /** Generated Token Manager. */");
genCodeLine(" " + staticOpt() + "public " + cu_name + "TokenManager token_source;");
if (!Options.getUserCharStream()) {
if (Options.getJavaUnicodeEscape()) {
genCodeLine(" " + staticOpt() + "JavaCharStream jj_input_stream;");
} else {
genCodeLine(" " + staticOpt() + "SimpleCharStream jj_input_stream;");
}
}
}
genCodeLine(" /** Current token. */");
genCodeLine(" " + staticOpt() + "public Token token;");
genCodeLine(" /** Next token. */");
genCodeLine(" " + staticOpt() + "public Token jj_nt;");
if (!Options.getCacheTokens()) {
genCodeLine(" " + staticOpt() + "private int jj_ntk;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" " + staticOpt() + "private int jj_depth;");
}
if (jj2index != 0) {
genCodeLine(" " + staticOpt() + "private Token jj_scanpos, jj_lastpos;");
genCodeLine(" " + staticOpt() + "private int jj_la;");
if (lookaheadNeeded) {
genCodeLine(" /** Whether we are looking ahead. */");
genCodeLine(" " + staticOpt() + "private " + Options.getBooleanType()
+ " jj_lookingAhead = false;");
genCodeLine(" " + staticOpt() + "private " + Options.getBooleanType()
+ " jj_semLA;");
}
}
if (Options.getErrorReporting()) {
genCodeLine(" " + staticOpt() + "private int jj_gen;");
genCodeLine(" " + staticOpt() + "final private int[] jj_la1 = new int["
+ maskindex + "];");
final int tokenMaskSize = (tokenCount - 1) / 32 + 1;
for (int i = 0; i < tokenMaskSize; i++) {
genCodeLine(" static private int[] jj_la1_" + i + ";");
}
genCodeLine(" static {");
for (int i = 0; i < tokenMaskSize; i++) {
genCodeLine(" jj_la1_init_" + i + "();");
}
genCodeLine(" }");
for (int i = 0; i < tokenMaskSize; i++) {
genCodeLine(" private static void jj_la1_init_" + i + "() {");
genCode(" jj_la1_" + i + " = new int[] {");
for (final Iterator it = maskVals.iterator(); it.hasNext();) {
final int[] tokenMask = (int[]) (it.next());
genCode("0x" + Integer.toHexString(tokenMask[i]) + ",");
}
genCodeLine("};");
genCodeLine(" }");
}
}
if (jj2index != 0 && Options.getErrorReporting()) {
genCodeLine(" " + staticOpt() + "final private JJCalls[] jj_2_rtns = new JJCalls["
+ jj2index + "];");
genCodeLine(" " + staticOpt() + "private " + Options.getBooleanType()
+ " jj_rescan = false;");
genCodeLine(" " + staticOpt() + "private int jj_gc = 0;");
}
genCodeLine(""); if (Options.getDebugParser()) {
genCodeLine(" {");
genCodeLine(" enable_tracing();");
genCodeLine(" }");
} if (!Options.getUserTokenManager()) {
if (Options.getUserCharStream()) {
genCodeLine(" /** Constructor with user supplied CharStream. */");
genCodeLine(" public " + cu_name + "(CharStream stream) {");
if (Options.getStatic()) {
genCodeLine(" if (jj_initialized_once) {");
genCodeLine(" System.out.println(\"ERROR: Second call to constructor of static parser. \");");
genCodeLine(" System.out.println(\" You must either use ReInit() "
+ "or set the JavaCC option STATIC to false\");");
genCodeLine(" System.out.println(\" during parser generation.\");");
genCodeLine(" throw new "+(Options.isLegacyExceptionHandling() ? "Error" : "RuntimeException")+"();");
genCodeLine(" }");
genCodeLine(" jj_initialized_once = true;");
}
if (Options.getTokenManagerUsesParser()) {
genCodeLine(" token_source = new " + cu_name
+ "TokenManager(this, stream);");
} else {
genCodeLine(" token_source = new " + cu_name + "TokenManager(stream);");
}
genCodeLine(" token = new Token();");
if (Options.getCacheTokens()) {
genCodeLine(" token.next = jj_nt = token_source.getNextToken();");
} else {
genCodeLine(" jj_ntk = -1;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" jj_depth = -1;");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen = 0;");
if (maskindex > 0) {
genCodeLine(" for (int i = 0; i < " + maskindex
+ "; i++) jj_la1[i] = -1;");
}
if (jj2index != 0) {
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) jj_2_rtns[i] = new JJCalls();");
}
}
genCodeLine(" }");
genCodeLine("");
genCodeLine(" /** Reinitialise. */");
genCodeLine(" " + staticOpt() + "public void ReInit(CharStream stream) {"); if (Options.isTokenManagerRequiresParserAccess()) {
genCodeLine(" token_source.ReInit(this,stream);");
} else {
genCodeLine(" token_source.ReInit(stream);");
} genCodeLine(" token = new Token();");
if (Options.getCacheTokens()) {
genCodeLine(" token.next = jj_nt = token_source.getNextToken();");
} else {
genCodeLine(" jj_ntk = -1;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" jj_depth = -1;");
}
if (lookaheadNeeded) {
genCodeLine(" jj_lookingAhead = false;");
}
if (jjtreeGenerated) {
genCodeLine(" jjtree.reset();");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen = 0;");
if (maskindex > 0) {
genCodeLine(" for (int i = 0; i < " + maskindex
+ "; i++) jj_la1[i] = -1;");
}
if (jj2index != 0) {
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) jj_2_rtns[i] = new JJCalls();");
}
}
genCodeLine(" }");
} else { if (!isJavaModernMode) {
genCodeLine(" /** Constructor with InputStream. */");
genCodeLine(" public " + cu_name + "(java.io.InputStream stream) {");
genCodeLine(" this(stream, null);");
genCodeLine(" }");
genCodeLine(" /** Constructor with InputStream and supplied encoding */");
genCodeLine(" public " + cu_name
+ "(java.io.InputStream stream, String encoding) {");
if (Options.getStatic()) {
genCodeLine(" if (jj_initialized_once) {");
genCodeLine(" System.out.println(\"ERROR: Second call to constructor of static parser. \");");
genCodeLine(" System.out.println(\" You must either use ReInit() or "
+ "set the JavaCC option STATIC to false\");");
genCodeLine(" System.out.println(\" during parser generation.\");");
genCodeLine(" throw new "+(Options.isLegacyExceptionHandling() ? "Error" : "RuntimeException")+"();");
genCodeLine(" }");
genCodeLine(" jj_initialized_once = true;");
} if (Options.getJavaUnicodeEscape()) {
if (!Options.getGenerateChainedException()) {
genCodeLine(" try { jj_input_stream = new JavaCharStream(stream, encoding, 1, 1); } "
+ "catch(java.io.UnsupportedEncodingException e) {"
+ " throw new RuntimeException(e.getMessage()); }");
} else {
genCodeLine(" try { jj_input_stream = new JavaCharStream(stream, encoding, 1, 1); } "
+ "catch(java.io.UnsupportedEncodingException e) { throw new RuntimeException(e); }");
}
} else {
if (!Options.getGenerateChainedException()) {
genCodeLine(" try { jj_input_stream = new SimpleCharStream(stream, encoding, 1, 1); } "
+ "catch(java.io.UnsupportedEncodingException e) { "
+ "throw new RuntimeException(e.getMessage()); }");
} else {
genCodeLine(" try { jj_input_stream = new SimpleCharStream(stream, encoding, 1, 1); } "
+ "catch(java.io.UnsupportedEncodingException e) { throw new RuntimeException(e); }");
}
}
if (Options.getTokenManagerUsesParser() && !Options.getStatic()) {
genCodeLine(" token_source = new " + cu_name
+ "TokenManager(this, jj_input_stream);");
} else {
genCodeLine(" token_source = new " + cu_name
+ "TokenManager(jj_input_stream);");
}
genCodeLine(" token = new Token();");
if (Options.getCacheTokens()) {
genCodeLine(" token.next = jj_nt = token_source.getNextToken();");
} else {
genCodeLine(" jj_ntk = -1;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" jj_depth = -1;");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen = 0;");
if (maskindex > 0) {
genCodeLine(" for (int i = 0; i < " + maskindex
+ "; i++) jj_la1[i] = -1;");
}
if (jj2index != 0) {
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) jj_2_rtns[i] = new JJCalls();");
}
}
genCodeLine(" }");
genCodeLine(""); genCodeLine(" /** Reinitialise. */");
genCodeLine(" " + staticOpt()
+ "public void ReInit(java.io.InputStream stream) {");
genCodeLine(" ReInit(stream, null);");
genCodeLine(" }"); genCodeLine(" /** Reinitialise. */");
genCodeLine(" "
+ staticOpt()
+ "public void ReInit(java.io.InputStream stream, String encoding) {");
if (!Options.getGenerateChainedException()) {
genCodeLine(" try { jj_input_stream.ReInit(stream, encoding, 1, 1); } "
+ "catch(java.io.UnsupportedEncodingException e) { "
+ "throw new RuntimeException(e.getMessage()); }");
} else {
genCodeLine(" try { jj_input_stream.ReInit(stream, encoding, 1, 1); } "
+ "catch(java.io.UnsupportedEncodingException e) { throw new RuntimeException(e); }");
} if (Options.isTokenManagerRequiresParserAccess()) {
genCodeLine(" token_source.ReInit(this,jj_input_stream);");
} else {
genCodeLine(" token_source.ReInit(jj_input_stream);");
} genCodeLine(" token = new Token();");
if (Options.getCacheTokens()) {
genCodeLine(" token.next = jj_nt = token_source.getNextToken();");
} else {
genCodeLine(" jj_ntk = -1;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" jj_depth = -1;");
}
if (jjtreeGenerated) {
genCodeLine(" jjtree.reset();");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen = 0;");
genCodeLine(" for (int i = 0; i < " + maskindex
+ "; i++) jj_la1[i] = -1;");
if (jj2index != 0) {
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) jj_2_rtns[i] = new JJCalls();");
}
}
genCodeLine(" }");
genCodeLine(""); } final String readerInterfaceName = isJavaModernMode ? "Provider" : "java.io.Reader";
final String stringReaderClass = isJavaModernMode ? "StringProvider"
: "java.io.StringReader"; genCodeLine(" /** Constructor. */");
genCodeLine(" public " + cu_name + "(" + readerInterfaceName + " stream) {");
if (Options.getStatic()) {
genCodeLine(" if (jj_initialized_once) {");
genCodeLine(" System.out.println(\"ERROR: Second call to constructor of static parser. \");");
genCodeLine(" System.out.println(\" You must either use ReInit() or "
+ "set the JavaCC option STATIC to false\");");
genCodeLine(" System.out.println(\" during parser generation.\");");
genCodeLine(" throw new "+(Options.isLegacyExceptionHandling() ? "Error" : "RuntimeException")+"();");
genCodeLine(" }");
genCodeLine(" jj_initialized_once = true;");
}
if (Options.getJavaUnicodeEscape()) {
genCodeLine(" jj_input_stream = new JavaCharStream(stream, 1, 1);");
} else {
genCodeLine(" jj_input_stream = new SimpleCharStream(stream, 1, 1);");
}
if (Options.getTokenManagerUsesParser() && !Options.getStatic()) {
genCodeLine(" token_source = new " + cu_name
+ "TokenManager(this, jj_input_stream);");
} else {
genCodeLine(" token_source = new " + cu_name
+ "TokenManager(jj_input_stream);");
}
genCodeLine(" token = new Token();");
if (Options.getCacheTokens()) {
genCodeLine(" token.next = jj_nt = token_source.getNextToken();");
} else {
genCodeLine(" jj_ntk = -1;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" jj_depth = -1;");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen = 0;");
if (maskindex > 0) {
genCodeLine(" for (int i = 0; i < " + maskindex
+ "; i++) jj_la1[i] = -1;");
}
if (jj2index != 0) {
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) jj_2_rtns[i] = new JJCalls();");
}
}
genCodeLine(" }");
genCodeLine(""); // Add-in a string based constructor because its convenient (modern only to prevent regressions)
if (isJavaModernMode) {
genCodeLine(" /** Constructor. */");
genCodeLine(" public " + cu_name
+ "(String dsl) throws ParseException, "+Options.getTokenMgrErrorClass() +" {");
genCodeLine(" this(new " + stringReaderClass + "(dsl));");
genCodeLine(" }");
genCodeLine(""); genCodeLine(" public void ReInit(String s) {");
genCodeLine(" ReInit(new " + stringReaderClass + "(s));");
genCodeLine(" }"); } genCodeLine(" /** Reinitialise. */");
genCodeLine(" " + staticOpt() + "public void ReInit(" + readerInterfaceName
+ " stream) {");
if (Options.getJavaUnicodeEscape()) {
genCodeLine(" if (jj_input_stream == null) {");
genCodeLine(" jj_input_stream = new JavaCharStream(stream, 1, 1);");
genCodeLine(" } else {");
genCodeLine(" jj_input_stream.ReInit(stream, 1, 1);");
genCodeLine(" }");
} else {
genCodeLine(" if (jj_input_stream == null) {");
genCodeLine(" jj_input_stream = new SimpleCharStream(stream, 1, 1);");
genCodeLine(" } else {");
genCodeLine(" jj_input_stream.ReInit(stream, 1, 1);");
genCodeLine(" }");
} genCodeLine(" if (token_source == null) {"); if (Options.getTokenManagerUsesParser() && !Options.getStatic()) {
genCodeLine(" token_source = new " + cu_name + "TokenManager(this, jj_input_stream);");
} else {
genCodeLine(" token_source = new " + cu_name + "TokenManager(jj_input_stream);");
} genCodeLine(" }");
genCodeLine(""); if (Options.isTokenManagerRequiresParserAccess()) {
genCodeLine(" token_source.ReInit(this,jj_input_stream);");
} else {
genCodeLine(" token_source.ReInit(jj_input_stream);");
} genCodeLine(" token = new Token();");
if (Options.getCacheTokens()) {
genCodeLine(" token.next = jj_nt = token_source.getNextToken();");
} else {
genCodeLine(" jj_ntk = -1;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" jj_depth = -1;");
}
if (jjtreeGenerated) {
genCodeLine(" jjtree.reset();");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen = 0;");
if (maskindex > 0) {
genCodeLine(" for (int i = 0; i < " + maskindex
+ "; i++) jj_la1[i] = -1;");
}
if (jj2index != 0) {
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) jj_2_rtns[i] = new JJCalls();");
}
}
genCodeLine(" }"); }
}
genCodeLine("");
if (Options.getUserTokenManager()) {
genCodeLine(" /** Constructor with user supplied Token Manager. */");
genCodeLine(" public " + cu_name + "(TokenManager tm) {");
} else {
genCodeLine(" /** Constructor with generated Token Manager. */");
genCodeLine(" public " + cu_name + "(" + cu_name + "TokenManager tm) {");
}
if (Options.getStatic()) {
genCodeLine(" if (jj_initialized_once) {");
genCodeLine(" System.out.println(\"ERROR: Second call to constructor of static parser. \");");
genCodeLine(" System.out.println(\" You must either use ReInit() or "
+ "set the JavaCC option STATIC to false\");");
genCodeLine(" System.out.println(\" during parser generation.\");");
genCodeLine(" throw new "+(Options.isLegacyExceptionHandling() ? "Error" : "RuntimeException")+"();");
genCodeLine(" }");
genCodeLine(" jj_initialized_once = true;");
}
genCodeLine(" token_source = tm;");
genCodeLine(" token = new Token();");
if (Options.getCacheTokens()) {
genCodeLine(" token.next = jj_nt = token_source.getNextToken();");
} else {
genCodeLine(" jj_ntk = -1;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" jj_depth = -1;");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen = 0;");
if (maskindex > 0) {
genCodeLine(" for (int i = 0; i < " + maskindex + "; i++) jj_la1[i] = -1;");
}
if (jj2index != 0) {
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) jj_2_rtns[i] = new JJCalls();");
}
}
genCodeLine(" }");
genCodeLine("");
if (Options.getUserTokenManager()) {
genCodeLine(" /** Reinitialise. */");
genCodeLine(" public void ReInit(TokenManager tm) {");
} else {
genCodeLine(" /** Reinitialise. */");
genCodeLine(" public void ReInit(" + cu_name + "TokenManager tm) {");
}
genCodeLine(" token_source = tm;");
genCodeLine(" token = new Token();");
if (Options.getCacheTokens()) {
genCodeLine(" token.next = jj_nt = token_source.getNextToken();");
} else {
genCodeLine(" jj_ntk = -1;");
}
if (Options.getDepthLimit() > 0) {
genCodeLine(" jj_depth = -1;");
}
if (jjtreeGenerated) {
genCodeLine(" jjtree.reset();");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen = 0;");
if (maskindex > 0) {
genCodeLine(" for (int i = 0; i < " + maskindex + "; i++) jj_la1[i] = -1;");
}
if (jj2index != 0) {
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) jj_2_rtns[i] = new JJCalls();");
}
}
genCodeLine(" }");
genCodeLine("");
genCodeLine(" " + staticOpt()
+ "private Token jj_consume_token(int kind) throws ParseException {");
if (Options.getCacheTokens()) {
genCodeLine(" Token oldToken = token;");
genCodeLine(" if ((token = jj_nt).next != null) jj_nt = jj_nt.next;");
genCodeLine(" else jj_nt = jj_nt.next = token_source.getNextToken();");
} else {
genCodeLine(" Token oldToken;");
genCodeLine(" if ((oldToken = token).next != null) token = token.next;");
genCodeLine(" else token = token.next = token_source.getNextToken();");
genCodeLine(" jj_ntk = -1;");
}
genCodeLine(" if (token.kind == kind) {");
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen++;");
if (jj2index != 0) {
genCodeLine(" if (++jj_gc > 100) {");
genCodeLine(" jj_gc = 0;");
genCodeLine(" for (int i = 0; i < jj_2_rtns.length; i++) {");
genCodeLine(" JJCalls c = jj_2_rtns[i];");
genCodeLine(" while (c != null) {");
genCodeLine(" if (c.gen < jj_gen) c.first = null;");
genCodeLine(" c = c.next;");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine(" }");
}
}
if (Options.getDebugParser()) {
genCodeLine(" trace_token(token, \"\");");
}
genCodeLine(" return token;");
genCodeLine(" }");
if (Options.getCacheTokens()) {
genCodeLine(" jj_nt = token;");
}
genCodeLine(" token = oldToken;");
if (Options.getErrorReporting()) {
genCodeLine(" jj_kind = kind;");
}
genCodeLine(" throw generateParseException();");
genCodeLine(" }");
genCodeLine("");
if (jj2index != 0) {
genCodeLine(" @SuppressWarnings(\"serial\")");
genCodeLine(" static private final class LookaheadSuccess extends "+(Options.isLegacyExceptionHandling() ? "java.lang.Error" : "java.lang.RuntimeException")+" {");
genCodeLine(" @Override");
genCodeLine(" public Throwable fillInStackTrace() {");
genCodeLine(" return this;");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine(" static private final LookaheadSuccess jj_ls = new LookaheadSuccess();");
genCodeLine(" " + staticOpt() + "private " + Options.getBooleanType()
+ " jj_scan_token(int kind) {");
genCodeLine(" if (jj_scanpos == jj_lastpos) {");
genCodeLine(" jj_la--;");
genCodeLine(" if (jj_scanpos.next == null) {");
genCodeLine(" jj_lastpos = jj_scanpos = jj_scanpos.next = token_source.getNextToken();");
genCodeLine(" } else {");
genCodeLine(" jj_lastpos = jj_scanpos = jj_scanpos.next;");
genCodeLine(" }");
genCodeLine(" } else {");
genCodeLine(" jj_scanpos = jj_scanpos.next;");
genCodeLine(" }");
if (Options.getErrorReporting()) {
genCodeLine(" if (jj_rescan) {");
genCodeLine(" int i = 0; Token tok = token;");
genCodeLine(" while (tok != null && tok != jj_scanpos) { i++; tok = tok.next; }");
genCodeLine(" if (tok != null) jj_add_error_token(kind, i);");
if (Options.getDebugLookahead()) {
genCodeLine(" } else {");
genCodeLine(" trace_scan(jj_scanpos, kind);");
}
genCodeLine(" }");
} else if (Options.getDebugLookahead()) {
genCodeLine(" trace_scan(jj_scanpos, kind);");
}
genCodeLine(" if (jj_scanpos.kind != kind) return true;");
genCodeLine(" if (jj_la == 0 && jj_scanpos == jj_lastpos) throw jj_ls;");
genCodeLine(" return false;");
genCodeLine(" }");
genCodeLine("");
}
genCodeLine("");
genCodeLine("/** Get the next Token. */");
genCodeLine(" " + staticOpt() + "final public Token getNextToken() {");
if (Options.getCacheTokens()) {
genCodeLine(" if ((token = jj_nt).next != null) jj_nt = jj_nt.next;");
genCodeLine(" else jj_nt = jj_nt.next = token_source.getNextToken();");
} else {
genCodeLine(" if (token.next != null) token = token.next;");
genCodeLine(" else token = token.next = token_source.getNextToken();");
genCodeLine(" jj_ntk = -1;");
}
if (Options.getErrorReporting()) {
genCodeLine(" jj_gen++;");
}
if (Options.getDebugParser()) {
genCodeLine(" trace_token(token, \" (in getNextToken)\");");
}
genCodeLine(" return token;");
genCodeLine(" }");
genCodeLine("");
genCodeLine("/** Get the specific Token. */");
genCodeLine(" " + staticOpt() + "final public Token getToken(int index) {");
if (lookaheadNeeded) {
genCodeLine(" Token t = jj_lookingAhead ? jj_scanpos : token;");
} else {
genCodeLine(" Token t = token;");
}
genCodeLine(" for (int i = 0; i < index; i++) {");
genCodeLine(" if (t.next != null) t = t.next;");
genCodeLine(" else t = t.next = token_source.getNextToken();");
genCodeLine(" }");
genCodeLine(" return t;");
genCodeLine(" }");
genCodeLine("");
if (!Options.getCacheTokens()) {
genCodeLine(" " + staticOpt() + "private int jj_ntk_f() {");
genCodeLine(" if ((jj_nt=token.next) == null)");
genCodeLine(" return (jj_ntk = (token.next=token_source.getNextToken()).kind);");
genCodeLine(" else");
genCodeLine(" return (jj_ntk = jj_nt.kind);");
genCodeLine(" }");
genCodeLine("");
}
if (Options.getErrorReporting()) {
if (!Options.getGenerateGenerics()) {
genCodeLine(" " + staticOpt()
+ "private java.util.List jj_expentries = new java.util.ArrayList();");
} else {
genCodeLine(" "
+ staticOpt()
+ "private java.util.List<int[]> jj_expentries = new java.util.ArrayList<int[]>();");
}
genCodeLine(" " + staticOpt() + "private int[] jj_expentry;");
genCodeLine(" " + staticOpt() + "private int jj_kind = -1;");
if (jj2index != 0) {
genCodeLine(" " + staticOpt() + "private int[] jj_lasttokens = new int[100];");
genCodeLine(" " + staticOpt() + "private int jj_endpos;");
genCodeLine("");
genCodeLine(" " + staticOpt()
+ "private void jj_add_error_token(int kind, int pos) {");
genCodeLine(" if (pos >= 100) {");
genCodeLine(" return;");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" if (pos == jj_endpos + 1) {");
genCodeLine(" jj_lasttokens[jj_endpos++] = kind;");
genCodeLine(" } else if (jj_endpos != 0) {");
genCodeLine(" jj_expentry = new int[jj_endpos];");
genCodeLine("");
genCodeLine(" for (int i = 0; i < jj_endpos; i++) {");
genCodeLine(" jj_expentry[i] = jj_lasttokens[i];");
genCodeLine(" }");
genCodeLine("");
if (!Options.getGenerateGenerics()) {
genCodeLine(" for (java.util.Iterator it = jj_expentries.iterator(); it.hasNext();) {");
genCodeLine(" int[] oldentry = (int[])(it.next());");
} else {
genCodeLine(" for (int[] oldentry : jj_expentries) {");
} genCodeLine(" if (oldentry.length == jj_expentry.length) {");
genCodeLine(" boolean isMatched = true;");
genCodeLine("");
genCodeLine(" for (int i = 0; i < jj_expentry.length; i++) {");
genCodeLine(" if (oldentry[i] != jj_expentry[i]) {");
genCodeLine(" isMatched = false;");
genCodeLine(" break;");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" }");
genCodeLine(" if (isMatched) {");
genCodeLine(" jj_expentries.add(jj_expentry);");
genCodeLine(" break;");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" if (pos != 0) {");
genCodeLine(" jj_lasttokens[(jj_endpos = pos) - 1] = kind;");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine(" }");
}
genCodeLine("");
genCodeLine(" /** Generate ParseException. */");
genCodeLine(" " + staticOpt() + "public ParseException generateParseException() {");
genCodeLine(" jj_expentries.clear();");
genCodeLine(" " + Options.getBooleanType() + "[] la1tokens = new "
+ Options.getBooleanType() + "[" + tokenCount + "];");
genCodeLine(" if (jj_kind >= 0) {");
genCodeLine(" la1tokens[jj_kind] = true;");
genCodeLine(" jj_kind = -1;");
genCodeLine(" }");
genCodeLine(" for (int i = 0; i < " + maskindex + "; i++) {");
genCodeLine(" if (jj_la1[i] == jj_gen) {");
genCodeLine(" for (int j = 0; j < 32; j++) {");
for (int i = 0; i < (tokenCount - 1) / 32 + 1; i++) {
genCodeLine(" if ((jj_la1_" + i + "[i] & (1<<j)) != 0) {");
genCode(" la1tokens[");
if (i != 0) {
genCode((32 * i) + "+");
}
genCodeLine("j] = true;");
genCodeLine(" }");
}
genCodeLine(" }");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine(" for (int i = 0; i < " + tokenCount + "; i++) {");
genCodeLine(" if (la1tokens[i]) {");
genCodeLine(" jj_expentry = new int[1];");
genCodeLine(" jj_expentry[0] = i;");
genCodeLine(" jj_expentries.add(jj_expentry);");
genCodeLine(" }");
genCodeLine(" }");
if (jj2index != 0) {
genCodeLine(" jj_endpos = 0;");
genCodeLine(" jj_rescan_token();");
genCodeLine(" jj_add_error_token(0, 0);");
}
genCodeLine(" int[][] exptokseq = new int[jj_expentries.size()][];");
genCodeLine(" for (int i = 0; i < jj_expentries.size(); i++) {");
if (!Options.getGenerateGenerics()) {
genCodeLine(" exptokseq[i] = (int[])jj_expentries.get(i);");
} else {
genCodeLine(" exptokseq[i] = jj_expentries.get(i);");
}
genCodeLine(" }"); if (isJavaModernMode) {
// Add the lexical state onto the exception message
genCodeLine(" return new ParseException(token, exptokseq, tokenImage, token_source == null ? null : " +cu_name+ "TokenManager.lexStateNames[token_source.curLexState]);");
} else {
genCodeLine(" return new ParseException(token, exptokseq, tokenImage);");
} genCodeLine(" }");
} else {
genCodeLine(" /** Generate ParseException. */");
genCodeLine(" " + staticOpt() + "public ParseException generateParseException() {");
genCodeLine(" Token errortok = token.next;");
if (Options.getKeepLineColumn()) {
genCodeLine(" int line = errortok.beginLine, column = errortok.beginColumn;");
}
genCodeLine(" String mess = (errortok.kind == 0) ? tokenImage[0] : errortok.image;");
if (Options.getKeepLineColumn()) {
genCodeLine(" return new ParseException("
+ "\"Parse error at line \" + line + \", column \" + column + \". "
+ "Encountered: \" + mess);");
} else {
genCodeLine(" return new ParseException(\"Parse error at <unknown location>. "
+ "Encountered: \" + mess);");
}
genCodeLine(" }");
}
genCodeLine(""); genCodeLine(" " + staticOpt() + "private " + Options.getBooleanType()
+ " trace_enabled;");
genCodeLine("");
genCodeLine("/** Trace enabled. */");
genCodeLine(" " + staticOpt() + "final public boolean trace_enabled() {");
genCodeLine(" return trace_enabled;");
genCodeLine(" }");
genCodeLine(""); if (Options.getDebugParser()) {
genCodeLine(" " + staticOpt() + "private int trace_indent = 0;"); genCodeLine("/** Enable tracing. */");
genCodeLine(" " + staticOpt() + "final public void enable_tracing() {");
genCodeLine(" trace_enabled = true;");
genCodeLine(" }");
genCodeLine("");
genCodeLine("/** Disable tracing. */");
genCodeLine(" " + staticOpt() + "final public void disable_tracing() {");
genCodeLine(" trace_enabled = false;");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" " + staticOpt() + "protected void trace_call(String s) {");
genCodeLine(" if (trace_enabled) {");
genCodeLine(" for (int i = 0; i < trace_indent; i++) { System.out.print(\" \"); }");
genCodeLine(" System.out.println(\"Call: \" + s);");
genCodeLine(" }");
genCodeLine(" trace_indent = trace_indent + 2;");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" " + staticOpt() + "protected void trace_return(String s) {");
genCodeLine(" trace_indent = trace_indent - 2;");
genCodeLine(" if (trace_enabled) {");
genCodeLine(" for (int i = 0; i < trace_indent; i++) { System.out.print(\" \"); }");
genCodeLine(" System.out.println(\"Return: \" + s);");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" " + staticOpt()
+ "protected void trace_token(Token t, String where) {");
genCodeLine(" if (trace_enabled) {");
genCodeLine(" for (int i = 0; i < trace_indent; i++) { System.out.print(\" \"); }");
genCodeLine(" System.out.print(\"Consumed token: <\" + tokenImage[t.kind]);");
genCodeLine(" if (t.kind != 0 && !tokenImage[t.kind].equals(\"\\\"\" + t.image + \"\\\"\")) {");
genCodeLine(" System.out.print(\": \\\"\" + "+Options.getTokenMgrErrorClass() + ".addEscapes("+"t.image) + \"\\\"\");");
genCodeLine(" }");
genCodeLine(" System.out.println(\" at line \" + t.beginLine + "
+ "\" column \" + t.beginColumn + \">\" + where);");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" " + staticOpt() + "protected void trace_scan(Token t1, int t2) {");
genCodeLine(" if (trace_enabled) {");
genCodeLine(" for (int i = 0; i < trace_indent; i++) { System.out.print(\" \"); }");
genCodeLine(" System.out.print(\"Visited token: <\" + tokenImage[t1.kind]);");
genCodeLine(" if (t1.kind != 0 && !tokenImage[t1.kind].equals(\"\\\"\" + t1.image + \"\\\"\")) {");
genCodeLine(" System.out.print(\": \\\"\" + "+Options.getTokenMgrErrorClass() + ".addEscapes("+"t1.image) + \"\\\"\");");
genCodeLine(" }");
genCodeLine(" System.out.println(\" at line \" + t1.beginLine + \""
+ " column \" + t1.beginColumn + \">; Expected token: <\" + tokenImage[t2] + \">\");");
genCodeLine(" }");
genCodeLine(" }");
genCodeLine("");
} else {
genCodeLine(" /** Enable tracing. */");
genCodeLine(" " + staticOpt() + "final public void enable_tracing() {");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" /** Disable tracing. */");
genCodeLine(" " + staticOpt() + "final public void disable_tracing() {");
genCodeLine(" }");
genCodeLine("");
} if (jj2index != 0 && Options.getErrorReporting()) {
genCodeLine(" " + staticOpt() + "private void jj_rescan_token() {");
genCodeLine(" jj_rescan = true;");
genCodeLine(" for (int i = 0; i < " + jj2index + "; i++) {");
genCodeLine(" try {");
genCodeLine(" JJCalls p = jj_2_rtns[i];");
genCodeLine("");
genCodeLine(" do {");
genCodeLine(" if (p.gen > jj_gen) {");
genCodeLine(" jj_la = p.arg; jj_lastpos = jj_scanpos = p.first;");
genCodeLine(" switch (i) {");
for (int i = 0; i < jj2index; i++) {
genCodeLine(" case " + i + ": jj_3_" + (i + 1) + "(); break;");
}
genCodeLine(" }");
genCodeLine(" }");
genCodeLine(" p = p.next;");
genCodeLine(" } while (p != null);");
genCodeLine("");
genCodeLine(" } catch(LookaheadSuccess ls) { }");
genCodeLine(" }");
genCodeLine(" jj_rescan = false;");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" " + staticOpt() + "private void jj_save(int index, int xla) {");
genCodeLine(" JJCalls p = jj_2_rtns[index];");
genCodeLine(" while (p.gen > jj_gen) {");
genCodeLine(" if (p.next == null) { p = p.next = new JJCalls(); break; }");
genCodeLine(" p = p.next;");
genCodeLine(" }");
genCodeLine("");
genCodeLine(" p.gen = jj_gen + xla - jj_la; ");
genCodeLine(" p.first = token;");
genCodeLine(" p.arg = xla;");
genCodeLine(" }");
genCodeLine("");
} if (jj2index != 0 && Options.getErrorReporting()) {
genCodeLine(" static final class JJCalls {");
genCodeLine(" int gen;");
genCodeLine(" Token first;");
genCodeLine(" int arg;");
genCodeLine(" JJCalls next;");
genCodeLine(" }");
genCodeLine("");
} if (cu_from_insertion_point_2.size() != 0) {
printTokenSetup((Token) (cu_from_insertion_point_2.get(0)));
ccol = 1;
for (final Iterator it = cu_from_insertion_point_2.iterator(); it.hasNext();) {
t = (Token) it.next();
printToken(t);
}
printTrailingComments(t);
}
genCodeLine(""); saveOutput(Options.getOutputDirectory() + File.separator + cu_name
+ getFileExtension(Options.getOutputLanguage())); } // matches "if (Options.getBuildParser())" }
5.4. LexGen 语法解析生成
LexGen 生成语法树,将所有的产生式转换成相应的语法表示。
// org.javacc.parser.LexGen#start
public void start() throws IOException
{
if (!Options.getBuildTokenManager() ||
Options.getUserTokenManager() ||
JavaCCErrors.get_error_count() > 0)
return; final String codeGeneratorClass = Options.getTokenManagerCodeGenerator();
keepLineCol = Options.getKeepLineColumn();
errorHandlingClass = Options.getTokenMgrErrorClass();
List choices = new ArrayList();
Enumeration e;
TokenProduction tp;
int i, j; staticString = (Options.getStatic() ? "static " : "");
tokMgrClassName = cu_name + "TokenManager"; if (!generateDataOnly && codeGeneratorClass == null) PrintClassHead();
BuildLexStatesTable(); e = allTpsForState.keys(); boolean ignoring = false; while (e.hasMoreElements())
{
int startState = -1;
NfaState.ReInit();
RStringLiteral.ReInit(); String key = (String)e.nextElement(); lexStateIndex = GetIndex(key);
lexStateSuffix = "_" + lexStateIndex;
List<TokenProduction> allTps = (List<TokenProduction>)allTpsForState.get(key);
initStates.put(key, initialState = new NfaState());
ignoring = false; singlesToSkip[lexStateIndex] = new NfaState();
singlesToSkip[lexStateIndex].dummy = true; if (key.equals("DEFAULT"))
defaultLexState = lexStateIndex; for (i = 0; i < allTps.size(); i++)
{
tp = (TokenProduction)allTps.get(i);
int kind = tp.kind;
boolean ignore = tp.ignoreCase;
List<RegExprSpec> rexps = tp.respecs; if (i == 0)
ignoring = ignore; for (j = 0; j < rexps.size(); j++)
{
RegExprSpec respec = (RegExprSpec)rexps.get(j);
curRE = respec.rexp; rexprs[curKind = curRE.ordinal] = curRE;
lexStates[curRE.ordinal] = lexStateIndex;
ignoreCase[curRE.ordinal] = ignore; if (curRE.private_rexp)
{
kinds[curRE.ordinal] = -1;
continue;
} if (!Options.getNoDfa() && curRE instanceof RStringLiteral &&
!((RStringLiteral)curRE).image.equals(""))
{
((RStringLiteral)curRE).GenerateDfa(this, curRE.ordinal);
if (i != 0 && !mixed[lexStateIndex] && ignoring != ignore) {
mixed[lexStateIndex] = true;
}
}
else if (curRE.CanMatchAnyChar())
{
if (canMatchAnyChar[lexStateIndex] == -1 ||
canMatchAnyChar[lexStateIndex] > curRE.ordinal)
canMatchAnyChar[lexStateIndex] = curRE.ordinal;
}
else
{
Nfa temp; if (curRE instanceof RChoice)
choices.add(curRE); temp = curRE.GenerateNfa(ignore);
temp.end.isFinal = true;
temp.end.kind = curRE.ordinal;
initialState.AddMove(temp.start);
} if (kinds.length < curRE.ordinal)
{
int[] tmp = new int[curRE.ordinal + 1]; System.arraycopy(kinds, 0, tmp, 0, kinds.length);
kinds = tmp;
}
//System.out.println(" ordina : " + curRE.ordinal); kinds[curRE.ordinal] = kind; if (respec.nextState != null &&
!respec.nextState.equals(lexStateName[lexStateIndex]))
newLexState[curRE.ordinal] = respec.nextState; if (respec.act != null && respec.act.getActionTokens() != null &&
respec.act.getActionTokens().size() > 0)
actions[curRE.ordinal] = respec.act; switch(kind)
{
case TokenProduction.SPECIAL :
hasSkipActions |= (actions[curRE.ordinal] != null) ||
(newLexState[curRE.ordinal] != null);
hasSpecial = true;
toSpecial[curRE.ordinal / 64] |= 1L << (curRE.ordinal % 64);
toSkip[curRE.ordinal / 64] |= 1L << (curRE.ordinal % 64);
break;
case TokenProduction.SKIP :
hasSkipActions |= (actions[curRE.ordinal] != null);
hasSkip = true;
toSkip[curRE.ordinal / 64] |= 1L << (curRE.ordinal % 64);
break;
case TokenProduction.MORE :
hasMoreActions |= (actions[curRE.ordinal] != null);
hasMore = true;
toMore[curRE.ordinal / 64] |= 1L << (curRE.ordinal % 64); if (newLexState[curRE.ordinal] != null)
canReachOnMore[GetIndex(newLexState[curRE.ordinal])] = true;
else
canReachOnMore[lexStateIndex] = true; break;
case TokenProduction.TOKEN :
hasTokenActions |= (actions[curRE.ordinal] != null);
toToken[curRE.ordinal / 64] |= 1L << (curRE.ordinal % 64);
break;
}
}
} // Generate a static block for initializing the nfa transitions
NfaState.ComputeClosures(); for (i = 0; i < initialState.epsilonMoves.size(); i++)
((NfaState)initialState.epsilonMoves.elementAt(i)).GenerateCode(); if (hasNfa[lexStateIndex] = (NfaState.generatedStates != 0))
{
initialState.GenerateCode();
startState = initialState.GenerateInitMoves(this);
} if (initialState.kind != Integer.MAX_VALUE && initialState.kind != 0)
{
if ((toSkip[initialState.kind / 64] & (1L << initialState.kind)) != 0L ||
(toSpecial[initialState.kind / 64] & (1L << initialState.kind)) != 0L)
hasSkipActions = true;
else if ((toMore[initialState.kind / 64] & (1L << initialState.kind)) != 0L)
hasMoreActions = true;
else
hasTokenActions = true; if (initMatch[lexStateIndex] == 0 ||
initMatch[lexStateIndex] > initialState.kind)
{
initMatch[lexStateIndex] = initialState.kind;
hasEmptyMatch = true;
}
}
else if (initMatch[lexStateIndex] == 0)
initMatch[lexStateIndex] = Integer.MAX_VALUE; RStringLiteral.FillSubString(); if (hasNfa[lexStateIndex] && !mixed[lexStateIndex])
RStringLiteral.GenerateNfaStartStates(this, initialState); if (generateDataOnly || codeGeneratorClass != null) {
RStringLiteral.UpdateStringLiteralData(totalNumStates, lexStateIndex);
NfaState.UpdateNfaData(totalNumStates, startState, lexStateIndex,
canMatchAnyChar[lexStateIndex]);
} else {
RStringLiteral.DumpDfaCode(this);
if (hasNfa[lexStateIndex]) {
NfaState.DumpMoveNfa(this);
}
}
totalNumStates += NfaState.generatedStates;
if (stateSetSize < NfaState.generatedStates)
stateSetSize = NfaState.generatedStates;
} for (i = 0; i < choices.size(); i++)
((RChoice)choices.get(i)).CheckUnmatchability(); CheckEmptyStringMatch(); if (generateDataOnly || codeGeneratorClass != null) {
tokenizerData.setParserName(cu_name);
NfaState.BuildTokenizerData(tokenizerData);
RStringLiteral.BuildTokenizerData(tokenizerData);
int[] newLexStateIndices = new int[maxOrdinal];
StringBuilder tokenMgrDecls = new StringBuilder();
if (token_mgr_decls != null && token_mgr_decls.size() > 0) {
Token t = (Token)token_mgr_decls.get(0);
for (j = 0; j < token_mgr_decls.size(); j++) {
tokenMgrDecls.append(((Token)token_mgr_decls.get(j)).image + " ");
}
}
tokenizerData.setDecls(tokenMgrDecls.toString());
Map<Integer, String> actionStrings = new HashMap<Integer, String>();
for (i = 0; i < maxOrdinal; i++) {
if (newLexState[i] == null) {
newLexStateIndices[i] = -1;
} else {
newLexStateIndices[i] = GetIndex(newLexState[i]);
}
// For java, we have this but for other languages, eventually we will
// simply have a string.
Action act = actions[i];
if (act == null) continue;
StringBuilder sb = new StringBuilder();
for (int k = 0; k < act.getActionTokens().size(); k++) {
sb.append(((Token)act.getActionTokens().get(k)).image);
sb.append(" ");
}
actionStrings.put(i, sb.toString());
}
tokenizerData.setDefaultLexState(defaultLexState);
tokenizerData.setLexStateNames(lexStateName);
tokenizerData.updateMatchInfo(
actionStrings, newLexStateIndices,
toSkip, toSpecial, toMore, toToken);
if (generateDataOnly) return;
Class<TokenManagerCodeGenerator> codeGenClazz;
TokenManagerCodeGenerator gen;
try {
codeGenClazz = (Class<TokenManagerCodeGenerator>)Class.forName(codeGeneratorClass);
gen = codeGenClazz.newInstance();
} catch(Exception ee) {
JavaCCErrors.semantic_error(
"Could not load the token manager code generator class: " +
codeGeneratorClass + "\nError: " + ee.getMessage());
return;
}
gen.generateCode(tokenizerData);
gen.finish(tokenizerData);
return;
} RStringLiteral.DumpStrLiteralImages(this);
DumpFillToken();
NfaState.DumpStateSets(this);
NfaState.DumpNonAsciiMoveMethods(this);
DumpGetNextToken(); if (Options.getDebugTokenManager())
{
NfaState.DumpStatesForKind(this);
DumpDebugMethods();
} if (hasLoop)
{
genCodeLine(staticString + "int[] jjemptyLineNo = new int[" + maxLexStates + "];");
genCodeLine(staticString + "int[] jjemptyColNo = new int[" + maxLexStates + "];");
genCodeLine(staticString + "" + Options.getBooleanType() + "[] jjbeenHere = new " + Options.getBooleanType() + "[" + maxLexStates + "];");
} DumpSkipActions();
DumpMoreActions();
DumpTokenActions(); NfaState.PrintBoilerPlate(this); String charStreamName;
if (Options.getUserCharStream())
charStreamName = "CharStream";
else
{
if (Options.getJavaUnicodeEscape())
charStreamName = "JavaCharStream";
else
charStreamName = "SimpleCharStream";
} writeTemplate(BOILERPLATER_METHOD_RESOURCE_URL,
"charStreamName", charStreamName,
"lexStateNameLength", lexStateName.length,
"defaultLexState", defaultLexState,
"noDfa", Options.getNoDfa(),
"generatedStates", totalNumStates); DumpStaticVarDeclarations(charStreamName);
genCodeLine(/*{*/ "}"); // TODO :: CBA -- Require Unification of output language specific processing into a single Enum class
String fileName = Options.getOutputDirectory() + File.separator +
tokMgrClassName +
getFileExtension(Options.getOutputLanguage()); if (Options.getBuildParser()) {
saveOutput(fileName);
}
}
5.5. 生成其他辅助类
OtherFilesGen 生成其他几个辅助类,比如Toekn, ParseException...
// org.javacc.parser.OtherFilesGen#start
static public void start(boolean isJavaModern) throws MetaParseException { JavaResourceTemplateLocations templateLoc = isJavaModern ? JavaFiles.RESOURCES_JAVA_MODERN : JavaFiles.RESOURCES_JAVA_CLASSIC; Token t = null; if (JavaCCErrors.get_error_count() != 0) throw new MetaParseException(); // Added this if condition -- 2012/10/17 -- cba
if ( Options.isGenerateBoilerplateCode()) { if (isJavaModern) {
JavaFiles.gen_JavaModernFiles();
} JavaFiles.gen_TokenMgrError(templateLoc);
JavaFiles.gen_ParseException(templateLoc);
JavaFiles.gen_Token(templateLoc);
} if (Options.getUserTokenManager()) {
// CBA -- I think that Token managers are unique so will always be generated
JavaFiles.gen_TokenManager(templateLoc);
} else if (Options.getUserCharStream()) {
// Added this if condition -- 2012/10/17 -- cba
if (Options.isGenerateBoilerplateCode()) {
JavaFiles.gen_CharStream(templateLoc);
}
} else {
// Added this if condition -- 2012/10/17 -- cba if (Options.isGenerateBoilerplateCode()) {
if (Options.getJavaUnicodeEscape()) {
JavaFiles.gen_JavaCharStream(templateLoc);
} else {
JavaFiles.gen_SimpleCharStream(templateLoc);
}
}
} try {
ostr = new java.io.PrintWriter(
new java.io.BufferedWriter(
new java.io.FileWriter(
new java.io.File(Options.getOutputDirectory(), cu_name + CONSTANTS_FILENAME_SUFFIX)
),
8192
)
);
} catch (java.io.IOException e) {
JavaCCErrors.semantic_error("Could not open file " + cu_name + "Constants.java for writing.");
throw new Error();
} List<String> tn = new ArrayList<String>(toolNames);
tn.add(toolName);
ostr.println("/* " + getIdString(tn, cu_name + CONSTANTS_FILENAME_SUFFIX) + " */"); if (cu_to_insertion_point_1.size() != 0 &&
((Token)cu_to_insertion_point_1.get(0)).kind == PACKAGE
) {
for (int i = 1; i < cu_to_insertion_point_1.size(); i++) {
if (((Token)cu_to_insertion_point_1.get(i)).kind == SEMICOLON) {
printTokenSetup((Token)(cu_to_insertion_point_1.get(0)));
for (int j = 0; j <= i; j++) {
t = (Token)(cu_to_insertion_point_1.get(j));
printToken(t, ostr);
}
printTrailingComments(t, ostr);
ostr.println("");
ostr.println("");
break;
}
}
}
ostr.println("");
ostr.println("/**");
ostr.println(" * Token literal values and constants.");
ostr.println(" * Generated by org.javacc.parser.OtherFilesGen#start()");
ostr.println(" */"); if(Options.getSupportClassVisibilityPublic()) {
ostr.print("public ");
}
ostr.println("interface " + cu_name + "Constants {");
ostr.println(""); RegularExpression re;
ostr.println(" /** End of File. */");
ostr.println(" int EOF = 0;");
for (java.util.Iterator<RegularExpression> it = ordered_named_tokens.iterator(); it.hasNext();) {
re = it.next();
ostr.println(" /** RegularExpression Id. */");
ostr.println(" int " + re.label + " = " + re.ordinal + ";");
}
ostr.println("");
if (!Options.getUserTokenManager() && Options.getBuildTokenManager()) {
for (int i = 0; i < Main.lg.lexStateName.length; i++) {
ostr.println(" /** Lexical state. */");
ostr.println(" int " + LexGen.lexStateName[i] + " = " + i + ";");
}
ostr.println("");
}
ostr.println(" /** Literal token values. */");
ostr.println(" String[] tokenImage = {");
ostr.println(" \"<EOF>\","); for (java.util.Iterator<TokenProduction> it = rexprlist.iterator(); it.hasNext();) {
TokenProduction tp = (TokenProduction)(it.next());
List<RegExprSpec> respecs = tp.respecs;
for (java.util.Iterator<RegExprSpec> it2 = respecs.iterator(); it2.hasNext();) {
RegExprSpec res = (RegExprSpec)(it2.next());
re = res.rexp;
ostr.print(" ");
if (re instanceof RStringLiteral) {
ostr.println("\"\\\"" + add_escapes(add_escapes(((RStringLiteral)re).image)) + "\\\"\",");
} else if (!re.label.equals("")) {
ostr.println("\"<" + re.label + ">\",");
} else {
if (re.tpContext.kind == TokenProduction.TOKEN) {
JavaCCErrors.warning(re, "Consider giving this non-string token a label for better error reporting.");
}
ostr.println("\"<token of kind " + re.ordinal + ">\",");
} }
}
ostr.println(" };");
ostr.println("");
ostr.println("}"); ostr.close(); }
以上解析,感悟,待完善中。
Calcite(一):javacc语法框架及使用的更多相关文章
- 3.JavaCC 语法描述文件的格式解析
JavaCC的语法描述文件格式如下所示: options { JavaCC的选项 } PARSER_BEGIN(解析器类名) package 包名; import 库名; public class ...
- Phoenix核心功能原理及应用场景介绍以及Calcite 查询计划生成框架介绍
Phoenix是一个开源的HBase SQL层.它不仅可以使用标准的JDBC API替代HBase Client API创建表,插入和查询HBase,也支持二级索引.事物以及多种SQL层优化. 此系列 ...
- javacc jjtree 写法 以及 jj写法 基本语法 以及应用
/***********************************************************/>我使用的测试jjt,jj文件来自于javacc5.0版本>dir ...
- Flink Sql 之 Calcite Volcano优化器(源码解析)
Calcite作为大数据领域最常用的SQL解析引擎,支持Flink , hive, kylin , druid等大型项目的sql解析 同时想要深入研究Flink sql源码的话calcite也是必备 ...
- Frameset框架优缺点--来自新浪微博
原文地址:http://blog.sina.com.cn/s/blog_4a4b1b010100p6ro.html HTML框架简述 一个浏览器窗体可以通过几个页面的组合来显示.我们可以使用框架来 ...
- javacc学习
为什么要研究这些,除了个人兴趣之外,还有可以了解语言是怎样解析字符串生成逻辑代码. 他的应用性也是非常之广,如人工智能方面,把复杂的逻辑抽象成简单的文法,不懂编程的人都可以使用 说到人工智能,数据库S ...
- ANTLR4权威指南 - 第5章 设计语法
在第I部分,我们熟悉了ANTLR,并在一个比较高的层次上了解了语法以及语言程序.现在,我们将要放慢速度来学习下实现更实用任务的一些细节上的技巧,例如建立内部数据结构,提取信息,生成输入对应的翻译内容等 ...
- Mysql数据库查询语法详解
数据库的完整查询语法 在平常的工作中经常需要与数据库打交道 , 虽然大多时间都是简单的查询抑或使用框架封装好的ORM的查询方法 , 但是还是要对数据库的完整查询语法做一个加深理解 数据库完整查询语法框 ...
- ANTLR 语法设计
下面学习如何编写语法. 如何定义语法规则 一种语言模式就是一种递归的语法结构. 我们需要从一系列有代表性的输入文件中归纳出一门语言的结构.在完成这样的归纳工作后,我们就可以正式使用ANTLR语法来表达 ...
随机推荐
- Vue(4)Vue指令的学习1
前言 Vue官网一共有提供了14个指令,分别如下 v-text v-html v-show v-if ☆☆☆ v-else ☆☆☆ v-else-if ☆☆☆ v-for ☆☆☆ v-on ☆☆☆ v ...
- JS replace 替换全部数据
(1)使用具有全局标志g的正则表达式 var str = "dogdogdog"; var str2 = str.replace(/dog/g,"cat");/ ...
- web自动化之windows页面切换
一.为什么切换windows页面 在页面操作过程中,存在点击某个元素之后会重新打开一个windows页面,如果不切换至新页面的话,无法在新页面中进行操作,程序会出现报错 二.如何切换 1.获取当前所有 ...
- 什么是forward和include?
请求包含的例子 第一个Servlet (DispatcherServlet) @Override protected void doGet(HttpServletRequest req, HttpSe ...
- SpringBoot | 1.2 全注解下的Spring IoC
前言 在学习SpringBoot之前,有几个Spring的重要的基础概念需要提一下,SpringBoot对这些基础概念做进一步的封装,完成自动配置.首先就是Spring的控制反转IOC,由于Sprin ...
- [转]CURL常用命令
From:http://www.cnblogs.com/gbyukg/p/3326825.html p.p1 { margin: 0 0 2px; font: 14px ".PingFang ...
- webpack 快速入门 系列 —— 性能
其他章节请看: webpack 快速入门 系列 性能 本篇主要介绍 webpack 中的一些常用性能,包括热模块替换.source map.oneOf.缓存.tree shaking.代码分割.懒加载 ...
- PYTHON2.7安装 pyinstaller出错,不能正常安装
解决方法: pip2.7 install pyinstaller==3.4
- WIN10 报错及解决方法
你的电脑/设备需要修复,无法加载操作系统,原因是关键系统驱动程序丢失或包含错误 \windows\system32\drivers\zklvv.sys 错误代码:0XC000007b 解决方法: 用U ...
- Spark RDD编程-大数据课设
目录 一.实验目的 二.实验平台 三.实验内容.要求 1.pyspark交互式编程 2.编写独立应用程序实现数据去重 3.编写独立应用程序实现求平均值问题 四.实验过程 (一)pyspark交互式编程 ...