Causal Intervention for Weakly-Supervised Semantic Segmentation
概
这篇文章从因果关系的角度剖析如何提升弱监督语义分割的方法.
主要内容
普通的弱监督语义分割
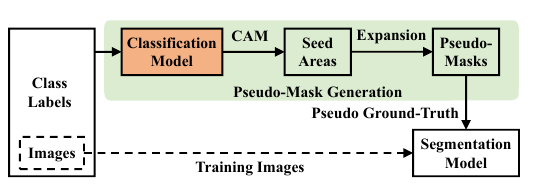
弱监督语义分割不似普通的语义分割一样依赖丰富的人工标注, 本文考虑的情况就是非常极限的, 仅知道每张图片的类别标签(可以是多标签, 比如: 人, 车, 表示一张图片里面有人有车).
一般的弱监督语义分割包含:
- 训练一个分类模型(多标签);
- 通过CAM确定大概的seed areas;
- 将seed areas进行拓展得到pseudo-masks;
- 训练一个分割模型(将pseudo-masks作为ground-truth);
- 概分割模型作为最后的模型
但是显然的是, 仅仅凭借类别标签完成复杂的语义分割任务是相当困难的, 大概有如下:
- 目标物体往往不是孤立的: 有可能数据集中每次出现马的时候都会有一个人, 则分类模型可能会将二者的特征混合用于分类, 那么最后的分割就很难明显的把二者的边界提取出来;
- 背景信息并不完全: 背景往往含有一些别的未被标注的目标, 而这些目标和我们所关心的目标有可能是相互联系甚至是同时存在的, 比如: 地板和沙发, 这导致在提取沙发的时候往往把模板也一并提取出来了;
- foreground, 前景的目标往往是共同变化的: 比如车和车窗, 车窗总是会反应周围的事物, 导致车窗这一属性不是用来提取车的好的特征, 分类模型很有可能会丢掉这一部分信息, 其导致的结果就是最后的分割的区域车窗少一块.
因果模型
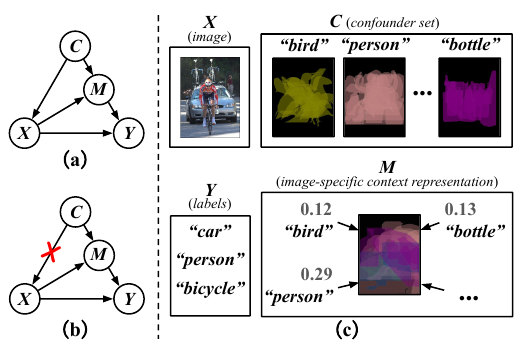
C: context prior;
X: pixel-level image;
M: image-specific representation using the textual templates from C;
Y: labels.
作者认为, 整个流程是这样的:
- 确定先验背景信息\(C\);
- 通过先验背景信息\(C\)构建图片\(X\);
- 图片\(X\)和背景信息\(C\)共同确定了和背景有关的特征表示\(M\);
- \(X\), \(M\) 共同影响最后的类别标签\(Y\).
我们一般的分类模型, 实际上是拟合条件分布
\]
显然这个条件分布与先验的背景信息有很大联系, 即图(a).
而我们实际上所关心的是
\]
即建立目标的出现和场景没有关系的模型.
首先我们要做的就是将其转为一般的统计估计量:
\begin{array}{rl}
\mathrm{{P}}[Y|do(X)]
=& \sum_{c} \mathrm{P}[Y|do(X), c] \: \mathrm{P}[c|do(x)]\\
=& \sum_{c} \mathrm{P}[Y|do(X), c] \: \mathrm{P}[c]\\
=& \sum_{c} \mathrm{P}[Y|X, c, f(X;c)] \: \mathrm{P}[c]\\
=& \sum_{c} \mathrm{P}[Y|X, M=f(X;c)] \: \mathrm{P}[c].\\
\end{array}
\]
显然, 这里有一个假设, 即知道了\(X, C\)之后, \(M\)也是确定的, 其通过\(M=f(X;c)\)来拟合.
训练流程
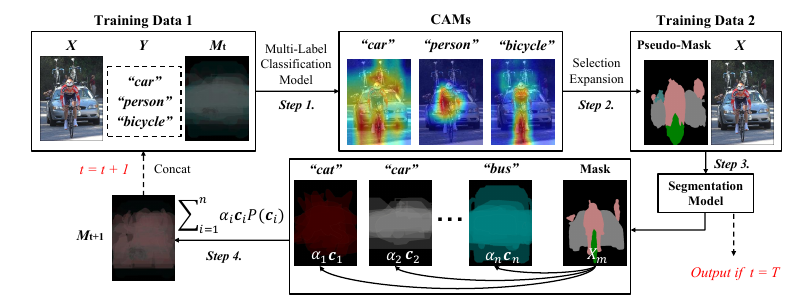
- 训练以\(X, M\)为输入的多标签分类网络, 其通过
\]
其中\(s_i=f(X, M_t;\theta_t^i)\), \(n\)是类别总数.
2. 利用CAM得到seed areas 并扩展为pseudo-mask;
3. 将上面的pseudo-mask作为ground-truth训练分割模型;
4. 计算
\]
注意到, 我们本应该最小化(1), 但是注意到, 此时对于每一个\(c\), 我们都要循环一次, 这非常非常耗时, 所以作者是:
\mathrm{P}[Y|do(X), M=\sum_{c}f(X;c)\mathrm{P}(c) ].\\
\]
一直进行\(T\)步.
注:第1步中的\(f(X, M_t;\theta_t^i)\)并不一定要让\(X, M_t\)都在同一层输入, 实际上\(M_t\)是比较抽象的信息, 故作者实验发现在后几个block加入效果更好;
注: 先验背景信息\(\{c_i\}\)是pseudo-mask的平均;
注: \(W_1, W_2\)是可训练的参数.
代码
Causal Intervention for Weakly-Supervised Semantic Segmentation的更多相关文章
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
- [ICCV 2019] Weakly Supervised Object Detection With Segmentation Collaboration
新在ICCV上发的弱监督物体检测文章,偷偷高兴一下,贴出我的poster,最近有点忙,话不多说,欢迎交流- https://arxiv.org/pdf/1904.00551.pdf http://op ...
- 论文笔记(3):STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
论文题目是STC,即Simple to Complex的一个框架,使用弱标签(image label)来解决密集估计(语义分割)问题. 2014年末以来,半监督的语义分割层出不穷,究其原因还是因为pi ...
- [CVPR 2016] Weakly Supervised Deep Detection Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- [CVPR2017] Weakly Supervised Cascaded Convolutional Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #042eee } p. ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 论文笔记《Feedforward semantic segmentation with zoom-out features》
[论文信息] <Feedforward semantic segmentation with zoom-out features> CVPR 2015 superpixel-level,f ...
- [Papers] Semantic Segmentation Papers(1)
目录 FCN Abstract Introduction Related Work FCN Adapting classifiers for dense prediction Shift-and-st ...
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
随机推荐
- 零基础学习java------25--------jdbc
jdbc开发步骤图 以下要用到的products表 一. JDBC简介 补充 JDBC本质:其实是官方(sun公司)定义的一套操作所有关系型数据库的规则,即接口,各个数据库厂商趋势线这个接口,提 ...
- windows下 apache 二级域名相关配置 【转】
转至: http://www.th7.cn/Program/php/201306/141305.shtml 今天给大家总结下 windows 下 apache的二级域名的相关配置 下面就利用本地127 ...
- STM32代码常见的坑
1 混淆换行符\和除号/造成的坑 入坑代码: GPIO_InitStructure.GPIO_Pin = GPIO_Pin_0 | GPIO_Pin_1 | GPIO_Pin_2 | GPIO_Pin ...
- linux系统的一些常用命令
cd 进入某个目录 ifconfig 查看本机的ip cp (要复制的文件的位置) (要把文件复制的位置) ll 查看文件下,文件的操作权限 ls查看该文件夹下的有那些文件和文件夹 vi filena ...
- JS - 字符串转换成数组,数组转换成字符串
1.字符串转换成数组: var arr = "1, 2, 3, 4, 5, 6"; arr.split(","); // ["1",&quo ...
- 网络通信引擎ICE的使用
ICE是一种网络通信引擎,在javaWeb的开发中可以用于解决局域网内部服务器端与客户端之间的网络通信问题.即可以在 1.在服务器和客户端都安装好ICE 2.服务器端(java)在java项目中引入I ...
- ASP.NET Web API路由解析
前言 本篇文章比较长,仔细思考阅读下来大约需要15分钟,涉及类图有可能在手机显示不完整,可以切换电脑版阅读. 做.Net有好几年时间了从ASP.NET WebForm到ASP.NET MVC再到ASP ...
- 干掉visio,这个画图神器太香了
前言 看过我以往文章的小伙伴可能会发现,我的大部分文章都有很多配图.我的文章风格是图文相结合,更便于大家理解. 最近有很多小伙伴发私信问我:文章中的图是用什么工具画的.他们觉得我画的图风格挺小清新的, ...
- idea 无法创建子目录
idea 无法创建子目录 解决方案
- Mongodb安全防护
1.Mongodb未授权访问 描述 MongoDB 是一个基于分布式文件存储的数据库.默认情况下启动服务存在未授权访问风险,用户可以远程访问数据库,无需认证连接数据库并对数据库进行任意操作,存在严重的 ...