Redis主从复制那点事
我们在 Redis持久化机制你学会了吗?学习了AOF和RDB,如果Redis宕机,他们分别通过回放日志和重新读入RDB文件的方式恢复数据,从而提高可靠性。我们今天来想这么一个问题,假如我们只部署了一台Redis实例,如果这个实例宕机了,那么它在恢复期间,是无法提供数据存取请求的,这样就会使得服务中断。
Redis采用了增加副本的方式,将一份数据同时保存在多个实例上来避免这种情况发生的。即使有一个实例出现故障,在这个实例恢复期间,其它实例也能对外提供服务,不会影响业务的使用。那多个实例是如何保证数据的一致性呢?数据的读写操作可以发给所有的实例吗?实际上,Redis提供了主从模式,以保证数据副本的一致。主从库之间采用的是读写分离的方式。
对于读操作来说,主、从库都可以服务。但是对于写操作来说,首先是要到主库执行,然后,主库再将写操作同步给从库。

那为什么要采用读写分离呢?如果不管是主库还是从库都能接受客户端的写操作,它带来的直接问题就是:如果客户端对同一个key进行了2次修改操作,并且每次修改都分到不同的实例上,那么这2个实例上的副本就不一致了。而主从库模式一旦采用了读写分离,所有数据的修改只会在主库上进行。主库有了最新的数据后,会同步给从库,这样,主从库的数据就是一致的。
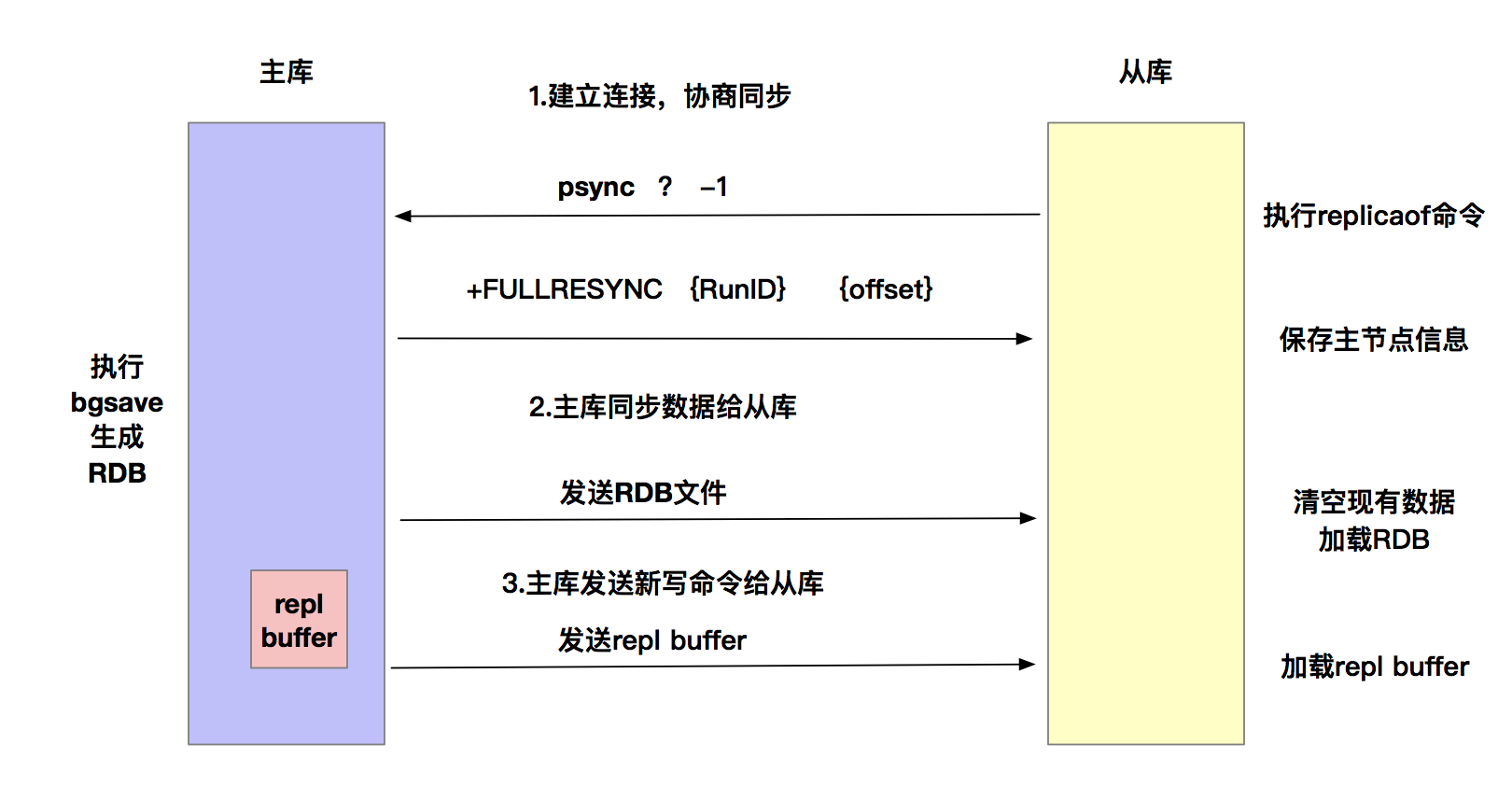
接下来我们来看一下主从同步是如何完成的?我们首先来看一下主从库之间的第一次同步是如何进行的。当我们启动多个redis实例时,它们之间的相互关系就可以通过replicaof命令的形式形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
replicaof 127.0.0.1 6379第一阶段是主从库建立连接、协商同步的过程,主要是为了全量复制做准备。在这一步,从库和主库建立连接,并告诉主库即将进行数据同步,主库确认回复后,主库和从库之间就可以开始同步了。
具体来说,从库给主库发送psync命令,表示要进行数据同步,主库根据这个命令参数来启动复制。psync命令包含了主库的runID和复制进度offset两个参数。
runID:每个Redis实例启动时会自动生成一个随机ID来唯一标识这个实例。当从库和主库第一次复制时,因为不知道主库的runID,所以复制为 ?
offset:此时设置为-1,表示第一次复制。
主库收到psync命令后,会用FULLRESYNC响应命令带上两个参数:主库runID和主库目前的复制进度offset,返回给从库。从库收到响应后,会记录下这两个参数。这里有个地方需要注意,FULLRESYNC 响应表示第一次复制采用的是全量复制,也就是说,主库会把当前所有的数据都复制给从库。
第二阶段是主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的RDB文件。
具体来说,主库执行bgsave命令,生成RDB文件,接着将文件发给从库。从库收到RDB文件后,会清空当前的数据库,然后加载RDB文件。这是因为从库在通过执行replicaof命令开始和主库进行同步之前,有可能存储了
其他的数据。为了避免之前数据的影响,从库需要把当前数据库清空。在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。
否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
最后第三阶段,主库会把第二阶段执行过程中收到的命令再发送给从库。具体操作是,当主库完成RDB文件发送后,就会把此时replication buffer中记录的操作发送给从库,从库接下来再去执行这些操作。这样一来,主从库就实现同步了。
到这里,我们就了解了主从库间通过全量复制实现数据同步的过程了。一旦主从库完成了全量复制,他们之间就会一直维护一个网络连接,主库会通过这个连接将后续收到的命令同步给从库,这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
但是,在主从传播命令的过程中,如果出现网络断开,那主从库之间就无法进行命令传播了,从库自然也就无法和主库保持一致了。接下来,我们就来聊一聊网络断开连接后该怎么办。
在网络断开连接后,Redis主从库会采用增量复制的方式继续同步。那么,增量复制时,主从库之间具体是怎么保证同步的呢?这里的奥妙就在repl_backlog_buffer这个环形缓存区。
主库除了会把接收到的写命令写入replication buffer发送给从库外,同时也会把这些操作命令也写入 repl_backlog_buffer 这个缓冲区。repl_backlog_buffer是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己读到的位置。刚开始的时候,主库和从库的写位置在一起,这算是他们的起始位置。随着主库不断接收新的操作,它在缓冲区中的写位置会逐步偏离起始位置。我们通常用偏移量来衡量这个偏移距离的大小,对主库来说,对应的偏移量就是 master_repl_offset。主库接收的新写操作越多,这个值就会越大。同样,从库在复制完写操作命令后,它在缓冲区中的读位置也开始逐步偏移刚才的起始位置,此时,从库已复制的偏移量 slave_repl_offset 也在不断增加。正常情况下,这两个偏移量基本相等。
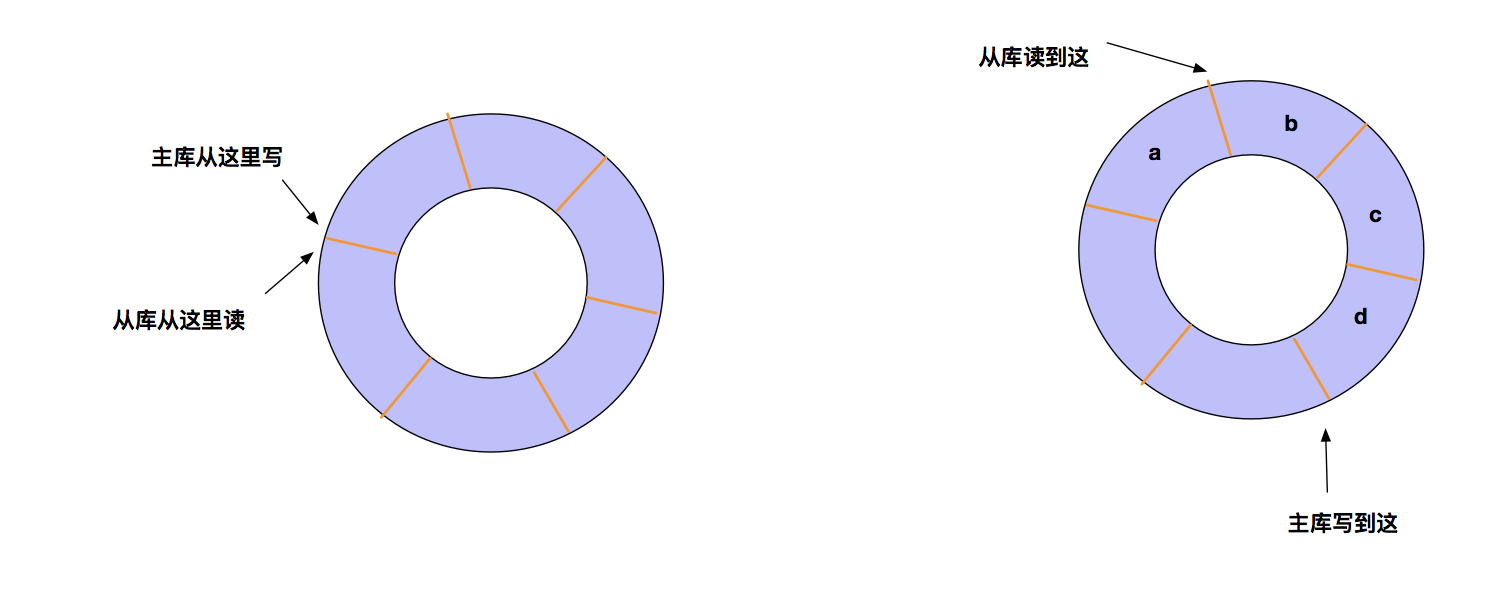
主从库的连接恢复之后,从库首先会给主库发送 psync 命令,并把自己当前的 slave_repl_offset 发给主库,主库会判断自己的 master_repl_offset 和 slave_repl_offset 之间的差距。在网络断连阶段,主库可能会收到新的写操作命令。所以,一般来说,master_repl_offset 会大于 slave_repl_offset。
此时,主库只用把 master_repl_offset 和 slave_repl_offset 之间的命令操作同步给从库就行。如上图所示,主库和从库之间差了b、c、d,增量复制时,主库只要把他们同步给从库就行了。
我们借助一张图来回顾一下增量复制。
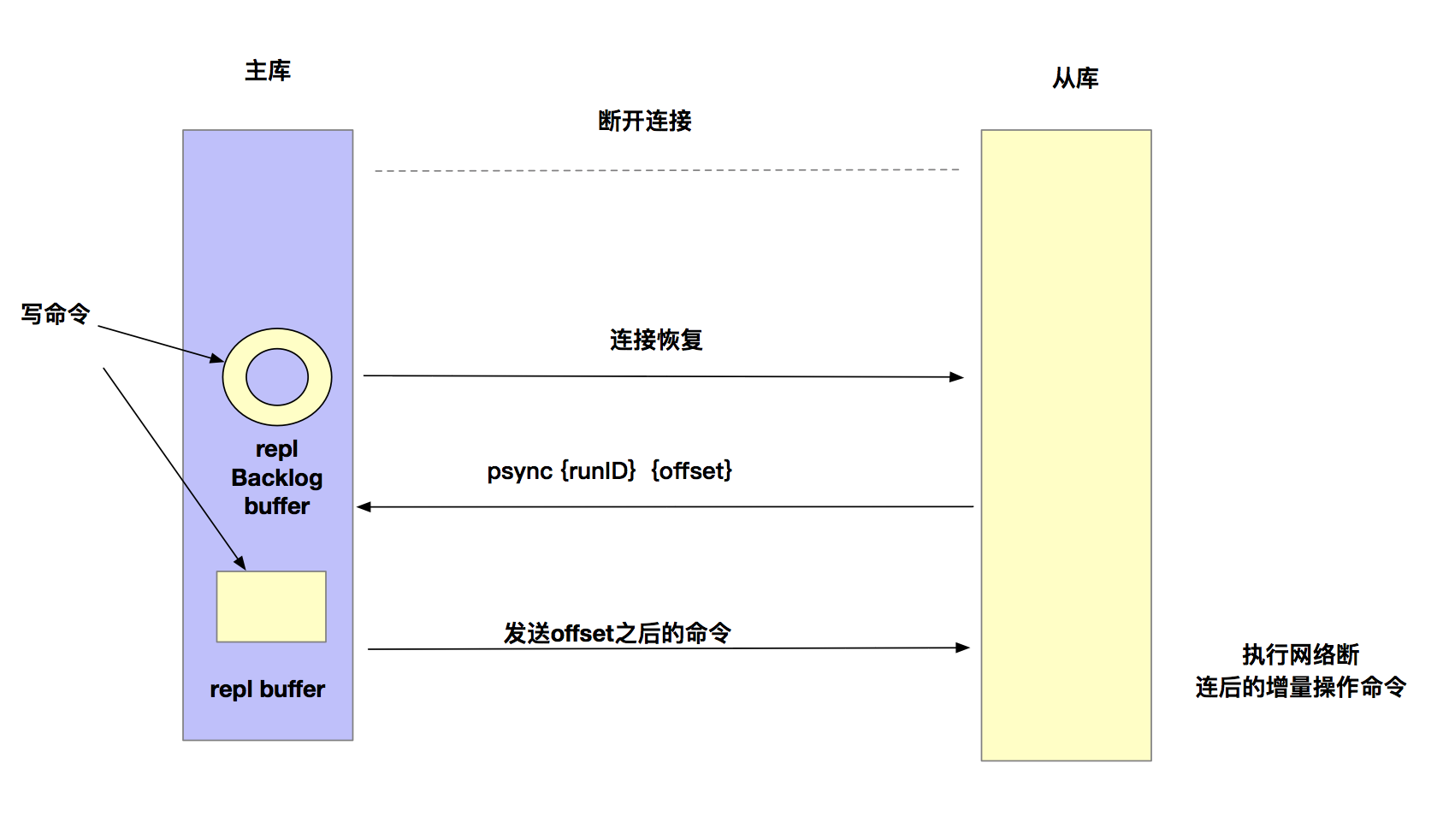
需要注意的一点,因为repl_backlog_buffer是一个环形缓冲区,所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致,从而进行全量复制了。
因此,我们要想办法避免这一情况,一般而言,我们可以调整repl_backlog_size这个参数来设置缓存区的大小。如果它配置得过小,在增量复制阶段,可能会导致从库的复制进度赶不上主库,进而导致从库重新进行全量复制。所以,通过调大这个参数,可以减少从库在网络断连时全量复制的风险。
Redis的主从复制就分享到这里。更多硬核知识,请关注公众号"程序员学长"。

Redis主从复制那点事的更多相关文章
- [原]Redis主从复制各种环境下测试
Redis 主从复制各种环境下测试 测试环境: Linux ubuntu 3.11.0-12-generic 2GB Mem 1 core of Intel(R) Core(TM) i5-3470 C ...
- NoSQL初探之人人都爱Redis:(4)Redis主从复制架构初步探索
一.主从复制架构简介 通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构.那么,我们首先来了解一 ...
- 【转】 NoSQL初探之人人都爱Redis:(4)Redis主从复制架构初步探索
一.主从复制架构简介 通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构.那么,我们首先来了解一 ...
- redis+Keepalived实现Redis主从复制
redis+Keepalived实现Redis主从复制: 环境:CentOs6.5Master: 10.10.10.203Slave: 10.10.10.204Virtural IP Addres ...
- 深入剖析 redis 主从复制
主从概述 redis 支持 master-slave(主从)模式,redis server 可以设置为另一个 redis server 的主机(从机),从机定期从主机拿数据.特殊的,一个 从机同样可以 ...
- 谈谈redis主从复制的重点
Redis主从复制的配置十分简单,它可以使从服务器是主服务器的完全拷贝.下面是关于Redis主从复制的几点重要内容: Redis使用异步复制.但从Redis 2.8开始,从服务器会周期性的应答从复制流 ...
- 配置Redis主从复制
[构建高性能数据库缓存之redis主从复制][http://database.51cto.com/art/201407/444555.htm] 一.什么是redis主从复制? 主从复制,当用户往Mas ...
- Redis主从复制及状态监测
参考链接:http://www.cnblogs.com/morvenhuang/p/4184262.html #配置redis主从复制: #安装redis- master slave #修改slave ...
- Redis主从复制(Master/Slave)
Redis主从复制(Master/Slave) 修改配置文件 拷贝多个redis.conf文件分别配置如下参数: 开启daemonize yes pidfile port logfile dbfile ...
随机推荐
- 保存数据到csv文件报错:Permission denied: './train_data.csv'
如果你此前已经输出,创建了文件,很有可能是你打开了此文件,导致写入不进去报错,关掉文件重新运行程序即可!
- WizTree——一个扫描快似Everything的硬盘空间分析工具
虽然我平时用的主要是Linux,但是由于实际环境是win10,对于磁盘资源的控制,我主要是通过Windows自带的文件资源管理器来查看的,但是显然这个工具不够直观.于是,我也被安利过SpaceSnif ...
- 关于使用JS去除URL中的指定参数问题,js 对url进行某个参数的删除,并返回url
在网页上找了半天,发现现在的资源实在是少的可怜,而前端尤甚.所以没办法,于是自己花了一些时间写了一个: 1 /** 2 * 删除URL中的指定参数 3 * @param {*} url 4 * @pa ...
- 6.17考试总结(NOIP模拟8)[星际旅行·砍树·超级树·求和]
6.17考试总结(NOIP模拟8) 背景 考得不咋样,有一个非常遗憾的地方:最后一题少取膜了,\(100pts->40pts\),改了这么多年的错还是头一回看见以下的情景... T1星际旅行 前 ...
- 删除主键时报错ORA-00955
一.利用已有索引创建主键1.建表GAO@PROD> create table abcd(id number(10),name1 varchar2(20)); Table created. 2.插 ...
- 关于DWG文件转换成PDF
最近有这样一个需求,客户会提供DWG文件,因为DWG文件是不能直接在网页上显示的,所以必须对他做处理,要求是转换成PDF格式.我查了很久的资料,很多都是基于C#和.NET的方法,而且都是说的很模糊,不 ...
- Golang控制子gorutine退出,并阻塞等待所有子gorutine全部退出
Golang控制子gorutine退出,并阻塞等待所有子gorutine全部退出 需求 程序有时需要自动重启或者重新初始化一些功能,就需要退出之前的所有子gorutine,并且要等待所有子goruti ...
- 【原创】Ingress-Nginx-Controller的Metrics监控源码改造简析
一.背景 目前我们的生产环境一层Nginx已经容器化部署,但是监控并不完善,我们期望其具有Ingress-Nginx-Controller组件上报监控的数据.这样可以建立请求全链路的监控大盘.有利于监 ...
- 10.ODBC创建/读取Excel QT4
看到一篇MFC的参考链接:https://blog.csdn.net/u012319493/article/details/50561046 改用QT的函数即可 创建Excel //创建Excel v ...
- Custom Controller CollectionQT样式自定义 003 :Bubblemessage 气泡消息窗
效果Demo 思路大致上是加定时器,触发完成出现 - 停留 - 消失的效果. 源码:https://github.com/linzD00/CustomControllerLibrary