Spark基础:(七)Spark Streaming入门
介绍
1、是spark core的扩展,针对实时数据流处理,具有可扩展、高吞吐量、容错.
数据可以是来自于kafka,flume,tcpsocket,使用高级函数(map reduce filter ,join , windows),
处理的数据可以推送到database,hdfs,针对数据流处理可以应用到机器学习和图计算中。
内部,spark接受实时数据流,分成batch(分批次)进行处理,最终在每个batch终产生结果stream.
2.discretized stream or DStream,
离散流,表示的是连续的数据流。
通过kafka、flume等输入数据流产生,也可以通过对其他DStream进行高阶变换产生。
在内部,DStream是表现为RDD序列。
体验
依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.0</version>
</dependency>scalaDeno
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object SparkStreamingDemo {
def main(args: Array[String]): Unit = {
//local[n] n > 1
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//创建Spark流上下文,批次时长是1s
val ssc = new StreamingContext(conf, Seconds(1))
//创建socket文本流
val lines = ssc.socketTextStream("localhost", 9999)
//压扁
val words = lines.flatMap(_.split(" "))
//变换成对偶
val pairs = words.map((_,1));
val count = pairs.reduceByKey(_+_) ;
count.print()
//启动
ssc.start()
//等待结束
ssc.awaitTermination()
}
}1.启动nc服务器
[win7]
cmd>nc -lL -p 9999
2.启动spark Streaming程序
3.在nc的命令行输入单词.
hello world
4.观察spark计算结果。
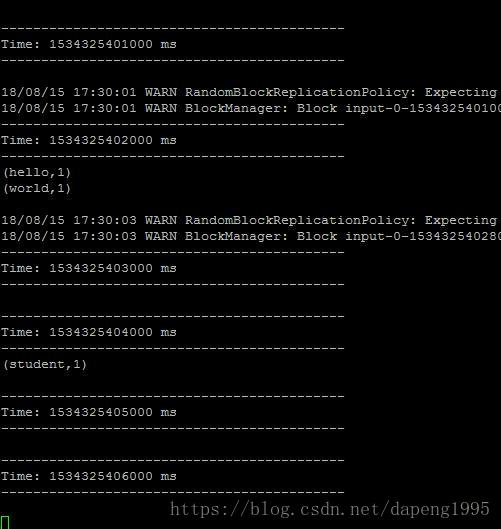
同样的丢到
Spark基础:(七)Spark Streaming入门的更多相关文章
- Spark 基础操作
1. Spark 基础 2. Spark Core 3. Spark SQL 4. Spark Streaming 5. Spark 内核机制 6. Spark 性能调优 1. Spark 基础 1. ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- spark streaming 入门例子
spark streaming 入门例子: spark shell import org.apache.spark._ import org.apache.spark.streaming._ sc.g ...
- Spark基础脚本入门实践3:Pair RDD开发
Pair RDD转化操作 val rdd = sc.parallelize(List((1,2),(3,4),(3,6))) //reduceByKey,通过key来做合并val r1 = rdd.r ...
- Spark基础脚本入门实践1
1.创建数据框架 Creating DataFrames val df = spark.read.json("file:///usr/local/spark/examples/src/mai ...
- spark基础知识(1)
一.大数据架构 并发计算: 并行计算: 很少会说并发计算,一般都是说并行计算,但是并行计算用的是并发技术.并发更偏向于底层.并发通常指的是单机上的并发运行,通过多线程来实现.而并行计算的范围更广,他是 ...
- 初步了解Spark生态系统及Spark Streaming
一. 场景 ◆ Spark[4]: Scope: a MapReduce-like cluster computing framework designed for low-laten ...
- spark基础知识介绍2
dataframe以RDD为基础的分布式数据集,与RDD的区别是,带有Schema元数据,即DF所表示的二维表数据集的每一列带有名称和类型,好处:精简代码:提升执行效率:减少数据读取; 如果不配置sp ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
随机推荐
- PicGo插件
前言:主要介绍PicGo插件,这里的图床上传软件是PicGo-Core,使用命令行操作 PicGo_Path:自己的PicGo安装路径,如果通过Typora一般安装位置位于 C:\Users\自己的主 ...
- 微信小程序API接口封装
@ 目录 一,让我们看一下项目目录 二,让我们熟悉一下这三个文件目的(文件名你看着办) 三,页面js中如何使用 今天的API的封装,我们拿WX小程序开发中,对它的API (wx.request)对这个 ...
- linux下c语言实现简单----线程池
这两天刚好看完linux&c这本书的进程线程部分,学长建议可以用c语言实现一个简单的线程池,也是对线程知识的一个回顾与应用.线程的优点有好多,它是"轻量级的进程",所需资源 ...
- css语法规范、选择器、字体、文本
css语法规范 使用 HTML 时需要遵从一定的规范,CSS 也是如此.要想熟练地使用 CSS 对网页进行修饰,首先需要了解CSS 样式规则. CSS 规则由两个主要的部分构成:选择器以及一条或多条声 ...
- 一.Promise入门准备阶段
一.Promise入门准备阶段 1.区别实例对象呵函数对象 2.两种类型的回调函数(同步与异步) 2.1 同步回调 2.2 异步回调 3.JS的error处理 3.1 错误的类型 3.2 错误处理与错 ...
- 使用 SSL 加密的 JDBC 连接 SAP HANA 数据库
近期客户为满足安全要求,提了让业务应用使用 SSL 方式连接 SAP HANA 数据库的需求.本人查询 SAP官方文档 发现数据库支持 SSL 连接,有参数直接加到 JDBC 的 URL 后边就行了, ...
- jenkins项目发布
目录 一.简介 二.docker打包 一.后端打包 二.前端打包 三.启动容器 四.完整代码 五.发布测试 六.优化方案 七.源码地址: 八.参考 一.简介 1.该章节基于jenkins.Harbor ...
- 连接url
celery broker redis with password broker_url = 'redis://user:password@redishost:6379/0' tooz zookeep ...
- 概述C# virtual修饰符
摘要:C#是继C++和Java语言后的又一面向对象的语言,在语法结构,C#有很多地方和C++及Java相似,但是又不同于它们,其中一些关键特别需要引起我们的注意. C# virtual修饰符用于修改方 ...
- [atARC103F]Distance Sums
给定$n$个数$d_{i}$,构造一棵$n$个点的树使得$\forall 1\le i\le n,\sum_{j=1}^{n}dist(i,j)=d_{i}$ 其中$dist(i,j)$表示$i$到$ ...