Spark系列(八)Worker工作原理
工作原理图
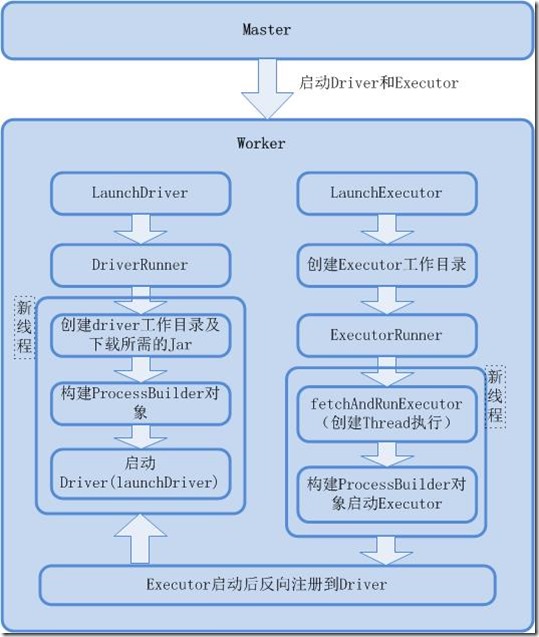
源代码分析
包名:org.apache.spark.deploy.worker
启动driver入口点:registerWithMaster方法中的case LaunchDriver
| 1 | ) => DriverState.FINISHED |
| 37 | case _ => DriverState.FAILED |
| 38 | } |
| 39 | } |
| 40 | |
| 41 | finalState = Some(state) |
| 42 | // 向Driver所属worker发送DriverStateChanged消息 |
| 43 | worker ! DriverStateChanged(driverId, state, finalException) |
| 44 | } |
| 45 | }.start() |
| 46 | } |
LaunchExecutor
管理LaunchExecutor的启动
| 1 | case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) => |
| 2 | if (masterUrl != activeMasterUrl) { |
| 3 | logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.") |
| 4 | } else { |
| 5 | try { |
| 6 | logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name)) |
| 7 | |
| 8 | // Create the executor's working directory |
| 9 | // 创建executor本地工作目录 |
| 10 | val executorDir = new File(workDir, appId + "/" + execId) |
| 11 | if (!executorDir.mkdirs()) { |
| 12 | throw new IOException("Failed to create directory " + executorDir) |
| 13 | } |
| 14 | |
| 15 | // Create local dirs for the executor. These are passed to the executor via the |
| 16 | // SPARK_LOCAL_DIRS environment variable, and deleted by the Worker when the |
| 17 | // application finishes. |
| 18 | val appLocalDirs = appDirectories.get(appId).getOrElse { |
| 19 | Utils.getOrCreateLocalRootDirs(conf).map { dir => |
| 20 | Utils.createDirectory(dir).getAbsolutePath() |
| 21 | }.toSeq |
| 22 | } |
| 23 | appDirectories(appId) = appLocalDirs |
| 24 | // 创建ExecutorRunner对象 |
| 25 | val manager = new ExecutorRunner( |
| 26 | appId, |
| 27 | execId, |
| 28 | appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)), |
| 29 | cores_, |
| 30 | memory_, |
| 31 | self, |
| 32 | workerId, |
| 33 | host, |
| 34 | webUi.boundPort, |
| 35 | publicAddress, |
| 36 | sparkHome, |
| 37 | executorDir, |
| 38 | akkaUrl, |
| 39 | conf, |
| 40 | appLocalDirs, ExecutorState.LOADING) |
| 41 | // executor加入本地缓存 |
| 42 | executors(appId + "/" + execId) = manager |
| 43 | manager.start() |
| 44 | // 增加worker已使用core |
| 45 | coresUsed += cores_ |
| 46 | // 增加worker已使用memory |
| 47 | memoryUsed += memory_ |
| 48 | // 通知master发送ExecutorStateChanged消息 |
| 49 | master ! ExecutorStateChanged(appId, execId, manager.state, None, None) |
| 50 | } |
| 51 | // 异常情况处理,通知master发送ExecutorStateChanged FAILED消息 |
| 52 | catch { |
| 53 | case e: Exception => { |
| 54 | logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e) |
| 55 | if (executors.contains(appId + "/" + execId)) { |
| 56 | executors(appId + "/" + execId).kill() |
| 57 | executors -= appId + "/" + execId |
| 58 | } |
| 59 | master ! ExecutorStateChanged(appId, execId, ExecutorState.FAILED, |
| 60 | Some(e.toString), None) |
| 61 | } |
| 62 | } |
| 63 | } |
总结
1、Worker、Driver、Application启动后都会向Master进行注册,并缓存到Master内存数据模型中
2、完成注册后发送LaunchExecutor、LaunchDriver到Worker
3、Worker收到消息后启动executor和driver进程,并调用Worker的ExecutorStateChanged和DriverStateChanged方法
4、发送ExecutorStateChanged和DriverStateChanged消息到Master的,根据各自的状态信息进行处理,最重要的是会调用schedule方法进行资源的重新调度
Spark系列(八)Worker工作原理的更多相关文章
- Spark系列(十)TaskSchedule工作原理
工作原理图 源码分析: 1.) 25 launchedTask = true 26 } 27 } catch { 28 ...
- Spark系列(九)DAGScheduler工作原理
以wordcount为示例进行深入分析 1 33 ) { 46 logInfo("Submitting " + tasks.size + " missi ...
- line-height系列——定义和工作原理总结
一.line-height的定义和工作原理总结 line-height的属性值: normal 默认 设置合理的行间距. number 设置数字,此数字会与当前的字体尺寸相乘来设置行间距li ...
- 源码分析八( hashmap工作原理)
首先从一条简单的语句开始,创建了一个hashmap对象: Map<String,String> hashmap = new HashMap<String,String>(); ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- How Javascript works (Javascript工作原理) (八) WebAssembly 对比 JavaScript 及其使用场景
个人总结: webworker有以下三种: Dedicated Workers 由主进程实例化并且只能与之进行通信 Shared Workers 可以被运行在同源的所有进程访问(不同的浏览的选项卡,内 ...
- 49、Spark Streaming基本工作原理
一.大数据实时计算介绍 1.概述 Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架.它的底层,其实,也是基于我们之前讲解的Spark Core的. 基本 ...
- 46、Spark SQL工作原理剖析以及性能优化
一.工作原理剖析 1.图解 二.性能优化 1.设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf()) 2.在Hive数据 ...
随机推荐
- NPOI读取Excel,导入数据到Excel练习01
NPOI 2.2.0.0,初级读取导入Excel 1.读取Excel,将数据绑定到dgv上 private void button1_Click(object sender, EventArgs e) ...
- Quartz动态添加、修改和删除定时任务
任务调度开源框架Quartz动态添加.修改和删除定时任务 Quartz 是个开源的作业调度框架,为在 Java 应用程序中进行作业调度提供了简单却强大的机制.Quartz框架包含了调度器监听.作业和触 ...
- 48. Rotate Image
题目: You are given an n x n 2D matrix representing an image. Rotate the image by 90 degrees (clockwis ...
- servlet request.getParamter 有时获取参数为null
他妈的,参数有时可以获取,有时又不行,折腾了好久,把tomcat换成8.0的,之前用apache-tomcat-7.0.67
- 利用PC创建一个无线接入点
win7 创建虚拟接入点,修改接入点名称和密码,然后存为bat文件,以管理员模式运行 netsh wlan set hostednetwork mode=allow ssid=APName key=p ...
- redis twitter
http://redis.io/topics/twitter-clone 翻译:http://my.oschina.net/Twitter/blog/287539
- WCf的理解
从 .NET 3.5 开始 WCF 已经支持用 WebHttpBinding 构建 RESTful Web 服务,基于 WCF 框架的 RESTful Web 服务还是建立在 WCF Message ...
- unity3d5.2.3中 调整视角
按住alt键不放,然后左边的手的图标会变成一个眼睛,在Scene中移动.就会发现可以调整视角了
- grunt + compass
compass和sass文章列表:http://182.92.240.72/tag/compass/ compass实战grunt: http://wrox.cn/article/2000491/ h ...
- JDBC 事务控制
一.简介: 前面一遍提到了jdbc事务相关的概念.从中了解到事务应具有ACID特性.所以对于javaweb开发来说,某一个service层的方法,应该是一个事务,应该是具有原子性的.特别是当一个ser ...